面试准备01-Java基础和其他
Java 面试准备笔记
To Be Top Javaer - Java工程师成神之路
http://hollischuang.gitee.io/tobetopjavaer/#/
hollischuang / toBeTopJavaer
https://github.com/hollischuang/toBeTopJavaer
阿里面试回来,和Java程序员谈一谈
https://zhuanlan.zhihu.com/p/20838139
平凡希 - 很不错的java博客
http://www.cnblogs.com/xiaoxi/
海子 - 很不错的java博客
http://www.cnblogs.com/dolphin0520/
各大公司Java后端开发面试题总结
https://www.cnblogs.com/java1024/p/7685400.html
Java面试通关要点汇总集 - 服务端思维
http://blog.720ui.com/2018/java_interview/
金三银四跳槽季,Java面试大纲 - 占小狼的博客
https://mp.weixin.qq.com/s?__biz=MzIwMzY1OTU1NQ==&mid=2247484038&idx=1&sn=a31c83f3a132ee8fa816f7b1db3839eb
2017.03 JAVA 面试题 中高级
https://blog.csdn.net/cyanqueen/article/details/62438972
Java 语法基础
数据类型
Integer会缓存-128到127之间的实例
在 Java 5 中,为 Integer 的操作引入了一个新的特性,用来节省内存和提高性能。
通过 valueOf(int) 构造整型对象时,会首先去缓存池 IntegerCache.cache[] 中查找相应值的实例是否已存在,如果已存在直接返回,不用重新实例化对象。
此规则默认适用于整数区间 -128 到 +127。
这种 Integer 缓存策略仅在自动装箱(autoboxing)的时候有用,装箱就相当于调用valueOf(int)方法,使用构造器创建的 Integer 对象不能被缓存。
例如:
Integer integer1 = new Integer(3);
Integer integer2 = new Integer(3);
Integer integer3 = 3;
Integer integer4 = 3;
System.out.println(integer1 == integer2); // false
System.out.println(integer3 == integer4); // true
这种缓存行为不仅适用于Integer对象。我们针对所有整数类型的类都有类似的缓存机制。
有 ByteCache 用于缓存 Byte 对象
有 ShortCache 用于缓存 Short 对象
有 LongCache 用于缓存 Long 对象
有 CharacterCache 用于缓存 Character 对象
Byte,Short,Long 有固定范围: -128 到 127。
对于 Character, 范围是 0 到 127。
除了 Integer 可以通过参数改变范围外,其它的都不行。
public final class Integer extends Number implements Comparable<Integer> {
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
private IntegerCache() {}
}
}
java 值与引用
一:搞清楚 基本类型 和 引用类型的不同之处
int num = 10;
String str = “hello”;
num是基本类型,值就直接保存在变量中。
而str是引用类型,变量中保存的只是实际对象的地址。一般称这种变量为”引用”,引用指向实际对象,实际对象中保存着内容。
二:搞清楚赋值运算符”=”的作用
num = 20;
str = “java”;
对于基本类型 num ,赋值运算符会直接改变变量的值,原来的值被覆盖掉。
对于引用类型 str,赋值运算符会改变引用中所保存的地址,原来的地址被覆盖掉。但是原来的对象不会被改变(重要)。
第二步中给str赋值”java”后,只是将str指向了”java”字符串,第一步中的”hello” 字符串对象没有被改变。(没有被任何引用所指向的对象是垃圾,会被垃圾回收器回收)
三:调用方法时发生了什么?参数传递基本上就是赋值操作。
第一个例子:基本类型
void foo(int value) {
value = 100;
}
foo(num); // num 没有被改变
第二个例子:没有提供改变自身方法的引用类型
void foo(String text) {
text = "windows";
}
foo(str); // str 也没有被改变
第三个例子:提供了改变自身方法的引用类型
StringBuilder sb = new StringBuilder("iphone");
void foo(StringBuilder builder) {
builder.append("4");
}
foo(sb); // sb 被改变了,变成了"iphone4"。
第四个例子:提供了改变自身方法的引用类型,但是不使用,而是使用赋值运算符。
StringBuilder sb = new StringBuilder("iphone");
void foo(StringBuilder builder) {
builder = new StringBuilder("ipad");
}
foo(sb); // sb 没有被改变,还是 "iphone"。
从局部变量/方法参数开始讲起:
局部变量和方法参数在jvm中的储存方法是相同的,都是在栈上开辟空间来储存的,随着进入方法开辟,退出方法回收。以32位JVM为例,boolean/byte/short/char/int/float以及引用都是分配4字节空间,long/double分配8字节空间。对于每个方法来说,最多占用多少空间是一定的,这在编译时就可以计算好。
我们都知道JVM内存模型中有,stack和heap的存在,但是更准确的说,是每个线程都分配一个独享的stack,所有线程共享一个heap。对于每个方法的局部变量来说,是绝对无法被其他方法,甚至其他线程的同一方法所访问到的,更遑论修改。
当我们在方法中声明一个 int i = 0,或者 Object obj = null 时,仅仅涉及stack,不影响到heap,当我们 new Object() 时,会在heap中开辟一段内存并初始化Object对象。当我们将这个对象赋予obj变量时,仅仅是stack中代表obj的那4个字节变更为这个对象的地址。
数组类型引用和对象:
当我们声明一个数组时,如int[] arr = new int[10],因为数组也是对象,arr实际上是引用,stack上仅仅占用4字节空间,new int[10]会在heap中开辟一个数组对象,然后arr指向它。
当我们声明一个二维数组时,如 int[][] arr2 = new int[2][4],arr2同样仅在stack中占用4个字节,会在内存中开辟一个长度为2的,类型为int[]的数组,然后arr2指向这个数组。这个数组内部有两个引用(大小为4字节),分别指向两个长度为4的类型为int的数组。
Java 到底是值传递还是引用传递? - Intopass的回答 - 知乎
https://www.zhihu.com/question/31203609/answer/50992895
Java的四种引用方式
https://www.cnblogs.com/huajiezh/p/5835618.html
字符串
String类使用+连接字符串的过程
大家经常会说不要使用”+” 来连接字符串这样效率不高(相对于 StringBuilder、StringBuffer)那为什么那,看看下面:
String str= “a”; str=str+”b”; str=str+”c”;
实现过程:
String str= “a”;创建一个String对象,str 引用到这个对象。
在创建一个长度为str.length() 的StringBuffer 对象
StringBuffer strb=new StringBuffer(str);
调用StringBuffer的append()方法将”B”添加进去,strb.append(“b”);
调用strb 的toString()方法创建String对象,之前对象失去引用而str重新引用到这个新对象。
同样在创建StringBuffer对象 调用append()方法将”c”添加进去,调用toString() 方法 创建String对象
再将str引用到 新创建的String对象。之前对象失去引用之后存放在常量池中,等待垃圾回收。
看到上面使用“+”连接字符串的过程,就明白了为什么要使用StringBuffer 来连接字符而不是使用String 的“+”来连接。
StringBuilder 和 StringBuffer 区别
String类是如何保证对象不可变的?
所有对String对象的写操作都是重新生成一个String对象,而不是对原String对象的修改。
那什么叫对象不可变:
当一个对象创建完成之后,不能再修改他的状态,不能改变状态是指不能改变对象内的成员变量,包括基本数据类型的值不能改变。引用类型的变量不能指向其他对象,引用类型指向的对象的状态也不能改变。对象一旦创建就没办法修改其所有属性,所以要修改不可变对象的值就只能重新创建对象。
String 类的源码:
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[]; // 数组被final修饰,所以数据引用变量的值不能变
/** Cache the hash code for the string */
private int hash; // Default to 0
...
}
String 的底层是使用字符数组来实现的,用一个char数组value[]来存放字符串
value 是一个被final修饰的数组对象,所以只能说他不能再引用到其他对象而不能说明他所引用的对象的内容不能改变。但我们在往下看源码就会发现String 类没有给这两个成员变量提供任何的方法所以我们也没办法修改所引用对象的内容,所以String 对象一旦被创建,这个变量被初始化后就不能再修改了,所以说String 对象是不可变对象。
String 类的成员变量都是final类型的并且没有提供任何方法可以来修改引用变量所引用的对象的内容,所以一旦这个对象被创建并且成员变量初始化后这个对象就不能再改变了,所以说String 对象是一个不可变对象。
String、StringBuilder、 StringBuffer 深入分析 源码解析
http://blog.csdn.net/qh_java/article/details/46382265
为什么将String对象设计为不可变的?
Java中的String被设计成不可变的,出于以下几点考虑:
字符串常量池的需要。字符串常量池的诞生是为了提升效率和减少内存分配。可以说我们编程有百分之八十的时间在处理字符串,而处理的字符串中有很大概率会出现重复的情况。正因为String的不可变性,常量池很容易被管理和优化。
安全性考虑。正因为使用字符串的场景如此之多,所以设计成不可变可以有效的防止字符串被有意或者无意的篡改。从java源码中String的设计中我们不难发现,该类被final修饰,同时所有的属性都被final修饰,在源码中也未暴露任何成员变量的修改方法。(当然如果我们想,通过反射或者Unsafe直接操作内存的手段也可以实现对所谓不可变String的修改)。
作为HashMap、HashTable等hash型数据key的必要。因为不可变的设计,jvm底层很容易在缓存String对象的时候缓存其hashcode,这样在执行效率上会大大提升。
如何设计一个不可变类?
不可变类:所谓的不可变类是指这个类的实例一旦创建完成后,就不能改变其成员变量值。如JDK内部自带的很多不可变类:Interger、Long和String等。
可变类:相对于不可变类,可变类创建实例后可以改变其成员变量值,开发中创建的大部分类都属于可变类。
不可变类的设计方法:
1、类添加final修饰符,保证类不被继承。
如果类可以被继承会破坏类的不可变性机制,只要继承类覆盖父类的方法并且继承类可以改变成员变量值,那么一旦子类以父类的形式出现时,不能保证当前类是否可变。
2、保证所有成员变量必须私有,并且加上final修饰
通过这种方式保证成员变量不可改变。但只做到这一步还不够,因为如果是对象成员变量有可能再外部改变其值。所以第4点弥补这个不足。
3、不提供改变成员变量的方法,包括setter
避免通过其他接口改变成员变量的值,破坏不可变特性。
4、通过构造器初始化所有成员,进行深拷贝(deep copy)
如果构造器传入的对象直接赋值给成员变量,还是可以通过对传入对象的修改进而导致改变内部变量的值。例如:
public final class ImmutableDemo {
private final int[] myArray;
public ImmutableDemo(int[] array) {
this.myArray = array; // wrong
}
}
这种方式不能保证不可变性,myArray和array指向同一块内存地址,用户可以在ImmutableDemo之外通过修改array对象的值来改变myArray内部的值。
为了保证内部的值不被修改,可以采用深度copy来创建一个新内存保存传入的值。正确做法:
public final class MyImmutableDemo {
private final int[] myArray;
public MyImmutableDemo(int[] array) {
this.myArray = array.clone();
}
}
5、在getter方法中,不要直接返回对象本身,而是克隆对象,并返回对象的拷贝
这种做法也是防止对象外泄,防止通过getter获得内部可变成员对象后对成员变量直接操作,导致成员变量发生改变。
JAVA不可变类(immutable)机制与String的不可变性
https://www.cnblogs.com/jaylon/p/5721571.html
String.intern()与字符串常量池
jdk源码中对intern方法的详细解释简单来说就是intern用来返回常量池中的某字符串,如果常量池中已经存在该字符串,则直接返回常量池中该对象的引用。否则,在常量池中加入该对象,然后 返回引用。
通过字面量赋值创建字符串时,会优先在常量池中查找是否已经存在相同的字符串,倘若已经存在,栈中的引用直接指向该字符串;倘若不存在,则在常量池中生成一个字符串,再将栈中的引用指向该字符串。
而通过new的方式创建字符串时,就直接在堆中生成一个字符串的对象(备注,JDK 7 以后,HotSpot 已将常量池从永久代转移到了堆中。详细信息可参考《JDK8内存模型-消失的PermGen》一文),栈中的引用指向该对象。
对于堆中的字符串对象,可以通过 intern() 方法来将字符串添加的常量池中,并返回指向该常量的引用。
String str1 = "string";
String str2 = new String("string");
String str3 = str2.intern();
System.out.println(str1==str2);//false
System.out.println(str1==str3);//true
结果1:因为 str1 指向的是字符串中的常量,str2是在堆中生成的对象,所以 str1 == str2 返回 false
结果2:str2 调用 intern 方法,会将 str2 中值 “string” 复制到常量池中,但是常量池中已经存在该字符串(即str1指向的字符串),所以直接返回该字符串的引用,因此 str1 == str2 返回true。
Java-String.intern的深入研究
https://www.cnblogs.com/Kidezyq/p/8040338.html
通过反编译深入理解Java String及intern
http://www.cnblogs.com/paddix/p/5326863.html
Java 泛型
什么是泛型(参数化类型)
泛型(Generic type 或者 generics),即“参数化类型”。一提到参数,最熟悉的就是定义方法时有形参,然后调用此方法时传递实参。那么参数化类型怎么理解呢?顾名思义,就是将类型由原来的具体的类型参数化,类似于方法中的变量参数,此时类型也定义成参数形式(可以称之为类型形参),然后在使用/调用时传入具体的类型(类型实参)。
泛型的本质是为了参数化类型(在不创建新的类型的情况下,通过泛型指定的不同类型来控制形参具体限制的类型)。也就是说在泛型使用过程中,操作的数据类型被指定为一个参数,这种参数类型可以用在类、接口和方法中,分别被称为泛型类、泛型接口、泛型方法。
泛型的好处(类型安全)
Java 1.5 中引入泛型是一个较大的功能增强。不仅语言、类型系统和编译器有了较大的变化,以支持泛型,而且类库也进行了大翻修,所以许多重要的类,比如集合框架,都已经成为泛型化的了。
这带来了很多好处:
1、类型安全。
在 Java SE 1.5 之前,没有泛型的情况的下,通过对类型 Object 的引用来实现参数的“任意化”,“任意化”带来的缺点是要做显式的强制类型转换,而这种转换是要求开发者对实际参数类型可以预知的情况下进行的。对于强制类型转换错误的情况,编译器可能不提示错误,在运行的时候才出现异常,这是一个安全隐患。
泛型的主要目标是提高 Java 程序的类型安全。通过知道使用泛型定义的变量的类型限制,编译器可以在一个高得多的程度上验证类型假设。
泛型的好处是在编译的时候检查类型安全,并且所有的强制转换都是自动和隐式的,以提高代码的重用率。
2、 消除强制类型转换。 泛型的一个附带好处是,消除源代码中的许多强制类型转换。这使得代码更加可读,并且减少了出错机会。
3、 潜在的性能收益。 泛型为较大的优化带来可能。在泛型的初始实现中,编译器将强制类型转换(没有泛型的话,程序员会指定这些强制类型转换)插入生成的字节码中。
泛型擦除(泛型只在编译阶段有效)
Java 在语法中虽然存在泛型的概念,但是在虚拟机中却没有泛型的概念,虚拟机中所有的类型都是普通类。无论何时定义一个泛型类型,编译后类型会被都被自动转换成一个相应的原始类型
在编译阶段,所有泛型类的类型参数都会被 Object 或者它们的限定边界来替换,这就是类型擦除
Java 中的泛型,只在编译阶段有效。在编译过程中,正确检验泛型结果后,会将泛型的相关信息擦除,并且在对象进入和离开方法的边界处添加类型检查和类型转换的方法。也就是说,泛型信息不会进入到运行时阶段。
List<String> l1 = new ArrayList<String>();
List<Integer> l2 = new ArrayList<Integer>();
System.out.println(l1.getClass() == l2.getClass()); //结果为true
泛型类型在逻辑上看以看成是多个不同的类型,实际上都是相同的基本类型。
Java 中的泛型基本上都是在编译器这个层次来实现的。在生成的 Java 字节代码中是不包含泛型中的类型信息的。使用泛型的时候加上的类型参数,会被编译器在编译的时候去掉。这个过程就称为类型擦除。
如在代码中定义的 List<Object> 和 List<String> 等类型,在编译之后都会变成 List。JVM 看到的只是 List,而由泛型附加的类型信息对 JVM 来说是不可见的。Java 编译器会在编译时尽可能的发现可能出错的地方,但是仍然无法避免在运行时刻出现类型转换异常的情况。类型擦除也是 Java 的泛型实现方式与 C++ 模板机制实现方式之间的重要区别
很多泛型的奇怪特性都与这个类型擦除的存在有关,包括:
1、泛型类并没有自己独有的 Class 类对象。比如并不存在 List<String>.class 或是 List<Integer>.class,而只有 List.class
2、静态变量是被泛型类的所有实例所共享的。对于声明为 MyClass<T> 的类,访问其中的静态变量的方法仍然是 MyClass.myStaticVar。不管是通过 new MyClass<String> 还是 new MyClass<Integer> 创建的对象,都是共享一个静态变量。
3、泛型的类型参数不能用在 Java 异常处理的 catch 语句中。因为异常处理是由 JVM 在运行时刻来进行的。由于类型信息被擦除,JVM 是无法区分两个异常类型 MyException<String> 和MyException<Integer> 的。对于 JVM 来说,它们都是 MyException 类型的。也就无法执行与异常对应的 catch 语句。
类型擦除的基本过程也比较简单,首先是找到用来替换类型参数的具体类。这个具体类一般是 Object。如果指定了类型参数的上界的话,则使用这个上界。把代码中的类型参数都替换成具体的类。同时去掉出现的类型声明,即去掉 <> 的内容。比如 T get() 方法声明就变成了 Object get(),List<String> 就变成了 List。接下来就可能需要生成一些桥接方法(bridge method)。这是由于擦除了类型之后的类可能缺少某些必须的方法。
java 泛型详解-绝对是对泛型方法讲解最详细的,没有之一
https://blog.csdn.net/s10461/article/details/53941091
Java中泛型 类型擦除
https://www.cnblogs.com/drizzlewithwind/p/6101081.html
如何进行类型擦除?
对类型变量进行替换的规则有两条:
1、若为无限定的类型,如 <T>,被替换为 Object
2、若为限定类型,如 <T extends Comparable & Serializable>,则用第一个限定的类型变量来替换,在这里被替换为 Comparable
桥方法(Bridge Method)
编译器通过桥方法协调类型擦除与多态
有如下代码,子类继承父类实现多态
class Father<T> {
T get(T t) {
System.out.println("In father get method: " + t);
return t;
}
}
class Son extends Father<String> {
String get(String t) {
System.out.println("In son get method: " + t);
return t;
}
}
@Test
public void testBridgeMethod() {
// 父类引用 father 指向子类对象 new Son() 最终调用的是 子类的 get 方法,实现多态
Father father = new Son();
System.out.println(father.get("xxx"));
}
运行结果:
In son get method: xxx
xxx
父类引用 father 指向子类对象 new Son() ,最终调用的是 子类的 get 方法,成功实现了多态。
但仔细分析一下,会有些疑问。
由于泛型擦除,父类的 get 方法 T 类型被擦除为 Object
Object get(Object t) {
System.out.println("In father get method: " + t);
return t;
}
我们知道 多态的前提是子类中覆盖/重写(Overwrite)父类的同名方法(通过方法名和参数确定)
但这里 Son 类并没有重写父类的 get(Object t) 方法,只是继承过来后又新增了一个 get(String t) 方法,按说编译器应该在这里报错的,但并没有。
为什么呢?
因为 编译器自动在子类 Son 中生成了一个 桥方法(Bridge Method) ,桥方法重写了父类方法,内部将调用委托给子类方法实现,对外保证多态中方法覆盖的正确性,避免类型擦除与多态发生冲突
Object get(Object t) {
return get(t);
}
桥方法是编译器自动生成的,无需手动实现。
如何处理桥方法带来的签名重复问题?
此外还有个问题,仔细分析下目前子类中所具有的方法
String get(String t) // 子类的 get 方法
Object get(Object t) // 编译器自动生成的桥方法
不难发现,桥方法和子类自己的 get 方法是签名完全相同的,注意:Java中使用方法名和参数列表做方法签名,返回值并不影响方法签名
那为什么不报错呢?
因为 JVM 会用 (方法名,参数类型,返回类型) 来确定一个方法,对于这种编译器自己生成的签名相同但返回值不同的方法,JVM是可以区分的,但是,只能由编译器生成这种代码,编译器绝不允许人为手动编写签名相同的方法
Java中的类型擦除和桥方法
https://juejin.im/post/5bcd741bf265da0abb146f76
both methods have same erasure, yet neither overrides the other
public class Father {
void test(Object o){}
}
class Son<T> extends Father{
void test(T o){}//编译错误!
}
这段代码会报一个编译错误,both methods have same erasure, yet neither overrides the other。
这个错误的意思是,两个方法在类型擦除后,具有相同的原生类型参数列表,但是都不能覆盖另一个方法。
泛型类型在编译后,会做类型擦除,只剩下原生类型。如参数列表中的T类型会编译成Object,但是会有一个Signature。
尽管两个test方法具有相同的字节码,但是类型参数信息用 一个新的签名(signature) 属性记录在类模式中。JVM 在装载类时记录这个签名信息,并在运行时通过反射使它可用。
这就导致了这个方法既不能作为覆盖父类test方法的方法,也不能作为test方法的重载。
both methods have same erasure, yet neither overrides the other 【泛型类型擦除与重载和覆盖问题】
https://blog.csdn.net/L_BestCoder/article/details/77822698
interface and a class. name clash: same erasure, yet neither overrides other
https://stackoverflow.com/questions/15442508/interface-and-a-class-name-clash-same-erasure-yet-neither-overrides-other
Method has the same erasure as another method in type
https://stackoverflow.com/questions/1998544/method-has-the-same-erasure-as-another-method-in-type
Java 泛型使用
泛型有三种使用方式,分别为:泛型类、泛型接口、泛型方法
泛型类
泛型类型用于类的定义中,被称为泛型类。通过泛型可以完成对一组类的操作对外开放相同的接口。最典型的就是各种容器类,如:List、Set、Map。
泛型类示例:
// 此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型
// 在实例化泛型类时,必须指定T的具体类型
public class Generic<T> {
// key这个成员变量的类型为T,T的类型由外部指定
private T key;
public Generic(T key) { //泛型构造方法形参key的类型也为T,T的类型由外部指定
this.key = key;
}
public T getKey(){ //泛型方法getKey的返回值类型为T,T的类型由外部指定
return key;
}
}
泛型类使用:
//泛型的类型参数只能是类类型(包括自定义类),不能是简单类型
//传入的实参类型需与泛型的类型参数类型相同,即为Integer.
Generic<Integer> genericInteger = new Generic<Integer>(123456);
//传入的实参类型需与泛型的类型参数类型相同,即为String.
Generic<String> genericString = new Generic<String>("key_vlaue");
Log.d("泛型测试","key is " + genericInteger.getKey());
Log.d("泛型测试","key is " + genericString.getKey());
java 泛型详解-绝对是对泛型方法讲解最详细的,没有之一
https://blog.csdn.net/s10461/article/details/53941091
使用泛型类时可以不传入泛型实参
使用泛型类时一定要传入泛型类型实参么?
并不是这样,在使用泛型的时候如果传入泛型实参,则会根据传入的泛型实参做相应的限制,此时泛型才会起到本应起到的限制作用。如果不传入泛型类型实参的话,在泛型类中使用泛型的方法或成员变量定义的类型可以为任何的类型。
例如 HashMap 是一个继承了抽象泛型类 AbstractMap 和实现了泛型接口 Map 的泛型类
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
}
但我们实例化 HashMap 时也可以不传入泛型实参:
Map m = new HashMap();
m.put("key", "value");
String s = (String) m.get("key");
但此时为了让程序通过编译,必须将 get() 的结果强制类型转换为 String,并且希望结果真的是一个 String。如果 map 中保存了的不是 String 的数据,则上面的代码将会抛出 ClassCastException
泛型接口
泛型接口与泛型类的定义及使用基本相同。泛型接口常被用在各种类的生产器中,可以看一个例子:
//定义一个泛型接口
public interface Generator<T> {
public T next();
}
实现泛型接口时不指定泛型实参
当实现泛型接口的类,未传入泛型实参时:
/**
* 未传入泛型实参时,与泛型类的定义相同,在声明类的时候,需将泛型的声明也一起加到类中
* 即:class FruitGenerator<T> implements Generator<T>{...}
* 如果不声明泛型,如:class FruitGenerator implements Generator<T>,编译器会报错:"Unknown class"
*/
class FruitGenerator<T> implements Generator<T>{
@Override
public T next() {
return null;
}
}
实现泛型接口时指定泛型实参
当实现泛型接口的类,传入泛型实参时:
/**
* 传入泛型实参时:
* 定义一个生产器实现这个接口,虽然我们只创建了一个泛型接口Generator<T>
* 但是我们可以为T传入无数个实参,形成无数种类型的Generator接口。
* 在实现类实现泛型接口时,如已将泛型类型传入实参类型,则所有使用泛型的地方都要替换成传入的实参类型
* 即:Generator<T>,public T next();中的的T都要替换成传入的String类型。
*/
public class FruitGenerator implements Generator<String> {
private String[] fruits = new String[]{"Apple", "Banana", "Pear"};
@Override
public String next() {
Random rand = new Random();
return fruits[rand.nextInt(3)];
}
}
java 泛型详解-绝对是对泛型方法讲解最详细的,没有之一
https://blog.csdn.net/s10461/article/details/53941091
泛型方法
1、泛型类,是在实例化类的时候指明泛型的具体类型;泛型方法,是在调用方法的时候指明泛型的具体类型 。
2、只有声明了 <T> 的方法才是泛型方法,泛型类中的使用了泛型的成员方法并不是泛型方法
3、泛型的数量也可以为任意多个,例如 public <T,K> K showKeyName(Generic<T> container)
泛型方法的声明:
/**
* 泛型方法的基本介绍
* @param tClass 传入的泛型实参
* @return T 返回值为T类型
* 说明:
* 1)public 与 返回值中间 <T> 非常重要,可以理解为声明此方法为泛型方法。
* 2)只有声明了<T>的方法才是泛型方法,泛型类中的使用了泛型的成员方法并不是泛型方法。
* 3)<T>表明该方法将使用泛型类型T,此时才可以在方法中使用泛型类型T。
* 4)与泛型类的定义一样,此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型。
*/
public <T> T genericMethod(Class<T> tClass) throws InstantiationException ,IllegalAccessException {
T instance = tClass.newInstance();
return instance;
}
区分泛型方法和使用泛型的方法
泛型方法注意事项:
public class GenericTest {
// 这个类是个泛型类
class Generic<T> {
private T key;
public Generic(T key) {
this.key = key;
}
//我想说的其实是这个,虽然在方法中使用了泛型,但是这并不是一个泛型方法。
//这只是类中一个普通的成员方法,只不过他的返回值是在声明泛型类已经声明过的泛型。
//所以在这个方法中才可以继续使用 T 这个泛型。
public T getKey(){
return key;
}
/**
* 这个方法显然是有问题的,在编译器会给我们提示这样的错误信息"cannot reslove symbol E"
* 因为在类的声明中并未声明泛型E,所以在使用E做形参和返回值类型时,编译器会无法识别。
public E setKey(E key){
this.key = keu
}
*/
}
/**
* 这才是一个真正的泛型方法。
* 首先在 public 与返回值之间的 <T> 必不可少,这表明这是一个泛型方法,并且声明了一个泛型 T
* 这个 T 可以出现在这个泛型方法的任意位置.
* 泛型的数量也可以为任意多个
* 如:public <T,K> K showKeyName(Generic<T> container){
* ...
* }
*/
public <T> T showKeyName(Generic<T> container){
System.out.println("container key :" + container.getKey());
//当然这个例子举的不太合适,只是为了说明泛型方法的特性。
T test = container.getKey();
return test;
}
//这也不是一个泛型方法,这就是一个普通的方法,只是使用了Generic<Number>这个泛型类做形参而已。
public void showKeyValue1(Generic<Number> obj){
Log.d("泛型测试","key value is " + obj.getKey());
}
//这也不是一个泛型方法,这也是一个普通的方法,只不过使用了泛型通配符?
//同时这也印证了泛型通配符章节所描述的,?是一种类型实参,可以看做为Number等所有类的父类
public void showKeyValue2(Generic<?> obj){
Log.d("泛型测试","key value is " + obj.getKey());
}
/**
* 这个方法是有问题的,编译器会为我们提示错误信息:"UnKnown class 'E' "
* 虽然我们声明了<T>,也表明了这是一个可以处理泛型的类型的泛型方法。
* 但是只声明了泛型类型T,并未声明泛型类型E,因此编译器并不知道该如何处理E这个类型。
public <T> T showKeyName(Generic<E> container){
...
}
*/
/**
* 这个方法也是有问题的,编译器会为我们提示错误信息:"UnKnown class 'T' "
* 对于编译器来说T这个类型并未项目中声明过,因此编译也不知道该如何编译这个类。
* 所以这也不是一个正确的泛型方法声明。
public void showkey(T genericObj){
}
*/
public static void main(String[] args) {
}
}
泛型方法中指定边界
// 在泛型方法中添加上下边界限制的时候,必须在权限声明与返回值之间的 <T> 上添加上下边界,即在泛型声明的时候添加
// public <T> T showKeyName(Generic<T extends Number> container),编译器会报错:"Unexpected bound"
public <T extends Number> T showKeyName(Generic<T> container){
System.out.println("container key :" + container.getKey());
T test = container.getKey();
return test;
}
泛型类中的泛型方法
如下
class GenerateTest<T> {
// 此方法并不是泛型方法,只是普通方法,只不过使用了在泛型类中声明过的泛型T
public void show_1(T t){
System.out.println(t.toString());
}
//在泛型类中声明了一个泛型方法,使用泛型E,这种泛型E可以为任意类型。可以类型与T相同,也可以不同。
//由于泛型方法在声明的时候会声明泛型<E>,因此即使在泛型类中并未声明泛型,编译器也能够正确识别泛型方法中识别的泛型。
public <E> void show_3(E t){
System.out.println(t.toString());
}
//在泛型类中声明了一个泛型方法,使用泛型T,注意这个T是一种全新的类型,可以与泛型类中声明的T不是同一种类型。
public <T> void show_2(T t){
System.out.println(t.toString());
}
public static void main(String[] args) {
Apple apple = new Apple();//Apple是Fruit的子类
Person person = new Person();
GenerateTest<Fruit> generateTest = new GenerateTest<Fruit>();
//apple是Fruit的子类,所以这里可以
generateTest.show_1(apple);
//编译器会报错,因为泛型类型实参指定的是Fruit,而传入的实参类是Person
//generateTest.show_1(person);
//使用这两个方法都可以成功
generateTest.show_2(apple);
generateTest.show_2(person);
//使用这两个方法也都可以成功
generateTest.show_3(apple);
generateTest.show_3(person);
}
}
静态泛型方法
静态方法无法访问类上定义的泛型;如果静态方法操作的引用数据类型不确定的时候,必须要将泛型定义在方法上。
即:如果静态方法要使用泛型的话,必须将静态方法也定义成泛型方法 。
这很容易理解,因为泛型类是在实例化的时候指定具体类型的,而静态方法在实例化之前就可以被调用,所以肯定无法访问泛型类中的泛型。
public class StaticGenerator<T> {
....
....
/**
* 如果在类中定义使用泛型的静态方法,需要添加额外的泛型声明(将这个方法定义成泛型方法)
* 即使静态方法要使用泛型类中已经声明过的泛型也不可以。
* 如:public static void show(T t){..},此时编译器会提示错误信息:
"StaticGenerator cannot be refrenced from static context"
*/
public static <T> void show(T t){
}
}
java 泛型详解-绝对是对泛型方法讲解最详细的,没有之一
https://blog.csdn.net/s10461/article/details/53941091
通配符和上下边界
<? extends T> 是指 “上界通配符(Upper Bounds Wildcards)”<? super T> 是指 “下界通配符(Lower Bounds Wildcards)”
为什么需要通配符和边界?
我们有 Fruit 类,和它的派生类 Apple 类:
class Fruit {}
class Apple extends Fruit {}
然后有一个最简单的容器:Plate 类。盘子里可以放一个泛型的“东西”。我们可以对这个东西做最简单的“放”和“取”的动作:set() 和 get() 方法。
class Plate<T> {
private T item;
public Plate(T t){item=t;}
public void set(T t){item=t;}
public T get(){return item;}
}
现在我定义一个“水果盘子”,逻辑上水果盘子当然可以装苹果。
Plate<Fruit> p = new Plate<Apple>(new Apple());
但实际上Java编译器不允许这个操作。
报错
error: incompatible types: Plate<Apple> cannot be converted to Plate<Fruit>
所以,就算容器里装的东西之间有继承关系,但容器之间是没有继承关系的。所以我们不可以把 Plate<Apple> 的引用传递给 Plate<Fruit>
Java 泛型 <? super T> 中 super 怎么 理解?与 extends 有何不同? - 胖胖的回答 - 知乎
https://www.zhihu.com/question/20400700/answer/117464182
上界<?extends T>可取不可存
Plate<? extends Fruit> p,泛型 ? 覆盖 Fruit 及其子类。可存放Fruit,Apple,RedApple,但不能存放Food
参数写成: ? extends B ,由于指定了B为所有元素的“根”,你任何时候都可以安全的用B来使用容器里的元素,但是插入有问题,由于供奉B为祖先的子树有很多,不同子树并不兼容,由于实参可能来自于任何一颗子树,所以你的插入很可能破坏函数实参,所以,对这种写法的形参,禁止做插入操作,只做读取。
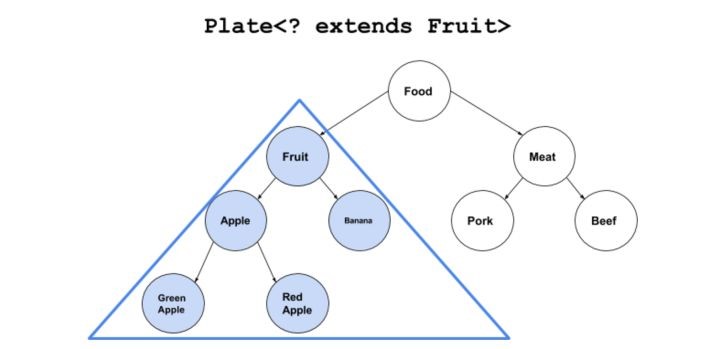
使用泛型上下界的副作用是容器的部分功能可能失效。
上界<? extends T>不能往里存,只能往外取<? extends Fruit>会使往盘子里放东西的set()方法失效。但取东西get()方法还有效。比如下面例子里两个set()方法,插入Apple和Fruit都报错。
Plate<? extends Fruit> p = new Plate<Apple>(new Apple());
//不能存入任何元素
p.set(new Fruit()); //Error
p.set(new Apple()); //Error
//读取出来的东西只能存放在Fruit或它的基类里。
Fruit newFruit1=p.get();
Object newFruit2=p.get();
Apple newFruit3=p.get(); //Error
原因是编译器只知道容器内是Fruit或者它的派生类,但具体是什么类型不知道。可能是Fruit?可能是Apple?也可能是Banana,RedApple,GreenApple?编译器在看到后面用Plate<Apple>赋值以后,盘子里没有被标上有“苹果”。而是标上一个占位符:CAP#1,来表示捕获一个Fruit或Fruit的子类,具体是什么类不知道,代号CAP#1。然后无论是想往里插入Apple或者Meat或者Fruit编译器都不知道能不能和这个CAP#1匹配,所以就都不允许。
所以通配符<?>和类型参数<T>的区别就在于,对编译器来说所有的T都代表同一种类型。比如下面这个泛型方法里,三个T都指代同一个类型,要么都是String,要么都是Integer。
public <T> List<T> fill(T... t);
但通配符?没有这种约束,Plate<?>单纯的就表示:盘子里放了一个东西,是什么我不知道。
下界<? super T>可存不可取
Plate<? super Fruit> p,泛型?覆盖Fruit及其父类。可以存放Food,Fruit,Apple,RedApple(因为Apple和RedApple是Fruit的子类,能存放Fruit自然可存放Apple和RedApple)
参数写成:? super B ,对于这个泛型,?代表容器里的元素类型,由于只规定了元素必须是B的超类,导致元素没有明确统一的“根”(除了Object这个必然的根),所以这个泛型你其实无法获取其中的元素,除了把元素强制转成Object。但是插入时可以插入所有B及子类型的元素。所以,对把参数写成这样形态的函数,你函数体内,只能对这个泛型做插入操作,而无法读
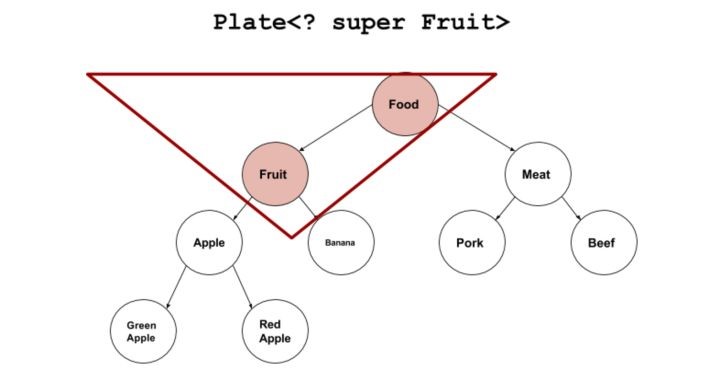
下界<? super T>不影响往里存,但往外取只能放在Object对象里
使用下界<? super Fruit>会使从盘子里取东西的get()方法部分失效,只能存放到Object对象里。set()方法正常。
Plate<? super Fruit> p=new Plate<Fruit>(new Fruit());
//存入元素正常
p.set(new Fruit());
p.set(new Apple());
//读取出来的东西只能存放在Object类里。
Apple newFruit3=p.get(); //Error
Fruit newFruit1=p.get(); //Error
Object newFruit2=p.get();
因为下界规定了元素的最小粒度的下限,实际上是放松了容器元素的类型控制。既然元素是Fruit的基类,那往里存粒度比Fruit小的都可以。但往外读取元素就费劲了,只有所有类的基类Object对象才能装下。但这样的话,元素的类型信息就全部丢失。
PECS原则(读用extends,写用super)
PECS(Producer Extends Consumer Super)原则
Joshua Bloch在著名的《Effective Java》中提出了PECS以帮助大家理解和记忆泛型通配符的用法,简洁有力。
PECS的意思是:Producer Extends, Consumer Super,即“Extends是生产者只往外吐,Super消费者只往里吃”
如果要从集合中读取类型T的数据,并且不能写入,可以使用 ? extends 通配符;(Producer Extends)
如果要从集合中写入类型T的数据,并且不需要读取,可以使用 ? super 通配符;(Consumer Super)
如果既要存又要取,那么就不要使用任何通配符。
Java 泛型 <? super T> 中 super 怎么 理解?与 extends 有何不同? - 胖胖的回答 - 知乎
https://www.zhihu.com/question/20400700/answer/117464182
Class 和 Class<?> 区别
https://stackoverflow.com/questions/1007084/difference-between-class-and-class
面向对象与多态
访问控制public/protected/default/private
privateprivate 表示私有,私有的意思就是除了 class 自己之外任何人都不可以直接使用,即便是子女(子类)、朋友(同一package下的)都不可以使用。default(默认,不加访问控制时): 有时候也称为 friendly,它是针对本 package 访问而设计的,可被同 package 中的类访问,但不能被子类访问protectedprotected 对于子女、朋友来说,就是public的,可以自由使用,没有任何限制,而对于其他的外部class,protected就变成private。publicpublic 表明该数据成员、成员函数是对所有用户开放的,可以被classpath下所有类、接口访问。
即:private 只能类内访问,default 开放给同包下访问, protected 进一步开放给子女访问, public 任何人都能访问。
注意:java的访问控制是停留在编译层的,也就是它不会在.class文件中留下任何的痕迹,只在编译的时候进行访问控制的检查。其实,通过反射的手段,是可以访问任何包下任何类中的成员,例如,访问类的私有成员也是可能的。
| 关键字 | 类内部 | 本包 | 子类 | 外部包 |
|---|---|---|---|---|
| public | √ | √ | √ | √ |
| protected | √ | √ | √ | × |
| default | √ | √ | × | × |
| private | √ | × | × | × |
java作用域public ,private ,protected 及不写时的区别
https://blog.csdn.net/ladofwind/article/details/774072
继承后的访问控制
和父类在同一个包中的子类会继成所有public,protced,default属性和方法
和父类在不同包中的子类会继成所有public,protced属性和方法,但是因为和父类在不同包中,所以并不能继承default级别属性和方法
总之:父类里面所有public和protected属性子类都能继承,但是只有当子类和父亲在同一个包中的时候才能继承默认级别属性。
java之中的四种访问权限和子类如何继承父类特性
https://blog.csdn.net/qq_34536381/article/details/51553560
通过AccessibleObject.setAccessible()访问private成员/方法
方法重载
方法重载是在编译阶段确定的,编译器根据参数列表的不同(个数、类型、顺序)来决定具体调用哪个方法。
注意:
(1) 声明为final的方法不能被重载
(2) 仅返回类型不同不构成重载。
Java中使用方法名和参数列表做方法签名,返回值并不影响方法签名。
方法绑定(将方法与所在类关联)
把一个方法与其所在的类/对象 关联起来叫做方法的绑定。绑定分为静态绑定(前期绑定)和动态绑定(后期绑定)。
静态绑定和动态绑定的区别:
- 程序在JVM运行过程中,会把类的类型信息、static属性和方法、final常量等元数据加载到方法区,这些在类被加载时就已经知道,不需对象的创建就能访问的,就是静态绑定的内容;
- 需要等对象创建出来,使用时根据堆中的实例对象的类型才进行取用的就是动态绑定的内容。
静态绑定(final/static/private方法)
静态绑定(前期绑定)是指:在程序运行前就已经知道方法是属于那个类的,在编译的时候就可以连接到类的中,定位到这个方法。
在Java中,final、private、static修饰的方法以及构造函数都是静态绑定的,不需程序运行,不需具体的实例对象就可以知道这个方法的具体内容。
自动转型与最佳匹配
如下代码
public class PolyTest {
public static void main(String[] args){
Father father = new Son(); //父类引用指向之类对象
//通过参数的自动转型找到Father.whoami(int i)方法
//由于父类引用无法调用子类新增的方法whoami(char c),所以最终调用的肯定是父类的whoami(int i)
father.whoami('a');
}
}
class Father{
public void whoami(){ System.out.println("Father.whoami()"); }
public void whoami(int i) { System.out.println("Father.whoami(int i): "+i); }
}
class Son extends Father{
public void whoami(){ System.out.println("Son.whoami()"); }
public void whoami(char c) { System.out.println("Son.whoami(char c): "+c); }
}
运行结果:Father.whoami(int i): 97
在代码的编译阶段,编译器通过 声明对象的类型(即引用本身的类型) 在方法区中该类型的方法表中查找匹配的方法(最佳匹配法:参数类型最接近的被调用),如果有则编译通过。(这里是根据声明的对象类型来查找的,所以此处是查找 Father类的方法表,而Father类方法表中是没有子类新增的方法的,所以不能调用。)
那么什么叫”匹配”的方法呢?
方法签名完全一样的方法自然是合适的。但是如果方法中的参数类型在声明的类型中并不能找到呢?比如上面的代码中调用father.whoami(char),Father类型并没有whoami(char)的方法签名。实际上,JVM会找到一种“凑合”的办法,就是通过 参数的自动转型 来找 到“合适”的 方法。比如char可以通过自动转型成int,那么Father类中就可以匹配到这个方法了。
但是还有一个问题,如果通过自动转型发现可以“凑合”出两个方法的话怎么办?比如下面的代码:
class Father{
public void f1(Object o){
System.out.println("Object");
}
public void f1(double[] d){
System.out.println("double[]");
}
}
public class Demo{
public static void main(String[] args) {
new Father().f1(null); //打印结果: double[]
}
}
null可以引用于任何的引用类型,那么JVM如何确定“合适”的方法呢。一个很重要的标准就是:如果一个方法可以接受传递给另一个方法的任何参数,那么第一个方法就相对不合适。比如上面的代码: 任何传递给f1(double[])方法的参数都可以传递给f1(Object)方法,而反之却不行,那么f1(double[])方法就更合适。因此JVM就会调用这个更合适的方法。
即优先匹配类型最具体的。
【解惑】Java动态绑定机制的内幕
http://hxraid.iteye.com/blog/428891
动态绑定(父类引用指向子类对象)
动态绑定(后期绑定)是指:在程序运行过程中,根据具体的实例对象才能具体确定是哪个方法。
动态绑定是多态性得以实现的重要因素,它通过方法表来实现:每个类被加载到虚拟机时,在方法区保存元数据,其中,包括一个叫做 方法表(method table)的东西,表中记录了这个类定义的方法的指针,每个表项指向一个具体的方法代码。如果这个类重写了父类中的某个方法,则对应表项指向新的代码实现处。从父类继承来的方法位于子类定义的方法的前面。
方法表
在JVM加载类的同时,会在方法区中为这个类存放很多信息。其中就有一个数据结构叫方法表。它以数组的形式记录了当前类及其所有超类的可见方法字节码在内存中的直接地址 。
下图是上面源代码中Father和Son类在方法区中的方法表:(Son类继承Father,Father中有f1()和f1(int),Son中有f1()和f1(char))
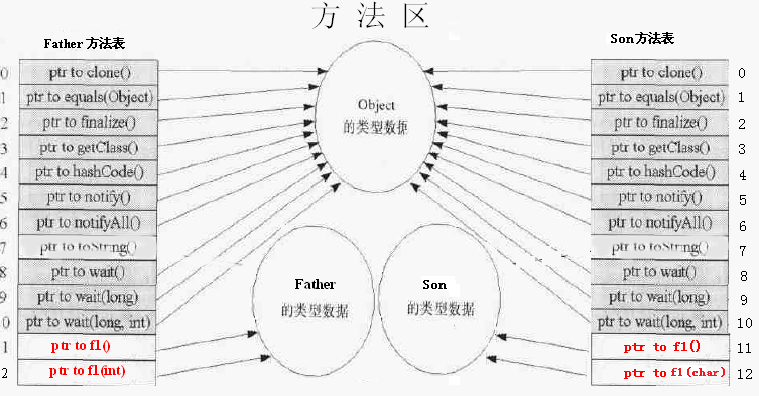
上图中的方法表有两个特点:
(1) 子类方法表中继承了父类的方法,比如Father extends Object。
(2) 相同的方法(相同的方法签名:方法名和参数列表)在所有类的方法表中的索引相同。比如Father方法表中的f1()和Son方法表中的f1()都位于各自方法表的第11项中。
【解惑】Java动态绑定机制的内幕
http://hxraid.iteye.com/blog/428891
动态绑定的原理(方法表)
动态绑定语句的编译、运行原理:我们假设 Father ft = new Son(); ft.say(); Son继承自Father,重写了say()。
1:编译:我们知道,向上转型时,用父类引用指向子类对象,并可以用父类引用调用子类中重写了的同名方法。但是不能调用子类中新增的方法,为什么呢?
因为在代码的编译阶段,编译器通过 声明对象的类型(即引用本身的类型) 在方法区中该类型的方法表中查找匹配的方法(最佳匹配法:参数类型最接近的被调用),如果有则编译通过。(这里是根据声明的对象类型来查找的,所以此处是查找 Father 类的方法表,而 Father 类方法表中是没有子类新增的方法的,所以不能调用。)
编译阶段是确保方法的存在性,保证程序能顺利、安全运行。
2:运行:我们又知道, ft.say() 调用的是 Son 中的 say() ,这不就与上面说的,查找Father类的方法表的匹配方法矛盾了吗?
不,这里就是动态绑定机制的真正体现。
上面编译阶段在 声明对象类型 的方法表中查找方法,只是为了安全地通过编译(也为了检验方法是否是存在的)。而在实际运行这条语句时,在执行 Father ft = new Son(); 这一句时创建了一个Son实例对象,然后在 ft.say() 调用方法时,JVM会把刚才的son对象压入操作数栈,用它来进行调用。而用实例对象进行方法调用的过程就是动态绑定:根据实例对象所属的类型去查找它的方法表,找到匹配的方法进行调用。我们知道,子类中如果重写了父类的方法,则方法表中同名表项会指向子类的方法代码;若无重写,则按照父类中的方法表顺序保存在子类方法表中。故此:动态绑定根据对象的类型的方法表查找方法是一定会匹配(因为编译时在父类方法表中以及查找并匹配成功了,说明方法是存在的。这也解释了为何向上转型时父类引用不能调用子类新增的方法:在父类方法表中必须先对这个方法的存在性进行检验,如果在运行时才检验就容易出危险——可能子类中也没有这个方法)。
Java方法的静态绑定与动态绑定讲解(向上转型的运行机制详解)
https://www.cnblogs.com/ygj0930/p/6554103.html
抽象类与接口的异同
只给出方法定义而不具体实现的方法被称为抽象方法,抽象方法是没有方法体的,在代码的表达上就是没有“{}”。
包含一个或多个抽象方法的类也必须被声明为抽象类。
使用abstract修饰符来表示抽象方法和抽象类。
抽象类除了包含抽象方法外,还可以包含具体的变量和具体的方法。
类即使不包含抽象方法,也可以被声明为抽象类,防止被实例化。
包含抽象方法的类一定是抽象类。
抽象类不能直接使用,必须用子类去实现抽象类,然后使用其子类的实例。
接口可以看做是一种特殊的抽象类,接口中所有的方法必须都是抽象的,不能有方法体,它比抽象类更加“抽象”。
接口中声明的成员变量默认都是public static final的,必须显示的初始化。因而在常量声明时可以省略这些修饰符。
接口中只能定义抽象方法,这些方法默认为public abstract的,因而在声明方法时可以省略这些修饰符。
接口中没有构造方法,不能被实例化。
一个接口不实现另一个接口,但可以继承多个其他接口。接口的多继承特点弥补了类的单继承。
接口作为类型
不允许创建接口的实例,但允许定义接口类型的引用变量,该变量指向了实现接口的类的实例。
抽象类和接口的区别
(1) 抽象类可以为部分方法提供实现,避免了在子类中重复实现这些方法,提高了代码的可重用性,这是抽象类的优势;而接口中只能包含抽象方法,不能包含任何实现。
(2) 一个类只能继承一个直接的父类(可能是抽象类),但一个类可以实现多个接口,这个就是接口的优势。
instanceof操作符
instanceof是一个二元操作符(运算符),和==类似,判断其左边对象是否为其右边类的实例,返回值为boolean类型。
如果变量引用的是当前类或它的子类的实例,instanceof 返回 true,否则返回 false。
boolean result = object instanceof class
内部类
在一个类(或方法、语句块)的内部定义的类,叫内部类(Inner Class),或嵌套类(Nested Class),此时外部类称为 enclosing class
内部类会被编译成独立的字节码文件。
编译器将会把内部类翻译成用 $ 符号分隔外部类名与内部类名的常规类文件,而虚拟机则对此一无所知。
注意:内部类是一个编译时的概念,一旦编译成功,就会成为完全不同的两类。
对于一个名为 Outer 的外部类和其内部定义的名为 Inner 的内部类。编译完成后出现 Outer.class 和 Outer$Inner.class 两类。
静态内部类和非静态内部类
内部类可以是 static 的,也可以是非 static的。
Java 中不能用 static 修饰顶级类(top level class),只有内部类可以为 static
静态内部类和非静态内部类之间到底有什么不同呢?
(1)内部静态类不需要有指向外部类的引用。但非静态内部类需要持有对外部类的引用, 即 Outer.this。
(2)非静态内部类能够访问外部类的静态和非静态成员。静态类不能访问外部类的非静态成员。他只能访问外部类的静态成员。
(3)一个非静态内部类不能脱离外部类实体被创建,一个非静态内部类可以访问外部类的数据和方法,因为他就在外部类里面。
(4)非静态内部类中无法声明 static 方法,因为 非静态内部类依赖于一个外部类的对象,无法提供 static 方法。
Inner classes cannot have static declaration
非 static 内部类内无法声明 static 方法
例如
class OuterClass {
class InnerClass {
public static void staticMethod() {
System.out.println("xxx");
}
}
}
无法通过编译,提示 Inner classes cannot have static declaration
原因:非 static 内部类是与一个外部类的实例隐式关联的,那自然就无法在其中定义 static 方法了,因为 static 方法可能在实例还不存在的时候就被调用,肯定出问题。
Why can’t we have static method in a (non-static) inner class?
https://stackoverflow.com/questions/975134/why-cant-we-have-static-method-in-a-non-static-inner-class
RecyclerView: Inner classes cannot have static declaration
https://stackoverflow.com/questions/31956340/recyclerview-inner-classes-cannot-have-static-declaration
为什么外部类可直接访问内部类的private成员?(access$000方法)
我们通过静态内部类实现单例模式时,代码如下
public class Singleton {
private Singleton() {}
private static class SingletonInstanceHolder {
private static final Singleton INSTANCE = new Singleton();
}
public static Singleton getInstance() {
return SingletonInstanceHolder.INSTANCE;
}
}
可能会有这样的疑问, SingletonInstanceHolder 中的 INSTANCE 是 private 的,为什么外部的 Singleton 类直接就能访问呢?
其实这是个 Java 编译器实现的语法糖。
Java 语言规范里规定了外部类可以访问内部类的 private/protected 成员,内部类也可以访问外部类的 private/protected 成员,但是没有规定死要如何实现这种访问。
从 JVM 的角度来看,所有类都是顶层类(Top Level),类之间没有嵌套关系,所以是编译器实现了嵌套类之间的 private/protected 访问。
具体如何实现的呢?
看下面例子
public class OuterInnerTest {
class Outer {
private int i = 1;
// 外部类访问内部类 private 变量
public void accessInnerPrivateField() {
System.out.println(new Inner().i);
}
class Inner {
private int i = 2;
}
}
// 外部类访问内部类 private 变量
@Test
public void testOuterAccessInnerPrivateField() {
Outer outer = new Outer();
outer.accessInnerPrivateField();
}
}
反编译后 Outer 类为
class OuterInnerTest$Outer {
private int i;
OuterInnerTest$Outer(final OuterInnerTest this$0) {
this.this$0 = this$0;
this.i = 1;
}
public void accessInnerPrivateField() {
System.out.println(com.masikkk.common.base.OuterInnerTest.Outer.Inner.access$000(new com.masikkk.common.base.OuterInnerTest.Outer.Inner(this)));
}
}
可以看到,编译器生成了一个 Inner.access$000() 方法来提供对内部类 private 成员变量的访问,这个方法是 default 访问类型的,外部类可访问,这个方法在反编译后也看不到,需要看字节码才能看到,实现是类似如下这种
static /* synthetic */ int access$000(Outer$Inner self) {
return self.i;
}
为什么内部类的private变量可被外部类直接访问?
https://www.zhihu.com/question/54730071
内部类如何访问外部类的同名成员?(Outer.this引用)
非静态内部类能够访问外部类成员是因为它持有外部类对象的引用 Outer.this 即 外部类名.this, 就像子类对像能够访问父类成员是持有父类对象引用 super一样。
局部内部类也和一般内部类一样,只持有了 Outer.this,就能够访问外部类成员。
内部类可直接访问外部类的 private/protected/public 字段和方法,但是,当外部类的成员和内部类的成员重名时,如何访问外部类中的重名成员呢?
此时,可通过 Outer.this.field 来访问外部类中的同名成员,也就是 外部类名.this.外部类中需要被访问的成员名
内部类访问外部类的同名变量测试
public class OuterInnerTest {
class Outer {
private int i = 1;
class Inner {
private int i = 2;
public void printInt() {
int i = 3;
System.out.println("内部类方法中的局部变量i: " + i);
System.out.println("内部类成员变量i: " + this.i);
System.out.println("外部类成员变量i: " + Outer.this.i);
i = 33;
this.i = 22;
Outer.this.i = 11;
System.out.println("内部类方法中的局部变量i: " + i);
System.out.println("内部类成员变量i: " + this.i);
System.out.println("外部类成员变量i: " + Outer.this.i);
}
}
}
// 内部类访问外部类的同名变量
@Test
public void testInnerClassAccessOuterClassSameNameField() {
Inner inner = new Outer().new Inner();
inner.printInt();
}
}
结果:
内部类方法中的局部变量i: 3
内部类成员变量i: 2
外部类成员变量i: 1
内部类方法中的局部变量i: 33
内部类成员变量i: 22
外部类成员变量i: 11
匿名内部类如何访问外部类的局部变量和外部方法参数?(构造方法参数)
匿名内部类,它可能引用三种外部变量:
- 外部类的成员变量
- 外部方法或作用域内的局部变量
- 外部方法的参数
测试代码如下:
public class AnonymousInnerTest {
class Outer {
private int outerFieldInt = 1;
void anonymousClassInMethod(int outerParamInt) {
int outerLocalInt = 3;
Inner inner = new Inner() {
public void printValue() {
System.out.println("访问外部类成员变量 outerFieldInt: " + outerFieldInt);
System.out.println("访问外部类方法参数 outerParamInt: " + outerParamInt);
System.out.println("访问外部类局部变量 outerLocalInt: " + outerLocalInt);
// outerLocalInt = 11; // final 无法修改
// outerLocalInt = 33; // final 无法修改
// outerParamInt = 22; // final 无法修改
}
};
inner.printValue();
}
}
interface Inner {
void printValue();
}
@Test
public void testAnonymousInnerClassAccessOuterValue() {
new Outer().anonymousClassInMethod(2);
}
}
结果
访问外部类成员变量 outerFieldInt: 1
访问外部类方法参数 outerParamInt: 2
访问外部类局部变量 outerLocalInt: 3
通过 http://javare.cn/ 反编译后(注意 JD-GUI 之类的工具反编译后代码不全,最好用这个在线工具)的匿名内部类为 AnonymousInnerTest$Outer$1,代码如下
package com.masikkk.common.base;
import com.masikkk.common.base.AnonymousInnerTest.Inner;
import com.masikkk.common.base.AnonymousInnerTest.Outer;
class AnonymousInnerTest$Outer$1 implements Inner {
AnonymousInnerTest$Outer$1(final Outer this$1, final int val$outerLocalInt, final int val$outerParamInt) {
this.this$1 = this$1;
this.val$outerParamInt = var2;
this.val$outerLocalInt = var3;
}
public void printValue() {
System.out.println("访问外部类成员变量 outerFieldInt: " + Outer.access$000(this.this$1));
System.out.println("访问外部类方法参数 outerParamInt: " + this.val$outerParamInt);
System.out.println("访问外部类局部变量 outerLocalInt: " + this.val$outerLocalInt);
}
}
可以看到
匿名内部类引用的外部类局部变量 outerLocalInt 和 外部类方法参数 outerParamInt 以及外部类的引用 this 都会被当做匿名内部类的构造函数的参数传入匿名内部类中,并将其作为内部类的成员属性封装在类中,以便匿名内部类访问。但外部类的成员变量无需传入,因为可通过外部类的引用来访问。
所以 匿名内部类访问外部类的局部变量 或 外部类的方法参数时,必须为 final,即便没有显示声明为 final ,也是隐式 final(effectively final) 的,无法在匿名内部类中修改,因为可修改的话就不一致了,匿名内部类中操作的是通过构造方法传入的外部类的局部变量或方法参数的副本。
但是 匿名内部类访问外部类的成员变量时,该变量无须 final 修饰,因为是通过 final 的 Outer.this 指针访问的。
java为什么匿名内部类的参数引用时final?
https://www.zhihu.com/question/21395848
内部类(或匿名类)只能访问外部的final变量
匿名内部类和局部内部类只能访问外部的final变量
原因是:局部变量的生命周期与局部内部类对象的生命周期的不一致性!
设方法f()被调用,从而在它的调用栈中生成了变量i,此时产生了一个局部内部类对象inner_object,它访问了该局部变量i。当方法f()运行结束后,局部变量i就已死亡了,不存在了。但局部内部类对象inner_object还可能一直存在(只能没有人再引用该对象时,它才会死亡),它不会随着方法f()运行结束而死亡。这时就出现了一个”荒唐”结果:局部内部类对象inner_object要访问一个已不存在的局部变量i
如何才能实现?
当变量是final时,通过将final局部变量”复制”一份,复制品直接作为局部内部中的数据成员。这样,当局部内部类访问局部变量时,其实真正访问的是这个局部变量的”复制品”(即这个复制品就代表了那个局部变量)。因此,当运行栈中的真正的局部变量死亡时,局部内部类对象仍可以访问局部变量(其实访问的是”复制品”),给人的感觉:好像是局部变量的”生命期”延长了。
那么,核心的问题是:怎么才能使得访问”复制品”与访问真正的原始的局部变量其语义效果是一样的呢?
当变量是final时,若是基本数据类型,由于其值不变,因而其复制品与原始的量是一样,语义效果相同(若不是final,就无法保证复制品与原始变量保持一致了,因为在方法中改的是原始变量,而局部内部类中改的是复制品)。
当变量是final时,若是引用类型,由于其引用值不变(即永远指向同一个对象),因而其复制品与原始的引用变量一样,永远指向同一个对象(由于是final从而保证只能指向这个对象,再不能指向其它对象),达到局部内部类中访问的复制品与方法代码中访问的原始对象永远都是同一个,即语义效果是一样的。否则,当方法中改原始变量,而局部内部类中改复制品时,就无法保证复制品与原始变量保持一致了。
Java 8 语言的 lambda 表达式只实现了 capture-by-value,也就是说它捕获的局部变量都会拷贝一份到 lambda 表达式的实体里,然后在 lambda 表达式里要变也只能变自己的那份拷贝而无法影响外部原本的变量;
内部类访问局部变量的时候,为什么变量必须加上final修饰
http://www.cnblogs.com/xh0102/p/5729381.html
为什么匿名内部类和局部内部类只能访问final变量
http://blog.csdn.net/salahg/article/details/7529091
static关键字
在《Java编程思想》P86页有这样一段话:
“static方法就是没有this的方法。在static方法内部不能调用非静态方法,反过来是可以的。而且可以在没有创建任何对象的前提下,仅仅通过类本身来调用static方法。这实际上正是static方法的主要用途。”
static方法
static方法一般称作静态方法,由于静态方法不依赖于任何对象就可以进行访问,因此对于静态方法来说,是没有this的,因为它不依附于任何对象,既然都没有对象,就谈不上this了。并且由于这个特性,在静态方法中不能访问类的非静态成员变量和非静态成员方法,因为非静态成员方法/变量都是必须依赖具体的对象才能够被调用。
为什么static方法中不能访问非static方法?
1、因为static方法不依赖于任何对象,其中不含this指针,所以无法调用依赖于具体对象的非static方法。
每个非static方法中都有this指针,指向当前调用此方法的对象;非static方法调用该类其他方法的时候实际上是用到了this.[Method]
2、static方法是在编译的时候确定的,在类装入内存的时候也同时装入内存了。而非static方法是在类的实例化的时候装入内存的,其必须依赖于类的实例。
static变量
static变量也称作静态变量,静态变量和非静态变量的区别是:静态变量被所有的对象所共享,在内存中只有一个副本,它当且仅当在类初次加载时会被初始化。而非静态变量是对象所拥有的,在创建对象的时候被初始化,存在多个副本,各个对象拥有的副本互不影响。
区别:
1、静态变量所有实例共享一个,在内存中只有一份。非静态变量每个实例对象有一个,在内存中有多份。
2、初始化时机不同:静态变量在类被初次加载时初始化,不论是否被使用。非静态变量在创建对象的时候被初始化。
注意:只要类被装载,静态变量就会被初始化,不管你是否使用了这个静态变量
static成员变量的初始化顺序按照定义的顺序进行初始化。
static变量一定可以通过Class.val访问吗?
不是
static变量前可以有private修饰,表示这个变量可以在类的静态代码块中或者类的其他静态成员方法中使用(当然也可以在非静态成员方法中使用–废话),但是不能在其他类中通过类名来直接引用,这一点很重要。
实际上你需要搞明白,private是访问权限限定,static表示不要实例化就可以使用,这样就容易理解多了。
只有public static变量才能通过Class.val直接访问。
static前面加上其它访问权限关键字的效果也以此类推。
static代码块
static关键字还有一个比较关键的作用就是 用来形成静态代码块以优化程序性能。static块可以置于类中的任何地方,类中可以有多个static块。在类初次被加载的时候,会按照static块的顺序来执行每个static块,并且只会执行一次。
static类/静态内部类
Java中的类可以是static吗?
答案是可以。在java中我们可以有静态实例变量、静态方法、静态块。类也可以是静态的。
Java 中不能用 static 修饰顶级类(top level class),只有内部类可以为static
相关特性已在内部类中描述。
Java中的static关键字解析
http://www.cnblogs.com/dolphin0520/p/3799052.html
final关键字
修饰类(不可被继承)
当用final修饰一个类时,表明这个类不能被继承。也就是说,如果一个类你永远不会让他被继承,就可以用final进行修饰。final类中的成员变量可以根据需要设为final,但是要注意final类中的所有成员方法都会被隐式地指定为final方法。
修饰方法(不可被覆盖)
用final关键字修饰方法,它表示该方法不能被覆盖。
private和final关键字还有一点联系,这就是类中所有的private方法都隐式地指定为是final的
修饰变量(不可变)
对于一个final变量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;
如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象。引用变量被final修饰之后,虽然不能再指向其他对象,但是它指向的对象的内容是可变的。
public class Test {
public static void main(String[] args) {
String a = "hello2";
final String b = "hello";
String d = "hello";
String c = b + 2;
String e = d + 2;
System.out.println((a == c)); //true
System.out.println((a == e)); //false
}
}
final变量是基本数据类型以及String类型时,如果在编译期间能知道它的确切值,则编译器会把它当做编译期常量使用。也就是说在用到该final变量的地方,相当于直接访问的这个常量,不需要在运行时确定。这种和C语言中的宏替换有点像。因此在上面的一段代码中,由于变量b被final修饰,因此会被当做编译器常量,所以在使用到b的地方会直接将变量b 替换为它的 值。而对于变量d的访问却需要在运行时通过链接来进行。
final和static
static作用于成员变量用来表示只保存一份副本,而final的作用是用来保证变量不可变。
public class Test {
public static void main(String[] args) {
MyClass myClass1 = new MyClass();
MyClass myClass2 = new MyClass();
System.out.println(myClass1.i);
System.out.println(myClass1.j);
System.out.println(myClass2.i);
System.out.println(myClass2.j);
}
}
class MyClass {
public final double i = Math.random();
public static double j = Math.random();
}
运行这段代码就会发现,每次打印的两个j值都是一样的,而i的值却是不同的。从这里就可以知道final和static变量的区别了。
浅析Java中的final关键字
http://www.cnblogs.com/dolphin0520/p/3736238.html
异常
所有异常类型都是内置类Throwable的子类,Throwable下有Exception子类和Error子类。
检查型异常(Checked Exception)
即必须进行处理的异常,如果不处理,程序就不能编译通过。
受检查的异常 = RuntimeException以外的异常
常见的有 IOException、SQLException,以及用户自定义的Exception
非检查型异常(Unchecked Exception)
Java编译器不会检查此类异常,也就是说,当程序中可能出现这类异常,即使没有用try-catch语句捕获它,也没有用throws子句声明抛出它,也会编译通过。 当然,如果要抛出运行时异常并捕捉后自己处理,也是可以的。
常见的有:NullPointerException空指针异常,IndexOutOfBoundsException下标越界等
不可查异常(编译器不要求强制处置的异常):包括运行时异常(RuntimeException与其子类)和错误(Error)。
不受检查的异常 = 运行时异常 + 错误
错误Error和异常Exception的区别
Error类一般是指与虚拟机相关的问题,如系统崩溃,虚拟机错误,内存空间不足,方法调用栈溢出等。
常见的错误有:OutOfMemoryError 内存溢出, StackOverflowError 栈溢出,UnknownError 未知错误, NoSuchMethodError 方法找不到
Error和Exception的区别:
1、Error都是不可被捕获不可处理的,Exception分为受检异常和不受检异常,受检异常可被捕获处理。
2、Error一般是系统级、虚拟机级错误,Exception一般是代码错误。
在Java中错误和异常是有区别的,我们 可以从异常中恢复程序(例如捕获并忽略)并继续执行,但发生 Error 时通常时很严重的系统级错误,程序无法继续执行。
子类覆盖父类方法时对于抛出异常的要求
子类覆盖父类方法时,如有异常,子类中抛出的异常与父类中一致或是其子类型,即子类抛出的异常类型不能比父类抛出的异常类型更宽泛。
如果父类方法抛出多个异常,那么子类在覆盖该方法时,只能抛出父类异常的子集。
如果父类或者接口的方法中没有异常抛出,那么子类在覆盖方法时,也不能抛出异常。
对于构造函数,又有不同:
如果父类的无参构造函数抛出了异常,则子类的无参构造函数不能省略不写,并且必须抛出父类的异常或父类异常的父类,即必须抛出更广泛的异常。
这看似违背了子类抛出的异常类型不能比父类抛出的异常类型更宽泛的原则。但其实并不是这样,因为构造函数没有覆写的概念,只是构造函数间的引用调用而已,即子类的无参构造函数默认调用的是父类的构造函数,所以子类的无参构造函数抛出的异常必须必父类更广泛。
如果是自定义构造函数则没有此限制,因为子类的自定义构造函数并没有调用父类的构造函数。
Throwable/Exception/Error之间是什么关系?
高德一面
所有 Exception 和 Error 都是 Throwable 的子类,注意 Throwable 是个类不是接口。
Java 中的异常分为受检异常和非受检异常:
受检异常 必须在代码中进行 catch 或向上 throw ,常见的比如打开File,IO操作,Socket操作,建立Connection, Session等相关的异常
非受检异常包括 不需要在代码中进行手动处理,包括 运行时异常 和 Error ,常见的运行时异常比如 NPE ,数组下标越界,零除,常见的 Error 比如 OOM, StackOverflowError
异常捕获是如何实现的?(异常表)
在编译生成的 Java 字节码中,每个方法都附带一个异常表。
异常表中的每一行均定义了一条异常执行路径,其中包括规定捕获范围的起始字节码索引、终止(不包含)字节码索引,异常处理代码的起始字节码索引,以及所捕获的异常类型。
当程序触发异常时,JVM 会从上至下遍历异常表中的所有条目。当触发异常的字节码的索引值在某行异常表条目的捕获范围内,JVM 会判断所抛出的异常和该条目想要捕获的异常是否匹配。如果匹配,JVM 会将控制流转移至该条目所指向的异常处理代码。
上述异常捕获机制还被用于 finally 从句的实现。通常,Java 程序的编译器 javac 会复制多份 finally 代码块,放置于生成的 Java 字节码之中,然后通过生成多行异常表条目,来实现完整的 finally 逻辑。
catch 和 finally 执行顺序
1、try-catch-finally 中的 finally 一定会执行,而且,一定优先于 try/catch 中的 return/throw 语句执行,除非系统崩了或者程序使用 System.exit(0) 强行终止
2、finally 中如果有 return 或 throw ,则优先处理 finally 中的 return/throw
3、return 和 throw,从语句流转的角度上看,这两个语句是等效的
4、finally 中没有 return 或 throw,则程序会回溯到 try/catch 中执行 return/throw 语句。如果当初是 catch=>finally ,则回溯到 catch 中执行 return/throw;如果是 try=>finally,则回溯到 try 中执行 return/throw;如果 try/catch 中都不存在 return/throw,则跳出 try-catch-finally 语句体继续执行后续代码
一、当 catch 里有 return 或 throw,finally 体的代码块将在 catch 执行 return 之前被执行。如果 catch 中的 return 是个方法调用,此方法会先于 finally 代码执行,但返回值会等 finally 代码执行完才返回。
1、catch 中 return
// catch 中 return
public String tryCatchReturnFinally() throws Throwable {
try {
int i = 4 / 0;
} catch (Exception e) {
System.out.println("in catch 1");
System.out.println("in catch 2");
return catchMethod();
} finally {
System.out.println("in finally 1");
System.out.println("in finally 2");
}
return "normal result";
}
@Test
public void testTryCatchReturnFinally() {
try {
System.out.println("返回值是: " + tryCatchReturnFinally());
} catch (Throwable throwable) {
throwable.printStackTrace();
}
}
输出:
in catch 1
in catch 2
In catchMethod
in finally 1
in finally 2
返回值是: catchMethod result
2、catch 中 throw
// catch 中 throw
public String tryCatchThrowFinally() throws Throwable {
try {
int i = 4 / 0;
} catch (Exception e) {
System.out.println("in catch 1");
System.out.println("in catch 2");
throw new Throwable("throw from catch");
} finally {
System.out.println("in finally 1");
System.out.println("in finally 2");
}
return "normal result";
}
@Test
public void testTryCatchThrowFinally() {
try {
System.out.println("返回值是: " + tryCatchThrowFinally());
} catch (Throwable throwable) {
throwable.printStackTrace();
}
}
输出:
in catch 1
in catch 2
in finally 1
in finally 2
java.lang.Throwable: throw from catch
at com.masikkk.common.base.ExceptionTest.tryCatchThrowFinally(ExceptionTest.java:75)
二、当 catch 和 finally 同时遇上 return,catch 的 return 返回值将不会被返回,finally 的 return 语句将结束整个方法并返回。如果 catch 中的 return 是个方法,此方法还是会被调用,但返回值会被忽略。
// catch 和 finally 中都有 return
public String tryCatchReturnFinallyReturn() throws Throwable {
try {
int i = 4 / 0;
} catch (Exception e) {
System.out.println("in catch 1");
System.out.println("in catch 2");
return catchMethod(); // 方法会被调用,但返回值被忽略
} finally {
System.out.println("in finally 1");
System.out.println("in finally 2");
return finallyMethod(); // 方法会被调用,返回值是整个方法的return
}
}
输出:
in catch 1
in catch 2
In catchMethod
in finally 1
in finally 2
In finallyMethod
返回值是 finally 中的返回值: finallyMethod result
Object/Runtime/System
java.lang.Object
java.lang.Runtime
java.lang.System
java.lang.Object
hashCode()和equals()方法
等号(==)对基本数据类型和引用类型的不同作用
java中的数据类型,可分为两类:
1、基本数据类型,也称原始数据类型
byte,short,char,int,long,float,double,boolean 他们之间的比较,应用双等号(==),比较的是他们的值。
2、引用类型(类、接口、数组)
当他们用(==)进行比较的时候,比较的是他们在内存中的存放地址,所以,除非是同一个new出来的对象,他们的比较后的结果为true,否则比较后结果为false。
使用==比较Long或Integer等引用类型是常犯的一个错误,一定要改用 equals() 方法
对象是放在堆中的,栈中存放的是对象的引用(地址)。由此可见’==’是对栈中的值进行比较的。如果要比较堆中对象的内容是否相同,那么就要重写equals方法了。
hashCode()和equals()方法在哈希表中的重要作用
当我们向哈希表(如HashSet、HashMap等)中添加对象object时,首先调用hashCode()方法计算object的哈希码,通过哈希码可以直接定位object在哈希表中的位置(一般是哈希码对哈希表大小取余)。如果该位置没有对象,可以直接将object插入该位置;如果该位置有对象(可能有多个,通过链表实现),则调用equals()方法比较这些对象与object是否相等,如果相等,则不需要保存object;如果不相等,则将该对象加入到链表中。
这也就解释了为什么equals()相等,则hashCode()必须相等。如果两个对象equals()相等,则它们在哈希表(如HashSet、HashMap等)中只应该出现一次;如果hashCode()不相等,那么它们会被散列到哈希表的不同位置,哈希表中出现了不止一次。
为什么覆盖equals时总要覆盖hashCode?
一个很常见的错误根源在于没有覆盖hashCode方法。在每个覆盖了equals方法的类中,也必须覆盖hashCode方法。如果不这样做的话,就会违反Object.hashCode的通用约定,从而导致该类无法结合所有基于散列的集合一起正常运作,这样的集合包括HashMap、HashSet和Hashtable。
1.在应用程序的执行期间,只要对象的equals方法的比较操作所用到的信息没有被修改,那么对这同一个对象调用多次,hashCode方法都必须始终如一地返回同一个整数。在同一个应用程序的多次执行过程中,每次执行所返回的整数可以不一致。
2.如果两个对象根据equals()方法比较是相等的,那么调用这两个对象中任意一个对象的hashCode方法都必须产生同样的整数结果。
3.如果两个对象根据equals()方法比较是不相等的,那么调用这两个对象中任意一个对象的hashCode方法,则不一定要产生相同的整数结果。但是程序员应该知道,给不相等的对象产生截然不同的整数结果,有可能提高散列表的性能。
eqauls方法和hashCode方法关系(从HashMap考虑)
Java对于eqauls方法和hashCode方法是这样规定的: (怎么记这个呢,就从两个对象往HashMap里放来考虑,就很容易理解)
(1)同一对象上多次调用hashCode()方法,总是返回相同的整型值。
(2)如果a.equals(b),则一定有a.hashCode() 一定等于 b.hashCode()。 (key相同的肯定得散列到同一个桶中)
(3)如果!a.equals(b),则a.hashCode() 不一定等于 b.hashCode()。此时如果a.hashCode() 总是不等于 b.hashCode(),会提高hashtables的性能。(key不等,也可能散列到同一个桶中,这就是冲突,冲突后往链表上挂)
(4)a.hashCode()==b.hashCode() 则 a.equals(b)可真可假(散列到同一个桶上的key不一定相等,也就是产生了冲突)
(5)a.hashCode()!= b.hashCode() 则 a.equals(b)为假。 (散列到不同桶上的key,肯定不能相等,否则不唯一了)
关于这两个方法的重要规范:
规范1:若重写equals(Object obj)方法,有必要重写hashcode()方法,确保通过equals(Object obj)方法判断结果为true的两个对象具备相等的hashcode()返回值。说得简单点就是:“如果两个对象相同,那么他们的hashcode应该相等”。不过请注意:这个只是规范,如果你非要写一个类让equals(Object obj)返回true而hashcode()返回两个不相等的值,编译和运行都是不会报错的。不过这样违反了Java规范,程序也就埋下了BUG。
规范2:如果equals(Object obj)返回false,即两个对象“不相同”,并不要求对这两个对象调用hashcode()方法得到两个不相同的数。说的简单点就是:“如果两个对象不相同,他们的hashcode可能相同”。
重写的equals()方法应具备的5个特性(自反/对称/传递等)
重写equals()方法需要注意五点:
1 自反性:对任意引用值X,x.equals(x)的返回值一定为true.
2 对称性:对于任何引用值x,y,当且仅当y.equals(x)返回值为true时,x.equals(y)的返回值一定为true;
3 传递性:如果x.equals(y)=true, y.equals(z)=true,则x.equals(z)=true
4 一致性:如果参与比较的对象没任何改变,则对象比较的结果也不应该有任何改变
5 非空性:任何非空的引用值X,x.equals(null)的返回值一定为false
实现高质量equals方法的诀窍
1.使用==符号检查“参数是否为这个对象的引用”。如果是,则返回true。这只不过是一种性能优化,如果比较操作有可能很昂贵,就值得这么做。
2.使用instanceof操作符检查“参数是否为正确的类型”。如果不是,则返回false。一般来说,所谓“正确的类型”是指equals方法所在的那个类。
3.把参数转换成正确的类型。因为转换之前进行过instanceof测试,所以确保会成功。
4.对于该类中的每个“关键”域,检查参数中的域是否与该对象中对应的域相匹配。如果这些测试全部成功,则返回true;否则返回false。
5.当编写完成了equals方法之后,检查“对称性”、“传递性”、“一致性”。
Object提供的原生hashCode()和equals()方法
Java的基类Object提供了一些方法,其中equals()方法用于判断两个对象是否相等,hashCode()方法用于计算对象的哈希码。equals()和hashCode()都不是final方法,都可以被重写(overwrite)。
Object类中equals()方法实现如下:
public boolean equals(Object obj) {
return (this == obj);
}
通过该实现可以看出,Object类的实现采用了区分度最高的算法,即只要两个对象不是同一个对象,那么equals()一定返回false。
Object类中hashCode()方法的声明如下:
public native int hashCode();
可以看出,hashCode()是一个native方法,而且返回值类型是整形;实际上,该native方法将对象在内存中的地址作为哈希码返回,可以保证不同对象的返回值不同。
String类的hashCode()和equals()方法
String类的equals()方法源码:
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
String类的hashcode()方法源码:
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
Integer类的hashCode()和equals()方法
Integer 类的 equals() 方法
public boolean equals(Object obj) {
if (obj instanceof Integer) {
return value == ((Integer)obj).intValue();
}
return false;
}
Integer 类的 hashcode() 方法, 直接返回这个 Integer 代表的整数值
@Override
public int hashCode() {
return Integer.hashCode(value);
}
public static int hashCode(int value) {
return value;
}
详解 equals() 方法和 hashCode() 方法
http://www.importnew.com/25783.html
java中equals,hashcode和==的区别
http://blog.csdn.net/hla199106/article/details/46907725
clone()浅拷贝与深拷贝
new与clone()创建对象的区别
clone() 是浅拷贝
详解Java中的clone方法 – 原型模式
https://blog.csdn.net/zhangjg_blog/article/details/18369201
浅拷贝(复制引用)
Object类有个protected方法:
protected native Object clone() throws CloneNotSupportedException;
因为每个类直接或间接的父类都是Object,因此它们都含有clone()方法,但是因为该方法是protected,所以都不能在类外进行访问。
要想对一个对象进行复制,就需要对clone方法覆盖。
浅复制:
1、 被复制的类需要实现Clonenable接口(不实现的话在调用clone方法会抛出CloneNotSupportedException异常) 该接口为标记接口(不含任何方法)
2、 覆盖clone()方法,访问修饰符设为public。方法中调用super.clone()方法得到需要的复制对象,(native为本地方法)
深拷贝(new对象)
总结:
浅拷贝是指在拷贝对象时,对于基本数据类型的变量会重新复制一份,而对于引用类型的变量只是对引用进行拷贝,没有对引用指向的对象进行拷贝。
而深拷贝是指在拷贝对象时,同时会对引用指向的对象进行拷贝。
区别就在于是否对 对象中的引用变量所指向的对象进行拷贝。
浅谈Java中的深拷贝和浅拷贝(转载)
http://www.cnblogs.com/dolphin0520/p/3700693.html
详解Java中的clone方法 – 原型模式
https://blog.csdn.net/zhangjg_blog/article/details/18369201
Spring BeanUtils.copyProperties() 是浅拷贝
MapStruct mapper 是深拷贝
内部对每个子对象都 new
java.lang.Runtime
Runtime,顾名思义,即运行时,表示当前进程所在的虚拟机实例。
每一个JAVA程序实际上都是启动了一个JVM进程,每一个JVM进程都对应一个Runtime实例
Runtime是单例的(饿汉模式)
由于任何进程只会运行于一个虚拟机实例当中,所以在 Runtime 中采用了单例模式,即只会产生一个虚拟机实例:
public class Runtime {
private static Runtime currentRuntime = new Runtime();
public static Runtime getRuntime() {
return currentRuntime;
}
/** Don't let anyone else instantiate this class */
private Runtime() {}
...
}
由于 Runtime 类的构造器是 private 的,所以只有通过 getRuntime 去获取 Runtime 的实例。
获取当前Jvm的内存信息、CPU数量
/*
* 获取当前jvm的内存信息,返回的值是 字节为单位
* */
public static void getFreeMemory() {
//获取可用内存
long value = Runtime.getRuntime().freeMemory();
System.out.println("可用内存为:"+value/1024/1024+"mb");
//获取jvm的总数量,该值会不断的变化
long totalMemory = Runtime.getRuntime().totalMemory();
System.out.println("全部内存为:"+totalMemory/1024/1024+"mb");
//获取jvm 可以最大使用的内存数量,如果没有被限制 返回 Long.MAX_VALUE;
long maxMemory = Runtime.getRuntime().maxMemory();
System.out.println("可用最大内存为:"+maxMemory/1024/1024+"mb");
}
“CPU个数:”+Runtime.getRuntime().availableProcessors();
Java-Runtime 类
https://www.cnblogs.com/slyfox/p/7272048.html
手动垃圾回收Runtime.getRuntime().gc()
public class RuntimeDemo01{
public static void main(String[] args){
Runtime run = Runtime.getRuntime(); //通过Runtime类的静态方法获取Runtime类的实例
System.out.println("JVM最大内存量:"+run.maxMemory());
System.out.println("JVM空闲内存量:"+run.freeMemory());
String str = "Hello"+"World";
System.out.println(str);
for(int i=0;i<2000;i++){
str = str + i;
}
System.out.println("操作String之后的JVM空闲内存量:"+run.freeMemory());
run.gc();
System.out.println("垃圾回收之后的JVM空闲内存量:"+run.freeMemory());
}
}
java中Runtime类总结
http://blog.csdn.net/tomcmd/article/details/48971051
Java中如何创建进程执行系统命令
在Java中,可以通过两种方式来创建进程,总共涉及到5个主要的类。
第一种方式是通过 Runtime.exec() 方法来创建一个进程,
第二种方法是通过 ProcessBuilder 的 start 方法来创建进程。
ProcessBuilder.start()创建进程
下面看一下具体使用ProcessBuilder创建进程的例子,比如我要通过ProcessBuilder来启动一个进程打开cmd,并获取ip地址信息,那么可以这么写:
public class Test {
public static void main(String[] args) throws IOException {
ProcessBuilder pb = new ProcessBuilder("cmd","/c","ipconfig/all");
Process process = pb.start();
Scanner scanner = new Scanner(process.getInputStream());
while(scanner.hasNextLine()){
System.out.println(scanner.nextLine());
}
scanner.close();
}
}
Runtime.exec()创建进程
首先还是来看一下Runtime类的exec方法的具体实现
public Process exec(String[] cmdarray, String[] envp, File dir)
throws IOException {
return new ProcessBuilder(cmdarray)
.environment(envp)
.directory(dir)
.start();
}
可以发现,事实上通过Runtime类的exec创建进程的话,最终还是通过ProcessBuilder类的start方法来创建的。
Java并发编程:如何创建线程? - 海子
http://www.cnblogs.com/dolphin0520/p/3913517.html
java.lang.System
System类是jdk提供的一个工具类,有final修饰,不可继承,由名字可以看出来,其中的操作多数和系统相关。其功能主要如下:
- 标准输入输出,如out、in、err
- 外部定义的属性和环境变量的访问,如getenv()/setenv()和getProperties()/setProperties()
- 加载文件和类库的方法,如load()和loadLibrary()、
- 一个快速拷贝数组的方法:arraycopy()
- 一些jvm操作,如gc()、runFinalization()、exit(),该部分并未在源码的java doc中提到,可能因为本身不建议主动调用吧。而且这几个方法都仅仅是Runtime.getRuntime()的调用,两者没有区别
System的初始化
在System类开头可以看如下代码:
public final class System {
/* register the natives via the static initializer.
*
* VM will invoke the initializeSystemClass method to complete
* the initialization for this class separated from clinit.
* Note that to use properties set by the VM, see the constraints
* described in the initializeSystemClass method.
*/
private static native void registerNatives();
static {
registerNatives();
}
...
}
静态代码块调用了一个native方法registerNatives(),是用c实现的,我们看不到,但是注释说了:“VM will invoke the initializeSystemClass method to complete the initialization for this class separated from clinit”该方法会令vm通过调用initializeSystemClass方法来完成初始化工作。
initializeSystemClass()源码如下:
private static void initializeSystemClass() {
// 初始化props
props = new Properties();
initProperties(props);
sun.misc.VM.saveAndRemoveProperties(props);
//获取系统相关的换行符
lineSeparator = props.getProperty("line.separator");
sun.misc.Version.init();
//分别创建in、out、err的实例对象,并通过setXX0()初始化,查看setXX0()方法可知,这是个native方法,将系统的标准流管理到类内的对象
FileInputStream fdIn = new FileInputStream(FileDescriptor.in);
FileOutputStream fdOut = new FileOutputStream(FileDescriptor.out);
FileOutputStream fdErr = new FileOutputStream(FileDescriptor.err);
setIn0(new BufferedInputStream(fdIn));
setOut0(new PrintStream(new BufferedOutputStream(fdOut, 128), true));
setErr0(new PrintStream(new BufferedOutputStream(fdErr, 128), true));
//加载zip包以获取java.util.zip.ZipFile这个类,以便之后加载利库使用
loadLibrary("zip");
// 设置平台相关的信号处理
Terminator.setup();
// 初始化sun.misc相关的环境变量
sun.misc.VM.initializeOSEnvironment();
// 主线程不会在同一个线程组中添加相同的线程,我们必须在这里自己实现。注释半天没弄明白,看代码就是主线程自己把自己加到了自己的线程组中......
Thread current = Thread.currentThread();
current.getThreadGroup().add(current);
// 注册共享秘钥?注释没看明白,该方法就是实例化一个JavaLangAccess
setJavaLangAccess();
// 子系统在初始化的时候可以调用sun.misc.VM.isBooted(),以保证在application类加载器启动前不做任何事。booted()其实就是改了个状态,使isBooted()变为true。
sun.misc.VM.booted();
}
这个方法的大概意思是说:1.初始化Properties 2.初始化输入、输出、错误流 3.进行一大堆配置。
重设标准输入/输出/错误流
可以注意initializeSystemClass()方法中的几行,setIn0,setOut0,setErr0这三个方法。这三个方法是System中public方法setIn,setOut,setErr内部调用的子方法。
我们可以用这几个方法来设置这三个流。
public static void setIn(InputStream in) {
checkIO();
setIn0(in);
}
比如这是setIn方法,我们使用这个方法来设置输入流(此方法被使用的频率不是很高)。checkIO是检查IO流是否正确,setIn0是native方法,做真正的输入流替换工作。
System.out是内部类还是变量?
System.out是System类的成员变量,源码如下:
public final static InputStream in = null;
public final static PrintStream out = null;
public final static PrintStream err = null;
在initializeSystemClass()方法中被初始化:
//分别创建in、out、err的实例对象,并通过setXX0()初始化,查看setXX0()方法可知,这是个native方法,将系统的标准流管理到类内的对象
FileInputStream fdIn = new FileInputStream(FileDescriptor.in);
FileOutputStream fdOut = new FileOutputStream(FileDescriptor.out);
FileOutputStream fdErr = new FileOutputStream(FileDescriptor.err);
setIn0(new BufferedInputStream(fdIn));
setOut0(new PrintStream(new BufferedOutputStream(fdOut, 128), true));
setErr0(new PrintStream(new BufferedOutputStream(fdErr, 128), true));
我们也可以调用setIn,setOut,setErr重设这些流对象
十分钟速懂java知识点 System类
http://www.jb51.net/article/76305.htm
java——深度解析System系统类
http://blog.csdn.net/quinnnorris/article/details/71077893?utm_source=gold_browser_extension
System.getProperty()获取配置参数
比如在启动java程序时指定如下VM参数:
-Dspring.profiles.active=test -Dmodule.xxx.switch=false -Dmodule.yyy.switch=true
可通过如下代码获取这些变量的值
String profile = System.getProperties().getProperty("spring.profiles.active");
String moduleXSwitch = System.getProperties().getProperty("module.xxx.switch");
String moduleYSwitch = System.getProperties().getProperty("module.yyy.switch");
logger.info("spring.profiles.active: {}", profile);
logger.info("module.xxx.switch: {}", moduleXSwitch);
logger.info("module.yyy.switch: {}", moduleYSwitch);
获取jvm参数(JMX)
JDK提供java.lang.management包, 其实就是基于JMX技术规范,提供一套完整的MBean,动态获取JVM的运行时数据,达到监控JVM性能的目的。
java动态获取jvm参数
http://blog.csdn.net/liudezhicsdn/article/details/51058504
System.getEnv()获取环境变量
System.getEnv() 得到所有的环境变量
System.getEnv(key) 得到某个环境变量的值
System.lineSeparator() 获取换行符
windows下的文本文件换行符:\r\n
linux/unix下的文本文件换行符:\r
Mac下的文本文件换行符:\n
Java 中可以根据该方法(System.lineSeparator())来判断,jdk必须在1.7以上;
String line = System.lineSeparator();
随机数
Math.random()
Math.random() 函数能够返回带正号的double值,取值范围是[0.0,1.0),在该范围内(近似)均匀分布。
如果我们想获取一个 1000 以内的随机数,可以int random = (int)(Math.random() * 1000);
因为返回值是double类型的,小数点后面可以保留15位小数,所以产生相同的可能性非常小,在这一定程度上是随机数。
Math.random() 内部其实是通过 Random 类实现的,Math 内部维护了一个 Random 类的单例
private static final class RandomNumberGeneratorHolder {
static final Random randomNumberGenerator = new Random();
}
public static double random() {
return RandomNumberGeneratorHolder.randomNumberGenerator.nextDouble();
}
弱伪随机数Random
弱伪随机数实现PRNG java.util.Random 类,默认使用当前时间作为种子,并且采用 线性同余法 计算下一个随机数。
@Test
public void testRandom() {
// 10000作为seed,默认使用当前时间作为seed
Random r = new Random(10000);
for (int i = 0; i < 5; ++i) {
System.out.println(r.nextInt());
}
}
以上这段代码,无论你怎么跑都会打印出以下结果:
-498702880
-858606152
1942818232
-1044940345
1588429001
即:
同一个种子,生成N个随机数,当你设定种子的时候,这N个随机数是什么已经确定。相同次数生成的随机数字是完全相同的。
如果用相同的种子创建两个 Random 实例, 如上面的r3,r4,则对每个实例进行相同的方法调用序列,它们将生成并返回相同的数字序列。
ThreadLocalRandom
ThreadLocalRandom 是 JDK 7 之后提供,继承了 java.util.Random
每一个线程有一个独立的随机数生成器,用于并发产生随机数,能够解决多个线程发生的竞争争夺。效率更高!
强伪随机数SecureRandom
强伪随机数RNG实现 java.security.SecureRandom 类
SecureRandom和Random都是,也是如果种子一样,产生的随机数也一样: 因为种子确定,随机数算法也确定,因此输出是确定的。
只是说,SecureRandom类收集了一些随机事件,比如鼠标点击,键盘点击等等,SecureRandom 使用这些随机事件作为种子。这意味着,种子是不可预测的,而不像Random默认使用系统当前时间的毫秒数作为种子,有规律可寻。
SecureRandom 提供加密的强随机数生成器 (RNG),要求种子必须是不可预知的,产生非确定性输出。
每次产生的随机数不同
@Test
public void testSecureRandom() {
SecureRandom secureRandom1 = new SecureRandom();
SecureRandom secureRandom2 = new SecureRandom();
for (int i = 0; i < 5; i++) {
System.out.println(secureRandom1.nextInt() + " " + secureRandom2.nextInt());
}
for (int i = 0; i < 5; i++) {
System.out.println((int)(secureRandom1.nextDouble() * 1000) + " " + (int)(secureRandom2.nextDouble() * 1000));
}
}
种子的作用是什么?
根据种子使用 先行同余算法 计算出一个序列,种子定了,这个序列也就定了。
所以
无参数构造方法(不设置种子)具有更强的随机性,能够满足一般统计上的随机数要求。使用有参的构造方法(设置种子)无论你生成多少次,每次生成的随机序列都相同,名副其实的伪随机
为什么java中的随机数是伪随机数?
伪随机数是看似随机实质是固定的周期性序列, 也就是有规则的随机。
只要这个随机数是由确定算法生成的,那就是伪随机,只能通过不断算法优化,使你的随机数更接近随机。
同一个种子,生成N个随机数,当你设定种子的时候,这N个随机数是什么已经确定。相同次数生成的随机数字是完全相同的。
Java JNI
JNI,是Java Native Interface的简称,中文是“Java本地调用”。通过这种技术可以做到以下两点:
- Java程序中的函数可以调用Native语言写的函数,Native一般指的是C/C++编写的函数。
- Native程序中的函数可以调用Java层的函数,也就是说在C/C++程序中可以调用Java的函数。
java中调用c/c++代码
最简单的Java调用C/C++代码,有以下步骤:
1、java类中编写带有native 声明的方法。
2、使用 javac 命令编译所编写的java类。
3、使用 javah 命令生成C/C++头文件,javah -jni HelloWorld
4、按照生成的C/C++头文件来编写C/C++源文件,实现native方法
5、将C/C++源文件编译成动态链接库(DLL),将DLL文件加入到PATH环境变量下。
6、Java类中加载DLL,static{System.loadLibrary("hello");//载入本地库},然后调用声明方法
native关键字
简单地讲,一个Native Method就是一个java调用非java代码的接口。
在定义一个native method时,并不提供实现体(有些像定义一个java interface),因为其实现体是由非java语言在外面实现的。
如果一个含有本地方法的类被继承,子类会继承这个本地方法并且可以用java语言重写这个方法(这个似乎看起来有些奇怪),同样的如果一个本地方法被fianl标识,它被继承后不能被重写。
本地方法非常有用,因为它有效地扩充了jvm.事实上,我们所写的java代码已经用到了本地方法,在sun的java的并发(多线程)的机制实现中,许多与操作系统的接触点都用到了本地方法,这使得java程序能够超越java运行时的界限。有了本地方法,java程序可以做任何应用层次的任务。
举几个native方法的例子
Object类中的求hashcode,wait,notify,getClass等的方法:
public native int hashCode();
public final native void wait(long timeout) throws InterruptedException;
public final native Class<?> getClass();
protected native Object clone() throws CloneNotSupportedException;
public final native void notify();
Runtime类中获取系统参数的方法
public native int availableProcessors();
public native long freeMemory();
public native long totalMemory();
public native long maxMemory();
Java的native方法
http://blog.csdn.net/lingjunqi/article/details/50032109
java中native的用法
https://www.cnblogs.com/b3051/p/7484501.html
Java Jni入门(一):Hello Jni(在Java中调用C库函数)
http://blog.csdn.net/afunx/article/details/53447563
Java Native Interface(JNI)从零开始详细教程
http://blog.csdn.net/createchance/article/details/53783490
Java 反射
具体参考 Java-反射
通俗来讲就是根据给出的类名(字符串方式)来动态地生成对象。
反射允许程序在运行时(注意不是编译的时候)来进行自我检查并且对内部的成员进行操作。例如它允许一个java的类获取它所有的成员变量和方法并且显示出来。
获取Class对象的三种方法
Java中,无论生成某个类的多少个对象,这些对象都会对应于同一个Class对象。 要想使用反射,首先需要获得待处理类或对象所对应的Class对象。
获取某个类或某个对象所对应的Class对象的常用的3种方式:
- 使用Class类的静态方法forName
Class.forName(“java.lang.String”); - 使用每个类都有的.class属性
String.class; - 使用每个对象都有的getClass()方法
在java.lang.Object类中定义了getClass()方法,因此对于任意一个Java对象,都可以通过此方法获得对象的类型。String s = “aa”; Class<?> clazz = s.getClass();
AccessibleObject类
AccessibleObject 类是 Field、Method 和 Constructor 对象的基类。它提供了将反射的对象标记为在使用时取消默认 Java 语言访问控制检查的能力。对于公共成员、默认(打包)访问成员、受保护成员和私有成员,在分别使用 Field、Method 或 Constructor 对象来设置或获取字段、调用方法,或者创建和初始化类的新实例的时候,会执行访问检查。
在反射对象中设置 accessible 标志允许具有足够特权的复杂应用程序(比如 Java Object Serialization 或其他持久性机制)以某种通常禁止使用的方式来操作对象。
如何在类外访问类的私有方法/成员/构造方法?
通过public Constructor<T> getDeclaredConstructor(Class<?>... parameterTypes)
返回指定的private构造方法
public void setAccessible(boolean flag)
将此对象的 accessible 标志设置为指示的布尔值。值为 true 则指示反射的对象在使用时应该取消 Java 语言访问检查。值为 false 则指示反射的对象应该实施 Java 语言访问检查。
java反射之使用Constructor调用私有构造函数
http://gaoquanyang.iteye.com/blog/1160561
Java反射机制调用private类型的构造方法
https://www.cnblogs.com/yinxiaoqiexuxing/p/5605513.html
java 代理
代理提供了对目标对象另外的访问方式;即通过代理对象访问目标对象.这样做的好处是:可以在目标对象实现的基础上,增强额外的功能操作,即扩展目标对象的功能
1、代理对象存在的价值主要用于拦截对真实业务对象的访问。
2、代理对象应该具有和目标对象(真实业务对象)相同的方法。
静态代理
静态代理在使用时,需要定义接口或者父类,被代理对象与代理对象一起实现相同的接口或者是继承相同父类
代理类中包含一个目标对象,然后通过调用相同的方法来调用目标对象的方法
可以做到在不修改目标对象的功能前提下,对目标功能扩展
缺点:每个目标类都要有个代理类,一旦接口增加方法,目标对象与代理对象都要维护.
JDK动态代理
利用JDK的API,动态的在内存中构建代理对象
java在JDK1.5之后提供了一个”java.lang.reflect.Proxy”类,通过”Proxy”类提供的一个newProxyInstance方法用来创建一个对象的代理对象static Object newProxyInstance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler h)
newProxyInstance方法用来返回一个代理对象,这个方法总共有3个参数,
- ClassLoader loader指定当前目标对象使用类加载器,获取加载器的方法是固定的
- Class<?>[] interfaces用来指明生成哪个对象的代理对象,通过接口指定
- InvocationHandler h,事件处理,执行目标对象的方法时,会触发事件处理器的方法,会把当前执行目标对象的方法作为参数传入
代理对象不需要实现接口,但是目标对象一定要实现接口,否则不能用动态代理
Cglib动态代理
上面的静态代理和动态代理模式都是要求目标对象是实现一个接口的目标对象,但是有时候目标对象只是一个单独的对象,并没有实现任何的接口,这个时候就可以使用以目标对象子类的方式类实现代理,这种方法就叫做:Cglib代理
Cglib代理,也叫作子类代理,它是在内存中构建一个子类对象从而实现对目标对象功能的扩展.
- JDK的动态代理有一个限制,就是使用动态代理的对象必须实现一个或多个接口,如果想代理没有实现接口的类,就可以使用Cglib实现.
- Cglib是一个强大的高性能的代码生成包,它可以在运行期扩展java类与实现java接口.它广泛的被许多AOP的框架使用,例如Spring AOP和synaop,为他们提供方法的interception(拦截)
- Cglib包的底层是通过使用一个小而块的字节码处理框架ASM来转换字节码并生成新的类.不鼓励直接使用ASM,因为它要求你必须对JVM内部结构包括class文件的格式和指令集都很熟悉.
java 注解
注解(Annotation),一种代码级别的说明。它是JDK1.5及以后版本引入的一个特性,与类、接口、枚举是在同一个层次。它可以声明在包、类、字段、方法、局部变量、方法参数等的前面,用来对这些元素进行说明。
注解的作用
主要的作用有以下四方面:
1、生成文档,通过代码里标识的元数据生成javadoc文档。
2、编译检查,通过代码里标识的元数据让编译器在编译期间进行检查验证。
3、编译时动态处理,编译时通过代码里标识的元数据动态处理,例如动态生成代码。
4、运行时动态处理,运行时通过代码里标识的元数据动态处理,例如使用反射注入实例。
三种内置注解
- @Override:用于修饰此方法覆盖了父类的方法;
- @Deprecated:用于修饰已经过时的方法;
- @SuppressWarnnings:用于通知java编译器禁止特定的编译警告。
自定义注解
元注解
java.lang.annotation提供了四种元注解,专门注解其他的注解:
@Documented –注解是否将包含在JavaDoc中
@Retention –什么时候使用该注解
@Target –注解用于什么地方
@Inherited – 是否允许子类继承该注解
注解有哪几种生命周期?(@Retention)
@Retention表示需要在什么级别保存该注释信息,用于描述注解的生命周期(即:被描述的注解在什么范围内有效)
取值(RetentionPoicy)有:
1、RetentionPolicy.SOURCE:在源文件中有效(即源文件保留),在编译阶段丢弃。这些注解在编译结束之后就不再有任何意义,所以它们不会写入字节码。@Override, @SuppressWarnings都属于这类注解。
2、RetentionPolicy.CLASS:在class文件中有效(即class保留),编译器将把注释记录在类文件中,但在运行时 VM 不需要保留注释。在类加载的时候丢弃。在字节码文件的处理中有用。注解默认使用这种方式
3、RetentionPolicy.RUNTIME:在运行时有效(即运行时保留),编译器将把注释记录在类文件中,在运行时 VM 将保留注释,因此可以反射性地读取。 始终不会丢弃,运行期也保留该注解,因此可以使用反射机制读取该注解的信息。我们自定义的注解通常使用这种方式。
Java学习之注解Annotation实现原理
http://www.cnblogs.com/whoislcj/p/5671622.html
自定义注解示例
使用@interface自定义注解
下面实现这样一个注解:通过@Test向某类注入一个字符串,通过@TestMethod向某个方法注入一个字符串。
自定义注解示例:
1、创建@Test注解,声明作用于类并保留到运行时,默认值为default。
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface Test {
String value() default "default";
}
2、创建@TestMethod注解,声明作用于方法并保留到运行时。
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
public @interface TestMethod {
String value();
}
3、测试类,运行后输出default和tomcat-method两个字符串,因为@Test没有传入值,所以输出了默认值,而@TestMethod则输出了注入的字符串。
@Test()
public class AnnotationTest {
@TestMethod("tomcat-method")
public void test(){
}
public static void main(String[] args){
Test t = AnnotationTest.class.getAnnotation(Test.class);
System.out.println(t.value());
TestMethod tm = null;
try {
tm = AnnotationTest.class.getDeclaredMethod("test",null).getAnnotation(TestMethod.class);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(tm.value());
}
}
编译后注解放在那里?()
从java源码到class字节码是由编译器完成的,编译器会对java源码进行解析并生成class文件,而注解也是在编译时由编译器进行处理,编译器会对注解符号处理并附加到class结构中,根据jvm规范,class文件结构是严格有序的格式,唯一可以附加信息到class结构中的方式就是保存到class结构的attributes属性中。我们知道对于类、字段、方法,在class结构中都有自己特定的表结构,而且各自都有自己的属性,而对于注解,作用的范围也可以不同,可以作用在类上,也可以作用在字段或方法上,这时编译器会对应将注解信息存放到类、字段、方法自己的属性上。
注解如何生效?
Annotation 是被动的元数据,永远不会有主动行为,但凡Annotation起作用的场合都是有一个执行机制/调用者通过反射获得了这个元数据然后根据它采取行动。
注解的实现原理(反射+代理)
java中的注解是一种继承自接口java.lang.annotation.Annotation的特殊接口。
注解被编译后的本质就是一个继承Annotation接口的接口,所以@Test其实就是“public interface Test extends Annotation”,当我们通过AnnotationTest.class.getAnnotation(Test.class)调用时,JDK会通过动态代理生成一个实现了Test接口的对象,并把将RuntimeVisibleAnnotations属性值设置进此对象中,此对象即为Test注解对象,通过它的value()方法就可以获取到注解值。
注解本质是一个继承了Annotation的特殊接口,其具体实现类是Java运行时生成的动态代理类。而我们通过反射获取注解时,返回的是Java运行时生成的动态代理对象$Proxy1。通过代理对象调用自定义注解(接口)的方法,会最终调用AnnotationInvocationHandler的invoke方法。该方法会从memberValues这个Map中索引出对应的值。而memberValues的来源是Java常量池。
注解机制及其原理
https://blog.csdn.net/wangyangzhizhou/article/details/51698638
注解Annotation实现原理与自定义注解例子
https://www.cnblogs.com/acm-bingzi/p/javaAnnotation.html
Java NIO
随笔分类 - Java NIO
http://www.cnblogs.com/xiaoxi/category/961993.html
Linux 5 种IO模型
参考 面试准备12-计算机基础
NIO概述
Java NIO 实际上就是多路复用 IO, 并不是异步IO
NIO采用内存映射文件的方式来处理输入输出,NIO将文件或文件的一段区域映射到内存中,这样就可以像访问内存一样访问文件了。
原来的 I/O 库(在 java.io.*中) 与 NIO 最重要的区别是数据打包和传输的方式。正如前面提到的,原来的 I/O 以流的方式处理数据,而 NIO 以块的方式处理数据。
IO 是面向流的,NIO 是面向缓冲区的
Java IO 的各种流是阻塞的,Java NIO 是非阻塞模式
NIO 主要有三大核心部分:Channel(通道),Buffer(缓冲区), Selector。传统IO基于字节流和字符流进行操作,而NIO基于Channel和Buffer(缓冲区)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。Selector(选择器)用于监听多个通道的事件(比如:连接打开,数据到达)。
Buffer 缓冲区
缓冲区实际上是一个容器对象,更直接的说,其实就是一个数组,在 NIO 库中,所有数据都是用缓冲区处理的。在读取数据时,它是直接读到缓冲区中的;在写入数据时,它也是写入到缓冲区中的;任何时候访问 NIO 中的数据,都是将它放到缓冲区中。而在面向流I/O系统中,所有数据都是直接写入或者直接将数据读取到Stream对象中。
在缓冲区中,最重要的属性有下面三个,它们一起合作完成对缓冲区内部状态的变化跟踪:
- position:指定了下一个将要被写入或者读取的元素索引,它的值由 get()/put() 方法自动更新,在新创建一个 Buffer 对象时,position 被初始化为0。
- limit:指定还有多少数据需要取出(在从缓冲区写入通道时),或者还有多少空间可以放入数据(在从通道读入缓冲区时)。
- capacity:指定了可以存储在缓冲区中的最大数据容量,实际上,它指定了底层数组的大小,或者至少是指定了准许我们使用的底层数组的容量。
以上四个属性值之间有一些相对大小的关系:0 <= position <= limit <= capacity。
Channel 通道
通道是双向的,通过一个 Channel 既可以进行读,也可以进行写;而 Stream 只能进行单向操作,通过一个 Stream 只能进行读或者写,比如 InputStream 只能进行读取操作,OutputStream 只能进行写操作;
通道是一个对象,通过它可以读取和写入数据,当然了所有数据都通过 Buffer 对象来处理。我们永远不会将字节直接写入通道中,相反是将数据写入包含一个或者多个字节的缓冲区。同样不会直接从通道中读取字节,而是将数据从通道读入缓冲区,再从缓冲区获取这个字节。
所有的 Channel 都不是通过构造器创建的,而是通过传统的节点 InputStream, OutputStream 的 getChannel 方法来返回响应的 Channel。
使用 NIO 读取数据可以分为下面三个步骤:
1、从 FileInputStream 获取 Channel
2、创建 Buffer
3、将数据从 Channel 读取到 Buffer 中
Selector 选择器
Selector 类是 NIO 的核心类,Selector 能够检测多个注册的通道上是否有事件发生,如果有事件发生,便获取事件然后针对每个事件进行相应的响应处理。这样一来,只是用一个单线程就可以管理多个通道,也就是管理多个连接。这样使得只有在连接真正有读写事件发生时,才会调用函数来进行读写,就大大地减少了系统开销,并且不必为每个连接都创建一个线程,不用去维护多个线程,并且避免了多线程之间的上下文切换导致的开销。
一个 Selector 实例可以同时检查一组信道的 I/O 状态。用专业术语来说,选择器就是一个多路开关选择器,因为一个选择器能够管理多个信道上的 I/O 操作。
Selector 内部可以同时管理多个 I/O,当一个信道有 I/O 操作的时候,他会通知 Selector,Selector 就是记住这个信道有 I/O 操作,并且知道是何种 I/O 操作,是读呢?是写呢?还是接受新的连接;所以如果使用 Selector,它返回的结果只有两种结果,一种是0,即在你调用的时刻没有任何客户端需要 I/O 操作,另一种结果是一组需要 I/O 操作的客户端,这是你就根本不需要再检查了,因为它返回给你的肯定是你想要的。
攻破JAVA NIO技术壁垒
http://blog.csdn.net/u013256816/article/details/51457215
Netty
官方那个给出的介绍是:Netty是由JBOSS提供的一个java开源框架。Netty提供异步的、事件驱动的网络应用程序框架和工具,用以快速开发高性能、高可靠性的网络服务器和客户端程序。
然后我们简单理解一下,这玩意就是个程序,干什么的?netty是封装java socket nio的。 类似的功能是 apache的mina。
相对于Tomcat这种Web Server(顾名思义主要是提供Web协议相关的服务的),Netty是一个Network Server,是处于Web Server更下层的网络框架,也就是说你可以使用Netty模仿Tomcat做一个提供HTTP服务的Web容器。
说白了,就是一个好使的处理Socket的东西。
Netty入门(一):零基础“HelloWorld”详细图文步骤
https://www.cnblogs.com/applerosa/p/7141684.html
java 序列化
序列化,简单地说,就是可以将一个对象(标志对象的类型)及其状态转换为字节码,保存起来(可以保存在数据库,内存,文件等),然后可以在适当的时候再将其状态恢复(也就是反序列化)
为什么需要序列化?
第一种情况是:一般情况下Java对象的声明周期都比Java虚拟机的要短,实际应用中我们希望在JVM停止运行之后能够持久化指定的对象,这时候就需要把对象进行序列化之后保存。
第二种情况是:需要把Java对象通过网络进行传输的时候。因为数据只能够以二进制的形式在网络中进行传输,因此当把对象通过网络发送出去之前需要先序列化成二进制数据,在接收端读到二进制数据之后反序列化成Java对象。
如何序列化?
a) 写入
首先创建一个OutputStream输出流;
然后创建一个ObjectOutputStream输出流,并传入OutputStream输出流对象;
最后调用ObjectOutputStream对象的writeObject()方法将对象状态信息写入OutputStream。
b)读取
首先创建一个InputStream输入流;
然后创建一个ObjectInputStream输入流,并传入InputStream输入流对象;
最后调用ObjectInputStream对象的readObject()方法从InputStream中读取对象状态信息。
例如:
public static void main(String[] args) {
Box myBox = new Box();
myBox.setWidth(50);
myBox.setHeight(30);
try {
FileOutputStream fs=new FileOutputStream("F:\\foo.ser");
ObjectOutputStream os=new ObjectOutputStream(fs);
os.writeObject(myBox);
os.close();
FileInputStream fi=new FileInputStream("F:\\foo.ser");
ObjectInputStream oi=new ObjectInputStream(fi);
Box box=(Box)oi.readObject();
oi.close();
System.out.println(box.height+","+box.width);
} catch (Exception e) {
e.printStackTrace();
}
}
java ArrayList的序列化分析
https://www.cnblogs.com/vinozly/p/5171227.html
serialVersionUID 有什么用
简单来说,Java的序列化机制是通过在运行时判断类的serialVersionUID来验证版本一致性的。
在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体(类)的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常。
有两种生成方式:
一个是默认的1L,比如: private static final long serialVersionUID = 1L;
一个是根据类名、接口名、成员方法及属性等来生成一个64位的哈希字段,比如:private static final long serialVersionUID = 3801124242820219131L;
当实现java.io.Serializable接口的实体(类)没有显式地定义一个名为serialVersionUID,类型为long的变量时,Java序列化机制会根据编译的class自动生成一个serialVersionUID作序列化版本比较用,这种情况下,只有同一次编译生成的class才会生成相同的serialVersionUID ,并不稳定,这样就可能在不同JVM环境下出现反序列化时报InvalidClassException异常。
如果我们不希望通过编译来强制划分软件版本,即实现序列化接口的实体能够兼容先前版本,未作更改的类,就需要显式地定义一个名为serialVersionUID,类型为long的变量,不修改这个变量值的序列化实体都可以相互进行串行化和反串行化。
如何使一个类可以被序列化
实现Serializable接口可被默认序列化
如果仅仅只是让某个类实现Serializable接口,而没有其它任何处理的话,则就是使用默认序列化机制。使用默认机制,在序列化对象时,不仅会序列化当前对象本身,还会对该对象引用的其它对象也进行序列化,同样地,这些其它对象引用的另外对象也将被序列化,以此类推。所以,如果一个对象包含的成员变量是容器类对象,而这些容器所含有的元素也是容器类对象,那么这个序列化的过程就会较复杂,开销也较大。
为什么实现了Serializable接口就能被序列化?
为什么一个类实现了Serializable接口,它就可以被序列化呢?
在上节的示例中,使用ObjectOutputStream类的writeObject(Object obj)方法来持久化对象,该方法会调用writeObject0(Object obj, boolean unshared),writeObject0源码如下:
private void writeObject0(Object obj, boolean unshared) throws IOException {
...
if (obj instanceof String) {
writeString((String) obj, unshared);
} else if (cl.isArray()) {
writeArray(obj, desc, unshared);
} else if (obj instanceof Enum) {
writeEnum((Enum) obj, desc, unshared);
} else if (obj instanceof Serializable) {
writeOrdinaryObject(obj, desc, unshared);
} else {
if (extendedDebugInfo) {
throw new NotSerializableException(cl.getName() + "\n"
+ debugInfoStack.toString());
} else {
throw new NotSerializableException(cl.getName());
}
}
...
}
从上述代码可知,如果被写对象的类型是String,或数组,或Enum,或Serializable接口的实例,那么就可以对该对象进行序列化,否则将抛出NotSerializableException。
这就是为什么实现了Serializable接口就能被序列化。
这里还可以解释一个问题:Serializbale接口是个空的接口,并没有定义任何方法,为什么需要序列化的接口只要实现Serializbale接口就能够进行序列化。
答案是:Serializable接口这是一个标识,告诉程序所有实现了”我”的对象都需要进行序列化。
深入理解Java对象序列化
http://developer.51cto.com/art/201202/317181.htm
实现Externalizable接口自定义序列化
Externalizable继承于Serializable,当使用该接口时,序列化的细节需要由程序员去完成。如上所示的代码,由于writeExternal()与readExternal()方法未作任何处理,那么该序列化行为将不会保存/读取任何一个字段。这也就是为什么输出结果中所有字段的值均为空。
另外,使用Externalizable进行序列化时,当读取对象时,会调用被序列化类的无参构造器去创建一个新的对象,然后再将被保存对象的字段的值分别填充到新对象中。这就是为什么在此次序列化过程中Person类的无参构造器会被调用。由于这个原因,实现Externalizable接口的类必须要提供一个无参的构造器,且它的访问权限为public。
Serializable接口和Externalizable接口对比
我们知道在Java中,对象的序列化可以通过实现两种接口来实现:
- 若实现的是Serializable接口,则所有的序列化将会自动进行
- 若实现的是Externalizable接口,则没有任何东西可以自动序列化,需要在writeExternal方法中进行手工指定所要序列化的变量,这与是否被 transient 修饰无关。Externalizable 接口定义了两个方法,writerExternal方法在序列化时被调用,可以再该方法中控制序列化内容,readExternal方法在反序列时被调用,可以在该方法中控制反序列的内容
自定义序列化
如果一个类不仅实现了Serializable接口,而且定义了 readObject(ObjectInputStream in)和 writeObject(ObjectOutputStream out)方法,那么将按照如下的方式进行序列化和反序列化:
ObjectOutputStream会调用这个类的writeObject方法进行序列化,ObjectInputStream会调用相应的readObject方法进行反序列化。
自定义序列化内部实现机制(反射)
那么ObjectOutputStream又是如何知道一个类是否实现了writeObject方法呢?又是如何自动调用该类的writeObject方法呢?
答案是:是通过反射机制实现的。
在ObjectStreamClass类的构造函数中有下面几行代码:
cons = getSerializableConstructor(cl); writeObjectMethod = getPrivateMethod(cl, "writeObject", new Class<?>[] { ObjectOutputStream.class }, Void.TYPE); readObjectMethod = getPrivateMethod(cl, "readObject", new Class<?>[] { ObjectInputStream.class }, Void.TYPE); readObjectNoDataMethod = getPrivateMethod( cl, "readObjectNoData", null, Void.TYPE); hasWriteObjectData = (writeObjectMethod != null);getPrivateMethod()方法实现如下:
private static Method getPrivateMethod(Class<?> cl, String name, Class<?>[] argTypes, Class<?> returnType) { try { Method meth = cl.getDeclaredMethod(name, argTypes); meth.setAccessible(true); int mods = meth.getModifiers(); return ((meth.getReturnType() == returnType) && ((mods & Modifier.STATIC) == 0) && ((mods & Modifier.PRIVATE) != 0)) ? meth : null; } catch (NoSuchMethodException ex) { return null; } }可以看到在ObejctStreamClass的构造函数中会查找被序列化类中有没有定义为void writeObject(ObjectOutputStream oos) 的函数,如果找到的话,则会把找到的方法赋值给writeObjectMethod这个变量,如果没有找到的话则为null。
在调用writeSerialData()方法写入序列化数据的时候,首先会调用hasWriteObjectMethod()方法判断有没有自定义的writeObject(),如果有的话就调用用户自定义的writeObject()方法。
transient修饰的字段不能被序列化
transit变量和类变量(static)不被序列化
我们都知道一个对象只要实现了Serilizable接口,这个对象就可以被序列化,java的这种序列化模式为开发者提供了很多便利,我们可以不必关系具体序列化的过程,只要这个类实现了Serilizable接口,这个类的所有属性和方法都会自动序列化。
然而在实际开发过程中,我们常常会遇到这样的问题,这个类的有些属性需要序列化,而其他属性不需要被序列化,打个比方,如果一个用户有一些敏感信息(如密码,银行卡号等),为了安全起见,不希望在网络操作(主要涉及到序列化操作,本地序列化缓存也适用)中被传输,这些信息对应的变量就可以加上transient关键字。换句话说,这个字段的生命周期仅存于调用者的内存中而不会写到磁盘里持久化。
总之,java 的transient关键字为我们提供了便利,你只需要实现Serilizable接口,将不需要序列化的属性前添加关键字transient,序列化对象的时候,这个属性就不会序列化到指定的目的地中。
transient使用小结
1)一旦变量被transient修饰,变量将不再是对象持久化的一部分,该变量内容在序列化后无法获得访问。
2)transient关键字只能修饰变量,而不能修饰方法和类。注意,本地变量是不能被transient关键字修饰的。变量如果是用户自定义类变量,则该类需要实现Serializable接口。
3)被transient关键字修饰的变量不再能被序列化,一个静态变量不管是否被transient修饰,均不能被序列化。
static和transient字段不能被序列化的实现机制(反射)
序列化的时候所有的数据都是来自于ObjectStreamClass对象,在生成ObjectStreamClass的构造函数中会调用fields = getSerialFields(cl);这句代码来获取需要被序列化的字段,getSerialFields()方法实际上是调用getDefaultSerialFields()方法的,getDefaultSerialFields()实现如下:
private static ObjectStreamField[] getDefaultSerialFields(Class<?> cl) {
Field[] clFields = cl.getDeclaredFields();
ArrayList<ObjectStreamField> list = new ArrayList<>();
int mask = Modifier.STATIC | Modifier.TRANSIENT;
for (int i = 0; i < clFields.length; i++) {
if ((clFields[i].getModifiers() & mask) == 0) {
// 如果字段既不是static也不是transient的才会被加入到需要被序列化字段列表中去
list.add(new ObjectStreamField(clFields[i], false, true));
}
}
int size = list.size();
return (size == 0) ? NO_FIELDS :
list.toArray(new ObjectStreamField[size]);
}
通过Java的反射机制获取输入Class参数cl的字段,然后剔除有static和transient修饰符的字符安。
从上面的代码中可以很明显的看到,在计算需要被序列化的字段的时候会把被static和transient修饰的字段给过滤掉。
深入学习 Java 序列化
http://www.importnew.com/24490.html
序列化对单例模式的破坏
当我们使用Singleton模式时,应该是期望某个类的实例应该是唯一的,但如果该类是可序列化的,那么情况可能略有不同。
我们知道java 对象的序列化操作是实现Serializable接口,我们就可以把它往内存地写再从内存里读出而”组装”成一个跟原来一模一样的对象. 但是当我们遇到单例序列化的时候,就出现问题了。当从内存读出而组装的对象破坏了单例的规则,会创建新的对象。单例要求JVM只有一个对象,而通过反序化时就会产生一个克隆的对象,这就打破了单例的规则。
实现readResolve()方法避免单例被序列化破坏
对于Serializable and Externalizable classes,方法readResolve允许class在反序列化返回对象前替换、解析在流中读出来的对象。实现readResolve方法,一个class可以直接控制反序化返回的类型和对象引用。
方法readResolve会在ObjectInputStream已经读取一个对象并在准备返回前调用。ObjectInputStream 会检查对象的class是否定义了readResolve方法。如果定义了,将由readResolve方法指定返回的对象。返回对象的类型一定要是兼容的,否则会抛出ClassCastException 。
无论是实现Serializable接口,或是Externalizable接口,当从I/O流中读取对象时,readResolve()方法都会被调用到。实际上就是用readResolve()中返回的对象直接替换在反序列化过程中创建的对象。
Java序列化之readObjectNoData、readResolve方法
http://blog.csdn.net/anla_/article/details/70195048
深入理解Java对象序列化
http://developer.51cto.com/art/201202/317181.htm
java新特性
java 9 10 11 12 13新特性,这里为你总结全了
https://zhuanlan.zhihu.com/p/82717035
java8新特性
Java 8 习惯用语,第 1 部分 Java 中的一种更轻松的函数式编程途径(IBM developerworks)
https://www.ibm.com/developerworks/cn/java/j-java8idioms1/index.html
《写给大忙人看的Java SE 8》——Java8新特性总结
https://www.cnblogs.com/justcooooode/p/7701260.html
Java 8 特性 – 终极手册
http://ifeve.com/java-8-features-tutorial/
接口的默认方法和静态方法
函数式接口和Lambda表达式
Stream流
java9新特性
模块化
1、模块化
默认g1垃圾收集器
2、增强了Garbage-First(G1)并用它替代Parallel GC成为默认的垃圾收集器。
java10新特性
var局部变量类型推断
局部变量类型推断可以说是Java 10中最值得注意的特性
局部变量类型推断将引入”var”关键字,也就是你可以随意定义变量而不必指定变量的类型
java10中用var来声明变量,局部变量类型推断
//之前的代码格式
URL url = new URL("http://www.oracle.com/");
URLConnection conn = url.openConnection();
Reader reader = new BufferedReader(new InputStreamReader(conn.getInputStream()))
//java10中用var来声明变量
var url = new URL("http://www.oracle.com/");
var conn = url.openConnection();
var reader = new BufferedReader(new InputStreamReader(conn.getInputStream()));
java11
zgc垃圾搜集器
引入 zgc 垃圾搜集器
java12
增强switch语句
在 Java 12 中重新拓展了 Switch 让它具备了新的能力,通过扩展现有的 Switch 语句,可将其作为增强版的 Switch 语句或称为 “Switch 表达式”来写出更加简化的代码。
int dayNumber = switch (day) {
case MONDAY, FRIDAY, SUNDAY -> 6;
case TUESDAY -> 7;
case THURSDAY, SATURDAY -> 8;
case WEDNESDAY -> 9;
default -> throw new IllegalStateException("Huh? " + day);
}
使用 Java 12 中 Switch 表达式的写法,省去了 break 语句,避免了因少些 break 而出错,同时将多个 case 合并到一行,显得简洁、清晰也更加优雅的表达逻辑分支,其具体写法就是将之前的 case 语句表成了:case L ->,即如果条件匹配 case L,则执行 标签右侧的代码 ,同时标签右侧的代码段只能是表达式、代码块或 throw 语句。为了保持兼容性,case 条件语句中依然可以使用字符 : ,这时 fall-through 规则依然有效的,即不能省略原有的 break 语句,但是同一个 Switch 结构里不能混用 -> 和 : ,否则会有编译错误。并且简化后的 Switch 代码块中定义的局部变量,其作用域就限制在代码块中,而不是蔓延到整个 Switch 结构,也不用根据不同的判断条件来给变量赋值。
上一篇 LeetCode.153.Find Minimum in Rotated Sorted Array 旋转排序数组中的最小值
页面信息
location:protocol: host: hostname: origin: pathname: href: document:referrer: navigator:platform: userAgent: