关于DPM(Deformable Part Model)算法中模型结构的解释
关于可变部件模型的描述在作者[2010 PAMI]Object Detection with Discriminatively Trained Part Based Models(中文翻译见 http://blog.csdn.net/masibuaa/article/details/17924671#t5 )的论文中已经有说明:
含有$n$个部件的目标模型可以形式上定义为一个$(n+2)$元组:$(F_0,P_1,…, P_n, b)$,$F_0$是根滤波器,$P_i$是第$i$个部件的模型,$b$是表示偏差的实数值。每个部件模型用一个三元组定义:$(F_i,v_i, d_i)$,$F_i$是第$i$个部件的滤波器;$v_i$是一个二维向量,指定第$i$个滤波器的锚点位置(anchor position,即未发生形变时的标准位置) 相对于根的坐标;$d_i$是一个四维向量,指定了一个二次函数的参数,此二次函数表示部件的每个可能位置相对于锚点位置的变形花费(deformation cost)。
但是有了这个说明我们在看源码时还是会有很多不明白的地方,刚开始困扰我很长时间,经过一段时间的分析,有了一定的理解,下面是我对这个模型的分析,如有不妥之处,请大家留言指正。
我分析的源码版本是voc-release3.1,从第4版开始加入了语法模型,更加复杂了,这里不讨论。
分析模型结构体主要看initmodel.m这个文件,通过看他如何初始化模型,我们可以明白其中大多数字段的含义。
训练好的模型m文件结构截图
在这之前,我们可以在matlab中打开一两个源码中自带的训练好的模型m文件,看看是什么样的。
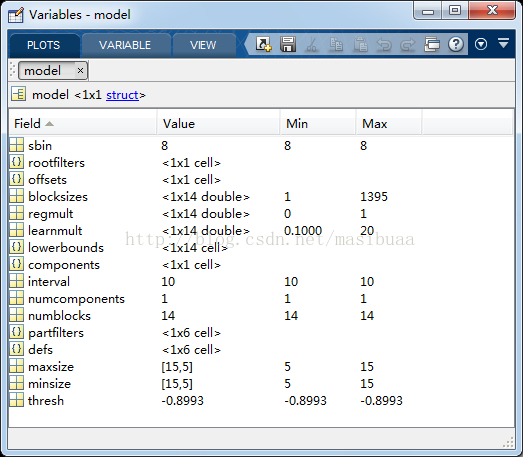
inria_final.mat(Inria数据集上训练的单组件模型)
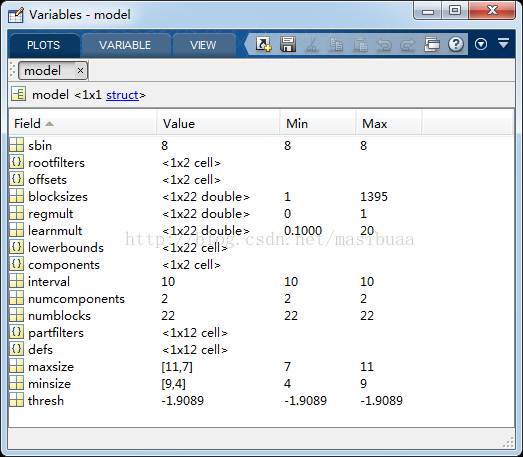
person_final.mat(VOC2007数据集上训练的2组件人体模型)
模型中各字段详细解释
下面我会依次对各个字段做详细解释
(1) sbin,整型标量
sbin是HOG特征中cell的尺寸,即cell的尺寸为sbin * sbin
定义cell是为了将像素级特征聚合成为基于cell的特征$C(i,j),0 \leq i \leq |(w-1)/k|,0 \leq j \leq |(h-1)/k|$,参见[2010 PAMI]论文6.1.2 空间聚合( http://blog.csdn.net/masibuaa/article/details/17924671#t20 ),这里的k就是cell尺寸sbin,这样可以更明确的理解sbin的用处。(2) interval,整型标量
HOG金字塔每组的层数(3) numblocks,整型标量
模型中总的数据块的个数(4) numcomponents,整型标量
组件的个数(含多少个组件模型)(5) blocksizes,double数组,长度等于numblock
blocksizes[]数组的元素个数等于numblock,指明每个数据块的大小,
所以,想知道哪个数据的大小,就先找到他的数据块标识,然后去blocksizes[]数组查找对应的数据块大小。(6) regmult,double数组,长度等于numblock
还不清楚干什么的(7) learnmult,double数组,长度等于numblock
还不清楚干什么的(8) lowerbounds,cell类型数组,长度等于numblock
每个数据块的数据值的下界,lowerbounds[]数组的元素个数等于numblock。
假如某个数据块的数据是向量或矩阵的话,则对应的lowerbounds元素值也是一个下界向量或矩阵(9) maxsize,二元组
所有组件的根滤波器的[高度 宽度]的最大值,maxsize是统计所有组件的根滤波器的尺寸获得的。(10) minsize,二元组
所有组件的根滤波器的[高度 宽度]的最小值,minsize是统计所有组件的根滤波器的尺寸获得的。(11) thresh,double类型标量
保证高召回率需要的得分阈值,根据训练结果计算得到的。
也就是说,如果用此模型进行目标检测时,将得分阈值设为thresh能够保证很高的召回率(recall rate),但是同时精度肯定就低了。(12) rootfilters,cell类型数组,长度为组件个数
根滤波器数组,其每个元素表示一个组件模型的根滤波器的信息,每个元素包括3个字段:size:根滤波器的尺寸,以cell为单位,$w \times h$
w:根滤波器的参数向量,维数为$(w \times h) \times 31$
blocklabel:此根滤波器所在的数据块标识
(13) partfilters,cell类型数组,长度为模型中所有组件的部件的个数之和
部件滤波器数组,其每个元素表示一个部件滤波器的信息,每个元素包括4个字段,注意:所有组件的部件是连续编号的w:部件滤波器的参数向量,维数为$(w \times h) \times 31$
partner:此部件对应的伙伴部件(对称部件)的索引,如果partner的值为0,表示此部件没有伙伴部件。
fake:是否假部件,值为1表示此部件是假部件,假部件不需要blocklabel
blocklabel:此部件滤波器所在的数据块标识
(14) defs,cell类型数组,长度为模型中所有组件的部件的个数之和
部件的锚点数组 (变形信息数组),每个元素表示对应部件的可变形信息。注意:所有组件的部件在defs中也是连续编号的。每个元素包含3个字段:anchor:部件的锚点坐标,即部件未变形时的左上角点坐标,参见论文[2010 PAMI]中的公式(3)中的$v_i$变量
w:w是一个四维向量,指明部件的变形花费函数的参数,参见论文[2010 PAMI]中的公式(2)中的$d_i$变量
blocklabel:所在的数据块标识
(15) offsets,cell类型数组,长度为组件个数
偏移量数组,每个元素表示对应组件模型的偏移量,每个元素又含有2个字段w:组件的偏移量,是个实数值
blocklabel:所在的数据块标识
(16) components,cell类型数组,长度为组件个数
组件信息数组,每个元素存储一个组件模型的信息,每个元素又包含7个字段:rootindex:根滤波器的索引,指出组件的根滤波器在
rootfilters[]数组的位置offsetindex:组件的偏移量索引,指出组件的偏移量在
offsets[]数组的位置part:组件的部件信息数组,长度为该组件的部件个数,每个元素表示一个部件,每个元素又有2个字段:
partindex:部件的索引,指出此部件在partfilters[]数组的位置,注意:所有组件的部件是连续编号的
defindex:部件的锚点数组索引,指出此部件的锚点在defs[]数组的位置,注意:所有组件的部件是连续编号的dim:组件的维数(至于这个值具体是怎么计算来的,我现在还不清楚,弄清楚了来更新)
numblocks:组件所占的数据块个数(需要多少个数据块来存储此组件模型)
x1,y1,x2,y2:包围盒预测参数
一些需要解释的地方
关于模型中的blocklabel的理解说明
模型中有好多数组,例如rootfilters[],partfilters[],defs[],offsets[],这些数组的数据是以块block为单位进行存储的,通过块标识blocklabel来识别哪个数据位于哪个块上,所以上述数组的每个成员都有一个blocklabel域,来指明此数据所在的块。numblock是总的数据块个数。blocksizes[]数组的元素个数等于numblock,指明每个数据块的大小,
所以,想知道哪个数据的大小,就先找到他的数据块标识,然后去blocksizes[]数组查找对应的数据块大小。
关于部件的伙伴partner的解释
在voc-release3.1中,模型是关于中轴对称的,所以就有了**伙伴部件(或称为对称部件)**的概念。注意:从第4版开始模型不再要求是对称的。一个部件存在伙伴,就说明有和此部件对称的部件。伙伴部件的参数向量和此部件的参数向量w完全相同,一个部件和其伙伴部件是关于模型的中轴对称的,所以不需要重复存储参数向量w,这样,就产生了一些假(fake)部件,它们只有一个空壳。假部件(fake=1)没有blocklabel,因为它们不需要数据块来存储信息,它们的信息存储在对应的伙伴部件中。如果partner的值为0,表示此部件没有伙伴部件。
关于偏移量offset的解释
偏移量offset就是加在每个组件模型的得分公式最后的一个实数值,参见论文[2010 PAMI]中的公式(2)中的b值。
关于锚点数组defs的解释
一开始我以为def是定义definition的缩写,但解释不通,现在知道了,def是可变形deformable的缩写,所以defs数组中存储的是所有部件的变形参数。anchor,锚点坐标,是部件未发生移动时的坐标,即理想状况下的位置,更详细的说,anchor是部件未变形时的左上角点坐标。w,是个4维向量,指明部件i的变形花费函数的参数,参见论文[2010 PAMI]中的公式(2)中的$d_i$变量。通过分析源码发现w中4个参数分别对应这4个偏移量$[\Delta x^2, \Delta x, \Delta y^2, \Delta y]$(分析可视化变形花费的代码时确定的,在文件visualizemodel.m中)。
关于每个cell的特征向量的维数为什么是31维的解释
设C是聚合有9个对比度不敏感方向的像素级特征映射而获得的基于cell的特征映射,D是聚合有18个对比度敏感方向的像素级特征而获得的基于cell的特征映射。用4种不同的归一化方法对$C(i,j)$和$D(i,j)$进行归一化和截断(限幅),可以获得一个$4 \times (9+18)=108$维的特征向量$F(i,j)$。实际中我们使用此108维向量的一个解析投影,此投影由下面几个统计量定义:27个在不同归一化因子上的累加和(即列的和),$F$中的每个方向通道对应一个;以及4个在不同方向(9维对比度不敏感方向)上的累加和(即行的和),每个归一化因子对应一个。cell尺寸$k=8$,截断(限幅)阈值$α=0.2$。最终的特征映射是31维向量$G(i,j)$,其中27维对应不同的方向通道(9个对比度不敏感方向和18个对比度敏感方向),剩下4维表示$(i,j)$周围4个cell组成的block的梯度能量。详见[2010 PAMI]论文中6.2节 PCA和解析降维( http://blog.csdn.net/masibuaa/article/details/17924671#t22 )。
模型初始化函数initmodel.m源码详细注释
明白了上述内容,初始化的过程就很容易看懂了,初始化的过程在下面的源码上有注释:
function model = initmodel(pos, sbin, size)
% 初始化模型结构
% 参数
% pos:用来训练此模型的正样本数组
% sbin:HOG特征的最小单位,cell的长度
% size:根滤波器尺寸
% 如果不提供根滤波器的尺寸,则根据正样本的长宽比统计信息计算得出
%
% model = initmodel(pos, sbin, size)
% Initialize model structure.
% If not supplied,the dimensions of the model template are computed from statistics in the postive examples.
%
% 关于cell尺寸sbin的解释:
% 将像素级特征聚合成为基于cell的特征C(i,j),0<=i<=|(w-1)/k|,0<=j<=|(h-1)/k|,参见[2010 PAMI]论文6.1.2 空间聚合,
% 这里的k就是cell尺寸sbin,这样可以更明确的理解sbin的用处
%
% 关于部件的伙伴partner的解释:
% 在voc-release3.1中,模型是关于中轴对称的,所以就有了伙伴部件(或称为对称部件)的概念。注意:从第4版开始模型不再要求是对称的。
% 一个部件存在伙伴,就说明有和此部件对称的部件。伙伴部件的参数向量和此部件的参数向量w完全相同,一个部件和其伙伴部件是关于模型的中轴对称的,
% 所以不需要重复存储参数向量w,这样,就产生了一些假(fake)部件,它们只有一个空壳。假部件(fake=1)没有blocklabel,因为它们不需要数据块来存储信息,
% 它们的信息存储在对应的伙伴部件中。如果partner的值为0,表示此部件没有伙伴部件。
%
% 关于每个cell的特征向量的维数为什么是31维的解释:
% 设C是聚合有9个对比度不敏感方向的像素级特征映射而获得的基于cell的特征映射,D是聚合有18个对比度敏感方向的像素级特征而获得的基于cell的特征映射。
% 用4种不同的归一化方法对C(i,j)和D(i,j)进行归一化和截断(限幅),可以获得一个4*(9+18)=108维的特征向量F(i,j)。
% 实际中我们使用此108维向量的一个解析投影,此投影由下面几个统计量定义:
% 27个在不同归一化因子上的累加和(即列的和),F中的每个方向通道对应一个;以及4个在不同方向(9维对比度不敏感方向)上的累加和(即行的和),每个归一化因子对应一个。
% cell尺寸k=8,截断(限幅)阈值α=0.2。最终的特征映射是31维向量G(i,j),其中27维对应不同的方向通道(9个对比度不敏感方向和18个对比度敏感方向),
% 剩下4维表示(i,j)周围4个cell组成的block的梯度能量。详见[2010 PAMI]论文中6.2节 PCA和解析降维
%
% 关于模型中的blocklabel的理解说明:
% 模型中有好多数组,例如rootfilters[],partfilters[],defs[],offsets[],这些数组的数据是以块block为单位进行存储的,
% 通过块标识blocklabel来识别哪个数据位于哪个块上,所以上述数组的每个成员都有一个blocklabel域,来指明此数据所在的块。
% numblock是总的数据块个数(注意不是总的部件个数,刚开始理解错了),blocksizes[]数组的元素个数等于numblock,指明每个数据块的大小,
% 所以,想知道哪个数据的大小,就先找到他的数据块标识,然后去blocksizes[]数组查找对应的数据块大小。
%
% 关于偏移量offset的解释:
% 偏移量offset就是加在每个组件模型的得分公式最后的一个实数值,参见论文[2010 PAMI]中的公式(2)中的b值
%
% 关于锚点坐标数组defs[]的解释:
% 一开始我以为def是定义definition的缩写,但解释不通,现在知道了,def是可变形deformable的缩写,所以defs数组中存储的是所有部件的变形参数
% anchor,锚点坐标,是部件未发生移动时的坐标,即理想状况下的位置,更详细的说,anchor是部件未变形时的左上角点坐标
% w,是个4维向量,指明部件i的变形花费函数的参数,参见论文[2010 PAMI]中的公式(2)中的di变量
% 通过分析源码发现w中4个参数分别对应这4个偏移量[Δx^2, Δx, Δy^2, Δy](分析可视化变形花费的代码时确定的,在文件visualizemodel.m中)
%
% model.sbin HOG cell的尺寸
% model.interval 金字塔每组的层数
% model.numblocks 总的数据块个数
% model.numcomponents 组件的个数(含多少个组件模型)
% model.blocksizes 每个数据块的大小,blocksizes[]数组的元素个数等于numblock
% model.regmult
% model.learnmult
% model.lowerbounds 每个数据块的数据值的下界,lowerbounds[]数组的元素个数等于numblock
%假如某个数据块的数据是向量或矩阵的话,则对应的lowerbounds元素值也是一个下界向量或矩阵
% model.maxsize 所有组件的根滤波器的[高度 宽度]的最大值
% model.minsize 所有组件的根滤波器的[高度 宽度]的最小值
% model.rootfilters{i} 组件i的根滤波器,根滤波器数组的长度等于组件个数
% .size 组件i的根滤波器的尺寸(以cell为单位),w*h
% .w 组件i的根滤波器向量,维数为(w*h)*31
% .blocklabel 组件i的根滤波器所在的数据块标识
% model.partfilters{i} 第i个部件滤波器,部件滤波器数组的长度等于所有组件的部件个数的总和,注意:所有组件模型的part是连续编号的
% .w 第i个部件滤波器向量,维数为(w*h)*31
% .blocklabel 第i个部件滤波器所在的数据块标识
% model.defs{i} 第i个部件的锚点,部件锚点数组的长度等于所有组件的部件个数的总和,所有组件模型的part是连续编号的
% .anchor 第i个部件的锚点坐标,即部件i未变形时的左上角点坐标,参见论文[2010 PAMI]中的公式(3)中的vi变量
% .w w是一个四维向量,指明部件i的变形花费函数的参数,参见论文[2010 PAMI]中的公式(2)中的di变量
% .blocklabel 第i个部件的锚点所在的数据块标识
% model.offsets{i} 第i个组件的偏移量,偏移量数组的长度等于组件个数
% .w 第i个组件的偏移量,是个实数值
% .blocklabel 第i个组件的偏移量所在的数据块标识
% model.components{i} 第i个组件的信息
% .rootindex 第i个组件的根滤波器的索引,指出组件i的根滤波器在rootfilters[]数组的位置
% .parts{j} 第i个组件的第j个部件的信息
% .partindex 第i个组件的第j个部件的部件滤波器数组索引,指出在partfilters[]数组的位置,注意:所有组件模型的part是连续编号的
% .defindex 第i个组件的第j个部件的锚点坐标数组索引,指出在defs[]数组的位置,注意:所有组件模型的part是连续编号的
% .offsetindex 第i个组件的偏移量的索引,指出在offsets[]数组的位置
% .dim 第i个组件的维数
% .numblocks 第i个组件模型的数据块个数(需要多少个数据块来存储组件模型i),所有组件的numblocks之和等于整个模型的numblocks
% 计算此组正样本典型的高宽比aspect
% pick mode of aspect ratios
h = [pos(:).y2]' - [pos(:).y1]' + 1; % 所有正样本的高度数组
w = [pos(:).x2]' - [pos(:).x1]' + 1; % 所有正样本的宽度数组
xx = -2:.02:2;
filter = exp(-[-100:100].^2/400);
aspects = hist(log(h./w), xx);
aspects = convn(aspects, filter, 'same');
[peak, I] = max(aspects);
aspect = exp(xx(I));
% 选择根滤波器的面积(以像素为单位)
% pick 20 percentile area
areas = sort(h.*w); % 对面积从小到大排序
area = areas(floor(length(areas) * 0.2)); % 选择从小到大20%处的面积
area = max(min(area, 5000), 3000); % 面积最大值5000,最小值3000
% 根据以上计算出的高宽比和面积,得到根滤波器的高度和宽度(以像素为单位)
% pick dimensions
w = sqrt(area/aspect); % 根的宽度(以像素为单位),area=w*h,aspect=h/w,所以area/aspect = (w*h)*(w/h) = w^2
h = w*aspect; % 根的高度(以像素为单位)
% HOG cell的尺寸,默认为8
% size of HOG features
if nargin < 4
model.sbin = 8;
else
model.sbin = sbin;
end
% 设定根滤波器尺寸(以cell为单位)
% size of root filter
if nargin < 5
model.rootfilters{1}.size = [round(h/model.sbin) round(w/model.sbin)]; % 以像素为单位的根的尺寸除以cell的尺寸,等于以cell为单位的根的尺寸
else
model.rootfilters{1}.size = size;
end
% 初始化偏移量数组
% 偏移量offset就是加在每个组件模型的得分公式最后的一个实数值,参见论文[2010 PAMI]中的公式(2)中的b值
model.offsets{1}.w = 0; % 组件1的偏移量的初始值设为0
model.offsets{1}.blocklabel = 1; % 组件1的偏移量的块标识,值为1表明组件1的偏移量是模型中的第一个数据块
model.blocksizes(1) = 1; % 第一个数据块的大小,值为1,因为只用来存储组件1的偏移量,即一个实数值
model.regmult(1) = 0;
model.learnmult(1) = 20;
model.lowerbounds{1} = -100; % 第一个数据块的数据值的下界,-100
% 初始化根滤波器数组
model.rootfilters{1}.w = zeros([model.rootfilters{1}.size 31]); % 组件1的初始根滤波器的向量值为全0
height = model.rootfilters{1}.size(1); % 组件1的根滤波器的高度
% root filter is symmetric 注意:根滤波器是左右对称的
width = ceil(model.rootfilters{1}.size(2)/2); % 组件1的根滤波器的宽度的一半
model.rootfilters{1}.blocklabel = 2; % 组件1的根滤波器的块标识
model.blocksizes(2) = width * height * 31; % 存储组件1的根滤波器的数据块(第二个数据块)的大小,由于根滤波器是左右对称的,所以是h*(w/2)*31
model.regmult(2) = 1;
model.learnmult(2) = 1;
model.lowerbounds{2} = -100*ones(model.blocksizes(2),1); % 第二个数据块的值的下界,-100
% 初始化组件模型
% set up one component model
model.components{1}.rootindex = 1; % 组件1的根滤波器数组索引
model.components{1}.offsetindex = 1; % 组件1的偏移量数组索引
model.components{1}.parts = {}; % 组件1的部件信息,当前为空
model.components{1}.dim = 2 + model.blocksizes(1) + model.blocksizes(2); % 组件1的模型参数向量维数
model.components{1}.numblocks = 2; % 组件1的数据块个数
% 初始化剩下的模型参数
% initialize the rest of the model structure
model.interval = 10; % 金字塔每组的层数
model.numcomponents = 1; % 模型的组件个数
model.numblocks = 2; % 模型的总的数据块个数
model.partfilters = {}; % 部件滤波器数组
model.defs = {}; % 部件锚点数组
model.maxsize = model.rootfilters{1}.size; % 所有组件的根滤波器的最大值
model.minsize = model.rootfilters{1}.size; % 所有组件的根滤波器的最小值
相关资源
注:以下网页有可能已打不开,请自行Google
- Deformable Part Model 相关网页:
http://www.cs.berkeley.edu/~rbg/latent/index.html - Pedro Felzenszwalb的个人主页:
http://cs.brown.edu/~pff/ - PASCAL VOC 目标检测挑战:
http://pascallin.ecs.soton.ac.uk/challenges/VOC/
相关博文
- A Discriminatively Trained, Multiscale, Deformable Part Model [CVPR 2008] 中文翻译
http://blog.csdn.net/masibuaa/article/details/17533419 - Object Detection with Discriminatively Trained Part Based Models [PAMI 2010]中文翻译
http://blog.csdn.net/masibuaa/article/details/17924671 - 有关可变形部件模型(Deformable Part Model)的一些说明
http://blog.csdn.net/masibuaa/article/details/17534151
相关源码运行实验
- 在Windows下运行Felzenszwalb的Deformable Part Models(voc-release4.01)目标检测matlab源码
http://blog.csdn.net/masibuaa/article/details/17577195 - 在Windows下运行Felzenszwalb的star-cascade DPM(Deformable Part Models)目标检测Matlab源码
http://blog.csdn.net/masibuaa/article/details/20651005 - 在windows下运行Felzenszwalb的Deformable Part Model(DPM)源码voc-release3.1来训练自己的模型
http://masikkk.com/article/DPM-voc-release3.1-windows-run/ - 用DPM(Deformable Part Model,voc-release3.1)算法在INRIA数据集上训练自己的人体检测模型
http://blog.csdn.net/masibuaa/article/details/25221103
上一篇 关于DPM(Deformable Part Model)算法中模型可视化的解释
下一篇 用DPM(Deformable Part Model,voc-release3.1)算法在INRIA数据集上训练自己的人体检测模型
页面信息
location:protocol: host: hostname: origin: pathname: href: document:referrer: navigator:platform: userAgent: