Apache-ZooKeeper
Apache ZooKeeper 使用笔记
https://zookeeper.apache.org/
ZooKeeper简介
ZooKeeper 是一个分布式的,开放源码的分布式应用程序协调服务。它对外提供一组简单的基本操作接口,使得分布式应用能够在其基础上实现高水平的服务同步、配置管理、集群管理、命名服务等功能。
ZooKeeper数据存储模型
ZooKeeper 数据存储方式类似于标准的文件系统。但和文件系统不同的是,ZooKeeper 的非叶子节点也可以存储数据。而标准文件系统中,只有文件才能存储数据,目录本身是不存储数据的。
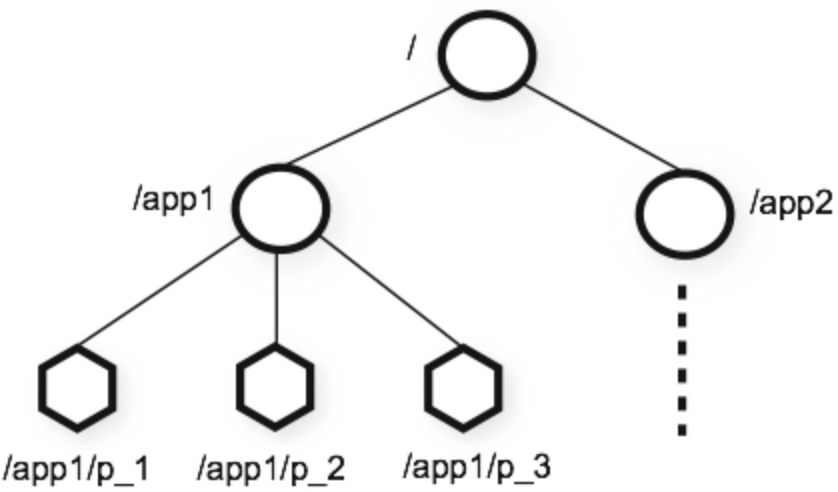
ZK结点
ZooKeeper节点类型
ZooKeeper 有四种节点,分别为:
PERSISTENT 持久节点
除非手动删除,否则节点一直存在于 Zookeeper 上
EPHEMERAL 临时节点
临时节点的生命周期与客户端会话绑定,一旦客户端会话失效(客户端与 zookeeper 连接断开不一定会话失效),那么这个客户端创建的所有临时节点都会被移除。
PERSISTENT_SEQUENTIAL 持久顺序节点
基本特性同持久节点,只是增加了顺序属性,节点名后边会追加一个由父节点维护的自增整型数字。
EPHEMERAL_SEQUENTIAL 临时顺序节点
基本特性同临时节点,增加了顺序属性,节点名后边会追加一个由父节点维护的自增整型数字。
ZooKeeper事件
当前zookeeper有如下四种事件:节点创建,节点删除,节点数据修改,子节点变更。
ZooKeeper原理及使用(转)
https://www.cnblogs.com/jpfss/p/8243902.html
有序性与ZXID
有序性是zookeeper中非常重要的一个特性,所有的更新都是全局有序的,每个更新都有一个唯一的时间戳,这个时间戳称为 **zxid(Zookeeper Transaction Id)**。
而读请求只会相对于更新有序,也就是读请求的返回结果中会带有这个zookeeper最新的zxid。
zookeeper 采用了全局递增的事务Id来标识,所有的proposal(提议)都在被提出的时候加上了zxid,zxid实际上是一个64位的数字,高32位是epoch(时期; 纪元; 世; 新时代)用来标识leader周期,如果有新的leader产生出来,epoch会自增,低32位用来递增计数。当新产生proposal的时候,会依据数据库的两阶段过程,首先会向其他的server发出事务执行请求,如果超过半数的机器都能执行并且能够成功,那么就会开始执行。
基于ZooKeeper的分布式锁原理
基于ZooKeeper的分布式锁利用ZooKeeper的 EPHEMERAL_SEQUENTIAL 节点特性,对于每一个试图获取同一把锁的线程,会在同一个节点(类似文件系统的目录)下创建一个 EPHEMERAL_SEQUENTIAL 节点,并保证先创建的节点的顺序编号一定小于后创建的节点的顺序编号。例如:/lock/0000,/lock/0001,依此类推。
且在释放锁的时候会删除该节点。
同时,如果发现创建的节点不是父节点下的第一个节点,则该节点会去监听前一个 EPHEMERAL_SEQUENTIAL【节点删除】事件消息,一旦发现前一个 EPHEMERAL_SEQUENTIAL 节点被删除,则收到消息的线程会获得锁。
使用 ZK 实现分布式锁的落地方案:
使用 ZK 的临时节点和有序节点,每个线程获取锁就是在 ZK 创建一个临时有序的节点,比如在 /lock/ 目录下。
创建节点成功后,获取 /lock 目录下的所有临时节点,再判断当前线程创建的节点是否是所有的节点的序号最小的节点。
如果当前线程创建的节点是所有节点序号最小的节点,则认为获取锁成功。
如果当前线程创建的节点不是所有节点序号最小的节点,则对节点序号的前一个节点添加一个事件监听。
ZAB 协议
ZAB 协议是为分布式协调服务 Zookeeper 专门设计的一种支持崩溃恢复的原子广播协议。
ZAB 协议包括两种基本的模式:崩溃恢复和消息广播。
当整个zookeeper集群刚刚启动或者Leader服务器宕机、重启或者网络故障导致不存在过半的服务器与Leader服务器保持正常通信时,所有进程(服务器)进入崩溃恢复模式,首先选举产生新的Leader服务器,然后集群中Follower服务器开始与新的Leader服务器进行数据同步,当集群中超过半数机器与该Leader服务器完成数据同步之后,退出恢复模式进入消息广播模式,Leader服务器开始接收客户端的事务请求生成事物提案来进行事务请求处理。
server角色
Leader
(1)事务请求的唯一调度和处理者,保证集群事务处理的顺序性
(2)集群内部各服务的调度者
Follower
(1)处理客户端的非事务请求,转发事务请求给 Leader 服务器
(2)参与事务请求 Proposal 的投票
(3)参与 Leader 选举投票
Observer
(1)3.0 版本以后引入的一个服务器角色,在不影响集群事务处理能力的基础上提升集群的非事务处理能力
(2)处理客户端的非事务请求,转发事务请求给 Leader 服务器
(3)不参与任何形式的投票
server 状态
服务器具有四种状态,分别是 LOOKING、FOLLOWING、LEADING、OBSERVING。
looking
(1)LOOKING:寻找 Leader 状态。当服务器处于该状态时,它会认为当前集群中没有 Leader,因此需要进入 Leader 选举状态。
following
(2)FOLLOWING:跟随者状态。表明当前服务器角色是 Follower。
leading
(3)LEADING:领导者状态。表明当前服务器角色是 Leader。
observing
(4)OBSERVING:观察者状态。表明当前服务器角色是 Observer。
ZooKeeper选举
什么时候会选举?
Leader选举是保证分布式数据一致性的关键所在。当Zookeeper集群中的一台服务器出现以下两种情况之一时,需要进入Leader选举。
(1) 服务器初始化启动。
(2) 服务器运行期间无法和Leader保持连接。
选举算法
Zookeeper中Leader的选举采用了三种算法:
LeaderElection
FastLeaderElection
AuthFastLeaderElection
并且在配置文件中是可配置的,对应的配置项为electionAlg
在 3.4.0 后的 Zookeeper 的版本只保留了 TCP 版本的 FastLeaderElection 选举算法。
投票二元组(SID, ZXID)
SID(server id) 服务器的唯一标识
ZXID(zookeeper transaction id) 每个改变 Zookeeper 状态的操作都会形成一个对应的 zxid,并记录到 transaction log 中。这个值越大,表示更新越新。
首次投票
(1) 第一次投票
无论哪种导致进行 Leader 选举,集群的所有机器都处于试图选举出一个 Leader 的状态,即 LOOKING 状态,LOOKING 机器会向所有其他机器发送消息,该消息称为投票。投票中包含了 SID(服务器的唯一标识)和 ZXID(事务ID),(SID, ZXID) 形式来标识一次投票信息。
假定 Zookeeper 由 5 台机器组成,SID 分别为 1、2、3、4、5,ZXID 分别为9、9、9、8、8,并且此时 SID 为 2 的机器是 Leader 机器,某一时刻,1、2 所在机器出现故障,因此集群开始进行 Leader 选举。在第一次投票时,每台机器都会将自己作为投票对象,于是 SID 为 3、4、5 的机器投票情况分别为 (3, 9),(4, 8),(5, 8)。
二次变更投票
(2) 变更投票。
每台机器发出投票后,也会收到其他机器的投票,每台机器会根据一定规则来处理收到的其他机器的投票,并以此来决定是否需要变更自己的投票,这个规则也是整个 Leader 选举算法的核心所在,其中术语描述如下
vote_sid 接收到的投票中所推举Leader服务器的SID。
vote_zxid 接收到的投票中所推举Leader服务器的ZXID。
self_sid 当前服务器自己的SID。
self_zxid 当前服务器自己的ZXID。
(vote_sid, vote_zxid) 和 (self_sid, self_zxid) 对比的过程。
规则一:如果 vote_zxid 大于 self_zxid,就认可当前收到的投票,并再次将该投票发送出去。
规则二:如果 vote_zxid 小于 self_zxid,那么坚持自己的投票,不做任何变更。
规则三:如果 vote_zxid 等于 self_zxid,那么就对比两者的 SID,如果 vote_sid 大于 self_sid,那么就认可当前收到的投票,并再次将该投票发送出去。
规则四:如果 vote_zxid 等于 self_zxid,并且 vote_sid 小于 self_sid,那么坚持自己的投票,不做任何变更。
确定leader
(3) 确定Leader。
经过第二轮投票后,集群中的每台机器都会再次接收到其他机器的投票,然后开始统计投票,如果一台机器收到了超过半数的相同投票,那么这个投票对应的 SID 机器即为 Leader。此时 Server3 将成为 Leader。
由上面规则可知,通常哪台服务器上的数据越新(ZXID 会越大),其成为 Leader 的可能性越大,也就越能够保证数据的恢复。如果 ZXID 相同,则 SID 越大机会越大。
启动时选举举例分析
若进行Leader选举,则至少需要两台机器,这里选取3台机器组成的服务器集群为例。在集群初始化阶段,当有一台服务器Server1启动时,其单独无法进行和完成Leader选举,当第二台服务器Server2启动时,此时两台机器可以相互通信,每台机器都试图找到Leader,于是进入Leader选举过程。选举过程如下
(1) 每个 Server 发出一个投票。由于是初始情况,Server1 和 Server2 都会将自己作为 Leader 服务器来进行投票,每次投票会包含所推举的服务器的 server_id 和 ZXID,使用 (server_id, ZXID) 来表示,此时 Server1 的投票为 (1, 0),Server2 的投票为 (2, 0),然后各自将这个投票发给集群中其他机器。
(2) 接受来自各个服务器的投票。集群的每个服务器收到投票后,首先判断该投票的有效性,如检查是否是本轮投票、是否来自 LOOKING 状态的服务器。
(3) 处理投票。针对每一个投票,服务器都需要将别人的投票和自己的投票进行PK,PK规则如下
- 优先检查 ZXID。ZXID 比较大的服务器优先作为 Leader。
- 如果 ZXID 相同,那么就比较 server_id, server_id 较大的服务器作为 Leader 服务器。
对于 Server1 而言,它的投票是 (1, 0),接收 Server2 的投票为 (2, 0),首先会比较两者的 ZXID,均为 0,再比较 server_id,此时 Server2 的 server_id 最大,于是更新自己的投票为 (2, 0),然后重新投票,对于 Server2 而言,其无须更新自己的投票,只是再次向集群中所有机器发出上一次投票信息即可。
(4) 统计投票。每次投票后,服务器都会统计投票信息,判断是否已经有过半机器接受到相同的投票信息,对于 Server1, Server2 而言,都统计出集群中已经有两台机器接受了 (2, 0) 的投票信息,此时便认为已经选出了Leader。
(5) 改变服务器状态。一旦确定了Leader,每个服务器就会更新自己的状态,如果是Follower,那么就变更为FOLLOWING,如果是Leader,就变更为LEADING。
运行时选举举例分析
在 Zookeeper 运行期间,Leader 与非 Leader 服务器各司其职,即便当有非 Leader 服务器宕机或新加入,此时也不会影响 Leader,但是一旦 Leader 服务器挂了,那么整个集群将暂停对外服务,进入新一轮 Leader 选举,其过程和启动时期的 Leader 选举过程基本一致。
假设正在运行的有 Server1, Server2, Server3 三台服务器,当前 Leader 是 Server2,若某一时刻 Leader 挂了,此时便开始 Leader 选举。选举过程如下
(1) 变更状态。Leader 宕机后,余下的非 Observer 服务器都会将自己的服务器状态变更为 LOOKING,然后开始进入 Leader 选举过程。
(2) 每个 Server 会发出一个投票。在运行期间,每个服务器上的 ZXID 可能不同,此时假定 Server1 的 ZXID 为 123,Server3 的 ZXID 为 122;在第一轮投票中,Server1 和 Server3 都会投自己,产生投票 (1, 123) 和 (3, 122),然后各自将投票发送给集群中所有机器。
(3) 接收来自各个服务器的投票。与启动时过程相同。
(4) 处理投票。与启动时过程相同。 server1 发现 server3 的 zxid 比自己小,则继续投自己一票 (1, 123), server3 发现 server1 的 zxid 比自己大,更新自己的投票来支持 server1 , 重新投票 (1, 123)
(5) 统计投票。与启动时过程相同。 此时,Server1 将会成为 Leader。
(6) 改变服务器的状态。与启动时过程相同。
Zookeeper面试题
https://www.cnblogs.com/lanqiu5ge/p/9405601.html
ZooKeeper数据同步
整个集群完成Leader选举之后,Learner(Follower和Observer的统称)会向Leader服务器进行注册。当Learner服务器向Leader服务器完成注册后,进入数据同步环节。
数据同步流程:(均以消息传递的方式进行)
1、Learner向Learder注册
2、数据同步
3、同步确认
Zookeeper的数据同步通常分为四类:
1、直接差异化同步(DIFF同步)
2、先回滚再差异化同步(TRUNC+DIFF同步)
3、仅回滚同步(TRUNC同步)
4、全量同步(SNAP同步)
在进行数据同步前,Leader服务器会完成数据同步初始化:peerLastZxid 从learner服务器注册时发送的ACKEPOCH消息中提取lastZxid(该Learner服务器最后处理的ZXID)minCommittedLog Leader服务器Proposal缓存队列committedLog中最小ZXIDmaxCommittedLog Leader服务器Proposal缓存队列committedLog中最大ZXID
直接差异化同步(DIFF同步)
场景:peerLastZxid介于minCommittedLog和maxCommittedLog之间
先回滚再差异化同步(TRUNC+DIFF同步)
当新的Leader服务器发现某个Learner服务器包含了一条自己没有的事务记录,那么就需要让该Learner服务器进行事务回滚–回滚到Leader服务器上存在的,同时也是最接近于peerLastZxid的ZXID
仅回滚同步(TRUNC同步)
peerLastZxid 大于 maxCommittedLog
全量同步(SNAP同步)
场景一:peerLastZxid 小于 minCommittedLog
场景二:Leader服务器上没有Proposal缓存队列且peerLastZxid不等于lastProcessZxid
安装和使用ZooKeeper
docker-compose安装部署zookeeper集群
zookeeper - docker hub
https://hub.docker.com/_/zookeeper
docker-compose.yml配置文件
创建文件 docker-compose.yml
在 docker-compose.yml 所在目录下执行 docker-compose up -d 在后台启动所有的容器。
控制台日志重定向到日志文件
默认 zk 将 stdout/stderr 打印到 控制台,通过配置 ZOO_LOG4J_PROP 环境变量,可以将日志重定向到 /logs 目录
例如docker run --name some-zookeeper --restart always -e ZOO_LOG4J_PROP="INFO,ROLLINGFILE" zookeeper
这将会使日志写入都 /logs/zookeeper.log
增加 -e ZOO_LOG4J_PROP="INFO,ROLLINGFILE" 配置后报下面的错误
错误
log4j:ERROR setFile(null,true) call failed.
java.io.FileNotFoundException: ./zookeeper.log (Permission denied)
需要映射的数据目录
zookeeper官方镜像,数据目录是 /data, 日志目录是 /datalog, 配置目录是 /conf
注意:zk 的 transaction log 文件所在的磁盘性能是影响 zk 性能的关键因素。
为了容器重启后 zk 数据不丢失,一般需要将容器内的 /data 目录映射到宿主机,为了方便看日志需要将 /datalog 和 /logs 映射出来。
查看容器状态
在 docker-compose.yml 所在目录中执行 docker-compose ps 只查看此 compose.yml 描述的容器状态
# docker-compose ps
Name Command State Ports
-------------------------------------------------------------------------------------------------
zookeeper_1 /docker-entrypoint.sh zkSe ... Up 0.0.0.0:2181->2181/tcp, 2888/tcp, 3888/tcp
zookeeper_2 /docker-entrypoint.sh zkSe ... Up 0.0.0.0:2182->2181/tcp, 2888/tcp, 3888/tcp
zookeeper_3 /docker-entrypoint.sh zkSe ... Up 0.0.0.0:2183->2181/tcp, 2888/tcp, 3888/tcp
当然也可以直接 docker ps 查看所有容器的状态
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
936ca6a90d3f zookeeper:3.4.10 "/docker-entrypoint.…" 27 minutes ago Up 27 minutes 2888/tcp, 0.0.0.0:2181->2181/tcp, 3888/tcp zookeeper_1
475f0ec7ef1b zookeeper:3.4.10 "/docker-entrypoint.…" 27 minutes ago Up 27 minutes 2888/tcp, 3888/tcp, 0.0.0.0:2182->2181/tcp zookeeper_2
d8b28308b6eb zookeeper:3.4.10 "/docker-entrypoint.…" 27 minutes ago Up 27 minutes 2888/tcp, 3888/tcp, 0.0.0.0:2183->2181/tcp zookeeper_3
查看zk服务器状态
依次进入 3 个 zk 容器执行 zkServer.sh status
zoo1
# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /conf/zoo.cfg
Mode: follower
zoo2
# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /conf/zoo.cfg
Mode: follower
zoo3
# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /conf/zoo.cfg
Mode: leader
docker-compose搭建zookeeper集群
https://www.jianshu.com/p/98bb69256cc3
Docker下Zookeeper集群搭建
http://jaychang.cn/2018/05/05/Docker%E4%B8%8BZookeeper%E9%9B%86%E7%BE%A4%E6%90%AD%E5%BB%BA/
安装docker-zkui
qnib/zkui
https://hub.docker.com/r/qnib/zkui/
Docker部署Zookeeper容器
https://www.cnblogs.com/wkaca7114/p/docker-zookeeper.html
Linux安装ZooKeeper
可以从 https://zookeeper.apache.org/releases.html 下载 ZooKeeper 安装包,然后解压。
Zookeeper 启动需要一个名为 zoo.cfg 的配置文件,解压后在 conf 目录中得到一个官方示例文件 zoo_sample.cfg, 如果使用默认配置启动,直接将该文件复制并且改名为 zoo.cfg 即可。里面可以配置端口号,是否启用集群等等。
进入 ZooKeeper 的 bin 目录。
启动 zk zkServer start
停止 zk zkServer stop
Zookeeper安装和部署
https://www.cnblogs.com/Lzf127/p/7155316.html
MAC brew 安装 zookeeper
查看信息 brew info zookeeper
$ brew info zookeeper
zookeeper: stable 3.5.8 (bottled), HEAD
Centralized server for distributed coordination of services
https://zookeeper.apache.org/
Not installed
From: https://github.com/Homebrew/homebrew-core/blob/HEAD/Formula/zookeeper.rb
License: Apache-2.0
==> Dependencies
Build: ant ✘, autoconf ✘, automake ✘, libtool ✘, pkg-config ✘
==> Options
--HEAD
Install HEAD version
==> Caveats
To have launchd start zookeeper now and restart at login:
brew services start zookeeper
Or, if you don't want/need a background service you can just run:
zkServer start
==> Analytics
install: 6,094 (30 days), 20,764 (90 days), 79,565 (365 days)
install-on-request: 1,934 (30 days), 6,624 (90 days), 25,871 (365 days)
build-error: 0 (30 days)
安装 brew install zookeeper
安装目录
/usr/local/Cellar/zookeeper/3.5.8
配置文件
/usr/local/etc/zookeeper/zoo.cfg
启动 zookeeper
brew services start zookeeper
默认端口是 2181
NoSuchMethodError java.nio.ByteBuffer.clear()
zk版本:2.5.8
zk启动后报错:
2021-05-25 18:17:21 NIOServerCnxnFactory [ERROR] Thread Thread[main,5,main] died
java.lang.NoSuchMethodError: java.nio.ByteBuffer.clear()Ljava/nio/ByteBuffer;
at org.apache.jute.BinaryOutputArchive.stringToByteBuffer(BinaryOutputArchive.java:77)
at org.apache.jute.BinaryOutputArchive.writeString(BinaryOutputArchive.java:107)
at org.apache.zookeeper.data.Id.serialize(Id.java:51)
原因:
3.5.x 版本的 ZooKeeper 和 jdk8 不兼容
3.5.x 版本的 ZooKeeper 是用 jdk9 及以上编译的,使用了 jdk8 中没有的方法,无法在 jdk8 版本中运行。
解决:
1、升级到jdk9及以上
2、zk降级到 3.4.x
想用 brew 安装 3.4.x 版本的 zk,太费劲了,改为用 docker 启动 zk 和 kafka
Kafka with Zookeeper 3.5.7 Crash NoSuchMethodError: java.nio.ByteBuffer.flip()
https://stackoverflow.com/questions/60612999/kafka-with-zookeeper-3-5-7-crash-nosuchmethoderror-java-nio-bytebuffer-flip
zkCli命令行
连接 zk 集群 zkCli -server localhost:2181
如果需要连接其他的 ZooKeeper 服务器,将 localhost 修改为服务器 IP 或域名即可。
zkCli -server localhost:2181
/usr/bin/java
Connecting to localhost:2181
Welcome to ZooKeeper!
JLine support is enabled
[zk: localhost:2181(CONNECTING) 0]
ls 查看列表
ls /xxx/... 可以查看子节点列表。
get 看节点内容
get /xxx/... 可以查看节点内容。
delete 删除节点
delete /xxx/... 可以删除节点。
上一篇 Apache-Curator
下一篇 Spring-动态切换数据源
页面信息
location:protocol: host: hostname: origin: pathname: href: document:referrer: navigator:platform: userAgent: