Elasticsearch-索引模块
Elasticsearch 索引模块
索引模块
Elasticsearch Guide [7.17] » Index modules
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/index-modules.html
索引的配置参数分为静态配置和动态配置:
- 静态配置只能在创建索引时设置,或在已关闭的索引上设置
- 动态配置可在打开的索引上通过 API
/index/_settings动态修改
静态配置
index.number_of_shards 主分片数
index.number_of_shards 索引的主分片(primary shards)数,默认值是 1
主分片数只能在创建索引时设定,已关闭的索引也无法修改分片数
默认分片数最大为 1024,可通过在每个节点上设置 export ES_JAVA_OPTS="-Des.index.max_number_of_shards=128" 来修改最大分片数限制
分片数设置的一个经验值:当单个分片内数据量小于10万时,查询时merge的网络开销就会大于分片带来的性能提升,再增加分片已经没有意义了
index.number_of_routing_shards 路由分片数
index.number_of_routing_shards 和 index.number_of_shards 一起决定数据如何被路由到主分片上,具体分片公式在 Mapping 映射 -> 元数据字段 -> _routing 字段的解释中。index.number_of_routing_shards 的默认值依赖于主分片的个数,目的是为了允许将索引以 2 为倍数拆分为最多 1024 个分片。例如索引有 5 个主分片,可以以 2 倍一次或多次拆分为 10,20,40,80,160,320,640 个分片,则 index.number_of_routing_shards 默认值为 640。
number_of_routing_shards 的目的是为了后续扩展分片时不需要重新计算哈希,通常是 number_of_shards 整数倍。
index.store.preload 预热索引列表
动态配置
index.number_of_replicas 副本数(默认1,有1个副本)
index.number_of_replicas 每个主分片的副本(replicas)数, 默认值是 1,设为 0 表示禁用副本
index.refresh_interval 刷新间隔
index.refresh_interval 后台定期自动 refresh 操作的间隔,默认值 1 秒,可设为 -1 来禁用 refresh
refresh 操作将内存缓冲区中的数据写入 Lucene segment 使之可读
未显式设置时,分片在 index.search.idle.after 秒未收到 search 请求后会停止后台的定时 refresh 任务,直到再次收到 search 请求。这么做的目的是为了加快批量索引的速度。
index.max_result_window 最大from+size分页数据量
from + size 分页可获取的最大结果数,默认值 10000
修改指定索引的 max_result_window 值
PUT /index_name/_settings
{
"settings": {
"index.max_result_window": 2147483647
}
}
修改全部索引的 max_result_window 值
PUT /_all/_settings
{
"settings": {
"index.max_result_window": 2147483647
}
}
Index Shard Allocation 索引分片分配
https://www.elastic.co/guide/en/elasticsearch/reference/7.6/index-modules-allocation.html
Elasticsearch 的 Index Shard Allocation(索引分片分配) 是集群管理中的核心机制,它决定了如何将索引的分片(主分片和副本分片)分配到集群中的不同节点上。合理的分片分配直接影响集群的性能、可靠性和资源利用率。
分片(Shard)
- 索引被拆分为多个分片(主分片)以提高处理能力和扩展性。
- 每个主分片可以有多个副本分片(Replica),用于高可用和负载均衡。
分片分配的目标
- 负载均衡:避免部分节点过载。
- 高可用性:主分片和副本分片不能分配在同一节点。
- 资源优化:合理利用磁盘、CPU、内存等资源。
- 容灾:通过跨机架(rack)或可用区(zone)分布分片。
Elasticsearch 的分片分配由 Allocation Deciders 模块控制,它根据一系列规则决定是否允许分片分配到某个节点。
索引级分片分配过滤
https://www.elastic.co/guide/en/elasticsearch/reference/7.6/shard-allocation-filtering.html
索引级分片分配允许你针对 单个索引 定义分片分配规则,精确控制其主分片和副本分片的分布。通过配置这些规则,可以实现:
- 定向分配:将索引的分片分配到特定节点(如高性能节点)。
- 资源隔离:避免某些索引占用过多资源,影响其他索引。
- 故障域感知:跨机架(rack)、可用区(zone)分布分片,提高容灾能力。
通过 index.routing.allocation.* 参数,定义索引的分片分配的 包含(include)、排除(exclude) 或 必须满足(require) 的条件:
require分片分配到满足 所有条件 的节点,例如 node.role: hotinclude分片分配到满足 至少一个 条件的节点,例如 disk_type: ssdexclude分片 禁止分配 到满足任意条件的节点,例如 region: us-west
注意:规则优先级 require > include > exclude,如果同时配置 require 和 include,节点必须满足 require 的条件。
支持的节点属性(Attributes):
- 内置属性:_id, _name, _host, _ip, _role(如 data, master)
- 自定义属性:在节点配置中定义,如 rack、zone、disk_type
例1,创建索引时配置,索引的分片必须分配到 ssd 磁盘,需要分配到 data_hot 节点
PUT /my_index
{
"settings": {
"index.routing.allocation.include.node.role": "data_hot",
"index.routing.allocation.require.disk_type": "ssd"
},
"mappings": { ... }
}
例2,动态修改索引配置,设置索引的分片 必须分配到 rack1 或 rack2 机架,禁止分配到 HDD 磁盘节点
PUT /my_index/_settings
{
"index.routing.allocation.require.rack": "rack1,rack2",
"index.routing.allocation.exclude.disk_type": "hdd"
}
数据分层(Data Tiers)(7.10+)
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/data-tiers.html
Elasticsearch 数据分层(Data Tiers)
1、data_content 数据内容层
Elasticsearch 从 7.13 版本 开始引入了更细粒度的节点角色划分,其中包括 data_content 角色。这是为了更清晰地管理不同类型的数据存储需求,尤其是区分 时间序列数据(如日志、指标)和 非时间序列数据(如内容型索引)。
data_content 是 Elasticsearch 节点的一种角色,表示该节点用于存储 非时间序列的常规数据(例如电商商品、用户信息等需要长期存储且不按时间分片的数据)。
2、时间序列(Time series)分层
Elasticsearch 按时间序列将节点划分为不同层级,每个层级对应不同的性能和存储成本,适合存储时间序列数据(如日志、指标),需按时间自动降级存储
- data_hot 高性能节点(如 SSD),用于存储高频访问的热数据。
- data_warm 中等性能节点,用于低频访问的温数据。
- data_cold 低成本存储节点(如 HDD),用于归档冷数据。
- data_frozen 可选,超低成本存储,用于只读快照数据。
索引级数据分层分配过滤(7.10+)
https://www.elastic.co/guide/en/elasticsearch/reference/7.10/data-tier-shard-filtering.html
index.routing.allocation.include._tier_preference 设置索引分片在不同数据层(Data Tiers)之间分配的优先级,允许指定分片优先分配到特定层级的节点(如 data_hot, data_warm, data_cold),从而实现冷热数据架构的自动分片管理。
_tier_preference 配置从 Elasticsearch 7.10 版本开始支持,与数据分层(Data Tiers)功能一同引入。
例如,设置数据分层分配优先级:先热、再温、再冷
PUT /<index>/_settings
{
"index.routing.allocation.include._tier_preference": "data_hot,data_warm,data_cold"
}
分类逻辑:
- 分片优先尝试分配到列表中第一个层级(如 data_hot)的节点。
- 如果该层级没有可用节点或资源不足(如磁盘空间不足),则尝试下一个层级(如 data_warm)。
- 若所有层级均无法分配,分片将处于未分配状态(需检查集群配置)。
_tier_preference 的优先级高于默认的分片分配策略,但低于显式指定的 require 或 exclude 规则。
例如,必须分配到 SSD 节点,之后按 _tier_preference 数据分层优先级分配
PUT /my_index/_settings
{
"index.routing.allocation.require.disk_type": "ssd",
"index.routing.allocation.include._tier_preference": "data_hot,data_warm"
}
similarity 相似度模块
https://www.elastic.co/guide/en/elasticsearch/reference/7.6/index-modules-similarity.html
自定义相似度算法参数
Elasticsearch 支持通过 similarity 模块调整内置相似度算法的参数(如 BM25 的 k1 和 b):
1、在索引配置中定义一个定制化的相似度算法 custom_bm25,修改 BM25 算法的 k1 和 b 参数。
2、之后在 text 类型的字段上可配置 similarity 属性为 custom_bm25
PUT /my_index
{
"settings": {
"index": {
"similarity": {
"custom_bm25": {
"type": "BM25",
"k1": 1.2, // 控制词频饱和度
"b": 0.75 // 控制文档长度归一化强度
}
}
}
},
"mappings": {
"properties": {
"content": {
"type": "text",
"similarity": "custom_bm25" // 引用自定义算法
}
}
}
}
可用的相关性算法
BM25 默认
https://www.elastic.co/guide/en/elasticsearch/reference/7.6/index-modules-similarity.html#bm25
基于 TF/IDF 的改进算法,专为短文本(如名称)优化,内置 TF 归一化,防止词频过高对评分的不合理影响。是当前 Elasticsearch 默认的相似度算法。
可调参数:
k1控制词频的非线性饱和程度(值越大,高频词影响越大),默认值1.2b控制文档长度对TF值的影响(0-1,值越大文档长度影响越大),默认值0.75discount_overlaps是否忽略重叠词(位置增量为0的词)的长度计算,默认值true
DFR
基于自由度背离模型(Divergence from Randomness),适合需要复杂统计建模的场景,建议保留停用词以获得更好的相关性。
可配置参数:
basic_model基础概率模型选择,可取值 g, if, in, ineafter_effect词频后的效应调整,可取值 b, lnormalization归一化方法(需额外参数,如h2需设置normalization.h2.c),可取值 no, h1, h2, h3, z
DFI
IB
LMDirichlet
LMJelinekMercer
scripted 脚本相似度算法
https://www.elastic.co/guide/en/elasticsearch/reference/7.6/index-modules-similarity.html#scripted_similarity
完全自定义评分脚本(需使用 Painless 语言),灵活性高,但需遵循评分规则(如分数非负),支持分阶段计算(weight_script 和 script)
weight_script: 计算文档无关部分(如IDF)
script: 计算文档相关部分(如TF和归一化)
核心规则:
- 分数必须为正
- 词频增加时分数不能降低(单调性)
- 文档长度增加时分数不能升高
Slowlog 慢查询日志
https://www.elastic.co/guide/en/elasticsearch/reference/7.6/index-modules-slowlog.html
通过设置不同级别的响应时间阈值(如WARN、INFO、DEBUG、TRACE),当查询或索引操作超过阈值时,系统会自动记录到对应的慢日志文件中。
默认慢查询日志未开启(默认阈值 -1 表示未开启)
还可以针对 query 和 fetch 两个阶段分别设置时间阈值,例如:
index.search.slowlog.threshold.query.warn: 10s
index.search.slowlog.threshold.query.info: 5s
index.search.slowlog.threshold.query.debug: 2s
index.search.slowlog.threshold.query.trace: 500ms
index.search.slowlog.threshold.fetch.warn: 1s
index.search.slowlog.threshold.fetch.info: 800ms
index.search.slowlog.threshold.fetch.debug: 500ms
index.search.slowlog.threshold.fetch.trace: 200ms
index.search.slowlog.level: info
这些都是动态配置,可通过 api 实时修改:
PUT /my_index/_settings
{
"index.search.slowlog.threshold.query.warn": "10s",
"index.search.slowlog.threshold.query.info": "5s",
"index.search.slowlog.threshold.query.debug": "2s",
"index.search.slowlog.threshold.query.trace": "500ms",
"index.search.slowlog.threshold.fetch.warn": "1s",
"index.search.slowlog.threshold.fetch.info": "800ms",
"index.search.slowlog.threshold.fetch.debug": "500ms",
"index.search.slowlog.threshold.fetch.trace": "200ms",
"index.search.slowlog.level": "info"
}
Translog 事务日志
Elasticsearch Guide [7.17] » Index modules » Translog
https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-translog.html
Elasticsearch 的 Translog(transaction log, 事务日志)是其实现数据可靠性和恢复机制的核心组件,主要用于在内存数据未持久化到磁盘前记录操作日志,确保故障时数据的完整性。
Translog 记录所有未提交的索引操作(增删改),在 Lucene 提交(Commit)到磁盘前暂存这些操作。由于 Lucene 的写入是先缓存在内存中,再批量写入磁盘,若此时发生故障,未落盘的数据会丢失,而 Translog 可在此场景下用于数据恢复。
ES 使用 translog(transaction log) 事务日志来记录所有的操作,增删改一条记录时会把数据写到 translog 中。这样一旦发生崩溃,数据可以从 Translog 中恢复。但如果系统崩溃时 translog 内容在系统缓冲区而没写入磁盘,也会造成数据丢失。
文档写入流程
- 插入文档时,ES 将文档写入内存缓冲区中,并将此次操作写入 translog
- 内存缓冲区的数据会以同步/异步方式刷入文件系统缓冲区(形成 Segment 段数据),之后可被检索到。
- 文件系统缓冲区中的 Segment 以同步/异步方式 flush 到磁盘,形成 Lucene commit point,同时清理对应的 translog,完成持久化。
Lucene Segment 内部是 LSM Tree 结构,这种数据结构充分利用磁盘顺序写速度大于随机写的特点,将随机写的操作都在内存里进行,当内存达到一定阈值后,使用顺序写一次性刷到磁盘里。
translog 中存储还未在 Lucene 中被安全持久化(即还不是 Lucene commit point 一部分,即还未 fsync 刷入磁盘)的操作记录,这部分操作虽然可被搜索到,但当出现系统掉电、OS崩溃、JVM崩溃等故障时这部分数据会丢失
写入 translog 的数据并不一定立即被写入磁盘,一般情况下,对磁盘文件的 write 操作,更新的只是内存中的页缓存,而脏页面不会立即更新到磁盘中,而是由操作系统统一调度,如由专门的 flusher 内核线程在满足一定条件时(如一定时间间隔、内存中的脏页面达到一定比例)将脏页面同步到磁盘上。因此如果服务器在 write 之后、磁盘同步之前宕机,则数据会丢失。
大量的 segment 和 commit point 在磁盘中存在,会影响数据的读性能。因此 Lucene 会按照一定的策略将磁盘中的 segment 和 commit point 合并,多个小的文件合并成一个大的文件并删除小文件,从而减少磁盘中文件数据,提升数据的读性能。
translog持久化策略
动态参数 index.translog.durability 控制 translog 是定时刷新到磁盘,还是每次请求都 fsync 同步刷到磁盘,这个参数有 2 个取值:
- 同步模式(request),默认,同步刷盘
index.translog.durability: request- 每次索引操作后强制刷盘,保证数据不丢失,但性能较低。
- 每次请求(增、删、改、bulk批量操作)都要等 translog 被 fsync 刷到磁盘且在主/从分片上提交后才会返回成功,所有已返回成功的数据操作都不会丢失。
- 异步模式(async),异步刷盘
index.translog.durability: async- translog 每隔
index.translog.sync_interval时间(默认5秒钟)fsync 并提交一次,写入性能会有提升,但出现故障时上次提交后的写入请求会丢失。 - 定时将内存缓冲区数据生成新的 Lucene 段(Segment),使数据可被搜索(near-realtime 近实时)。性能更高,但存在数据丢失风险。
index.translog.sync_interval 控制 translog 多久 fsync 到磁盘,默认为 5 秒,允许的最小为 100ms
index.translog.flush_threshold_size translog 的大小超过这个参数后 flush 然后生成一个新的 translog,默认 512mb
ES 文档写入及持久化过程
es 为了保证高可用,会定期将全部数据持久化到磁盘上。
Elasticsearch持久化过程详解
https://blog.csdn.net/aa1215018028/article/details/108746679
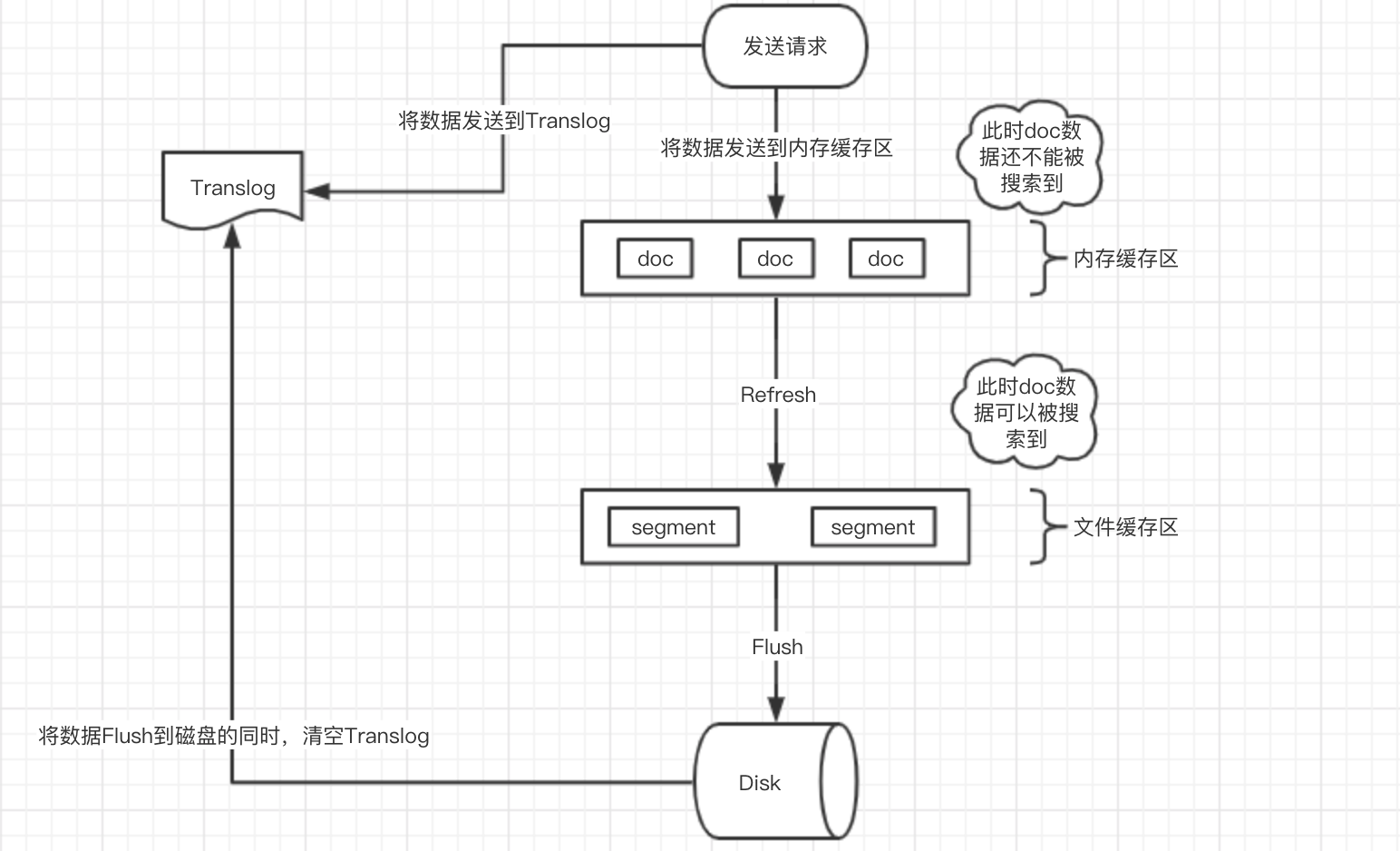
Elasticsearch 持久化存储过程
这个描述是 异步持久化的过程。
1、数据写入内存缓存区和 Translog 日志文件中。
当写一条数据 doc 的时候,一方面写入到内存缓冲区中,一方面同时写入到 Translog 日志文件中。
2、如果 index.translog.durability=async,内存缓存区满了或者每隔1秒(默认1秒),refresh 将内存缓存区的数据生成 index segment 文件并写入文件系统缓存区,此时 index segment 可被打开以供 search 查询读取,这样文档就可以被搜索到了(注意,此时文档还没有写到磁盘上);然后清空内存缓存区供后续使用。可见,refresh 实现的是文档从内存缓存区移到文件系统缓存区的过程。
如果 index.translog.durability=request 每次文档 CRUD 请求都要等 refresh 并 fsync 后才返回。
3、重复上两个步骤,新的 segment 不断添加到文件系统缓存区,内存缓存区不断被清空,而 translog 的数据不断增加,随着时间的推移,Translog 文件会越来越大。
4、当 Translog 长度达到一定程度的时候,会触发 flush 操作,否则默认每隔 30 分钟也会定时 flush,其主要过程:
4.1、执行 refresh 操作将内存缓存区中的数据写入到新的 segment 并写入文件系统缓存区,然后打开本 segment 以供 search 使用,最后再次清空内存缓存区。
4.2、一个 commit point 被写入磁盘,这个 commit point 中标明所有的 index segment。
4.3、文件系统中缓存的所有的 index segment 文件被 fsync 强制刷到磁盘,当 index segment 被 fsync 强制刷到磁盘上以后,就会被打开,供查询使用。
4.4、translog 被清空和删除,创建一个新的translog。
详细文档写入流程
1、客户端写入请求
如 PUT /index/_doc/1
请求首先由协调节点路由到主分片(Primary Shard)。
2、写入内存缓冲区和 Translog
文档被写入 内存缓冲区(In-Memory Buffer)(Lucene 管理)。
同时,操作被追加到 Translog(事务日志) 中。
注意:
此时文档不可被搜索(内存缓冲区未生成可搜索的段)。
Translog 默认写入操作系统的 Page Cache(内存缓存),但尚未调用 fsync 强制刷盘。
3、定时刷新(Refresh)
Refresh 机制:
- 默认每 1 秒(
index.refresh_interval=1s),Elasticsearch 会执行一次 Refresh,将内存缓冲区(In-Memory Buffer)中的数据转换为新的 Lucene 段(Segment),写入操作系统的 Page Cache。 - 此外,文档写入时可以设置单次调用的 refersh 参数,例如 PUT /test/_doc/4?refresh=true,refresh=true 表示立即执行刷新操作,使得这次写入的改变对搜索操作立即可见。
Refresh 机制的目的是实现 近实时搜索(NRT, near-realtime),让新写入的文档能够快速被检索到。
此时:
此时数据仍在内存/Page Cache 中,并未持久化到物理磁盘。
Translog 不会被清理,因为它仍需保护未持久化的数据。
4、Translog 的持久化(fsync)
根据 index.translog.durability 配置决定何时调用 操作系统的 fsync:
- request(同步模式):默认,每次写入请求后,强制调用 fsync,将 Translog 从 Page Cache 刷到磁盘。
- async(异步模式):按固定间隔(
index.translog.sync_interval=5s)调用 fsync 刷盘。
fsync 的作用:
确保 Translog 数据从操作系统的内存缓存(Page Cache)写入物理磁盘。
防止系统崩溃时丢失 Page Cache 中的 Translog 数据。
5、触发 Flush 操作
Flush 的触发条件:
- Translog 大小达到阈值(index.translog.flush_threshold_size=512MB)。
- 时间间隔(index.translog.flush_threshold_period=30m)。
- 手动调用 /_flush API。
Flush 的操作内容:
将内存缓冲区(In-Memory Buffer)中的剩余数据写入新的 Lucene 段。
调用 Lucene Commit:将所有新生成的段(包括 Refresh 生成的段)持久化到磁盘。隐式调用 fsync:确保段文件从 Page Cache 写入物理磁盘。
清理旧的 Translog:生成新的 Translog 文件,旧的 Translog 条目被标记为可删除
6、清理旧的 Translog
Translog 文件会保留一定历史(默认保留 512MB,由 index.translog.retention.size 控制)。
Merge 段合并
Elasticsearch Guide [7.17] » Index modules » Merge
https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-merge.html
如果使用默认的 index.translog.durability=request 同步刷新方式,每个请求都会创建一个新的 Lucene Segment,这样会导致短时间内的段数量暴增。
段数目太多会带来较大的麻烦,每一个段都会消耗文件句柄、内存和cpu运行周期。此外,每个搜索请求都必须轮流检查每个段;所以段越多,搜索也就越慢。
Elasticsearch 通过在后台进行段合并来解决这个问题。
段合并的时候会将标记为已删除的文档和文档的旧版本从文件系统中清除
ES 中有后台线程根据 Lucene 的合并规则定期进行段合并操作,一般不需要用户担心或者采取任何行动。
通过 /index/_forcemerge API 可以手动强制段合并
Store 存储类型(mmap内存映射)
Elasticsearch Guide [7.17] » Index modules » Store
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/index-modules-store.html
存储类型用于配置索引数据在磁盘上的存储和访问方式。
默认情况下,Elasticsearch 会基于操作系统选择最优存储类型。
支持的存储类型:fs 基于操作系统选择最优存储类型,当前在全部系统上都是 hybridfssimplefs 在 7.15 版本中废弃,在 8.0 版本中会删除,使用 niofs 代替。对应 Lucene 的 SimpleFsDirectory 类型,直接随机访问文件,并发性能较差,niofs 对应 Lucene 的 NIOFSDirectory 类型,使用 Java NIO 读写索引数据文件。允许多线程并发读取同一个文件。mmapfs 对应 Lucene 的 MMapDirectory 类型,通过 mmap 零拷贝内存映射读写索引文件,内存映射会占用进程的 virt 虚拟地址空间,virt 大小等于被 mmap 映射的索引文件大小。使用这个存储类型要保证系统有足够的虚拟地址空间。对应到文件扩展名,就是 nvd(norms),dvd(doc values),tim(term dictionary),tip(term index),cfs(compound) 类型的文件使用 mmap 方式加载,其余使用 nio。hybridfs 是 niofs 和 mmapfs 的混合,基于每种文件的读写模式选择最合适的文件系统类型。对于 Lucene term dictionary, norms, doc values 使用 mmap 内存映射打开,其他使用 NIOFSDirectory 打开。
node.store.allow_mmap 使用 mmapfs 和 hybridfs 存储类型时,是否允许开启 mmap 内存映射,默认值是允许。
操作系统的 mmap 虚拟内存区域个数会影响 Elasticsearch 读写索引数据的性能,sysctl -w vm.max_map_count=262144 提高进程的虚拟内存区域个数,sysctl vm.max_map_count 查看改后的值。
预加载文件系统缓存
Elasticsearch Guide [7.17] » Index modules » Store » Preloading data into the file system cache
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/preload-data-to-file-system-cache.html
默认情况下,Elasticsearch 完全依赖操作系统的文件系统缓存来进行 I/O 操作。可以将常用的索引配置在 index.store.preload 中,实现 ES 启动时就预加载索引数据到系统缓存。
注意索引预加载可能会减慢索引的打开速度,并且只有当索引数据加载到物理内存后才可用。
索引预加载只是尽最大努力进行,具体是否生效依赖存储类型以及操作系统类型。
index.store.preload 静态参数,配置逗号分割的索引列表,默认为空,即不预加载任何索引到系统缓存。
例如 index.store.preload: ["nvd", "dvd"]
支持通配符,例如 index.store.preload: ["*"]
在创建索引时设置此参数
PUT /my-index-000001
{
"settings": {
"index.store.preload": ["nvd", "dvd"]
}
}
Index blocks 索引限制(锁)
Elasticsearch Guide [7.17] » Index modules » Index blocks
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/index-modules-blocks.html
索引 block 用于限制在指定索引上的操作,用于限制读、写、元数据操作。
index.blocks.read_only
index.blocks.read_only 动态参数,设为 true 时索引的数据和元数据变为只读,设为 false 时索引数据和元数据可写。
index.blocks.read_only_allow_delete
index.blocks.read_only_allow_delete 动态参数,设为 true 时索引只读且 允许删除索引本身来释放空间,磁盘分配器在节点的磁盘使用率超过洪水位时会自动添加这个block,低于高水位时会自动解除此block
注意:**index.blocks.read_only_allow_delete 为 true 时允许删的是索引本身,而不是索引内的文档**,删除索引内文档可能还会导致空间占用更大。所以 index.blocks.read_only_allow_delete 为 true 时是不允许删除索引内的文档的。
index.blocks.read
index.blocks.read 动态参数,设为 true 时禁用索引上的读操作
index.blocks.write
index.blocks.write 动态参数,设为 true 时禁用索引上的写操作,这个设置不影响元数据操作,期间依然可读写索引元数据。
index.blocks.metadata
index.blocks.metadata 动态参数,设为 true 时禁用索引元数据读写。
Index Sorting 索引排序
Elasticsearch Guide [7.17] » Index modules » Index Sorting
https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-index-sorting.html
Elasticsearch 从 6.0 版本开始引入了一个新的特征,叫 Index Sorting(索引排序)。用户可以将索引数据按照指定的顺序存储在硬盘上,这样在搜索排序取前 N 条时,不需要访问所有的匹配中的记录再进行排序,只需要访问前 N 条记录即可。
默认情况下, Lucene 没有任何排序字段,可通过配置 index.sort.* 来设置 Segment 内文档的排序字段。
例1、创建索引时指定单个排序字段,按 date 倒序排序:
PUT my-index-000001
{
"settings": {
"index": {
"sort.field": "date",
"sort.order": "desc"
}
},
"mappings": {
"properties": {
"date": {
"type": "date"
}
}
}
}
例2、创建索引时指定多个排序字段,按 username 正序、date 倒序排序:
PUT my-index-000001
{
"settings": {
"index": {
"sort.field": [ "username", "date" ],
"sort.order": [ "asc", "desc" ]
}
},
"mappings": {
"properties": {
"username": {
"type": "keyword",
"doc_values": true
},
"date": {
"type": "date"
}
}
}
}
文档会先按 username 正序排序,username 相同的按 date 倒序排序。
早期中断
假如要搜索按日期倒序排序的前 N 条数据,无其他条件:
- 如果索引中的文档没有排序,需要遍历索引中的全部文档后找出排序的 TopN 数据,开销巨大。
- 如果索引中的文档已经按日期倒序排好序了,只需要访问每个 segment 中的前 N 条数据即可中断请求,这就是 早期中断(Early termination)
例如有上文中按 date 倒序排序的索引,执行下面的检索时,es发现检索条件的排序字段与索引中文档存储的排序字段一致,只需访问每个 segment 中的前 10 条数据,可更快的返回。如果完全不需要计数,可以将 track_total_hits 设为 false,进一步加速检索。
GET /my-index-000001/_search
{
"size": 10,
"sort": [
{ "date": "desc" }
],
"track_total_hits": false
}
Indexing pressure 索引压力
Elasticsearch Guide [7.17] » Index modules » Indexing pressure
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/index-modules-indexing-pressure.html
indexing_pressure.memory.limit 外部索引请求可占用的堆内存最大值,默认 JVM 堆内存的 10%。当超出次阈值时,节点会拒绝执行新的协调和主分片操作。当副本操作超过 1.5 被次阈值时,节点会拒绝执行副本操作。
FST 索引前缀
FST(Finite State Transducer)
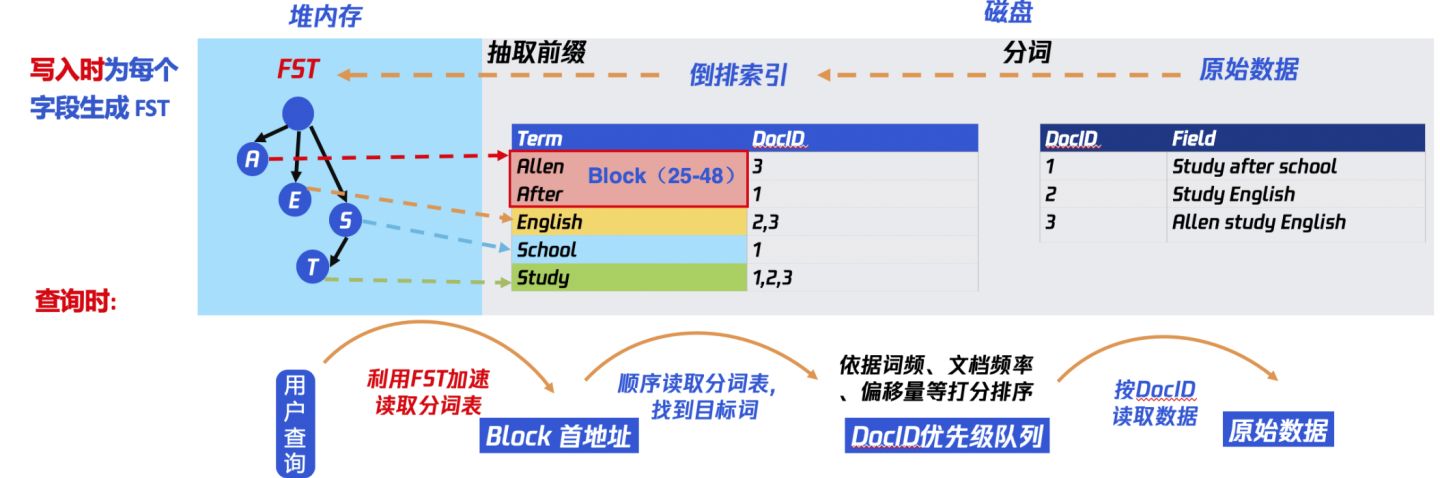
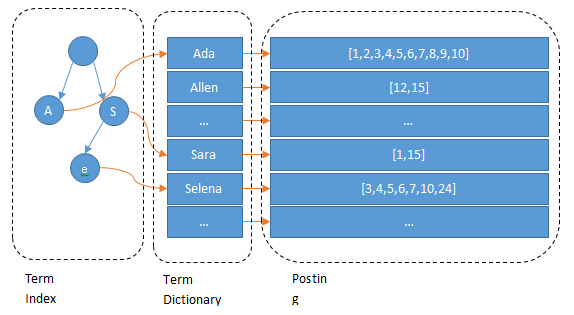
Lucene 会为每个词都生成倒排索引,数据量较大。所以倒排索引对应的倒排表被存放在磁盘上。这样如果每次查询都直接读取磁盘上的倒排表,再查询目标关键词,会有很多次磁盘 I/O,严重影响查询性能。为优化磁盘 I/O,Lucene 引入倒排索引的二级索引 FST(Finite State Transducer),原理类似 前缀树/字典树/Trie树,加速查询。
用户查询时,先通过关键词(Term)查询内存中的 FST,找到该 Term 对应的 Block 首地址。再读磁盘上的分词表,将该 Block 加载到内存,遍历该 Block,查找到目标 Term 对应的 DocID。再按照一定的排序规则,生成 DocID 的优先级队列,再按该队列的顺序读取磁盘中的原始数据(行存或列存)。
Lucene 使用 FST 实现 Term Index,Term Index 是 Term Dictionary 的索引,可以快速查找一个 Term 是否在 Dictionary 中;并且能够快速定位 Block 的位置。
elasticsearch-fst
elasticsearch-fst2
7.7 开始将 FST 通过mmap加载
从 ES 7.7 版本开始,将 tip(term index) 文件修改为通过 mmap 的方式加载,这使 FST 占据的内存从堆内转移到了堆外由操作系统的 pagecache 管理。
7.7 之前 FST 永驻堆内存,无法被 GC 回收,FST 约占堆内存总量的 50% - 70%,每 GB 索引大约需要几 MB 的 FST,则 10TB 索引数据需要 10-15 GB 的 FST。
将数据结构从 JVM 堆移动到磁盘,并依赖文件系统缓存(通常称为页面缓存或 OS 缓存)将热数据保存在内存中。
7.7 版本中的新改进:显著降低 Elasticsearch 堆内存使用量
https://www.elastic.co/cn/blog/significantly-decrease-your-elasticsearch-heap-memory-usage
Term 词条: 索引里面最小的存储和查询单元,对于英文来说是一个单词,对于中文来说一般指分词后的一个词。
Term Dictionary 词典:是词条 Term 的集合。搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
Postings List 倒排表:一个文档通常由多个词组成,倒排表记录的是某个词在哪些文档里出现过以及出现的位置。每条记录称为一个倒排项(Posting)。倒排表记录的不单是文档编号,还存储了词频等信息。
Inverted File 倒排文件:所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
Lucene 段文件内容
Lucene 一个 Index 会包含多个 Segment,一个 Segment 又由多个文件共同组成:
xx.tip:存储 Term Index
xx.tim:存储 Term Dictionary
xx.doc:存储 Postings 的 DocId 信息和 Term 的词频
xx.fnm:存储文档 Field 的元信息
xx.fdx:存储文档的索引,使用 SkipList 来实现
xx.fdt:存储具体的文档
xx.dvm:存储 DocValues 元信息
xx.dvd:存储具体 DocValues 数据
Lucene 没有更新跟删除逻辑,所有对 Lucene 的更新都是 Append 一个新 Doc 到 Segment。
Ingest pipeline 数据处理流
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/ingest.html
Elasticsearch 中的 Ingest Pipeline 允许在文档被索引之前对其进行预处理转换操作。这些转换可以包括删除字段、从文本中提取值以及其他丰富数据的操作。
Pipeline 是由一系列称为处理器(Processors)的可配置任务组成。每个处理器按顺序运行,对传入的文档进行特定的更改。处理器运行后,Elasticsearch 会将转换后的文档添加到数据流或索引中。
Ingest Pipeline 提供了多种处理器,如:
Remove删除字段。Rename重命名字段。Set设置字段的值。Convert转换字段的数据类型。Grok使用正则表达式解析字段。Date解析日期字段。Dot Expander展开以点分隔的字段。JSON解析 JSON 格式的字段。
script 脚本处理器
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/script-processor.html
参数:
lang脚本的语言,默认是 painlessid已存储的脚本id,id和source至少指定1个sourceinline 内联脚本的文本,id和source至少指定1个
访问文档源(_source)字段:ctx['my-field']. 或 ctx.<my-field>
访问文档元数据(meta)字段:例如 ctx['_index'], _type, _version
/_ingest/pipeline/name 创建处理流
PUT /_ingest/pipeline/<pipeline> 创建处理流
PUT _ingest/pipeline/my-pipeline-id
{
"description" : "My optional pipeline description",
"processors" : [
{
"set" : {
"description" : "My optional processor description",
"field": "my-keyword-field",
"value": "foo"
}
}
]
}
pipeline+reindex将1024维向量截断为512维
index1 索引中有两个 1024 维的向量,拷贝数据到 index2,同时将向量数据改为 512 维的。
1、创建脚本处理器,将 1024 维向量的 title_vector 和 content_vector 字段内容处理为 512 维向量
PUT _ingest/pipeline/truncate_vector
{
"description" : "truncate vector fields",
"processors" : [
{
"script" : {
"source": "ctx.title_vector = ctx.title_vector.stream().limit(512).collect(Collectors.toList())"
}
},
{
"script" : {
"source": "ctx.content_vector = ctx.content_vector.stream().limit(512).collect(Collectors.toList())"
}
}
]
}
2、创建新索引 index2,两个向量字段改为 512 维的
3、使用 _reindex api 拷贝索引数据,指定 pipeline 为 truncate_vector
POST /_reindex
{
"source": {
"index": "index1"
},
"dest": {
"index": "index2",
"pipeline": "truncate_vector"
}
}
上一篇 GlusterFS
页面信息
location:protocol: host: hostname: origin: pathname: href: document:referrer: navigator:platform: userAgent: