Apache-Kafka
Kafka 使用笔记
Matt’s Blog - kafka 源码解析相关文章
https://matt33.com/tags/kafka/
huxihx - kafka源码分析等
https://www.cnblogs.com/huxi2b/tag/Kafka/
Kafka 配置
CONFIGURATION
https://kafka.apache.org/documentation/#configuration
Broker 配置
3.1 Broker Configs
https://kafka.apache.org/documentation/#brokerconfigs
auto.create.topics.enable:true
https://kafka.apache.org/27/documentation.html#brokerconfigs_auto.create.topics.enable
kafka 默认就是自动创建 topic 的,在 kafka server.properties 配置中auto.create.topics.enable 默认为 true,表示如果主题不存在,则自动创建主题,分区数量由 kafka server.properties 配置文件中 num.partitions 指定,默认是 1
num.partitions:1
https://kafka.apache.org/27/documentation.html#brokerconfigs_num.partitionsnum.partitions 默认值 1,如果创建 topic 时没有给出划分 partitions 个数,这个数字将是 topic 下 partitions 数目的默认数值。
offsets.retention.minutes:10080
当消费组内的所有消费者都消失后,此消费组的 offset 将保存这么长时间后被忽略,默认值是 7 天。
对于手动 assignment 的 standalone 单独消费者,offset 将在最后一次提交加上此时间后过期。
offsets.retention.check.interval.ms:600000
扫描过期 offset 的时间间隔,默认 600 秒,即 10 分钟
offsets.topic.num.partitions:50
保存消费组 offset 等信息的 kafka 内部 topic __consumer_offsets 的 partition 个数,默认 50
offsets.topic.replication.factor:3
保存消费组 offset 等信息的 kafka 内部 topic __consumer_offsets 的 副本个数,默认值 3
Producer 生产者配置(在使用方服务中配置)
3.3 Producer Configs
https://kafka.apache.org/documentation/#producerconfigs
bootstrap.servers:””
kafka 集群地址
格式:host1:port1,host2:port2,...
例如:192.168.1.101:9092,192.168.1.102:9092,192.168.1.103:9092
key.serializer
实现了 org.apache.kafka.common.serialization.Serializer 接口的 key 序列化类
value.serializer
实现了 org.apache.kafka.common.serialization.Serializer 接口的 value 序列化类
retries:2147483647
Producer 发送失败时重试 retry 次数。
security.protocol:PLAINTEXT
与brokers通信的安全协议
取值范围:PLAINTEXT, SSL, SASL_PLAINTEXT, SASL_SSL
我们用的是 SASL_PLAINTEXT
sasl.mechanism:GSSAPI
我们用的是 PLAIN
sasl.jaas.config
producerProps.put("sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"" + username + "\" password=\"" + password + "\";");
partitioner.class 生产者分区器
默认值:org.apache.kafka.clients.producer.internals.DefaultPartitioner
DefaultPartitioner 默认分区器(hash)
hash:由消息所提供的 key 来进行 hash,然后分发到对应的partition。这是默认使用的partition机制。
从 Kafka 2.4.0 开始,DefaultPartitioner 使用黏着分区策略,也就是,在同一个 batch 批量里 key 是 null 的消息都会被发送到同一个 partition. 等新的 batch 创建后,会再次选择新的 partition. 这种策略会减少生产延时,但在 key 全是 null 的边缘场景下可能导致 partition 间分配不均。
自定义分区器
实现 org.apache.kafka.clients.producer.Partitioner 接口可自定义分区器,并在配置中用参数 partitioner.class 指定这个实现。
request.timeout.ms:30000
收到响应前客户端等待的最大超时时长(毫秒),默认30秒。时间到后如果未收到响应,客户端会选择重传或标为失败。
此配置值应大于 broker 配置 replica.lag.time.max.ms 以避免消息重复
max.request.size:1048576
https://kafka.apache.org/27/documentation.html#producerconfigs_max.request.size
kafka 请求体最大值,单位 bytes,如果是批量发送则是多个消息总和的最大值
默认值:1048576,即 1MB
RecordTooLargeException
曾经出现过 kafka 消息体中有多个背景图base64,单个消息体大小超过 1MB 导致发送失败,报错:
org.apache.kafka.common.errors.RecordTooLargeException: The message is 10151950 bytes when serialized which is larger than 1048576, which is the value of the max.request.size configuration.
Consumer 消费者配置
3.4 Consumer Configs
https://kafka.apache.org/documentation/#consumerconfigs
bootstrap.servers:””
kafka集群地址
格式:host1:port1,host2:port2,...
例如:192.168.1.101:9092,192.168.1.102:9092,192.168.1.103:9092
group.id:””
消费组id
security.protocol:PLAINTEXT
和brokers之间通信的安全协议,可取以下值:
PLAINTEXT, SSL, SASL_PLAINTEXT, SASL_SSL
sasl.mechanism:GSSAPI
客户端连接的sasl机制
sasl.jaas.config:null
SASL JAAS 配置文件
例如kafka.conf
KafkaClient {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="admin"
password="admin";
};
enable.auto.commit:true
是否启用自动提交
auto.commit.interval.ms:5000
自动提交offset的时间间隔,当 enable.auto.commit 为true时才起作用
session.timeout.ms:10000
会话超时时间,就是说如果发送心跳时间超过这个时间,broker就会认为消费者死亡了,默认值是10000ms,也就是10s(这个值一般默认没问题)
max.poll.interval.ms:300000
两次 poll 消息之间的最大间隔
假如消息处理太慢,两次 poll 之间时间差超过 max.poll.interval.ms 毫秒值,broker 就认为这个消费者挂了,就会把它从组内删除,并且重新平衡,把 partition 分配给组内的其他消费者。
kafka 0.10.0.0 或之前版本中,尚未提供 max.poll.interval.ms 参数,因此 session.timeout.ms 既用于失败检测,也用于控制消息处理时间,同时还承担着rebalance过程的超时控制。
在 0.10.1.0 版本时社区对该参数的含义进行了解耦,推出了 max.poll.interval.ms 参数。
实际上,在 0.10.1.0.0 或之后的版本中,作者推荐用户将 session.timeout.ms 设置一个很小的值,比如5s,但需要把 max.poll.interval.ms 设置成平均的消息处理时间。举个例子,假设你一次 poll 调用返回的消息数是N,你处理每条消息的平均时间是t0,那么你需要设置 max.poll.interval.ms 稍稍大于 N * t0 以保证 poll 调用间隔不会超过该阈值。
max.poll.records:500
一次从kafka中poll出来的数据最大值
heartbeat.interval.ms:3000
这个值是心跳时间,表示消费组多长时间向broker报告一次,这个默认值3000ms,这个值官方推荐不要高于session.timeout.ms 的1/3(这个值默认没问题)
auto.offset.reset:latest
只能是以下三个值之一:
earliest当各分区下有已提交的 offset 时,从提交的 offset 开始消费;无提交的 offset 时,从头开始消费latest当各分区下有已提交的 offset 时,从提交的 offset 开始消费;无提交的 offset 时,消费新产生的该分区下的数据nonetopic 各分区都存在已提交的 offset 时,从 offset 后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
这个配置只有在当前无法获取到有效的 offset 时才生效,有两种情况:
一、全新的group;
二、已存在的group, 但很久没有提交过offset, 其保存在 __consumer_offsets 里的信息将被compact并最终清除掉;
Kafka auto.offset.reset值详解
https://blog.csdn.net/lishuangzhe7047/article/details/74530417
Kafka重置消费的Offset
https://www.jianshu.com/p/2945a90b48af
kafka 0.10.1一些使用经验
https://www.jianshu.com/p/32f1f16af937
partition.assignment.strategy 消费者分区分配策略
partition.assignment.strategy
https://kafka.apache.org/documentation/#consumerconfigs_partition.assignment.strategy
一个分区分配策略类列表,优先级按顺序依次降低。客户端根据此策略决定如何将 partition 分配给消费者实例。
接收消息的顺序只能保证一个 partition 之内是有序的,一个 consumer 接收多个 partition 的话是无法保证消息全局有序的,即 consumer 接收的消息的顺序可能跟 producer 发送的顺序不同。
RangeAssignor(默认)
org.apache.kafka.clients.consumer.RangeAssignor 默认分区分配策略
对于每个topic,会将 topic 的 partition 编上序号排好序,然后 consumer 线程以字典序排序。然而把 partition 的总数除以 consumer 线程的总数来决定分配给每个线程的 partition 数目。如果无法除尽,将余数再均分给排序靠前的几个线程,即这些线程都会多出额外的一个partition。
RoundRobinAssignor
org.apache.kafka.clients.consumer.RoundRobinAssignor
round-robin:这个策略把所有partition和所有consumer线程都列出来。然后它以循环制分配partition给线程。如果所有consumer实例的订阅是相同的,那么partition会均匀分布。
这个分配策略只有当以下情况成立时才可用:
a.每个topic在一个consumer实例中有同样的stream数目。
b.在group中的每个consumer实例订阅的topic的集合是相同的。
如果所有consumer实例有相同的consumer group,那么这个就像传统的队列,负载均衡到所有consumer上。假如多个consumer实例都有多个线程,且属于同一个group,那么一个topic的所有partition会均匀分配给所有线程。
StickyAssignor
org.apache.kafka.clients.consumer.StickyAssignor
sticky中文意思是粘的,粘性的。在kafka这里,是为了保证再分配的结果尽可能多的保有现有分配。
CooperativeStickyAssignor
org.apache.kafka.clients.consumer.CooperativeStickyAssignor
自定义策略
实现抽象类 org.apache.kafka.clients.consumer.ConsumerPartitionAssignor 可自定义分片策略
Kafka 使用
Java 中使用 kafka
Java Kafka 发送消息示例
KafkaProducer 官方 apidoc 和使用示例
https://kafka.apache.org/36/javadoc/org/apache/kafka/clients/producer/KafkaProducer.html
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++) {
producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i)));
}
producer.close();
Java Kafka 消费消息手动commit示例(带sasl配置)
package com.masikkk.kafka;
import com.google.common.collect.Lists;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
public class MyKafkaConsumer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("bootstrap.servers", "192.168.1.101:9092,192.168.1.102:9092,192.168.1.103:9092");
//设置不自动提交,自己手动更新offset
properties.put("enable.auto.commit", "false");
// 从最新offset开始消费
properties.put("auto.offset.reset", "latest");
//properties.put("auto.offset.reset", "earliest");
properties.put("session.timeout.ms", "30000");
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 消费组
properties.put("group.id", "com-masikkk-kafka-group-test");
properties.put("auto.commit.interval.ms", "100000");
// 认证
properties.put("security.protocol", "SASL_PLAINTEXT");
properties.put("sasl.mechanism", "PLAIN");
properties.put("sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"admin\" password=\"admin\";");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
// 订阅topic消费,自动分配分区
consumer.subscribe(Lists.newArrayList("com-masikkk-kafka-topic-test"));
// 手动指定topic和分区消费
consumer.assign(Arrays.asList(new TopicPartition(topic,2), new TopicPartition(topic,1)));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
if (records.isEmpty()) {
System.out.print("null ");
continue;
}
for (ConsumerRecord<String, String> record: records) {
System.out.println("topic = " + record.topic() + ", partition = " + record.partition() + ", offset = " + record.offset() + ", value = " + record.value());
consumer.commitSync();
}
}
}
}
java自己手动控制kafka的offset
https://blog.csdn.net/qq_20641565/article/details/64440425
Kafka启用SASL_PLAINTEXt动态配置JAAS文件的几种方式
https://blog.csdn.net/russle/article/details/81041135
Kafka Java Client 生产者分区选择策略
跟进 producer.send() 看源码,最终能看到
int partition = this.partition(record, serializedKey, serializedValue, cluster);
private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) {
Integer partition = record.partition();
return partition != null ? partition : this.partitioner.partition(record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);
}
所以
如果 ProducerRecord 消息中指定了 partition 编号,则直接使用
否则使用分区器 partitioner.partition() 选择分区,默认分区器是 DefaultPartitioner.class
源码为:
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
即
如果 key 不是 null, 使用 murmur2 hash 算法计算 key 的 hash 值,和 topic 的分区总数取模
如果 key 是 null, 用此 topic 的上个分区选择自增数+1,然后和 topic 的分区总数取模
指定partition消费
消费者有一处需要特别注意
// 订阅topic消费,自动分配分区
consumer.subscribe(Lists.newArrayList("com-masikkk-kafka-topic-test"));
指定消费模式为指定topic,由kafka指定partition分配策略,
与
// 手动指定topic和分区消费
consumer.assign(Arrays.asList(new TopicPartition(topic,2), new TopicPartition(topic,1)));
由用户自定义partition分配策略。
对kafka而言是互斥的,二者只能指定其一,前者后者
KafkaEmbedded kafka单元测试
Spring Kafka - Embedded Unit Test Example
https://www.codenotfound.com/spring-kafka-embedded-unit-test-example.html
code-not-found/spring-kafka
https://github.com/code-not-found/spring-kafka
Simple embedded Kafka test example with spring boot
https://stackoverflow.com/questions/48753051/simple-embedded-kafka-test-example-with-spring-boot
Kafka 安装
Kafka 版本
查看kafka版本
kafka 没有提供 version 命令,可以进入 kafka/libs 文件夹,看相关的 jar 包版本。
Mac 上 brew 安装的 kafka 可以进入目录 /usr/local/Cellar/kafka/2.1.0/libexec/libs
找到 kafka_2.13-2.7.0.jar
其中 2.13 是 Scala 版本,2.7.0 是 Kafka 版本。
Kafka 2.8.0 不再需要zk
2021年4月19日,Kafka 2.8.0 版本发布,
kafka通过自我管理的仲裁来替代ZooKeeper,通俗的说,Kafka将不再需要ZooKeeper
Kafka 3.0.0 开始将java8标为废弃
https://blogs.apache.org/kafka/date/20210921
Kafka 3.0.0 开始 java 8 被标为废弃(deprecated),4.0 开始正式移除(remove)
Support for Java 8 is deprecated across all components of the Apache Kafka project in 3.0. This will give users time to adapt before the next major release (4.0), when Java 8 support is planned to be removed.
Docker 安装部署 kafka
Docker 安装 zookeeper
1、拉取 zookeeper:3.4.14 镜像
docker pull zookeeper:3.4.14
2、启动zk容器, 映射出 2181 端口
docker run -d --rm \
-p 2181:2181 \
--name zookeeper \
zookeeper:3.4.14
解释下:-d 后台运行--rm 停止容器后删掉容器文件-p 2181:2181 将容器的2181端口映射到主机的2181端口--name zookeeper 指定启动的容器名,方便按名称stop等操作
3、验证zkdocker exec -it zookeeper bash 进入zk容器
进入 /zookeeper-3.4.14/bin 目录,用目录下的 ./zkCli.sh 脚本连接本机zk
# ./zkCli.sh
Connecting to localhost:2181
2021-05-25 13:44:08,314 [myid:] - INFO [main:Environment@100] - Client environment:zookeeper.version=3.4.14-4c25d480e66aadd371de8bd2fd8da255ac140bcf, built on 03/06/2019 16:18 GMT
...
Welcome to ZooKeeper!
ls / 看根节点
[zk: localhost:2181(CONNECTED) 3] ls /
[zookeeper, kafka-manager, kafka]
Docker 安装 kafka
1、拉取 kafka 镜像,kafka 没有官方镜像,多数都用 wurstmeister 封装的
docker pull wurstmeister/kafka
2、启动kafka,映射出 9092 端口
docker run -d --rm \
--name kafka \
-p 9092:9092 \
-e KAFKA_BROKER_ID=0 \
-e KAFKA_ZOOKEEPER_CONNECT=172.24.220.146:2181/kafka \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://172.24.220.146:9092 \
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
-e TZ="Asia/Shanghai" \
wurstmeister/kafka
-e KAFKA_BROKER_ID=0 在 kafka 集群中每个 broker 都有一个唯一的 BROKER_ID 来区分自己-e KAFKA_ZOOKEEPER_CONNECT=172.24.220.146:2181/kafka 连接的 zk 地址。注意这里的子目录 /kafka 可自定义,不加子目录也可以,但都放到 zk 根目录有点儿乱。这里如果加了子目录,则后续的 kafka-manager 连接,kafka-topics 等工具的 --zookeeper 参数都需要加子目录-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://172.24.220.146:9092 kafka 的地址和端口,用于向 zookeeper 注册-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 kafka 的监听端口
3、验证docker exec -it kafka bash 进入 kafka 容器
进入 /opt/kafka_2.13-2.7.0/bin 目录,kafka 的所有工具脚本都在这里
发消息:
使用 kafka-console-producer.sh 脚本发消息,指定 broker 和 topic, topic 如果不存在会自动创建。
./kafka-console-producer.sh --broker-list localhost:9092 --topic masikkk-test-topic
出现 > 后,输入任何内容回车就发送了。
发完后 Ctrl+C 退出
收消息:
使用 kafka-console-consumer.sh 脚本接收消息,指定 broker, topic, 起始位置,执行后立即就能收到刚才发的消息。
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic masikkk-test-topic --from-beginning
Mac 使用 Docker 安装 kafka 遇到的问题
在 Mac 上通过 docker 安装 kafka
Mac不支持host主机网络
为了方便在本机直接通过 localhost 访问,一开始我想用主机网络 --network host 启动 zookeeper 和 kafka, 但是发现 Mac 不支持 docker 的主机网络方式。
Use host networking
https://docs.docker.com/network/host/
使用host.docker.internal访问宿主机
后来改为使用 docker.for.mac.host.internal 或者 host.docker.internal 代替宿主机 ip 实现容器内访问宿主机, 这是 docker 容器内配置好的可解析到宿主机 IP 的 DNS, 详见 https://docs.docker.com/docker-for-mac/networking/
docker run -d --rm \
--name kafka \
-p 9092:9092 \
-e KAFKA_BROKER_ID=0 \
-e KAFKA_ZOOKEEPER_CONNECT=docker.for.mac.host.internal:2181/kafka \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://docker.for.mac.host.internal:9092 \
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
wurstmeister/kafka
启动后利用 kafka 自带的 kafka-console-producer.sh 和 kafka-console-consumer.sh 脚本发送接收消息都没有问题。
java.net.UnknownHostException: docker.for.mac.host.internal
使用 host.docker.internal 代替宿主机 ip 启动的 kafka 镜像虽然通过脚本发送接收消息无问题,但通过 Spring Boot 连接后报错,无法识别 docker.for.mac.host.internal
2021-05-26 16:45:31.391 [kafka-admin-client-thread | adminclient-1] WARN org.apache.kafka.clients.NetworkClient.initiateConnect:950 - [AdminClient clientId=adminclient-1] Error connecting to node docker.for.mac.host.internal:9092 (id: 0 rack: null)
java.net.UnknownHostException: docker.for.mac.host.internal
at java.net.InetAddress.getAllByName0(InetAddress.java:1281)
最终改为指定本地 Mac 电脑的具体 IP 启动 kafka 解决
docker run -d --rm \
--name kafka \
-p 9092:9092 \
-e KAFKA_BROKER_ID=0 \
-e KAFKA_ZOOKEEPER_CONNECT=172.24.196.145:2181/kafka \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://172.24.196.145:9092 \
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
wurstmeister/kafka
缺点是:每次 Mac IP 发生变化后,还要用新的 IP 重启 kafka 容器。
zookeeper中查看kafka相关节点
假定 zookeeper.connect=localhost:2181/kafka, 即所有 kafka 相关内容都注册到 zk 的 /kafka 子目录。
docker exec -it zookeeper sh 进入 zk 容器
进入 /zookeeper-3.4.14/bin 目录,用目录下的 ./zkCli.sh 脚本连接本机zk
[zk: localhost:2181(CONNECTED) 2] ls /kafka
[cluster, controller_epoch, controller, brokers, feature, admin, isr_change_notification, consumers, log_dir_event_notification, latest_producer_id_block, config]
[zk: localhost:2181(CONNECTED) 2] ls /kafka/brokers
[ids, topics, seqid]
[zk: localhost:2181(CONNECTED) 3] ls /kafka/brokers/topics
[masikkk-test-topic, __consumer_offsets, alert-push-topic]
[zk: localhost:2181(CONNECTED) 8] get /kafka/brokers/topics/masikkk-test-topic
{"version":2,"partitions":{"0":[0]},"adding_replicas":{},"removing_replicas":{}}
cZxid = 0x62
ctime = Wed May 26 10:57:35 UTC 2021
mZxid = 0x62
mtime = Wed May 26 10:57:35 UTC 2021
pZxid = 0x63
cversion = 1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 80
numChildren = 1
[zk: localhost:2181(CONNECTED) 15] get /kafka/brokers/topics/masikkk-test-topic/partitions/0/state
{"controller_epoch":3,"leader":0,"version":1,"leader_epoch":0,"isr":[0]}
cZxid = 0x65
ctime = Wed May 26 10:57:35 UTC 2021
mZxid = 0x65
mtime = Wed May 26 10:57:35 UTC 2021
pZxid = 0x65
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 72
numChildren = 0
Mac Brew 安装启动 Kafka
brew install kafka 安装 kafka,安装过程会自动安装 zookeeper
Intel Mac 安装 kafka 2.5.0 及 Zookeeper
2.8.0 之前,kafka 使用 zookeeper 管理,安装过程会自动安装 zookeeper
Intel Mac 安装目录 /usr/local/Cellar/kafka/2.5.0
配置文件目录:/usr/local/etc/kafka
工具脚本目录 /usr/local/Cellar/kafka/2.5.0/libexec/bin
kafka是基于zookeeper的,启动kafka之前,需要先启动zookeeper
启动zookeeper:brew services start zookeeper
后台启动kafka:brew services start kafka
前台启动kafka:zookeeper-server-start /usr/local/etc/kafka/zookeeper.properties & kafka-server-start /usr/local/etc/kafka/server.properties
M1 Mac 安装 kafka 3.1.0 及 Zookeeper
M1 Mac 安装目录:
- zk:/opt/homebrew/Cellar/zookeeper/3.7.0_1
- kafka:/opt/homebrew/Cellar/kafka/3.1.0
后台启动 kafka: brew services start kafka
前台启动 kafka: /opt/homebrew/opt/kafka/bin/kafka-server-start /opt/homebrew/etc/kafka/server.properties
2022年3月11日,M1 Mac 上已验证直接 brew install kafka 安装的 kafka 和 Zookeeper 都可正常使用
启动验证 Zookeeper
1、启动zk: brew services start zookeeper
2、任意目录执行 zkCli 连接 localhost:2181 进入 zk,通过 homebrew 安装 zk 时已将可执行程序 zkCLi 拷贝到 /opt/homebrew/bin 目录,此目录在 $PATH 中,可直接访问
执行 ls / 有结果即可
[zk: localhost:2181(CONNECTED) 1] ls /
[zookeeper]
启动验证 kafka
1、kafka server 配置在 /opt/homebrew/etc/kafka/server.properties 中,默认不需要修改
listeners 默认监听 localhost:9092 和 本机ip:9092,改为 PLAINTEXT://0.0.0.0:9092 还可监听 127.0.0.1
zookeeper.connect=localhost:2181 默认连接 localhost:2181 的 zk
2、brew services start kafka 启动 kafka
通过 homebrew 安装 kafka 时已将 kafka 自带的工具脚本拷贝到 /opt/homebrew/bin 目录,此目录在 $PATH 中,可直接访问
3、发送消息
使用 kafka-console-producer 脚本发消息,指定 broker 和 topic, topic 如果不存在会自动创建。
kafka-console-producer --broker-list localhost:9092 --topic masikkk-test-topic
>masikkk
4、接收消息
使用 kafka-console-consumer 脚本接收消息,指定 broker, topic, 起始位置,执行后立即就能收到刚才发的消息。
kafka-console-consumer --bootstrap-server localhost:9092 --topic masikkk-test-topic --from-beginning
masikkk
5、查看 topic
kafka-topics --bootstrap-server localhost:9092 --list
__consumer_offsets
masikkk-test-topic
brew kafka service error 启动错误
问题:
brew 启动 kafka 后,brew services list 查看服务状态
kafka error 256 masi ~/Library/LaunchAgents/homebrew.mxcl.kafka.plist
排查:
不太好查看错误日志,直接改用前台启动 kafka
/opt/homebrew/opt/kafka/bin/kafka-server-start /opt/homebrew/etc/kafka/server.properties
报错:
[2022-08-22 15:50:33,447] ERROR Exiting Kafka due to fatal exception (kafka.Kafka$)
java.lang.IllegalArgumentException: requirement failed: advertised.listeners cannot use the nonroutable meta-address 0.0.0.0. Use a routable IP address.
解决:
advertised.listeners 配置改为:
advertised.listeners=PLAINTEXT://localhost:9092
@@HOMEBREW_JAVA@@ No such file or directory
执行 kafka 自带工具脚本脚本报错如下:
# kafka-console-producer --broker-list localhost:9092 --topic masikkk-test-topic
/opt/homebrew/Cellar/kafka/3.1.0/libexec/bin/kafka-run-class.sh: line 342: /opt/homebrew/etc/kafka/@@HOMEBREW_JAVA@@/bin/java: No such file or directory
/opt/homebrew/Cellar/kafka/3.1.0/libexec/bin/kafka-run-class.sh: line 342: exec: /opt/homebrew/etc/kafka/@@HOMEBREW_JAVA@@/bin/java: cannot execute: No such file or directory
解决:
执行 HOMEBREW_BOTTLE_DOMAIN= brew reinstall kafka 可能需要再代理环境下才能成功
brew bottle command replaces JAVA_HOME path with @@HOMEBREW_JAVA@@
https://github.com/Homebrew/discussions/discussions/2530
Linux 裸机部署 Kafka
官网下载 Binary tgz 包
https://kafka.apache.org/downloads
安装启动kafka内置zookeeper
kafka 安装包内自带 zookeeper, 只是测试用的话不需要单独去下载zk,直接启动内置zk即可, 当然生产环境建议独立安装 zk 集群后再部署 kafka
进入解压后的 kafka 安装包,编辑 config/zookeeper.properties 中的 clientPort 可修改 zk 启动的端口号,默认 2181
# the port at which the clients will connect
clientPort=2181
然后启动 zknohup ./bin/zookeeper-server-start.sh config/zookeeper.properties 1>/dev/null 2>&1 &
停止 zk sh bin/zookeeper-server-stop.sh
安装启动kafka
编辑 config/server.properties 修改 kafka server 配置,常用配置项:zookeeper.connect=localhost:2181 表示连接的zk地址和端口号listeners = PLAINTEXT://your.host.name:9092 启动 kafka 服务监听的 ip 和端口,可以监听内网 ip 和 0.0.0.0(不能为外网ip),默认为 java.net.InetAddress.getCanonicalHostName() 获取的ip。advertised.listeners=PLAINTEXT://your.host.name:9092 生产者和消费者连接的地址,kafka会把该地址注册到zookeeper中,所以只能为除0.0.0.0之外的合法ip或域名 ,默认和listeners的配置一致。
然后启动 kafkanohup ./bin/kafka-server-start.sh config/server.properties 1>/dev/null 2>&1 &
停止 kafka sh bin/kafka-server-stop.sh
默认 server.properties 配置内容
apache / kafka
kafka/config/server.properties
https://github.com/apache/kafka/blob/trunk/config/server.properties
# The address the socket server listens on. It will get the value returned from
# java.net.InetAddress.getCanonicalHostName() if not configured.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://:9092
# Hostname and port the broker will advertise to producers and consumers. If not set,
# it uses the value for "listeners" if configured. Otherwise, it will use the value
# returned from java.net.InetAddress.getCanonicalHostName().
advertised.listeners=PLAINTEXT://your.host.name:9092
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=localhost:2181
Kafka 工具
kafka-map
dushixiang / kafka-map
https://github.com/dushixiang/kafka-map/blob/master/README-zh_CN.md
可管理topic,重置offset,发送、查看消息,非常强大,比 kafka-manager 好用多了。
M1 Mac Docker 安装 kafka-map
1、拉取镜像 docker pull dushixiang/kafka-map
2、启动容器
docker run -d --rm \
-p 8089:8080 \
-v /var/kafka-map/data:/usr/local/kafka-map/data \
-e DEFAULT_USERNAME=admin \
-e DEFAULT_PASSWORD=admin \
--name kafka-map \
dushixiang/kafka-map:latest
M1 Mac 上启动时提示
WARNING: The requested image’s platform (linux/amd64) does not match the detected host platform (linux/arm64/v8) and no specific platform was requested
但没关系,可正常使用
启动报错
docker: Error response from daemon: Mounts denied:
The path /opt/kafka-map/data is not shared from the host and is not known to Docker.
原因:
Mac 系统上的 /opt 目录默认并没有暴露给 Docker for Mac,默认只暴露了 /Users, /Volumes, /private, /tmp, /var/folders,可在 Docker for Mac 设置 -> Resources -> File Sharing 中配置
解决:
创建目录 /var/kafka-map/data ,将启动命令里的 /opt/kafka-map/data 改为 /var/kafka-map/data
http://localhost:8089/
admin/admin 登录
点 Import Cluster,Broker Servers:填入 ip:9092,如果是 kafka 集群,填入逗号分割的 brokers 列表
查看 kafka 数据:
选择 topic -> xx-topic -> Consume Message
Offset Explorer(Kafka Tool)
Offset Explorer(之前叫 Kafka Tool)
https://www.kafkatool.com/index.html
Java 写的 kafka 客户端,虽然界面看起来很老旧,但功能全面,方便好用。
由于是运行在 JVM 中,无需担心是否适配 M1 版 Mac,实测 M1 Mac 可直接下载 Mac 版安装包运行没问题。
连接 kafka broker:
可以只输入 kafka broker 地址连接,配置 Advanced -> Bootstrap servers,填入 ip:9092,如果是 kafka 集群,填入逗号分割的 brokers 列表
查看 kafka 数据
设置 -> topics -> key 和 value content type 都设置为 String(默认是 Byte Array)后可直接查看消息内容,也可以在具体某个 topic -> properties 上配置 key 和 value 的格式后点 update 更新。
选择 topics -> xx-topic -> Data 标签,点击 retrieve messages 按钮可拉取消息,消息还可以直接 json 格式化查看
发送 kafka 数据
点开具体的 partition 点击加号 Add Message 即可
kafka-manager
kafka-manager
https://github.com/yahoo/kafka-manager
安装 kafka-manager, 现在叫 CMAK (Cluster Manager for Apache Kafka)
下载 cmak-3.0.0.5.zip 包
https://github.com/yahoo/CMAK/releases
kafka集群管理工具kafka-manager部署安装
https://www.jianshu.com/p/c24ed08dfa63
Apache Kafka 入门 - Kafka-manager的基本配置和运行
https://blog.csdn.net/isea533/article/details/73727485
Intel Mac Docker 安装 kafka-manager
1、本地启动 zookeeper
拉取 zookeeper:3.4.14 镜像: docker pull zookeeper:3.4.14
启动 zookeeper 容器, 映射出 2181 端口
docker run -d --rm \
-p 2181:2181 \
--name zookeeper \
zookeeper:3.4.14
2、本地启动 kafka-manager
拉取 kafka-manager 镜像:docker pull sheepkiller/kafka-manager
启动 kafka-manager 容器:
docker run -d --rm \
--name kafka-manager \
-p 9000:9000 \
-e ZK_HOSTS=172.24.220.146:2181 \
sheepkiller/kafka-manager
注意:
- 这里的 zk 地址是 kafka-manager 用于存储配置信息的,不一定和要连接的目标 kafka 集群使用同一zk
- 由于 Mac 没有主机网络,这里即使连本地 zk 也不能填 localhost,得填自己 Mac 的 ip
M1 Mac Docker 安装 kafka-manager
1、本地安装 Zookeeper 或使用某个已有的 Zookeeper
2、本地安装 kafka-manager
拉取 linux/arm64 版本 kafka-manager 镜像: docker pull scjtqs/kafka-manager
https://hub.docker.com/r/scjtqs/kafka-manager
启动 kafka-manager 容器:
docker run -d --rm \
--name kafka-manager \
-p 9000:9000 \
-e ZK_HOSTS=172.25.106.90:2181 \
scjtqs/kafka-manager
注意:
- 这里的 zk 地址是 kafka-manager 用于存储配置信息的,不一定和要连接的目标 kafka 集群使用同一zk
- 由于 Mac 没有主机网络,这里即使连本地 zk 也不能填 localhost,得填自己 Mac 的 ip
kafka-manager 连接远程 kafka
打开 kafka-manger 主页
http://localhost:9000/
需要手动配置要管理的 kafka 集群,点击 Cluster -> Add Cluster
Cluster Name 填入自定义节点名称
Cluster Zookeeper Hosts 填入 zk 地址。注意这里的 zk 地址要带子目录,比如我启动 kafka 的时候参数是 -e KAFKA_ZOOKEEPER_CONNECT=172.24.220.146:2181/kafka, 则这里也需要填入 172.24.220.146:2181/kafka, 否则读取不到 topic 等信息
勾选 Poll consumer information (Not recommended for large # of consumers) 否则看不到消费信息
kafka命令行工具
Mac brew 安装的 kafka 的 bin 目录 /usr/local/Cellar/kafka/2.5.0/libexec/bin
Kafa Docker 容器内的 bin 目录:/opt/kafka_2.13-2.7.0/bin
kafka-topics.sh:对topic进行增删改查
kafka-server-start.sh:启动脚本
kafka-server-stop.sh:关闭脚本
kafka-consumer-groups.sh:展示所有的消费者组的信息 ,消费者消费的分区也会在这个脚本内显示出来
kafka-reassign-partitions.sh:重新分配partitions
kafka-preferred-replica-election.sh:每个partitions leader的重新分配
kafka-console-consumer.sh:消费者控制台 / 常用测试
kafka-console-producer.sh 生产者控制台 / 常用测试
准备kafka认证文件
准备kafka认证文件,后面的脚本都需要用
/Users/lll/kafka.conf
KafkaClient {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="admin"
password="admin";
};
kafka-topics.sh
--bootstrap-server <String: server to connect to> 要连接的 kafka server 地址。--zookeeper <String: hosts> (已废弃)host:port 格式的 zk 地址,多个可逗号分割。
注意这里的 zk 地址要带子目录,比如我启动 kafka 的时候参数是 -e KAFKA_ZOOKEEPER_CONNECT=172.24.220.146:2181/kafka, 则这里也需要填入 172.24.220.146:2181/kafka, 否则读取不到 topic 等信息
注意:
1、Kafka 从 2.2 版本开始将 kafka-topic.sh 脚本中的 −−zookeeper 参数标注为“废弃”,推荐使用 −−bootstrap-server 参数。
2、kafka 2.2 之前,只能通过 −−zookeeper 连接,不识别 −−bootstrap-server 参数。
查看 topic 列表
./kafka-topics.sh –zookeeper zk_host:port/namespace –list
./kafka-topics.sh –zookeeper 172.24.220.179:2181/kafka –list
./kafka-topics.sh –zookeeper host.docker.internal:2181/kafka –list
sh /usr/bin/kafka-topics –bootstrap-server localhost:9092 –list
例1,指定 zk 地址 查看 topic
./kafka-topics.sh --zookeeper host.docker.internal:2181/kafka --list
__consumer_offsets
alert-push-topic
count-push-topic
my-test-topic
例2,指定 kafka 地址查看 topic
$ kafka-topics --bootstrap-server kafka-service:9092 --list
__consumer_offsets
alert-push-topic
count-push-topic
my-push-topic
topic.test
例3,指定本地 kafka 地址查看 topic
./kafka-topics.sh –bootstrap-server=localhost:9092 –list
./kafka-topics.sh –list −−bootstrap-server localhost:9092
查看 topic 详情(分区,副本,isr等)
./kafka-topics.sh –zookeeper 172.24.196.145:2181/kafka –topic alert-push-topic –describe
./kafka-topics.sh –zookeeper host.docker.internal:2181/kafka –topic alert-push-topic –describe
./kafka-topics.sh −−bootstrap-server 172.24.196.145:9092 –topic alert-push-topic –describe
kafka-topics –bootstrap-server kafka-service:9092 –topic alert-push-topic –describe
例如:
./kafka-topics.sh --zookeeper 172.24.220.179:2181/kafka --topic my-test-topic --describe
Topic: my-test-topic PartitionCount: 12 ReplicationFactor: 1 Configs:
Topic: my-test-topic Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: my-test-topic Partition: 1 Leader: 0 Replicas: 0 Isr: 0
Topic: my-test-topic Partition: 2 Leader: 0 Replicas: 0 Isr: 0
Topic: my-test-topic Partition: 3 Leader: 0 Replicas: 0 Isr: 0
Topic: my-test-topic Partition: 4 Leader: 0 Replicas: 0 Isr: 0
Topic: my-test-topic Partition: 5 Leader: 0 Replicas: 0 Isr: 0
Topic: my-test-topic Partition: 6 Leader: 0 Replicas: 0 Isr: 0
Topic: my-test-topic Partition: 7 Leader: 0 Replicas: 0 Isr: 0
Topic: my-test-topic Partition: 8 Leader: 0 Replicas: 0 Isr: 0
Topic: my-test-topic Partition: 9 Leader: 0 Replicas: 0 Isr: 0
Topic: my-test-topic Partition: 10 Leader: 0 Replicas: 0 Isr: 0
Topic: my-test-topic Partition: 11 Leader: 0 Replicas: 0 Isr: 0
创建topic
sh ./bin/kafka-topics.sh –create –topic face –partitions 1 –replication-factor 1 –zookeeper 127.0.0.1:2181
./kafka-topics.sh –create –topic my-test-topic –partitions 1 –replication-factor 1 –bootstrap-server localhost:9092
kafka-run-class.sh
GetOffsetShell 查看topic的offset范围
sh /usr/bin/kafka-run-class kafka.tools.GetOffsetShell --broker-list localhost:9092 --topic my-test-topic --time -1
最后的参数
–time -1表示查询最新offset(或者叫最大offset),默认 -1
time -2表示查询最旧offset(或者叫最小offset),
–timetimestamp表示查询指定时间的offset
sh /usr/bin/kafka-run-class kafka.tools.GetOffsetShell --broker-list localhost:9092 --topic my-test-topic --time -1
my-test-topic:0:14260
my-test-topic:1:0
my-test-topic:2:2276
表示这个 topic 有 3 个 partition, 各个 partition 的 offset 的最大值
kafka-consumer-groups.sh
kafka-consumer-groups 脚本可查看消费组信息,以及重置 offset
这是 0.11.0.0 版本提供的新功能且只适用于新版本 consumer
在新版本之前,如果要为已有的 consumer group 调整位移必须要手动编写 Java 程序调用 KafkaConsumer.seek() 方法,费时费力不说还容易出错:
KafkaConsumer.seek(TopicPartition partition, long offset)
KafkaConsumer.seekToBeginning(Collection<TopicPartition> partitions)
KafkaConsumer.seekToEnd(Collection<TopicPartition> partitions)
0.11.0.0 版本丰富了 kafka-consumer-groups 脚本的功能,用户可以直接使用该脚本很方便地为已有的 consumer group 重新设置位移。
查看消费组列表
sh /usr/bin/kafka-consumer-groups --bootstrap-server localhost:9092 --list
例如:
sh /usr/bin/kafka-consumer-groups --bootstrap-server localhost:9092 --list
anonymous.a4d52d16-18f4-408a-868b-03402fdf433e
anonymous.85a3412f-a1f5-448a-b330-95f836d19b64
anonymous.b3f9eb94-7892-4b6f-9ce1-19f494695bee
anonymous.9e6b6e1a-11c4-4690-9c77-389d54ec4431
anonymous.d4106207-1a2e-4e3e-b5e8-cf84aeb2befd
anonymous.fa80d1c4-372f-4a96-b8b5-1c8e20127a3e
anonymous.9f622b57-8179-4b8e-b6af-b9c75cee5866
anonymous.7f758db5-c4be-4865-9226-f091f19f5061
anonymous.b4e4682d-7ce0-4831-b893-3f1e1f3aaacf
group-my
group-my-2
查看某消费组的offset信息
sh /usr/bin/kafka-consumer-groups --bootstrap-server localhost:9092 --group group-my --describe
例1、查看offset信息,带认证:
export KAFKA_OPTS="-Djava.security.auth.login.config=/Users/lll/kafka.conf"
./kafka-consumer-groups.sh --bootstrap-server 192.168.1.101:9092,192.168.1.102:9092,192.168.1.103:9092 --group consumer-group-name --describe
例2、查看消费组信息:
sh /usr/bin/kafka-consumer-groups --bootstrap-server localhost:9092 --group my-test-group --describe
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
my-test-group 6 0 0 0 consumer-9-b3bcd7e0-0fd6-49a5-af1b-b880407220cf /127.0.0.87 consumer-9
my-test-group 7 13575 13575 0 consumer-9-b3bcd7e0-0fd6-49a5-af1b-b880407220cf /127.0.0.87 consumer-9
my-test-group 4 634 634 0 consumer-8-9608bfb4-2f48-41f1-9c79-7e8770aecfdc /127.0.0.86 consumer-8
my-test-group 5 1002 1002 0 consumer-8-9608bfb4-2f48-41f1-9c79-7e8770aecfdc /127.0.0.86 consumer-8
my-test-group 10 11013 11013 0 consumer-9-f71aed99-0681-437c-be99-df7d619556a5 /127.0.0.85 consumer-9
my-test-group 11 31583 31583 0 consumer-9-f71aed99-0681-437c-be99-df7d619556a5 /127.0.0.85 consumer-9
my-test-group 0 17271 17271 0 consumer-8-35f70e5f-5bd4-4ddf-8a5c-941cec8fd035 /127.0.0.85 consumer-8
my-test-group 1 0 0 0 consumer-8-35f70e5f-5bd4-4ddf-8a5c-941cec8fd035 /127.0.0.85 consumer-8
my-test-group 2 2445 2445 0 consumer-8-5be62248-db16-4940-8290-d84d6a628218 /127.0.0.87 consumer-8
my-test-group 3 7775 7775 0 consumer-8-5be62248-db16-4940-8290-d84d6a628218 /127.0.0.87 consumer-8
my-test-group 8 19 19 0 consumer-9-b3d9d55d-d310-40cf-860b-a49f7eb616f5 /127.0.0.86 consumer-9
my-test-group 9 16051 16051 0 consumer-9-b3d9d55d-d310-40cf-860b-a49f7eb616f5 /127.0.0.86 consumer-9
可以看到每个消费组从哪个 partition 消费,是否有 lag 等。
修改消费组offset为初始/任意/最新
1、设为最新 offset
sh /usr/bin/kafka-consumer-groups --bootstrap-server localhost:9092 --group my-test-group --topic my-test-topic --reset-offsets --to-latest --execute
2、设为最早 offset
sh /usr/bin/kafka-consumer-groups --bootstrap-server localhost:9092 --group my-test-group --topic my-test-topic --reset-offsets --to-earliest --execute
3、设为任意 offset
sh /usr/bin/kafka-consumer-groups --bootstrap-server localhost:9092 --group my-test-group --topic my-test-topic --reset-offsets --to-offset 3 --execute
注意:如果消费组 my-test-group 还在活跃中,无法重置 offset, 报错如下,必须先关停对应应用
Error: Assignments can only be reset if the group ‘my-test-group’ is inactive, but the current state is Stable.
例1,重设 offset 到最新
sh /usr/bin/kafka-consumer-groups --bootstrap-server localhost:9092 --group my-test-group --topic my-test-topic --reset-offsets --to-latest --execute
TOPIC PARTITION NEW-OFFSET
my-test-topic 5 773
my-test-topic 0 15358
my-test-topic 2 2296
my-test-topic 6 0
my-test-topic 4 600
my-test-topic 3 7775
my-test-topic 9 14508
my-test-topic 7 12687
my-test-topic 10 9941
my-test-topic 11 27052
my-test-topic 1 0
my-test-topic 8 19
例2,重设消费组offset到最新,带认证
export KAFKA_OPTS="-Djava.security.auth.login.config=/Users/lll/kafka.conf"
./kafka-consumer-groups.sh --bootstrap-server 192.168.1.101:9092,192.168.1.102:9092,192.168.1.103:9092 --topic kafka-topic-name --group consumer-group-name --reset-offsets --to-latest --execute
kafka-console-producer.sh
发消息:
使用 kafka-console-producer.sh 脚本发消息,指定 broker 和 topic, topic 如果不存在会自动创建。
无认证发送消息
./kafka-console-producer.sh --broker-list localhost:9092 --topic masikkk-test-topic
执行完上面的命令后,实际发送消息之前,就自动创建了 masikkk-test-topic 这个 topic
出现 > 后,输入任何内容回车就发送了。
发完后 Ctrl+C 退出
带认证发送消息
export KAFKA_OPTS="-Djava.security.auth.login.config=/Users/lll/kafka.conf"
./kafka-console-producer.sh --broker-list xxx:9092,yyy:9092 --topic sparktest --security-protocol SASL_PLAINTEXT
发送多行消息
kafka-console-producer 最终调用的是用 java 写的工具代码,使用 Java Scanner 按行读入消息,所以多行消息体必然被识别为不同消息。
push multiple Line Text as one message in a kafka topic
https://stackoverflow.com/questions/52151816/push-multiple-line-text-as-one-message-in-a-kafka-topic/52162998
例如,如果直接将下面这个多行的 json 贴到提示符后发送,会被分为多条消息,每行是一条。
{
"msgCode":"user-123",
"msgType":"user",
"taskId":"123",
"appCode":"appcode",
"deviceId":"12",
"payload":{
"account":12345,
"id":1,
"name":"masikkk"
}
}
想发 json 的话利用工具压缩成一行即可。
kafka-console-consumer.sh
使用 kafka-console-consumer.sh 脚本接收消息,指定 broker, topic, 起始位置。
无认证接收消息
默认从最新 offset 开始消费
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic masikkk-test-topic
也可以指定 --from-beginning 从头开始消费:
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic masikkk-test-topic --from-beginning
带认证接收消息
同目录下准备消费者配置文件 consumer.properties
指定消费组和认证方式
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAIN
#group.id=consumer-group-name
不指定消费组也可以,好像不指定时会以一个新的消费组去消费消息,比如服务器上有消费者在消费某个 topic 的消息,我们本地也想看看,这时应该以一个新的消费组去消费,不能和服务器上的消费组争抢消息,以免造成数据不一致。
从头开始消费:
export KAFKA_OPTS="-Djava.security.auth.login.config=/Users/lll/kafka.conf"
./kafka-console-consumer.sh --bootstrap-server 192.168.1.101:9092,192.168.1.102:9092 --topic kafka-topic-name -from-beginning —offset earliest --consumer.config ./consumer.properties
从最新开始消费:
export KAFKA_OPTS="-Djava.security.auth.login.config=/Users/lll/kafka.conf"
./kafka-console-consumer.sh --bootstrap-server 192.168.1.101:9092,192.168.1.102:9092 --topic kafka-topic-name --consumer.config ./consumer.properties
k8s kafka 容器中脚本报错 Port already in use: 5555
k8s kafka 容器中执行 kafka-console-consumer 脚本报错:
$ kafka-console-consumer --bootstrap-server localhost:9092 --topic my-topic
Error: Exception thrown by the agent : java.rmi.server.ExportException: Port already in use: 5555; nested exception is:
java.net.BindException: Address already in use (Bind failed)
sun.management.AgentConfigurationError: java.rmi.server.ExportException: Port already in use: 5555; nested exception is:
java.net.BindException: Address already in use (Bind failed)
at sun.management.jmxremote.ConnectorBootstrap.startRemoteConnect
原因:
kafka 容器中默认会启动 JMX exporter,使用 JMX_PORT 变量设置的端口,默认值是 5555,我们使用的 kafka-console-consumer 也是 Java 写的工具,启动时会读取 KAFKA_OPTS 和 JMX_PORT 来设置 JMX 端口,索引会冲突。
解决:
1、取消 JMX_PORT 变量
unset JMX_PORT
kafka-console-consumer --bootstrap-server localhost:9092 --topic mytopic
2、或者将 JMX_PORT 改为一个未使用的端口
export JMX_PORT=5557
kafka-console-consumer --bootstrap-server localhost:9092 --topic mytopic
Kafka安全
自0.9.0.0.版本引入Security之后,Kafka一直在完善security的功能。当前Kafka security主要包含3大功能:认证(authentication)、信道加密(encryption)和授权(authorization)。信道加密就是为client到broker、broker到broker以及工具脚本与broker之间的数据传输配置SSL;认证机制主要是指配置SASL,而授权是通过ACL接口命令来完成的。
生产环境中,用户若要使用SASL则必须配置Kerberos,但对于一些小公司而言,他们的用户系统并不复杂(特别是专门为Kafka集群服务的用户可能不是很多),显然使用Kerberos有些大材小用,而且由于运行在内网环境,SSL加密也不是很必要。因此一个SASL+PLAINTEXT的集群环境足以应付一般的使用场景。
Kafka ACL使用实战
https://www.cnblogs.com/huxi2b/p/7382144.html
加载jaas的几种方式
设置系统属性java.security.auth.login.config
比如我们使用kafka命令行时手动设置此属性:
export KAFKA_OPTS=”-Djava.security.auth.login.config=/Users/lll/kafka.conf”
或者在消费者服务的启动脚本中设置 java.security.auth.login.config 属性
直接设置Producer或者Consumer的sasl.jaas.config属性
例如:
Properties properties = new Properties();
properties.put("security.protocol", "SASL_PLAINTEXT");
properties.put("sasl.mechanism", "PLAIN");
properties.put("sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"admin\" password=\"admin\";");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
consumer.subscribe(Lists.newArrayList("com-masikkk-kafka-topic-test"));
Kafka启用SASL_PLAINTEXt动态配置JAAS文件的几种方式
https://blog.csdn.net/russle/article/details/81041135
kafka为什么这么快?
Kafka在底层摒弃了Java堆缓存机制,采用了操作系统级别的页缓存,同时将随机写操作改为顺序写,再结合Zero-Copy的特性极大地改善了IO性能。但是,这只是一个方面,毕竟单机优化的能力是有上限的。
如何通过水平扩展甚至是线性扩展来进一步提升吞吐量呢? Kafka就是使用了分区(partition),通过将topic的消息打散到多个分区并分布保存在不同的broker上实现了消息处理(不管是producer还是consumer)的高吞吐量。
底层使用系统级PageCache缓存
kafka写操作时,依赖底层文件系统的pagecache功能,pagecache会将尽量多的将空闲内存,当做磁盘缓存,写操作先写到pageCache,并将该page标记为dirty;发生读操作时,会先从pageCache中查找,当发生缺页时,才会去磁盘调整;当有其他应用申请内存时,回收pageCache的代价是很低的。
使用pageCache的缓存功能,会减少我们队JVM的内存依赖,JVM为我们提供了GC功能,依赖JVM内存在kafka高吞吐,大数据的场景下有很多问题。如果heap管理缓存,那么JVM的gc会频繁扫描heap空间,带来的开销很大,如果heap过大,full gc带来的成本也很高;所有的In-Process Cache在OS中都有一份同样的PageCache。所以通过只在PageCache中做缓存至少可以提高一倍的缓存空间。如果Kafka重启,所有的In-Process Cache都会失效,而OS管理的PageCache依然可以继续使用。
sendfile零拷贝技术
传统IO:
磁盘 -> 内核缓冲区 -> 用户缓冲区 -> 内核缓冲区 -> socket缓冲区
sendfile():
磁盘 -> 内核缓冲区 -> 内核缓冲区 -> socket缓冲区
kafka性能技术分析
https://cloud.tencent.com/developer/article/1011927
appending log追加写
Kafka的核心设计是append log file。即不断追加写log文件来实现消息数据的写入(对比一下,active mq的内部更偏向一个传统数据库,不过active mq最近的版本开始用level db)。磁盘追加写的性能要远高于随机写。
partition分区机制水平扩展
kafka事务
幂等和事务是 Kafka 0.11.0.0版本引入的两个特性,以此来实现 EOS(exactly once semantics,精确一次处理语义)
Kafka 在 0.11.0.0 之前的版本中只支持 At Least Once 和 At Most Once 语义,尚不支持Exactly Once语义。
kafka幂等
幂等,简单地说就是对接口的多次调用所产生的结果和调用一次是一致的。生产者在进行重试的时候有可能会重复写入消息,而使用Kafka的幂等性功能之后就可以避免这种情况。
为了实现 Producer 的幂等语义,Kafka 引入了 Producer ID(即PID)和Sequence Number。每个新的 Producer 在初始化的时候会被分配一个唯一的 PID,该 PID 对用户完全透明而不会暴露给用户。
对于每个 PID,该 Producer 发送数据的每个 <Topic, Partition> 都对应一个从 0 开始单调递增的Sequence Number。
类似地,Broker 端也会为每个 <PID, Topic, Partition> 维护一个序号,并且每次 Commit 一条消息时将其对应序号递增。对于接收的每条消息,如果其序号比 Broker 维护的序号(即最后一次 Commit 的消息的序号)大一,则 Broker 会接受它,否则将其丢弃:
如果消息序号比 Broker 维护的序号大一以上,说明中间有数据尚未写入,也即乱序,此时 Broker 拒绝该消息,Producer 抛出InvalidSequenceNumber
如果消息序号小于等于 Broker 维护的序号,说明该消息已被保存,即为重复消息,Broker 直接丢弃该消息,Producer 抛出DuplicateSequenceNumber
上述设计解决了 0.11.0.0 之前版本中的两个问题:
Broker 保存消息后,发送 ACK 前宕机,Producer 认为消息未发送成功并重试,造成数据重复
前一条消息发送失败,后一条消息发送成功,前一条消息重试后成功,造成数据乱序
开启幂等性功能的方式很简单,只需要显式地将生产者客户端参数 enable.idempotence 设置为true即可(这个参数的默认值为false)。
引入序列号来实现幂等也只是针对每一对而言的,也就是说,Kafka的幂等只能保证单个生产者会话(session)中单分区的幂等。幂等性不能跨多个分区运作,而事务可以弥补这个缺陷。
kafka事务
为了使用事务,应用程序必须提供唯一的transactionalId,这个transactionalId通过客户端参数transactional.id来显式设置。事务要求生产者开启幂等特性,因此通过将transactional.id参数设置为非空从而开启事务特性的同时需要将enable.idempotence设置为true(如果未显式设置,则KafkaProducer默认会将它的值设置为true),如果用户显式地将enable.idempotence设置为false,则会报出ConfigException的异常。
transactionalId与PID一一对应,两者之间所不同的是transactionalId由用户显式设置,而PID是由Kafka内部分配的。
另外,为了保证新的生产者启动后具有相同transactionalId的旧生产者能够立即失效,每个生产者通过transactionalId获取PID的同时,还会获取一个单调递增的producer epoch。如果使用同一个transactionalId开启两个生产者,那么前一个开启的生产者会报错。
从生产者的角度分析,通过事务,Kafka可以保证跨生产者会话的消息幂等发送,以及跨生产者会话的事务恢复。
前者表示具有相同transactionalId的新生产者实例被创建且工作的时候,旧的且拥有相同transactionalId的生产者实例将不再工作。
后者指当某个生产者实例宕机后,新的生产者实例可以保证任何未完成的旧事务要么被提交(Commit),要么被中止(Abort),如此可以使新的生产者实例从一个正常的状态开始工作。
KafkaProducer提供了5个与事务相关的方法,详细如下:
void initTransactions();
void beginTransaction() throws ProducerFencedException;
void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets, String consumerGroupId) throws ProducerFencedException;
void commitTransaction() throws ProducerFencedException;
void abortTransaction() throws ProducerFencedException;
initTransactions()方法用来初始化事务;beginTransaction()方法用来开启事务;sendOffsetsToTransaction()方法为消费者提供在事务内的位移提交的操作;commitTransaction()方法用来提交事务;abortTransaction()方法用来中止事务,类似于事务回滚。
在消费端有一个参数isolation.level,与事务有着莫大的关联,这个参数的默认值为“read_uncommitted”,意思是说消费端应用可以看到(消费到)未提交的事务,当然对于已提交的事务也是可见的。
这个参数还可以设置为“read_committed”,表示消费端应用不可以看到尚未提交的事务内的消息。
kafka事务消息的发送
Producer 在接收到 producer id 后,就可以正常的发送消息了。不过发送消息之前,需要先将这些消息的分区地址,上传到 TC 服务。TC 服务会将这些分区地址持久化到事务 topic。然后 Producer 才会真正的发送消息,这些消息与普通消息不同,它们会有一个字段,表示自身是事务消息。
发送提交请求
Producer 发送完消息后,如果认为该事务可以提交了,就会发送提交请求到 TC 服务。Producer 的工作至此就完成了,接下来它只需要等待响应。这里需要强调下,Producer 会在发送事务提交请求之前,会等待之前所有的请求都已经发送并且响应成功。
提交请求持久化
TC 服务收到事务提交请求后,会先将提交信息先持久化到事务 topic 。持久化成功后,服务端就立即发送成功响应给 Producer。然后找到该事务涉及到的所有分区,为每 个分区生成提交请求,存到队列里等待发送。
事务主要指原子性,也即 Producer 将多条消息作为一个事务批量发送,要么全部成功要么全部失败。
为了实现这一点,Kafka 0.11.0.0 引入了一个服务器端的模块,名为Transaction Coordinator,用于管理 Producer 发送的消息的事务性。
该Transaction Coordinator维护Transaction Log,该 log 存于一个内部的 Topic 内。由于 Topic 数据具有持久性,因此事务的状态也具有持久性。
Producer 并不直接读写Transaction Log,它与Transaction Coordinator通信,然后由Transaction Coordinator将该事务的状态插入相应的Transaction Log。
Transaction Log的设计与Offset Log用于保存 Consumer 的 Offset 类似。
Kafka 设计解析(八):Kafka 事务机制与 Exactly Once 语义实现原理
https://www.infoq.cn/article/kafka-analysis-part-8
Kafka 事务实现原理
https://zhmin.github.io/2019/05/20/kafka-transaction/
Kafka科普系列 | Kafka中的事务是什么样子的? - 朱小厮
https://juejin.im/post/5cf29413e51d454fa33b185c
问题
TimeoutException since batch creation plus linger time
调用 send 发送消息后,onError 回调中报错:
topic:org.apache.kafka.common.errors.TimeoutException: Expiring 1 record(s) for swc-uds-relation-test-vehicle-user-relations-0: 2343 ms has passed since batch creation plus linger time, partition:{}, key:{}, value:{}
调用 send() 方法后,ProducerRecord 消息体会被放到缓存中,send()方法立即返回。
缓存中的消息会累积一定量后批量发送,每个放入缓存中的消息如果在时间间隔 request.timeout.ms 默认30秒 内没有被发送,就会抛出此异常。
producer往broker发送数据时是串行的,只有上次batch全部写入broker,并且全部callback函数执行完毕后,才会继续下一次发送。如果上一次发送全部callback函数执行时间超过了 request.timeout.ms(默认30s),就会导致后续batch的message发送时间大于创建时间30s以上,然后被producer丢弃并抛出异常;
解决方法:
原因可能是生产者产生的消息太快了导致来不及发送,或者brokers临时连不上等,可以试着调高 request.timeout.ms 的值。
Kafka Producer error Expiring 10 record(s) for TOPIC:XXXXXX: 6686 ms has passed since batch creation plus linger time
https://stackoverflow.com/questions/46750420/kafka-producer-error-expiring-10-records-for-topicxxxxxx-6686-ms-has-passed
Error while fetching metadata with correlation id 123 : {topic-name=UNKNOWN_TOPIC_OR_PARTITION}
原因1、发消息时报这个错,原因是使用的 kafka 账号没有这个 topic 的读写权限,导致无法读到这个 topic 的信息,以为是 topic-name 不存在
Error while fetching metadata with correlation id 123 : {topic-name=UNKNOWN_TOPIC_OR_PARTITION}
原因2、消费者报错,原因是 kafka 中没有 mytopic-1,mytopic-2,mytopic-3 这三个 topic,kafka 自动创建 topic 配置项 auto.create.topics.enable 改为 false 了,发送方也没创建 topic,导致 topic 不存在。
2023-05-08 10:02:18.884 [org.springframework.kafka.KafkaListenerEndpointContainer#0-4-C-1] WARN org.apache.kafka.clients.NetworkClient - [Consumer clientId=consumer-group-myapp-5, groupId=group-myapp] Error while fetching metadata with correlation id 1589880 : {mytopic-1=UNKNOWN_TOPIC_OR_PARTITION, mytopic-2=UNKNOWN_TOPIC_OR_PARTITION, mytopic-3=UNKNOWN_TOPIC_OR_PARTITION}
用kafka命令发送消息时候,一直报WARN Error while fetching metadata with correlation id 0 : {test=UNKNOWN_TOPIC_OR_PARTITION}?
https://www.orchome.com/447
CommitFailedException异常
CommitFailedException异常:位移提交失败时候抛出的异常。通常该异常被抛出时还会携带这样的一段话:
Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member. This means that the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time message processing. You can address this either by increasing the session timeout or by reducing the maximum size of batches returned in poll() with max.poll.records.
抛出时机
从源代码方面说,CommitFailedException 异常通常发生在手动提交位移时,即用户显式调用KafkaConsumer.commitSync()方法。
消息处理时间大于 max.poll.interval.ms 时: 如前所述,这是该异常最“正宗”的出现场景。复现也比较容易,用户只需写一个consumer程序,订阅topic(即使用consumer.subscribe),设置max.poll.interval.ms=N,然后在consumer.poll循环中Thread.sleep(>N),之后手动提交位移即可复现,比如:
props.put("max.poll.interval.ms", 5000);
consumer.subscribe(Arrays.asList("topic1", "topic2", ...));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
// 处理消息
Thread.sleep(6000L);
consumer.commitSync();
}
Kafka的CommitFailedException异常
https://www.cnblogs.com/huxi2b/p/8405566.html
NotLeaderForPartitionException: This server is not the leader for that topic
org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition
报错原因:producer在向kafka broker写的时候,刚好发生选举,本来是向broker0上写的,选举之后broker1成为leader,所以无法写成功,就抛异常了。
解决办法:修改producer的重试参数retries参数,默认是0, 一般设置为3, 我在生产环境配置的retries=10
NetworkException: The server disconnected before a response was received
org.apache.kafka.common.errors.NetworkException: The server disconnected before a response was received.
报错原因:kafka client与broker断开连接了
一次Kafka消息循环消费问题排查
现象:
有个微服务的接口被持续大量调用,产生的日志迅速堆满磁盘,产生告警。经查问题发现调用来自kafka消息的消费服务,有一个topic里有100多条消息被不断的重复消费,而每条消息的消费都要调100多次微服务接口,最终导致微服务日志堆积。
问题:
查到问题来自kafka消息循环消费后,发现日志中有自动 commit offset 失败:
Auto-commit of offsets {swc-uds-relation-stg-inviter-relations-2=OffsetAndMetadata{offset=146, metadata=''}, swc-uds-relation-stg-inviter-relations-1=OffsetAndMetadata{offset=3, metadata=''}, swc-uds-relation-stg-inviter-relations-0=OffsetAndMetadata{offset=3, metadata=''}} failed for group uds-receiver-relation-inviter-relationship-stg: Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member. This means that the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time message processing. You can address this either by increasing the session timeout or by reducing the maximum size of batches returned in poll() with max.poll.records.
自动commit offset失败的原因也说的很清楚,消息消费太慢,下次 poll 消息时超过 max.poll.interval.ms ,然后就被再平衡了,从而自动 commit offset 失败,offset没有往前走,下次再poll消息时还会取到之前的消息,造成重复消费现象。
一共两台消费者服务器,每次rebalance时自动转给另一个消费者,但另一个消费者也必然消费超时,就这么互相转来转去,各自都commit offset失败,一直循环。
kafka版本:spring-kafka:1.3.1.RELEASE, 对应的kafka版本:kafka-clients:0.11.0.0
原因:
原因也很容易找到,每条消息的消费中要调用100多次服务接口导致超时。
解决方法:
kafka的异常提示中已经给出了解决方案:要么改大超时时间,要么减少每次poll取回的消息个数,总之就是想办法在超时时间内快速把消息消费掉。
我的解决方法是把接口调用改为多线程异步调用,每次取完消息马上就commit offset,后来继续消费过程。
处理当前问题:
由于服务器上这些消息一直循环消费浪费服务器资源,临时想了个解决方法,在本地用同一个group id把服务器上的消费消费掉,让offset往前走,解决当前的循环消费问题,后续改进代码。
试了kafka的命令行工具,可以用同一个消费组在控制台打出消息,但貌似消费完后没有自动commit,offset还是原来的值。后来用java写了段代码,手动调用 consumer.commitSync(); 才使offset前进。
但offset前进后,服务器上还是在重复消费这些消息,猜可能是已经分配的消息消费失败的话总是会重复,后来重启了一下消费者服务,没问题了,因为消费者重启后,会去 latest offset 拉取消息,肯定就取不到之前的消息了。
总结:
一般情况下,kafka重复消费都是由于未正常提交offset
Kafka的CommitFailedException异常
https://www.cnblogs.com/huxi2b/p/8405566.html
‘java.security.auth.login.config’ is not set
原因是找不到 kafka 账号配置文件,可能原因是配置文件是通过启动脚本的 jvm参数传入的,但本地启动spring boot时忘了指定这个参数,就可能出此问题。
解决方法是在idea中配置Run Configuration,把kafka配置文件路径加入 jvm 参数中。
VM options: -Djava.security.auth.login.config=/Users/user/IdeaProjects/uds/uds-message-consumer/conf/test/kafka.conf
Caused by: java.lang.IllegalArgumentException: Could not find a 'KafkaClient' entry in the JAAS configuration. System property 'java.security.auth.login.config' is not set
at org.apache.kafka.common.security.JaasContext.defaultContext(JaasContext.java:131)
at org.apache.kafka.common.security.JaasContext.load(JaasContext.java:96)
at org.apache.kafka.common.security.JaasContext.load(JaasContext.java:78)
at org.apache.kafka.common.network.ChannelBuilders.create(ChannelBuilders.java:100)
at org.apache.kafka.common.network.ChannelBuilders.clientChannelBuilder(ChannelBuilders.java:58)
at org.apache.kafka.clients.ClientUtils.createChannelBuilder(ClientUtils.java:88)
at org.apache.kafka.clients.producer.KafkaProducer.<init>(KafkaProducer.java:374)
Kafka “Login module not specified in JAAS config”
https://stackoverflow.com/questions/45756543/kafka-login-module-not-specified-in-jaas-config
基础
Kafka 是一个分布式流数据系统,使用 Zookeeper 进行集群的管理(kafka 2.8之后可不使用zk)。与其他消息系统类似,整个系统由生产者、Broker Server和消费者三部分组成,生产者和消费者由开发人员编写,通过API连接到Broker Server进行数据操作。
kafka 版本
我们使用的版本
之前一直使用 0.11.0.2,最近升级到 2.2.2
topic 主题
Topic,是Kafka下消息的类别,类似于RabbitMQ中的Exchange的概念。这是逻辑上的概念,用来区分、隔离不同的消息数据,屏蔽了底层复杂的存储方式。对于大多数人来说,在开发的时候只需要关注数据写入到了哪个topic、从哪个topic取出数据。
consumer group 消费组
Consumer Group, 同样是逻辑上的概念,是 Kafka 实现单播和广播两种消息模型的手段。同一个topic的数据,会广播给不同的group;同一个group中的worker,只有一个worker能拿到这个数据。换句话说,对于同一个topic,每个group都可以拿到同样的所有数据,但是数据进入group后只能被其中的一个worker消费。group内的worker可以使用多线程或多进程来实现,也可以将进程分散在多台机器上,worker的数量通常不超过partition的数量,且二者最好保持整数倍关系,因为Kafka在设计时假定了 一个partition只能被一个worker消费(同一group内)。
Kafka中规定了每个消息分区(partition)只能被同组的一个消费者进行消费
consumer group是kafka提供的可扩展且具有容错性的消费者机制。既然是一个组,那么组内必然可以有多个消费者或消费者实例(consumer instance),它们共享一个公共的ID,即group ID。组内的所有消费者协调在一起来消费订阅主题(subscribed topics)的所有分区(partition)。当然,每个分区只能由同一个消费组内的一个consumer来消费。理解consumer group记住下面这三个特性就好了:
1)consumer group下可以有一个或多个consumer instance,consumer instance可以是一个进程,也可以是一个线程
2)group.id是一个字符串,唯一标识一个consumer group
3)consumer group下订阅的topic下的每个分区只能分配给某个group下的一个consumer(当然该分区还可以被分配给其他group)
offset 偏移量
Kafka消费后都会提交保存当前的消费位置offset, 可以选择保存在zk, 本地文件或其他存储系统;
Kafka 0.8以后提供了Coordinator的角色,Coordinator除了可以来协调消费的group作balance外, 还接受 OffsetCommit Request, 用来存储消费的offset到Kafka本身中
Kafka消费端的offset主要由consumer来控制, Kafka将每个consumer所监听的tocpic的partition的offset保存在__consumer_offsets主题中
partition 分区
Partition 是 Kafka 下数据存储的基本单元,这个是物理上的概念。同一个 topic 的数据,会被分散的存储到多个 partition 中,这些 partition 可以在同一台机器上,也可以是在多台机器上。
这种方式在大多数分布式存储中都可以见到,比如 MongoDB, Elasticsearch 的分片技术,其优势在于:有利于水平扩展,避免单台机器在磁盘空间和性能上的限制,同时可以通过复制来增加数据冗余性,提高容灾能力。为了做到均匀分布,通常 partition 的数量通常是 Broker Server 数量的整数倍。
Kafka 中可以将 Topic 从物理上划分成一个或多个分区(Partition),每个分区在物理上对应一个文件夹,以 topicName_partitionIndex 的命名方式命名,该文件夹下存储这个分区的所有消息(.log)和索引文件(.index),这使得 Kafka 的吞吐率可以水平扩展。
生产者在生产数据的时候,可以为每条消息指定 Key, 这样消息被发送到 broker 时,会根据分区规则选择被存储到哪一个分区中,如果分区规则设置的合理,那么所有的消息将会被均匀的分布到不同的分区中,这样就实现了负载均衡和水平扩展。另外,在消费者端,同一个消费组可以多线程并发的从多个分区中同时消费数据(后续将介绍这块)。
为什么要分区?
Kafka 在底层摒弃了 Java 堆缓存机制,采用了操作系统级别的页缓存,同时将随机写操作改为顺序写,再结合 Zero-Copy 的特性极大地改善了 IO 性能。但是,这只是一个方面,毕竟单机优化的能力是有上限的。
如何通过水平扩展甚至是线性扩展来进一步提升吞吐量呢? Kafka 就是使用了分区(partition),通过将 topic 的消息打散到多个分区并分布保存在不同的broker上实现了消息处理(不管是producer还是consumer)的高吞吐量。
分区就像高速公路的多车道,车道越多,吞吐量越大。
__consumer_offsets 保存offset的topic
__consumer_offsets 是一个内部topic,对用户而言是透明的。
__consumer_offsets 中保存的记录是普通的Kafka消息,只是它的格式完全由Kafka来维护,用户不能干预。严格来说,__consumer_offsets 中保存三类消息,分别是:
1、Consumer group 元数据消息
2、Consumer group offset 位移消息
3、Tombstone 消息
消费组元数据
都知道__consumer_offsets是保存位移的,但实际上每个消费者组的元数据信息也保存在这个topic中。
消费组元数据包括:group_id, group_generation,组员的信息(成员ID,IP等等)
offset消息
offset 消息 key是 groupId + topic + 分区号, value则是要提交的位移信息
提交时间是提交位移时的时间戳
过期时间则是用户指定的过期时间。一般consumer在提交位移时并没有明确指定过期间隔,故broker端默认设置过期时间为 提交时间+offsets.retention.minutes参数值,即提交7天之后自动过期。
Kafka会定期扫描__consumer_offsets中的位移消息并删除掉那些过期的位移数据。
tombstone消息或delete mark消息
何时写入这类消息?
Kafka会定期扫描过期位移消息并删除之。一旦某个consumer group下已没有任何active成员且所有的位移数据都已被删除时,Kafka会将该group的状态置为Dead并向 __consumer_offsets 对应分区写入tombstone消息,表明要彻底删除这个group的信息。简单来说,这类消息就是用于彻底删除group信息的。
__consumer_offsets的分区数和副本数
__consumer_offsets 的分区数和备份因子分别由 offsets.topic.num.partitions 和 offsets.topic.replication.factor 参数决定。这两个参数的默认值分别是50和3,表示该topic有50个分区,副本因子是3。鉴于位移和group元数据等信息都保存在该topic中,增加可靠性是推荐的做法。
消费组的删除
Kafka是会删除consumer group信息的,既包括位移信息,也包括组元数据信息。
对于位移信息而言,前面提到过每条位移消息都设置了过期时间。每个Kafka broker在后台会启动一个线程,定期(由 offsets.retention.check.interval.ms 确定,默认10分钟)扫描过期位移,并删除之。
而对组元数据而言,删除它们的条件有两个:1. 这个group下不能存在active成员,即所有成员都已经退出了group;2. 这个group的所有位移信息都已经被删除了。当满足了这两个条件后,Kafka后台线程会删除group运输局信息。
那么Kafka到底是怎么删除的呢?
正是通过写入具有相同key的tombstone消息。
关于Kafka __consumer_offests的讨论
https://www.cnblogs.com/huxi2b/p/8316289.html
GroupCoordinator消费者协调器
GroupCoordinator 是运行在 Kafka Broker 上的一个服务,每台 Broker 在运行时都会启动一个这样的服务。
GroupCoordinator 负责 consumer group member 管理以及 offset 管理。
每个 Consumer Group 都有其对应的 GroupCoordinator,但具体是由哪个 GroupCoordinator 负责与 group.id 的 hash 值有关,通过这个 abs(GroupId.hashCode()) % NumPartitions 来计算出一个值(其中,NumPartitions 是 __consumer_offsets 的 partition 数,默认是50个),这个值代表了 __consumer_offsets 的一个 partition,而这个 partition 的 leader 即为这个 Group 要交互的 GroupCoordinator 所在的节点。
Kafka 源码解析之 Consumer 如何加入一个 Group(六)
https://matt33.com/2017/10/22/consumer-join-group/
Kafka高可用HA
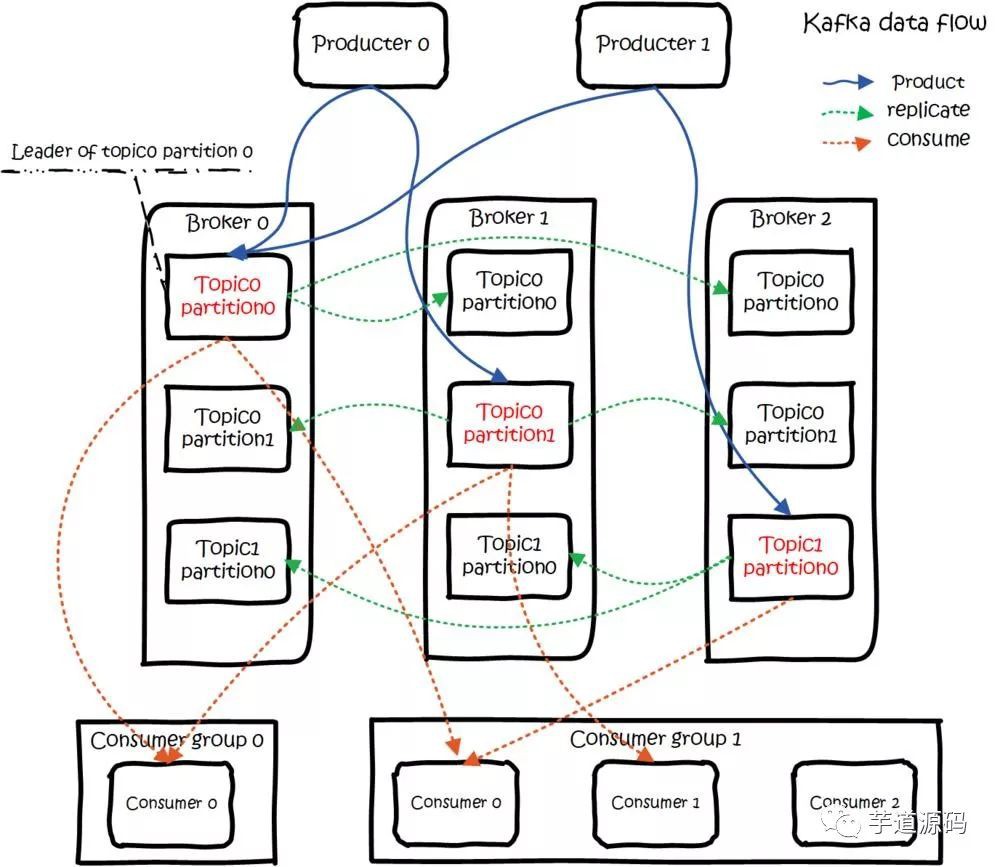
kafka dataflow
Kafka的复制机制
Kafka 的主题被分为多个分区,分区是基本的数据块。
分区存储在单个磁盘上,Kafka 可以保证分区里的事件是有序的,分区可以在线(可用),也可以离线(不可用)。
每个分区可以有多个副本,其中一个副本是 leader 副本。所有的生产者请求和消费者请求都经过 leader 副本,leader 副本以外的副本都是 follower 副本,follower 副本不处理来自客户端的请求,它们唯一的任务就是从 leader 副本那里复制消息,保持与 leader 副本一致的状态。
如果 leader 副本发生崩溃,其中的一个 follower 副本会被提升为新的 leader 副本。
复制提供了高可用, 即使有些节点出现了失败:
Producer 可以继续发布消息
Consumer 可以继续接收消息
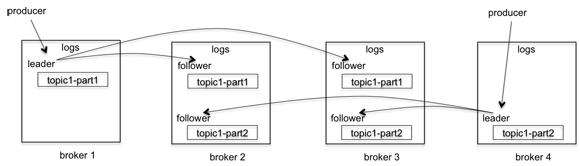
kafka 分区复制
kafka的复制是针对分区的。
比如上图中有四个broker,一个topic,2个分区,复制因子是3。
当producer发送一个消息的时候,它会选择一个分区,比如topic1-part1分区,将消息发送给这个分区的leader, broker2、broker3会拉取这个消息,一旦消息被拉取过来,slave会发送ack给master,这时候master才commit这个log。
一个Broker既可能是一个分区的leader,也可能是另一个分区的slave。
这个过程中producer有两个选择:
一是等所有的副本都拉取成功producer才收到写入成功的response,
二是等leader写入成功就得到成功的response。
第一个中可以确保在异常情况下不丢消息,但是latency就下来了。后一种latency提高很多,但是一旦有异常情况,slave还没有来得及拉取到最新的消息leader就挂了,这种情况下就有可能丢消息了。
ISR(in sync replicas)同步副本
kafka 实际是保证在足够多的 slave 写入成功的情况下就认为消息写入成功,而不是全部写入成功。这是因为有可能一些节点网络不好,或者机器有问题hang住了,如果leader一直等着,那么所有后续的消息都堆积起来了,所以kafka认为只要足够多的副本写入就可以饿。那么,怎么才认为是足够多呢?
Kafka 引入了 ISR 的概念。ISR 是 in-sync replicas 的简写。ISR中的副本保持和leader的同步,当然leader本身也在ISR中。初始状态所有的副本都处于ISR中,当一个消息发送给leader的时候,leader会等待ISR中所有的副本告诉它已经接收了这个消息,如果一个副本失败了,那么它会被移除ISR。下一条消息来的时候,leader就会将消息发送给当前的ISR中节点了。
同步副本是满足如下条件的副本:
- leader 副本是同步副本
- 与 zookeeper 之间有一个活跃的会话,也即在过去 6S(可配置)内向 zookeeper 发送过心跳。
- 在过去的 10S 内(可配置)从 leader 副本那里获得过信息。
- 在过去 10S 内从 leader 副本那里获取过最新的信息。(光从leader那里获取信息是不够的,还必须是几乎零延迟的)
leader 会跟踪与其保持同步的副本列表,该列表称为ISR(即in-sync Replica)。如果一个 follower 宕机,或者落后太多,leader 将把它从 ISR 中移除。这里所描述的“落后太多”指:
1、Follower 复制的消息落后于 Leader 的条数超过预定值(该值可通过 replica.lag.max.messages 配置,其默认值是 4000)
2、或者 Follower 超过一定时间(该值可通过 replica.lag.time.max.ms 来配置,其默认值是 10000,即 10s)未向 Leader 发送 fetch 请求。
如果 OSR 集合中所有 follower 副本“追上”了 leader 副本,那么 leader 副本会把它从 OSR 集合转移至 ISR 集合。默认情况下,当 leader 副本发生故障时,只有在 ISR 集合中的 follower 副本才有资格被选举为新的 leader,而在 OSR 集合中的副本则没有任何机会(不过这个可以通过配置来改变)。
AR(Assigned Replicas)集合
简单来说,分区中的所有副本统称为 AR (Assigned Replicas)。
所有与leader副本保持一定程度同步的副本(包括leader副本在内)组成 ISR (In Sync Replicas)。
ISR 集合是 AR 集合的一个子集。
OSR(Out-of-Sync Replied)集合
消息会先发送到leader副本,然后follower副本才能从leader中拉取消息进行同步。
同步期间,follow副本相对于leader副本而言会有一定程度的滞后。前面所说的 ”一定程度同步“ 是指可忍受的滞后范围,这个范围可以通过参数进行配置。
于leader副本同步滞后过多的副本(不包括leader副本)将组成 OSR (Out-of-Sync Replied)
由此可见,AR = ISR + OSR。
正常情况下,所有的follower副本都应该与leader 副本保持 一定程度的同步,即AR=ISR,OSR集合为空。
同时,leader还维护着 HW(high watermark),这是一个分区的最后一条消息的offset。HW会持续的将HW发送给slave,broker可以将它写入到磁盘中以便将来恢复。
当一个失败的副本重启的时候,它首先恢复磁盘中记录的HW,然后将它的消息truncate到HW这个offset,这就是日志截断。这是因为HW之后的消息不保证已经commit。这时它变成了一个slave, 从HW开始从Leader中同步数据,一旦追上leader,它就可以再加入到ISR中。
kafka使用Zookeeper实现leader选举。如果 leader失败,controller会从ISR选出一个新的leader。leader 选举的时候可能会有数据丢失,但是committed的消息保证不会丢失。
ISR(in-sync replica) 就是 Kafka 为某个分区维护的一组同步集合,即每个分区都有自己的一个 ISR 集合,处于 ISR 集合中的副本,意味着 follower 副本与 leader 副本保持同步状态,只有处于 ISR 集合中的副本才有资格被选举为 leader。
一条 Kafka 消息,只有被 ISR 中的副本都接收到,才被视为“已同步”状态。这跟 zk 的同步机制不一样,zk 只需要超过半数节点写入,就可被视为已写入成功。
分区leader选举
当 Leader 宕机了,怎样在 Follower 中选举出新的 Leader?
Kafka 在 ZooKeeper 中动态维护了一个 ISR(in-sync replicas),这个 ISR 里的所有 Replica 都跟上了 leader,只有 ISR 里的成员才有被选为 Leader 的可能。
最简单最直观的方案是:
所有 Follower 都在 ZooKeeper 上设置一个 Watch,一旦 Leader 宕机,其对应的 ephemeral znode 会自动删除,此时所有 Follower 都尝试创建该节点,而创建成功者(ZooKeeper 保证只有一个能创建成功)即是新的 Leader,其它 Replica 即为 Follower。
但是该方法会有 3 个问题:
split-brain 这是由 ZooKeeper 的特性引起的,虽然 ZooKeeper 能保证所有 Watch 按顺序触发,但并不能保证同一时刻所有 Replica“看”到的状态是一样的,这就可能造成不同 Replica 的响应不一致
herd effect 如果宕机的那个 Broker 上的 Partition 比较多,会造成多个 Watch 被触发,造成集群内大量的调整
ZooKeeper 负载过重 每个 Replica 都要为此在 ZooKeeper 上注册一个 Watch,当集群规模增加到几千个 Partition 时 ZooKeeper 负载会过重。
Kafka 0.8.* 之后 的 Leader Election 方案解决了上述问题:
它在所有 broker 中选出一个 controller,所有 Partition 的 Leader 选举都由 controller 决定。controller 会将 Leader 的改变直接通过 RPC 的方式(比 ZooKeeper Queue 的方式更高效)通知需为为此作为响应的 Broker。同时 controller 也负责增删 Topic 以及 Replica 的重新分配。
分区leader副本的选举由Kafka Controller 负责具体实施。当创建分区(创建主题或增加分区都有创建分区的动作)或分区上线(比如分区中原先的leader副本下线,此时分区需要选举一个新的leader上线来对外提供服务)的时候都需要执行leader的选举动作。
基本思路是 按照AR集合中副本的顺序查找第一个存活的副本,并且这个副本在ISR集合中。一个分区的AR集合在分配的时候就被指定,并且只要不发生重分配的情况,集合内部副本的顺序是保持不变的,而分区的ISR集合中副本的顺序可能会改变。注意这里是根据AR的顺序而不是ISR的顺序进行选举的。
还有一些情况也会发生分区leader的选举,比如当分区进行重分配(reassign)的时候也需要执行leader的选举动作。这个思路比较简单:从重分配的AR列表中找到第一个存活的副本,且这个副本在目前的ISR列表中。
再比如当发生优先副本(preferred replica partition leader election)的选举时,直接将优先副本设置为leader即可,AR集合中的第一个副本即为优先副本。
还有一种情况就是当某节点被优雅地关闭(也就是执行ControlledShutdown)时,位于这个节点上的leader副本都会下线,所以与此对应的分区需要执行leader的选举。这里的具体思路为:从AR列表中找到第一个存活的副本,且这个副本在目前的ISR列表中,与此同时还要确保这个副本不处于正在被关闭的节点上。
partition和replica分配方法
为了更好的做负载均衡,Kafka 尽量将所有的 Partition 均匀分配到整个集群上。一个典型的部署方式是一个 Topic 的 Partition 数量大于 Broker 的数量。同时为了提高 Kafka 的容错能力,也 需要将同一个 Partition 的 Replica 尽量分散到不同的机器。实际上,如果所有的 Replica 都在同一个 Broker 上,那一旦该 Broker 宕机,该 Partition 的所有 Replica 都无法工作,也就达不到 HA 的效果。同时,如果某个 Broker 宕机了,需要保证它上面的负载可以被均匀的分配到其它幸存的所有 Broker 上。
Kafka 分配 Replica 的算法如下:
将所有 Broker(假设共 n 个 Broker)和待分配的 Partition 排序
将第 i 个 Partition 分配到第(i mod n)个 Broker 上
将第 i 个 Partition 的第 j 个 Replica 分配到第((i + j) mode n)个 Broker 上
producer发送消息到partition的流程
Producer 在发布消息到某个 Partition 时,先通过 ZooKeeper 找到该 Partition 的 Leader,然后无论该 Topic 的 Replication Factor 为多少(也即该 Partition 有多少个 Replica),Producer 只将该消息发送到该 Partition 的 Leader。Leader 会将该消息写入其本地 Log。每个 Follower 都从 Leader pull 数据。这种方式上,Follower 存储的数据顺序与 Leader 保持一致。Follower 在收到该消息并写入其 Log 后,向 Leader 发送 ACK。一旦 Leader 收到了 ISR 中的所有 Replica 的 ACK,该消息就被认为已经 commit 了,Leader 将增加 HW 并且向 Producer 发送 ACK。
为了提高性能,每个 Follower 在接收到数据后就立马向 Leader 发送 ACK,而非等到数据写入 Log 中。因此,对于已经 commit 的消息,Kafka 只能保证它被存于多个 Replica 的内存中,而不能保证它们被持久化到磁盘中,也就不能完全保证异常发生后该条消息一定能被 Consumer 消费。但考虑到这种场景非常少见,可以认为这种方式在性能和数据持久化上做了一个比较好的平衡。在将来的版本中,Kafka 会考虑提供更高的持久性。
Consumer 读消息也是从 Leader 读取,只有被 commit 过的消息(offset 低于 HW 的消息)才会暴露给 Consumer。
高水位HW与LEO
水位或水印(watermark)一词,也可称为 **高水位(high watermark)**,通常被用在流式处理领域(比如Apache Flink、Apache Spark等),以表征元素或事件在基于时间层面上的进度。
一个比较经典的定义是:在时刻T,任意创建时间(Event Time)为T’,且 T’<=T 的所有事件都已经到达,那么 T 就被定义为水位。
或者说,水位是一个单调增加且表征最早未完成工作的时间戳。
在 Kafka 中,水位的概念与时间无关,通过位移 offset 来代表水位。
HW(High Watermark)俗称高水位,它标识了一个特定的消息偏移量(offset),消费者只能拉取到 高水位 HW 之前的消息。
每个副本都有自己的HW和LEO值
每个 Kafka 副本都有两个重要的属性: LEO 和 HW。注意是所有的副本,而不只是 leader 副本。
LEO(Log End Offset) 即日志末端位移, 记录了该副本底层日志(log)中下一条消息的位移值。注意是下一条消息!也就是说,如果 LEO=10,那么表示该副本保存了 10 条消息,位移值范围是[0,9]。所以,也可以说,LEO 的值等于当前副本中最后一条消息的 offset 值加 1。
HW(High Watermark) 即高水位, 副本的水位值,对于同一个副本对象而言,其 HW 值不会大于 LEO 值。小于等于 HW 值的所有消息都被认为是“已备份”的(replicated)
对于分区 Leader 副本的高水位图,在分区高水位以下的消息被认为是已提交消息(committed),反之为未提交消息(uncommitted)。
consumer 无法消费未提交消息。这句话如果用以上名词来解读的话,应该表述为:consumer 无法消费分区下 leader 副本中位移值大于分区 HW 的任何消息。这里需要特别注意分区 HW 就是 leader 副本的 HW 值。
即,Kafka 所有副本对象都有对应的 HW 和 LEO ,而 Kafka 使用 Leader 副本的 HW 来定义所在分区的 HW。
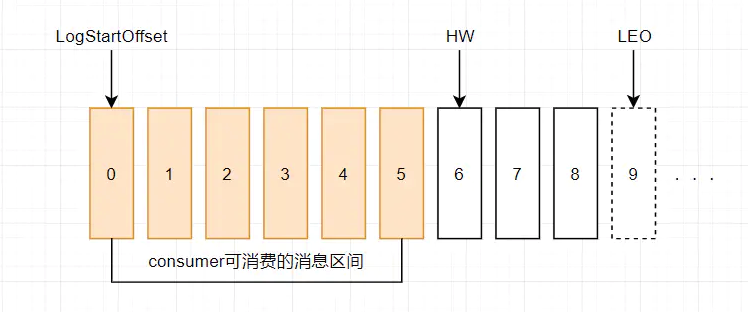
Leader副本高水位HW和LEO示意图
分区高水位HW的更新机制
首先要搞清楚 Kafka 中副本 LEO 的保存机制,对于每个 Follower 副本来说,有两个地方存储了其 LEO 值:
1、一份 LEO 保存在 follower 副本所在 broker 中;
2、另一分 LEO 保存在 leader 副本所在 broker 中。
也就是说,Leader 副本所在的 Broker 会保存所有 Follower 副本的 LEO 值。
如下示意图:
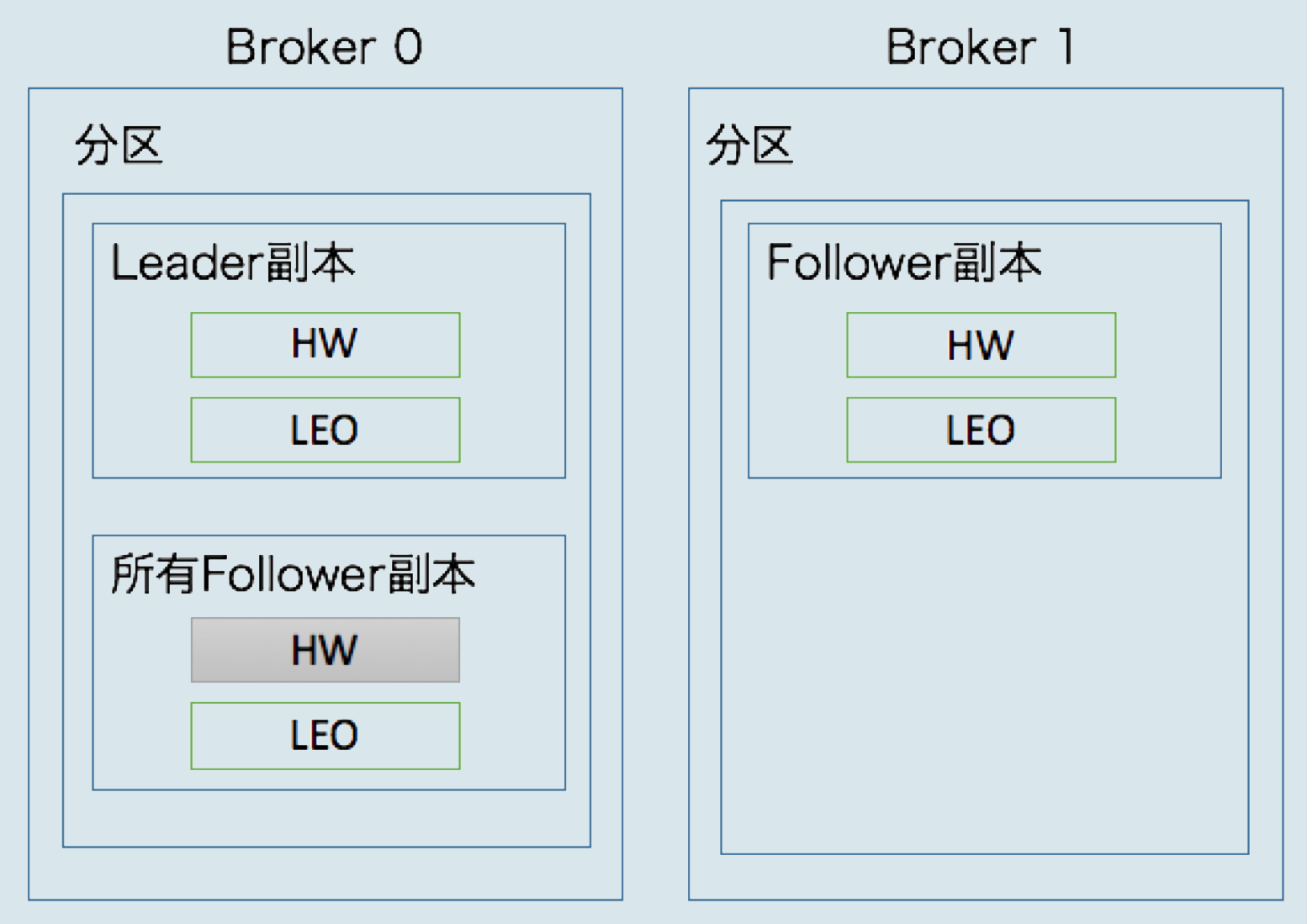
Leader副本所在的Broker会保存所有Follower副本的LEO值
每个副本对象都保存了一组高水位HW和LEO值,Leader副本所在的Broker还保存了其它Follower副本的LEO值
更新机制如下:
一、对于 Leader 副本
1、处理生产者请求时
(1)写入消息到本地磁盘,更新 Leader 副本的 LEO 值,也就是分区的 LEO 值,写入一条消息 LEO 就加 1
(2)更新分区高水位 HW 值,算法如下:
- 获取 Leader 副本所在 Broker 端保存的所有同步副本的 LEO 值 {LEO-1, LEO-2,… LEO-n}
- 获取 Leader 副本的 LEO 值:currentLEO
- 更新
currentHW = min(currentLEO, LEO-1, LEO-2,... LEO-n),即分区内所有同步副本 LEO 的最小值就是 Leader 的 HW 值,也就是分区的 HW 值。
上面的 HW 更新算法需要统计与 Leader 副本保持同步的 Follower 副本,这里的“同步”需要满足两个条件
1、该远程 Follower 副本在 ISR 中
2、该远程 Follower 副本 LEO 值落后 Leader 副本 LEO 值的时间不超过参数 replica.lag.time.max.ms(默认10秒)
注意:虽然 ISR 同步副本集合的条件就是 follower 副本延迟时间不超过 replica.lag.time.max.ms,但这两个条件并不是完全等同的,因为会存在follower副本已经“追上”了leader的进度,但却不在ISR中的情况,比如刚从failure中恢复的副本,所以第二个条件是为了应对意外情况:Follower副本已经追上Leader,却不在ISR中。
假如只有第一个条件,就可能出现分区HW值越过ISR中副本LEO的情况,但这是不允许的。举例:假如现在 min(ISR副本LEO值) 是 10,有个刚恢复的 follower 副本 F 的 LEO 值是 8,计算出分区 HW 值后 F 加入了 ISR 中,这时就出现了分区 HW 值 10 大于 ISR 中副本 F 的 LEO 值 8 的情况。
2、处理 Follower 副本拉取消息(Fetch)请求时
(1)读取磁盘(或页缓存)中的消息数据
(2)使用 Follower 副本发送请求中的位移值来更新远程副本的 LEO 值
(3)更新分区高水位 HW 值(与上面一致)
二、对于 Follower 副本
从 Leader 拉取消息(Fetch) 后
(1)写入消息到本地磁盘
(2)更新 LEO 值,写入一条消息 LEO 就加 1
(3)更新高水位 HW 值,算法如下:
- 获取 Leader 发送的高水位值 currentHW
- 获取步骤(2)中更新的 LEO 值 currentLEO
- 更新高水位
HW = min(currentHW, currentLEO),所以 follower 的 HW 值是不会越过 leader HW 值的
使用高水位HW表示副本更新进度会导致数据丢失或不一致
如果我们结合一个具体事例分析一下 Leader 副本和 Follower 副本的 LEO/HW 更新过程(下面的参考链接博客中有具体分析过程,比较麻烦),就会发现一个问题:
Follower 副本的高水位 HW 更新需要一轮额外的拉取请求才能实现,即 Leader 副本高水位更新和 Follower 副本高水位更新在时间上存在错配,这种错配是很多数据丢失或数据不一致问题的根源。
Kafka 使用 HW 值来决定副本备份的进度,而 HW 值的更新通常需要额外一轮 FETCH RPC 才能完成,故而这种设计是有问题的。它们可能引起:1、备份数据丢失。2、备份数据不一致。
造成上述两个问题的根本原因在于 HW 值被用于衡量副本备份的成功与否以及在出现 failture 时作为日志截断的依据,但 HW 值的更新是异步延迟的,特别是需要额外的 FETCH 请求处理流程才能更新,故这中间发生的任何崩溃都可能导致 HW 值的过期。
因此,Kafka 在 0.11 版本正式引入了 Leader Epoch 概念,来规避高水位更新错配导致的各种不一致问题
Kafka0.11之后使用Leader Epoch取代HW高水位
0.11.0.0 版本的 Kafka 通过引入 leader epoch 解决了原先依赖高水位 HW 表示副本备份进度可能造成的数据丢失/数据不一致问题。
所谓 leader epoch 实际上是一对值:(epoch, offset)
epoch表示 leader 的版本号,或者说 leader 的纪元,从 0 开始单调递增,当 leader 变更过 1 次时 epoch 就会加 1。小版本号的 Leader 被认为是过期 Leader,不能再行使 Leader 权利。offset表示该 epoch 版本的 leader 写入第一条消息的位移。
例如有如下两对 (epoch, offset) 值:
(0, 0)
(1, 120)
从中我们可以看出如下信息:
1、leader 有过一次变更,当前的 leader 是第 2 个,即当前 leader 的 epoch 是 2
2、第一个 leader 从位移 0 开始写入消息,共写了 120 条,offset 范围是 [0,119]
之后 leader 发生了变更,第二个 leader 版本号是 1,是当前的 leader,从位移 120 处开始写入消息。
Broker 在内存中为每个分区都缓存 Leader Epoch 数据,同时还会定期地将这些数据持久化到一个 checkpoint 文件中
当 Leader 副本写入消息到磁盘时,Broker 会尝试更新这部分缓存:如果 Leader 是首次写入消息,那么 Broker 会向缓存中增加 Leader Epoch 条目,否则不做更新。
这样每次有 Leader 变更时,新的 Leader 副本会查询这部分缓存,取出对应的 Leader Epoch 的起始位移,然后进行相关的逻辑判断,避免数据丢失和数据不一致的情况。
Kafka水位(high watermark)与leader epoch的讨论
https://www.cnblogs.com/huxi2b/p/7453543.html
Kafka – 高水位 + Leader Epoch
http://zhongmingmao.me/2019/09/20/kafka-high-watermark-leader-epoch/
kafka与zookeeper
早期版本的 kafka 用 zk 做 meta 信息存储,consumer 的消费状态,group 的管理以及 offset 的值。
考虑到zk本身的一些因素以及整个架构较大概率存在单点问题,新版本中确实逐渐弱化了zookeeper的作用。新的consumer使用了kafka内部的group coordination协议,也减少了对zookeeper的依赖
在老版本(0.8.1以前)里面消费者(consumer)也是依赖ZK的,在新版本中移除了客户端对ZK的依赖,但是broker依然依赖于ZK。
Broker注册
Broker是分布式部署并且相互之间相互独立,但是需要有一个注册系统能够将整个集群中的Broker管理起来,此时就使用到了Zookeeper。在Zookeeper上会有一个专门用来进行Broker服务器列表记录的节点:/brokers/ids
每个Broker在启动时,都会到Zookeeper上进行注册,即到 /brokers/ids 下创建属于自己的节点,如 /brokers/ids/[0...N]
Kafka使用了全局唯一的数字来指代每个Broker服务器,不同的Broker必须使用不同的Broker ID进行注册,创建完节点后,每个Broker就会将自己的IP地址和端口信息记录到该节点中去。
Broker创建的节点类型是临时节点,一旦Broker宕机,则对应的临时节点也会被自动删除。
Topic注册
在Kafka中,同一个Topic的消息会被分成多个分区并将其分布在多个Broker上,这些分区信息及与Broker的对应关系也都是由Zookeeper在维护,由专门的节点来记录,如:/borkers/topics
Kafka中每个Topic都会以 /brokers/topics/[topic] 的形式被记录,如/brokers/topics/login和/brokers/topics/search等。
Broker服务器启动后,会到对应Topic节点(/brokers/topics)上注册自己的Broker ID并写入针对该Topic的分区总数,如/brokers/topics/login/3->2,这个节点表示Broker ID为3的一个Broker服务器,对于”login”这个Topic的消息,提供了2个分区进行消息存储,同样,这个分区节点也是临时节点。
broker failover 过程简介
1、Controller 在 ZooKeeper 注册 Watch,一旦有 Broker 宕机(这是用宕机代表任何让系统认为其 die 的情景,包括但不限于机器断电,网络不可用,GC 导致的 Stop The World,进程 crash 等),其在 ZooKeeper 对应的 znode 会自动被删除,ZooKeeper 会 fire Controller 注册的 watch,Controller 读取最新的幸存的 Broker。
2、Controller 决定 set_p,该集合包含了宕机的所有 Broker 上的所有 Partition。
3、对 set_p 中的每一个 Partition
3.1 从/brokers/topics/[topic]/partitions/[partition]/state读取该 Partition 当前的 ISR
3.2 决定该 Partition 的新 Leader。如果当前 ISR 中有至少一个 Replica 还幸存,则选择其中一个作为新 Leader,新的 ISR 则包含当前 ISR 中所有幸存的 Replica。否则选择该 Partition 中任意一个幸存的 Replica 作为新的 Leader 以及 ISR(该场景下可能会有潜在的数据丢失)。如果该 Partition 的所有 Replica 都宕机了,则将新的 Leader 设置为 -1。
3.3 将新的 Leader,ISR 和新的leader_epoch及controller_epoch写入/brokers/topics/[topic]/partitions/[partition]/state。注意,该操作只有其 version 在 3.1 至 3.3 的过程中无变化时才会执行,否则跳转到 3.1
4、直接通过 RPC 向 set_p 相关的 Broker 发送 LeaderAndISRRequest 命令。Controller 可以在一个 RPC 操作中发送多个命令从而提高效率。
kafka选举
Kafka中的选举有多处,不止分区leader的选举这一处。
Kafka中的选举大致可以分为三大类:控制器的选举、分区leader的选举以及消费者相关的选举
controller选举
在Kafka集群中会有一个或多个broker,其中有一个broker会被选举为控制器(Kafka Controller),它负责管理整个集群中所有分区和副本的状态等工作。
比如当某个分区的leader副本出现故障时,由控制器负责为该分区选举新的leader副本。再比如当检测到某个分区的ISR集合发生变化时,由控制器负责通知所有broker更新其元数据信息。
Kafka Controller的选举是依赖Zookeeper来实现的,在Kafka集群中哪个broker能够成功创建/controller这个临时(EPHEMERAL)节点他就可以成为Kafka Controller。
消费组leader选举
组协调器GroupCoordinator需要为消费组内的消费者选举出一个消费组的leader,这个选举的算法也很简单,分两种情况分析。
如果消费组内还没有leader,那么第一个加入消费组的消费者即为消费组的leader。
如果某一时刻leader消费者由于某些原因退出了消费组,那么会重新选举一个新的leader,这个重新选举leader的过程又更“随意”了,相关代码如下:
//scala code.
private val members = new mutable.HashMap[String, MemberMetadata]
var leaderId = members.keys.head
解释一下这2行代码:在GroupCoordinator中消费者的信息是以HashMap的形式存储的,其中key为消费者的member_id,而value是消费者相关的元数据信息。leaderId表示leader消费者的member_id,它的取值为HashMap中的第一个键值对的key,这种选举的方式基本上和随机无异。总体上来说,消费组的leader选举过程是很随意的。
Kafka科普系列 | 原来Kafka中的选举有这么多?
https://juejin.im/post/5cdec305f265da1b7c60e71c
页面信息
location:protocol: host: hostname: origin: pathname: href: document:referrer: navigator:platform: userAgent: