当前位置 : 首页 » 文章分类 : » Docker-基础
Docker-基础
Docker 学习笔记
Docker 是一个跨平台、可移植并且简单易用的容器解决方案。基于 Go 语言开发。
Docker 可在容器内部快速自动化地部署应用,并通过操作系统内核技术(namespaces、cgroup等)为容器提供资源隔离和安全保障。
《Docker — 从入门到实践》 – docker 中文白皮书
https://yeasy.gitbooks.io/docker_practice/content/
https://github.com/yeasy/docker_practice
learn to build and deploy your distributed applications easily to the cloud with docker
https://docker-curriculum.com/
OCI 容器标准
https://www.modb.pro/db/630125
podman
https://docs.podman.io/en/latest/Commands.html
RunC
RunC 简介
https://www.cnblogs.com/sparkdev/p/9032209.html
RunC 是一个轻量级的容器运行工具,用来运行按照 OCI(Open Container Initiative) 标准格式打包的容器。
RunC 是用 golang 创建的项目。
RunC 是标准化容器运行时的一个实现,是 docker 内置的默认容器运行时。
containerd
Containerd 简介
https://www.cnblogs.com/sparkdev/p/9063042.html
containerd 是一个工业级标准的容器运行时,可以在宿主机中管理完整的容器生命周期:容器镜像的传输和存储、容器的执行和管理、存储和网络等。
containerd 是从 docker 中分离出来的,或者说 containerd 本身是 docker 的一部分。
containerd 并不是直接面向最终用户的,而是主要用于集成到更上层的系统里,比如Swarm, Kubernetes, Mesos等容器编排系统。
containerd 以 Daemon 的形式运行在系统上,通过 unix domain socket 暴露很底层的 gRPC API,上层系统可以通过这些 API 管理机器上的容器。每个 containerd 只负责一台机器,Pull 镜像,对容器的操作(启动、停止等),网络,存储都是由 containerd 完成。具体运行容器由 runC 负责,实际上只要是符合 OCI 规范的容器都可以支持。
Nydus
Nydus —— 下一代容器镜像的探索实践
https://www.sofastack.tech/blog/nydus-exploratory-practice-of-next-generation-container-images/
为什么要用docker?
一方面应用包含多种服务,这些服务有自己所依赖的库和软件包;另一方面存在多种部署环境,服务在运行时可能需要动态迁移到不同环境中。这就产生了一个问题:
如何让每种服务能够在所有的部署环境中顺利进行?
各种服务与环境排列组合产生了一个大矩阵,开发人员需要考虑不同的运行环境,运维人员需要为不同的服务和平台配置环境。这对双方而言,都是一项艰难的任务。
如何解决这个问题呢?
最终程序员们从传统运输业找到了答案。
几十年前,运输业面临着类似的问题。
每一次运输,货主与承运方都会担心因货物类型的不同而导致损失,比如几个铁桶错误地压在了一堆香蕉上。另一方面,运输过程中需要使用不同的交通工具也让整个过程痛苦不堪:货物先装上车运到码头,卸货,然后装上船,到岸后又卸下船,再装上火车,到达目的地,最后卸货。一半以上的时间花费在装、卸货上,而且搬上搬下还容易损坏货物。 这也是一个N x M 的矩阵。
集装箱的发明解决这个难题。
任何货物,无论钢琴还是保时捷,都被放到各自的集装箱中。集装箱在整个运输过程中都是密封的,只有到达最终目的地才被打开。标准集装箱可以被高效地装卸、重叠和长途运输。现代化的起重机可以自动在卡车、轮船和火车之间移动集装箱。集装箱被誉为运输业与世界贸易最重要的发明。
Docker 将集装箱思想运用到软件打包上,为代码提供了一个基于容器的标准化运输系统。
Docker 可以将任何应用及其依赖打包成一个轻量级、可移植、自包含的容器。容器可以运行在几乎所有的操作系统上。
repository 仓库
镜像构建完成后,可以很容易的在当前宿主机上运行,但是,如果需要在其它服务器上使用这个镜像,我们就需要一个集中的存储、分发镜像的服务,Docker Registry 就是这样的服务。
一个 Docker Registry 中可以包含多个 仓库(Repository);每个仓库可以包含多个 标签(Tag);每个标签对应一个镜像。
通常,一个仓库会包含同一个软件不同版本的镜像,而标签就常用于对应该软件的各个版本。我们可以通过 仓库名:标签 的格式来指定具体是这个软件哪个版本的镜像。如果不给出标签,将以 latest 作为默认标签。
以 Ubuntu 镜像 为例,ubuntu 是仓库的名字,其内包含有不同的版本标签,如,16.04, 18.04。我们可以通过 ubuntu:16.04,或者 ubuntu:18.04 来具体指定所需哪个版本的镜像。如果忽略了标签,比如 ubuntu,那将视为 ubuntu:latest
image 镜像
Docker 的镜像概念类似于虚拟机里的镜像,是一个只读的模板,一个独立的文件系统,包括运行容器所需的数据,可以用来创建新的容器。
docker 镜像是一个只读的docker容器模板,它含有启动docker 容器所需的文件系统结构及内容,是启动一个docker 容器的基础。
镜像(Image)是 Docker 最突出的创新。
镜像是容器的基础,每次执行 docker run 的时候都会指定哪个镜像作为容器运行的基础。
docker镜像的文件内容以及一些运行docker 容器的配置文件组成了docker 容器的静态文件系统运行环境 ——— rootfs。
rootfs 是docker 容器在启动时内部进程可见的文件系统,即 docker 容器的根目录。rootfs 通常包含一个操作系统运行时所需的文件系统。
在传统的linux 操作系统内核启动时,首先挂载一个只读的rootfs,当系统检测其完整性以后,再将其切换为读写模式。在docker daemon 为docker 容器挂载rootfs 时,沿用了上述方法,即将rootfs 设为只读模式,挂载完毕后,利用联合挂载(union mount)技术在已有的只读rootfs 上在挂载一个读写层。
镜像的特点:
分层:docker 镜像是采用分层方式构建的,每个镜像都由一系列的“镜像层”组成
写时复制:每个容器启动时不需要单独复制一份镜像文件,而是将所有镜像层以只读的方式挂载到一个挂载点,在其上覆盖一个可读写的容器层。
内容寻址:对镜像内容计算校验和,生成内容哈希,减少冲突。
联合挂载:联合挂载技术可以在一个挂载点同时挂载多个文件系统,将挂载点的原目录与被挂载的内容进行整合,使得最终可见的文件系统将会包含整合之后的各层的文件和目录。
image 镜像内容
将一个镜像导出为 tar 文件再解压后,其中的文件如下
$ docker save -o hello-world.tar hello-world:latest
$ tar -xvf hello-world.tar -C hello-world-image
cdccdf50922d90e847e097347de49119be0f17c18b4a2d98da9919fa5884479d/
cdccdf50922d90e847e097347de49119be0f17c18b4a2d98da9919fa5884479d/VERSION
cdccdf50922d90e847e097347de49119be0f17c18b4a2d98da9919fa5884479d/json
cdccdf50922d90e847e097347de49119be0f17c18b4a2d98da9919fa5884479d/layer.tar
fce289e99eb9bca977dae136fbe2a82b6b7d4c372474c9235adc1741675f587e.json
manifest.json
repositories
1、manifest.json 清单(manifest)文件是一段元数据,描述了该镜像中的内容。
[
{
"Config":"fce289e99eb9bca977dae136fbe2a82b6b7d4c372474c9235adc1741675f587e.json",
"RepoTags":[
"hello-world:latest"
],
"Layers":[
"cdccdf50922d90e847e097347de49119be0f17c18b4a2d98da9919fa5884479d/layer.tar"
]
}
]
2、image-id.json文件
还有个前几位和 image-id 相同的 image-idxxx.json 文件,详细描述了镜像的信息。
3、此外有好多子目录,每个子目录是文件系统的一层(layer),每个子目录里也有一个 json 描述当前层的元数据信息。
容器共享宿主机内核
1、Docker 容器不是虚拟机
Docker 是基于 Linux 的一种操作系统级虚拟化技术(基于 namespace 和 cgroups 实现隔离),它直接复用宿主机(Host)的 Linux 内核。
容器内运行的进程实际上就是宿主机上的进程(只是被隔离起来),所以它们用的内核其实就是宿主机的内核。
容器内看到的 /proc/version, uname -a 等命令看到的内核信息,和宿主机是一致的
2、容器镜像中没有内核
Docker 镜像中只有用户空间的应用和库,没有内核。
启动容器时,镜像只是提供了运行环境(比如 CentOS、Ubuntu 的发行版用户空间),内核还是宿主机的。
Linux 操作系统分为 『内核空间』 和 『用户空间』
- 内核空间:由宿主机提供,容器直接共享宿主机的内核。 Docker 容器只隔离了用户空间,所有容器都共享宿主机的内核空间
- 用户空间:容器镜像里的内容(比如 bash、apt、dpkg、glibc、各种应用和库),和宿主机可以完全不同。容器里的系统工具和库都是来自镜像,不影响内核。
内核负责硬件和进程调度,是所有进程(包括容器内进程)共同用的。
3、内核参数和模块
容器可以看到和使用宿主机加载的内核模块和参数,不能自行加载宿主机没有的内核模块。
Windows 或 Mac 上的 Docker
在 Windows 或 Mac 上跑 Docker,底层其实是通过虚拟机(如 Hyper-V、Apple HyperKit)运行一个 Linux 虚拟机,然后容器跑在这个 Linux 虚拟机上。
这时,容器用的是虚拟机的内核,不是物理主机的内核。
container 容器
镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的 类 和 实例 一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。
容器是一个运行的镜像实例,可以创建、启动、终止、删除它。
一个容器可以连接多个网络和存储。删除容器后,任何未在存储中进行的修改都会消失。
可以这样理解,docker image 是 docker container 的静态视角,docker container 是 docker image 的运行方式。
image和container的区别?
Docker 文件系统
UnionFS 联合文件系统
Union File System, 简称UnionFS,是一种为Linux,FreeBSD,和NetBSD操作系统设计的把其他文件系统联合挂载到一个挂载点的文件系统服务。它通过使用branch把不同文件系统的文件和目录覆盖,形成一个一致的文件系统。这些branch是只读或者只写的。当对文件进行写操作时候,才会真正的复制
文件进行写操作。实际上本身没有对原来的文件进行修改,可以看做是共享了原来的文件。在写的时候进行修改用到了一种资源管理技术成为写时复制。
联合文件系统(Union File System):2004年由纽约州立大学石溪分校开发,它可以把多个目录(也叫分支)内容联合挂载到同一个目录下,而目录的物理位置是分开的。UnionFS允许只读和可读写目录并存,就是说可同时删除和增加内容。UnionFS应用的地方很多,比如在多个磁盘分区上合并不同文件系统的主目录,或把几张CD光盘合并成一个统一的光盘目录(归档)。另外,具有写时复制(copy-on-write)功能UnionFS可以把只读和可读写文件系统合并在一起,虚拟上允许只读文件系统的修改可以保存到可写文件系统当中。
Union文件系统(UnionFS)是一种分层、轻量级并且高性能的文件系统,它支持对文件系统的修改作为一次提交来一层层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统下(unite several directories into a single virtual filesystem)。
使用mount创建一个AUFS文件系统
Linux AUFS 文件系统
https://www.cnblogs.com/sparkdev/p/11237347.html
AUFS
AUFS 的英文全称为 Advanced Mult-Layered Unification Filesystem,之前叫 Another Mult-Layered Unification Filesystem
AUFS(AnotherUnionFS)就是一种 Union FS。 AUFS 支持为每一个成员目录(类似 Git 的分支)设定只读(readonly)、读写(readwrite)和写出(whiteout-able)权限, 同时 AUFS 里有一个类似分层的概念, 对只读权限的分支可以逻辑上进行增量地修改(不影响只读部分的)。
OverlayFS
OverlayFS 是和 AUFS 相似的联合文件系统(union filesystem),它有如下特点:
设计简洁;
内核 3.18 开始已经并入内核主线
可能更快
OverlayFS 将单个 Linux 主机上的两个目录进行分层,然后将它们表示为一个目录。这些目录就叫做 layers,这个过程就被叫做 union mount。OverlayFS 将靠下一层的目录叫做 lowerdir,将靠上一层的叫做 upperdir。然后经过处理后我们看到的那个目录叫做 merged。
Docker 支持的 UFS
Linux 各发行版实现的 UnionFS 各不相同,所以 Docker 在不同 linux 发行版中使用的 UFS 也不同。
Docker 支持几种不同的 UFS 实现,包括 AUFS、Overlay、devicemapper、BTRFS 和 ZFS。哪一个被用看系统需要并且可以通过运行 docker info 来检查,在“Storage Driver”下列出:
$ docker info |grep "Storage"
Storage Driver: overlay2
初代 docker 默认的存储驱动是 AUFS,后来 docker 默认的存储驱动已经演进到了 overlay2
每个容器都有它们自己的文件系统视图,Docker 获取镜像所有的层,并使它们层叠在一起,以呈现为文件系统的一个视图。这个技术称为 Union Mounting,Docker 支持 Linux 上的几个 Union Mount 文件系统,主要是 OverlayFS 和 AUFS。
Docker的文件系统是如何工作的?
Docker镜像是由多个文件系统(只读层)叠加而成。当我们启动一个容器的时候,Docker会加载只读镜像层并在其上(译者注:镜像栈顶部)添加一个读写层。如果运行中的容器修改了现有的一个已经存在的文件,那该文件将会从读写层下面的只读层复制到读写层,该文件的只读版本仍然存在,只是已经被读写层中该文件的副本所隐藏。当删除Docker容器,并通过该镜像重新启动时,之前的更改将会丢失。在Docker中,只读层及在顶部的读写层的组合被称为Union File System(联合文件系统)。
Union 文件系统是 Docker 镜像的基础。镜像可以通过分层来进行继承,基于基础镜像(没有父镜像),可以制作各种具体的应用镜像。
另外,不同 Docker 容器就可以共享一些基础的文件系统层,同时再加上自己独有的改动层,大大提高了存储的效率。
为了能够保存(持久化)数据以及共享容器间的数据,Docker提出了Volume的概念。简单来说,Volume就是目录或者文件,它可以绕过默认的联合文件系统,而以正常的文件或者目录的形式存在于宿主机上。
一个容器中修改了基础镜像是否会影响其他容器?
如果多个容器共享同一个基础镜像,基础镜像被修改,例如 /etc/ 修改,是否会影响?
答案是不会
容器其实是在镜像的最上面加了一层读写层,在运行容器里文件改动时, 会先从镜像里要写的文件复制到容器自己的文件系统中(读写层)。 如果容器删除了,最上面的读写层也就删除了,改动也就丢失了。所以无论多少个容器共享一个镜像,所做的写操作都是从镜像的文件系统中复制过来操作的,并不会修改镜像的源文件,这种方式提高磁盘利用率。 若想持久化这些改动,可以通过 docker commit 将容器保存成新的镜像
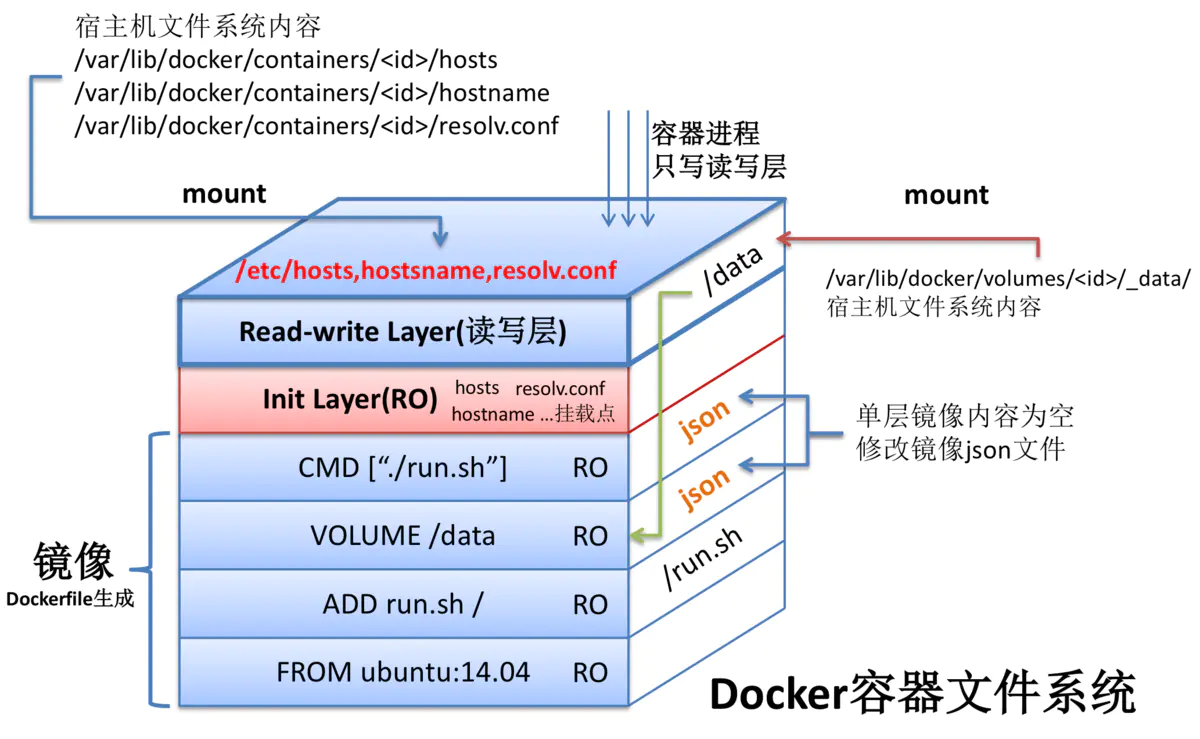
Docker容器文件系统
volume 卷
由于docker 的镜像是由一系列的只读层组合而来,当启动一个容器时,docker 加载镜像的所有只读层,并在最上层加入一个读写层。
这样的设计固然让docker 可以提高镜像构建、储存、分发的效率,节省时间和存储空间,但也导致了一些问题:
- 容器中的文件存在形式复杂,宿主机访问容器的文件很困难。
- 多个容器之间的数据无法共享。
- 容器一旦被删除,容器产生的数据将丢失。
- 数据卷就是为了解决以上问题出现的。volume 是存在于一个或多个容器中的特定文件或文件夹,这个目录以独立于联合文件系统的形式在宿主机中存在,并为数据的共享与持久化提供便利。
volume 在容器创建时就会初始化,所以运行时就可以使用。
在不同容器间共享和重用。
对volume 中数据的操作会马上生效。
对volume 中的数据操作不会影响到镜像本身。
volume 的生存周期独立于容器的生存周期,即使删除容器,volume依然存在,没有任何容器使用它,也不会被docker 删除。
按照 Docker 最佳实践的要求,容器不应该向其存储层内写入任何数据,容器存储层要保持无状态化。所有的文件写入操作,都应该使用 数据卷(Volume)、或者绑定宿主目录,在这些位置的读写会跳过容器存储层,直接对宿主(或网络存储)发生读写,其性能和稳定性更高。
数据卷的生存周期独立于容器,容器消亡,数据卷不会消亡。因此,使用数据卷后,容器删除或者重新运行之后,数据却不会丢失。
数据卷 是被设计用来持久化数据的,它的生命周期独立于容器,Docker 不会在容器被删除后自动删除 数据卷,并且也不存在垃圾回收这样的机制来处理没有任何容器引用的 数据卷。如果需要在删除容器的同时移除数据卷。可以在删除容器的时候使用 docker rm -v 这个命令。
docker Daemon与client
Docker 在运行时分为 Docker 引擎(也就是服务端守护进程)和客户端工具。
Docker 的引擎提供了一组 REST API,被称为 Docker Remote API,而如 docker 命令这样的客户端工具,则是通过这组 API 与 Docker 引擎交互,从而完成各种功能。
因此,虽然表面上我们好像是在本机执行各种 docker 功能,但实际上,一切都是使用的远程调用形式在服务端(Docker 引擎)完成。
也因为这种 C/S 设计,让我们操作远程服务器的 Docker 引擎变得轻而易举。
docker daemon 接受 docker api 的请求,并管理docker 中定义的对象:镜像、容器、网络、数据卷等。
docker client 是大多数人与docker 打交道的工具,比如当你输入docker run命令时,docker client 将命令发到 daemon执行。
docker 网络
Network Overview
https://docs.docker.com/network/
安装 Docker 时,它会自动创建 3 个网络。可以使用 docker network ls 命令列出这些网络。
这 3 个网络包含在 Docker 实现中。运行一个容器时,可以使用 --net 标志指定您希望在哪个网络上运行该容器。您仍然可以使用这 3 个网络。
bridge 网络表示所有 Docker 安装中都存在的 docker0 网络。除非使用 docker run --net=<NETWORK> 选项另行指定,否则 Docker 守护进程默认情况下会将容器连接到此网络。在主机上使用 ifconfig命令,可以看到此网桥是主机的网络堆栈的一部分。
none 网络在一个特定于容器的网络堆栈上添加了一个容器。该容器缺少网络接口。
host 网络在主机网络堆栈上添加一个容器。您可以发现,容器中的网络配置与主机相同。
bridge 即桥接网络,以桥接模式连接到宿主机,即宿主机和容器之间通过 docker0 虚拟网卡连到同一个局域网。bridge是默认的网络模式host 宿主网络,即与宿主机共用网络,这种模式相当于没有网络隔离,好处是和宿主机处于同一网络,可随意访问,都不用-p做端口映射了。none 则表示无网络,容器将无法联网
overlay 跨主机网络。
在早期的docker版本中,是不支持跨主机通信网络驱动的,也就是说明如果容器部署在不同的节点上面,只能通过暴露端口到宿主机上,再通过宿主机之间进行通信。
docker 1.9 之后,随着docker swarm集群的推广,docker也有了自家的跨主机通信网络驱动,名叫overlay,overlay网络模型是swarm集群容器间通信的载体,将服务加入到同一个网段上的Overlay网络上,服务与服务之间就能够通信。
bridge
Use bridge networks
https://docs.docker.com/network/bridge/
安装 Docker 的时候,会在宿主机安装一个虚拟网卡 docker0, 它在内核层连通了其他的物理或虚拟网卡,这就将所有容器和本地主机都放到同一个物理网络。
$ ifconfig
docker0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
inet6 fe80::42:88ff:fe56:8251 prefixlen 64 scopeid 0x20<link>
ether 02:42:88:56:82:51 txqueuelen 0 (Ethernet)
RX packets 915966 bytes 2933746454 (2.7 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 875092 bytes 62233810 (59.3 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
Docker 默认指定了 docker0 接口 的 IP 地址和子网掩码,让主机和容器之间可以通过网桥相互通信。例如Linux下一般是 172.17.0.1 , 并不固定。
它还给出了 MTU(接口允许接收的最大传输单元),通常是 1500 Bytes,或宿主主机网络路由上支持的默认值。
这些值都可以在服务启动的时候进行配置。
host
Use host networking
https://docs.docker.com/network/host/
host 网络和主机之间没有隔离,和主机共享一个 network namespace.
注意:使用 host 网络模式时,端口映射不起作用。 docker run 时的 -p, --publish, -P, --publish-all 参数会被忽略,并产生一条警告:
WARNING: Published ports are discarded when using host network mode
Mac和Windows上没有host网络
host 类型网络只能在 Linux 上使用, 在 Mac 和 Windows 上不支持。
The host networking driver only works on Linux hosts, and is not supported on Docker Desktop for Mac, Docker Desktop for Windows, or Docker EE for Windows Server.
Mac中主机和容器网络互通解决方案
1、容器内访问宿主机
使用 docker.for.mac.host.internal 或者 host.docker.internal 这两个特定域名可访问宿主机,这是 docker 容器内配置好的可解析到宿主机 IP 的 DNS, 可以直接当宿主机的 IP 使用。
进入任意容器后,ping 这两个域名都会解析到宿主机 IP
2、宿主机访问容器
通过 -p 端口映射。
例如 docker run -p 8081:80 -d nginx
之后在主机上通过 localhost:8081 可直接访问容器内的 80 端口
Networking features in Docker Desktop for Mac
https://docs.docker.com/docker-for-mac/networking/
docker-proxy
docker-proxy 是 dockerd 的子进程,用于端口映射。
docker-proxy 主要是用来做端口映射的。当我们使用 docker run 命令启动容器时,如果使用了 -p 参数,docker-proxy 组件就会把容器内相应的端口映射到主机上来,底层是依赖于 iptables 实现的。
https://learn.lianglianglee.com/专栏/由浅入深吃透%20Docker-完/11%20%20组件组成:剖析%20Docker%20组件作用及其底层工作原理.md
根据 docker-proxy 端口占用找对应容器
1、netstat -anp 查看端口占用看到是 docker-proxy 进程,获取 pid
2、ps -ef|grep pid 查看进程命令,看到是监听宿主机 8080 端口转发到 192.168.42.2 容器的 8080 端口
root 75958 11931 0 Aug21 ? 00:00:00 /usr/local/bin/docker-proxy -proto tcp -host-ip 0.0.0.0 -host-port 8080 -container-ip 192.168.42.2 -container-port 8080
3、docker ps |grep 8080 端口,能看到是哪个容器在使用 8080 端口
4、docker inspect container-id |grep IPAddress 能看到使用 8080 端口的容器的 ip 就是 192.168.42.2
Docker 原理
chroot 隔离文件系统
namespace 隔离进程访问
cgroups 隔离资源使用
docker 并不是彻底的虚拟化,不同容器之间会共享内核。
Linux 虚拟机是完全的虚拟化,内核隔离。
chroot
Linux Namespace
DOCKER基础技术:LINUX NAMESPACE(上)
https://coolshell.cn/articles/17010.html
Linux CGroup
Linux CGroup 全称 Linux Control Group, 是 Linux 内核的一个功能,用来限制,控制与分离一个进程组群的资源(如CPU、内存、磁盘输入输出等)
CGroup 主要提供了如下功能:
Resource limitation: 限制资源使用,比如内存使用上限以及文件系统的缓存限制。
Prioritization: 优先级控制,比如:CPU利用和磁盘IO吞吐。
Accounting: 一些审计或一些统计,主要目的是为了计费。
Control: 挂起进程,恢复执行进程。
容器 request/limit 利用 cgroup cpu 公平调度器实现。
DOCKER基础技术:LINUX CGROUP
https://coolshell.cn/articles/17049.html
下一篇 Hexo博客(30)放弃Hexo
页面信息
location:protocol: host: hostname: origin: pathname: href: document:referrer: navigator:platform: userAgent: