面试准备14-计算机网络
面试准备之计算机基础
网络分层
OSI 七层网络模型
最初网络分层是标准的 OSI 七层模型:
- 应用层:为应用程序提供服务。定义了用于在网络中进行通信和传输数据的接口。
- 表示层:数据格式转换、数据加密。定义不同的系统中数据的传输格式,编码和解码规范等。
- 会话层:建立、管理和维护会话。管理用户的会话,控制用户间逻辑连接的建立和中断。
- 传输层:建立、管理和维护端到端的连接
- 网络层:IP选址及路由选择。定义网络设备间如何传输数据。
- 数据链路层:提供介质访问和链路管理。将上面的网络层的数据包封装成数据帧,便于物理层传输。
- 物理层:传输二进制数据。
TCP/IP 五层网络模型
TCP/IP 五层模型是从 OSI 七层优化而来,把某些层进行了合并:
- 应用层
- 传输层
- 网络层
- 数据链路层
- 物理层
输入网址到显示页面的网络流程
从输入网址到显示页面经过哪些步骤?用到哪些协议?
应用层(Application)
HTTP超文本传输协议,提供www等服务。输入的网址包含http一般为默认。
DNS动态域名系统,提供域名到IP地址的解析
FTP文件传输协议,提供文件的传送,如上传,下载
RIP路由信息协议,提供路由信息
传输层(Transport)
TCP传输控制协议,提供面向连接的,端到端的,可靠的数据传输
UDP用户数据报协议,提供面向无连接的,不可靠的,快捷的数据传输
网际层(Internet)
IP因特网通信协议,负责选择数据传送的道路。主要有两个功能:寻址,分段。
ARP地址解析协议,提供IP地址到MAC地址的解析
ICMP控制报文协议,提供IP主机,路由器之间控制消息(网络通不通)的传递。
链路层(link)
PPP点对点协议,提供路由器之间或者主机之间的连接
四层负载均衡与七层负载均衡
四层负载均衡:在 TCP/IP 层做,或者说只能依靠 ip:port 做转发。
七层负载均衡:在 应用层做,可以实现根据 http url路径进行转发。Nginx 是一个典型的七层负载均衡器。
四层负载均衡不识别域名,七层负载均衡识别域名
kubernetes 自带的 service 概念只有四层代理,即表现形式为 IP:Port
如果需要实现七层负载均衡,需要使用 ingress 插件。
IP地址
localhost 和 127.0.0.1 的区别
所有以 127 开头的IP地址都是回环地址(Loop back address),是主机用于向自身发送通信的一个特殊地址。所谓的回环地址,通俗的讲,就是我们在主机上发送给127开头的IP地址的数据包会被发送的主机自己接收,根本传不出去,外部设备也无法通过回环地址访问到本机。
正常的数据包会从IP层进入链路层,然后发送到网络上;而给回环地址发送数据包,数据包会直接被发送主机的IP层获取,后面就没有链路层他们啥事了。
而127.0.0.1作为{127}集合中的一员,当然也是个回环地址。只不过127.0.0.1经常被默认配置为localhost的IP地址。
当操作系统初始化本机的TCP/IP协议栈时,设置协议栈本身的IP地址为127.0.0.1(保留地址),并注入路由表。当IP层接收到目的地址为127.0.0.1(准确的说是:网络号为127的IP)的数据包时,不调用网卡驱动进行二次封装,而是立即转发到本机IP层进行处理,由于不涉及底层操作。因此,ping 127.0.0.1 一般作为测试本机TCP/IP协议栈正常与否的判断之一。
localhost 首先是一个域名,也是本机地址,它可以被配置为任意的IP地址(也就是说,可以通过hosts这个文件进行更改的),不过通常情况下都指向:
IPv4 中指向 127.0.0.1
IPv6 中指向 [::1]
之所以我们经常把 localhost 与 127.0.0.1 认为是同一个是因为我们使用的大多数电脑上都将 localhost 指向了 127.0.0.1 这个地址。
localhot 不经网卡传输,这点很重要,它不受网络防火墙和网卡相关的的限制。
127.0.0.1 需要通过网卡传输,依赖网卡,并受到网络防火墙和网卡相关的限制。
一般访问本地服务用 localhost 是最好的,localhost 不会解析成 ip,也不会占用网卡、网络资源。
有时候用 localhost 可以,但用 127.0.0.1 就不可以的情况就是在于此。猜想localhost访问时,系统带的本机当前用户的权限去访问,而用ip的时候,等于本机是通过网络再去访问本机,可能涉及到网络用户的权限。
mysql -hlocalhost 和 -h127.0.0.1 的区别
mysql -h 127.0.0.1 的时候,使用 TCP/IP 连接,连上后 status 查看状态能看到 Connection: 127.0.0.1 via TCP/IPmysql -h localhost 的时候,不使用 TCP/IP 连接的,而使用Unix Domain Socket,连上后 status 查看状态能看到 Connection: Localhost via UNIX socket
实验如下,使用的是 mariadb ,和 mysql 相同,注意看 status 命令返回结果中的 Connection 信息
1、mysql -h localhost 连接
mysql -h localhost -udevelopment -p uds
Enter password:
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 27
Server version: 10.3.7-MariaDB Homebrew
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [uds]> status
--------------
mysql Ver 15.1 Distrib 10.3.7-MariaDB, for osx10.13 (x86_64) using readline 5.1
Connection id: 27
Current database: uds
Current user: development@localhost
SSL: Not in use
Current pager: less
Using outfile: ''
Using delimiter: ;
Server: MariaDB
Server version: 10.3.7-MariaDB Homebrew
Protocol version: 10
Connection: Localhost via UNIX socket
Server characterset: utf8
Db characterset: utf8
Client characterset: utf8
Conn. characterset: utf8
UNIX socket: /tmp/mysql.sock
Uptime: 22 days 27 min 32 sec
Threads: 9 Questions: 1357 Slow queries: 0 Opens: 488 Flush tables: 1 Open tables: 481 Queries per second avg: 0.000
2、mysql -h 127.0.0.1 连接
mysql -h 127.0.0.1 -udevelopment -p uds
Enter password:
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 28
Server version: 10.3.7-MariaDB Homebrew
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [uds]> status
--------------
mysql Ver 15.1 Distrib 10.3.7-MariaDB, for osx10.13 (x86_64) using readline 5.1
Connection id: 28
Current database: uds
Current user: development@localhost
SSL: Not in use
Current pager: less
Using outfile: ''
Using delimiter: ;
Server: MariaDB
Server version: 10.3.7-MariaDB Homebrew
Protocol version: 10
Connection: 127.0.0.1 via TCP/IP
Server characterset: utf8
Db characterset: utf8
Client characterset: utf8
Conn. characterset: utf8
TCP port: 3306
Uptime: 22 days 31 min 22 sec
Threads: 9 Questions: 1721 Slow queries: 0 Opens: 488 Flush tables: 1 Open tables: 481 Queries per second avg: 0.000
--------------
0.0.0.0 本机所有ip
IPV4中,0.0.0.0地址被用于表示一个无效的,未知的或者不可用的目标。
- 在服务器中,0.0.0.0 指的是本机上的所有IPV4地址,如果一个主机有两个IP地址,192.168.1.1 和 10.1.2.1,并且该主机上的一个服务监听的地址是0.0.0.0, 那么通过两个ip地址都能够访问该服务。
- 在路由中,0.0.0.0表示的是默认路由,即当路由表中没有找到完全匹配的路由的时候所对应的路由。
私有IP
私有IP地址范围:
10.0.0.010.255.255.255,即10.0.0.0/8172.31.255.255,即172.16.0.0/12
172.16.0.0
192.168.0.0~192.168.255.255,即192.168.0.0/16
UDP协议
UDP协议全称是用户数据报协议,在网络中它与TCP协议一样用于处理数据包,是一种无连接的协议。
在OSI模型中,在第四层——传输层,处于IP协议的上一层。UDP不提供数据包分组、组装和不能对数据包进行排序的缺点,也就是说,当报文发送之后,是无法得知其是否安全完整到达的。
它有以下几个特点:
1、 面向无连接
首先 UDP 是不需要和 TCP 一样在发送数据前进行三次握手建立连接的,想发数据就可以开始发送了。并且也只是数据报文的搬运工,不会对数据报文进行任何拆分和拼接操作。
具体来说就是:
在发送端,应用层将数据传递给传输层的 UDP 协议,UDP 只会给数据增加一个 UDP 头标识下是 UDP 协议,然后就传递给网络层了
在接收端,网络层将数据传递给传输层,UDP 只去除 IP 报文头就传递给应用层,不会任何拼接操作
2、 有单播,多播,广播的功能
UDP 不止支持一对一的传输方式,同样支持一对多,多对多,多对一的方式,也就是说 UDP 提供了单播,多播,广播的功能。
3、 UDP是面向报文的
发送方的UDP对应用程序交下来的报文,在添加首部后就向下交付IP层。UDP对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界。因此,应用程序必须选择合适大小的报文
4、 不可靠性
首先不可靠性体现在无连接上,通信都不需要建立连接,想发就发,这样的情况肯定不可靠。
并且收到什么数据就传递什么数据,并且也不会备份数据,发送数据也不会关心对方是否已经正确接收到数据了。
再者网络环境时好时坏,但是 UDP 因为没有拥塞控制,一直会以恒定的速度发送数据。即使网络条件不好,也不会对发送速率进行调整。这样实现的弊端就是在网络条件不好的情况下可能会导致丢包,但是优点也很明显,在某些实时性要求高的场景(比如电话会议)就需要使用 UDP 而不是 TCP。
TCP和UDP对比
| 特性 | UDP | TCP |
|---|---|---|
| 是否连接 | 无连接 | 面向连接 |
| 是否可靠 | 不可靠传输,不使用流量控制和拥塞控制 | 可靠传输,使用流量控制和拥塞控制 |
| 连接对象个数 | 支持一对一,一对多,多对一和多对多交互通信 | 只能是一对一通信 |
| 传输方式 | 面向报文 | 面向字节流 |
| 首部开销 | 首部开销小,仅8字节 | 首部最小20字节,最大60字节 |
| 适用场景 | 适用于实时应用(IP电话、视频会议、直播等) | 适用于要求可靠传输的应用,例如文件传输 |
| 黏包半包问题 | 无 | 有 |
UDP是用桶运水,都是一桶一桶的发货。
TCP是用水管运水,水管打开后,水就或连续或不连续的流。
一文搞懂TCP与UDP的区别
https://blog.fundebug.com/2019/03/22/differences-of-tcp-and-udp/
TCP协议
TCP协议全称是传输控制协议是一种面向连接的、可靠的、基于字节流的传输层通信协议,由 IETF 的 RFC 793 定义。
TCP 是面向连接的、可靠的流协议。流就是指不间断的数据结构,你可以把它想象成排水管中的水流。
TCP 的那些事儿(上)
https://coolshell.cn/articles/11564.html
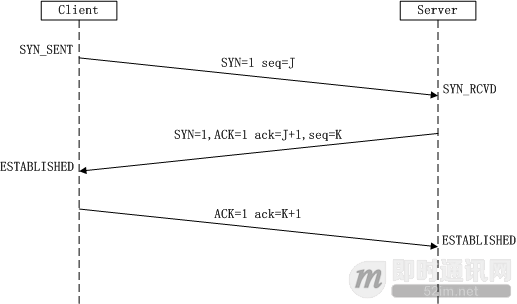
三次握手
所谓三次握手(Three-Way Handshake)即建立TCP连接,就是指建立一个TCP连接时,需要客户端和服务端总共发送3个包以确认连接的建立。
跳跃表
(1)第一次握手:
Client 将标志位 SYN 置为 1,随机产生一个值 seq=J,并将该数据包发送给 Server,Client进入 SYN_SENT 状态,等待 Server 确认。
(2)第二次握手:
Server 收到数据包后由标志位 SYN=1 知道 Client 请求建立连接,Server 将标志位 SYN 和 ACK 都置为1,ack=J+1,随机产生一个值seq=K,并将该数据包发送给 Client 以确认连接请求,Server进入 SYN_RCVD 状态。
(3)第三次握手:
Client 收到确认后,检查 ack是否为J+1,ACK 是否为1,如果正确则将标志位 ACK 置为1,ack=K+1,并将该数据包发送给Server,Server 检查ack是否为 K+1,ACK是否为1,如果正确则连接建立成功,Client 和 Server 进入 ESTABLISHED 状态,完成三次握手,随后Client与Server之间可以开始传输数据了。
一个TCP连接必须要经过三次“对话”才能建立起来,其中的过程非常复杂,只简单的 描述下这三次对话的简单过程:主机A向主机B发出连接请求数据包:“我想给你发数据,可以吗?”,这是第一次对话;主机B向主机A发送同意连接和要求同步 (同步就是两台主机一个在发送,一个在接收,协调工作)的数据包:“可以,你什么时候发?”,这是第二次对话;主机A再发出一个数据包确认主机B的要求同 步:“我现在就发,你接着吧!”,这是第三次对话。三次“对话”的目的是使数据包的发送和接收同步,经过三次“对话”之后,主机A才向主机B正式发送数 据。
为什么需要3次握手?
TCP握手是为了协商什么?
是为了协商通信双方数据起点的序列号seq!
TCP 设计中一个基本设定就是,通过TCP 连接发送的每一个包,都有一个sequence number。
而因为每个包都是有序列号的,所以都能被确认收到这些包。
确认机制是累计的,所以一个对sequence number X 的确认,意味着 X 序列号之前(不包括 X) 包都是被确认接收到的。
谢希仁《计算机网络》第四版 中关于为什么两次握手不行的解释:
建立三次握手主要是因为A发送了再一次的确认,那么A为什么会再确认一次呢,主要是为了防止已失效的连接请求报文段又突然传送给B,从而产生了错误。
异常情况下,A发送的请求报文连接段并没有丢失,而是在某个网络节点滞留较长时间,以致延误到请求释放后的某个时间到达B,本来是一个早已失效的报文段,但是B收到了此失效连接请求报文段后,就误以为A又重新发送的连接请求报文段,并发送确认报文段给A,同意建立连接,如果没有三次握手,那么B发送确认后,连接就建立了,而此时A没有发送建立连接的请求报文段,于是不理会B的确认,也不会给B发送数据,而B却一直等待A发送数据,因此B的许多资源就浪费了
其他解释:
A syn, seq_a -> B
B syn, seq_b -> A
如果只有2次握手,但是B无法知道A是否已经接收到自己的同步信号,如果这个同步信号丢失了,A和B就B的初始序列号将无法达成一致。
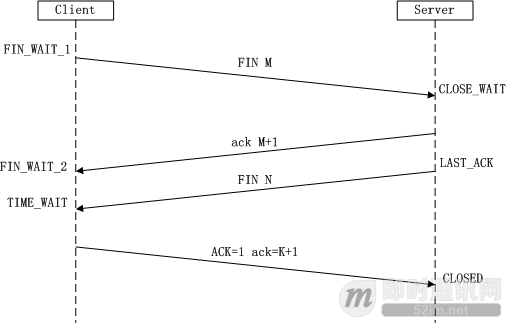
四次挥手
由于TCP连接时全双工的,因此,每个方向都必须要单独进行关闭,这一原则是当一方完成数据发送任务后,发送一个 FIN 来终止这一方向的连接,收到一个 FIN 只是意味着这一方向上没有数据流动了,即不会再收到数据了,但是在这个 TCP 连接上仍然能够发送数据,直到这一方向也发送了 FIN。首先进行关闭的一方将执行主动关闭,而另一方则执行被动关闭
第一次挥手:
Client(首先没有数据发送的一方)调用 close() 发送 FIN,用来关闭 Client 到 Server 的数据传送,Client 进入 FIN_WAIT_1 状态。
第二次挥手:
Server 收到 FIN 后,发送一个 ACK 给 Client,确认序号为收到序号+1(与 SYN 相同,一个 FIN 占用一个序号),Server 进入 CLOSE_WAIT 状态。
Client 接收到 ACK 后,进入 FIN_WAIT_2 状态
第三次挥手:
Server 也没有数据要发送后,调用 close() 发送一个 FIN,用来关闭 Server 到 Client 的数据传送,Server 进入 LAST_ACK 状态。
第四次挥手:
Client 收到 FIN 后,Client 进入 TIME_WAIT 状态,接着发送一个 ACK 给 Server,确认序号为收到序号+1
Server 收到 ACK 后,进入 CLOSED 状态,完成四次挥手。
为什么连接是三次握手而关闭时需要四次握手?
答:因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,”你发的FIN报文我收到了”。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
理论经典:TCP协议的3次握手与4次挥手过程详解
http://blog.csdn.net/omnispace/article/details/52701752
tcp三次握手四次挥手(及原因)详解
http://blog.csdn.net/xulu_258/article/details/51146489
TCP状态转换图
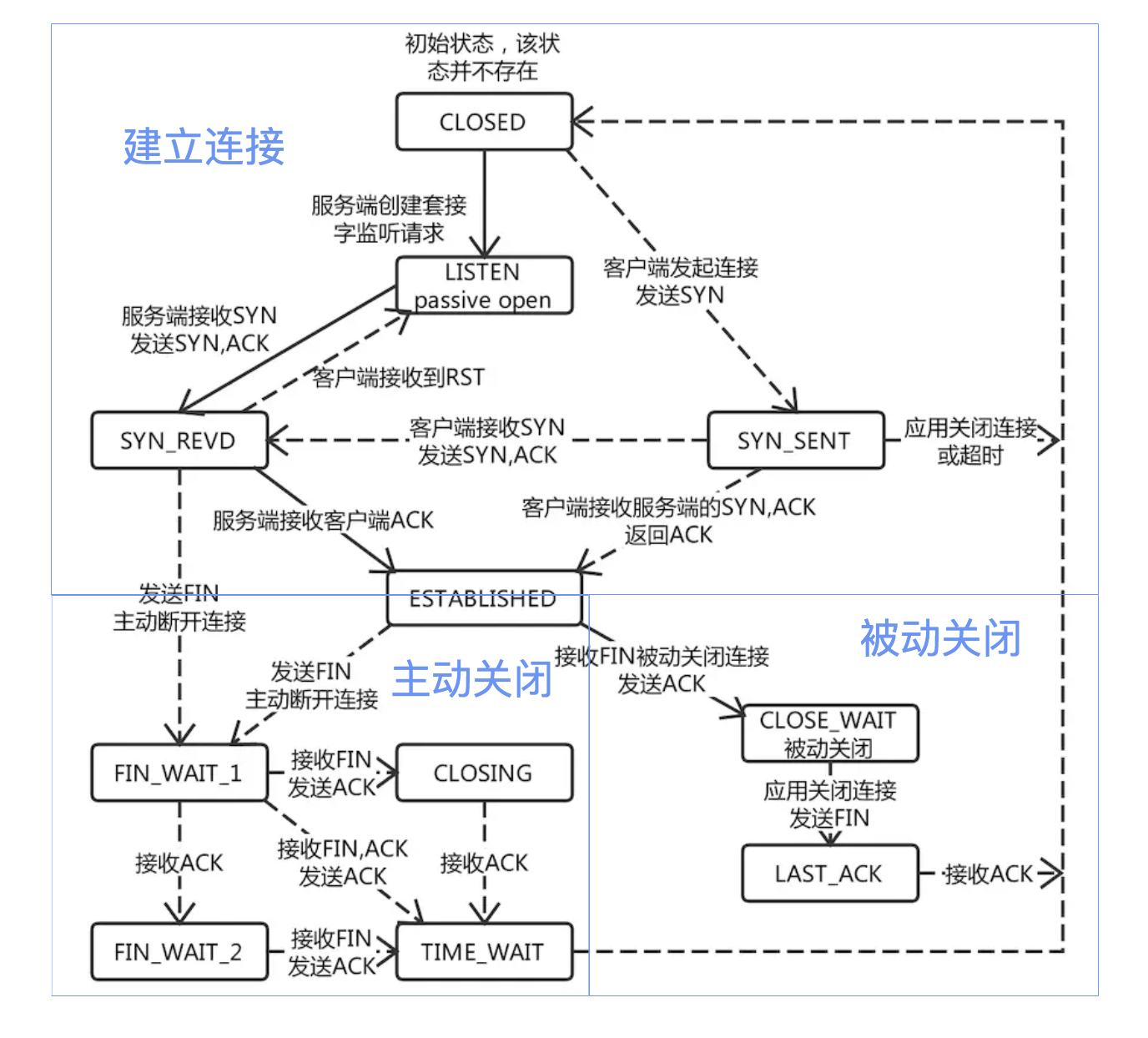
TCP状态转换图
CLOSE_WAIT 状态
CLOSE_WAIT与TIME_WAIT区别
- 主动关闭连接的一方,调用close();协议层发送FIN包 ;
- 被动关闭的一方收到FIN包后,协议层回复ACK;然后被动关闭的一方,进入CLOSE_WAIT状态,主动关闭的一方等待对方关闭,则进入FIN_WAIT_2状态;此时,主动关闭的一方等待被动关闭一方的应用程序,调用close操作 ;
- 被动关闭的一方在完成所有数据发送后,调用close()操作;此时,协议层发送FIN包给主动关闭的一方,等待对方的ACK,被动关闭的一方进入LAST_ACK状态;
- 主动关闭的一方收到FIN包,协议层回复ACK;此时,主动关闭连接的一方,进入TIME_WAIT状态;而被动关闭的一方,进入CLOSED状态 ;
- 等待 2MSL 时间,主动关闭的一方,结束TIME_WAIT,进入CLOSED状态 ;
CLOSE_WAIT 很多,表示说要么是你的应用程序写的有问题,没有合适的关闭socket;要么是说,你的服务器CPU处理不过来(CPU太忙)或者你的应用程序一直睡眠到其它地方(锁,或者文件I/O等等),你的应用程序获得不到合适的调度时间,造成你的程序没法真正的执行close操作。
TCP连接的TIME_WAIT和CLOSE_WAIT 状态解说
https://www.cnblogs.com/kevingrace/p/9988354.html
TIME_WAIT 状态
什么情况下会进入 TIME_WAIT 状态?
TCP 四次握手结束后,连接双方都不再交换消息,但主动关闭的一方保持这个连接在一段时间内不可用。
主动调用 close() 关闭连接的一方会进入 TIME_WAIT 状态
为什么要保持 TIME_WAIT 状态一段时间?
为了理解 TIME_WAIT 状态的必要性,我们先来假设没有这么一种状态会导致的问题。暂以 A、B 来代指 TCP 连接的两端,A 为主动关闭的一端。
1、四次挥手中,A 发 FIN, B 响应 ACK,B 再发 FIN,A 响应 ACK 实现连接的关闭。而如果 A 响应的 ACK 包丢失,B 会以为 A 没有收到自己的关闭请求,然后会重试向 A 再发 FIN 包。
如果没有 TIME_WAIT 状态,A 不再保存这个连接的信息,收到一个不存在的连接的包,A 会响应 RST 包,导致 B 端异常响应。
此时, TIME_WAIT 是为了保证全双工的 TCP 连接正常终止。
2、我们还知道,TCP 下的 IP 层协议是无法保证包传输的先后顺序的。如果双方挥手之后,一个网络四元组(src/dst ip/port)被回收,而此时网络中还有一个迟到的数据包没有被 B 接收,A 应用程序又立刻使用了同样的四元组再创建了一个新的连接后,这个迟到的数据包才到达 B,那么这个数据包就会让 B 以为是 A 刚发过来的。
此时, TIME_WAIT 的存在是为了保证网络中迷失的数据包正常过期。
由以上两个原因,TIME_WAIT 状态的存在是非常有意义的。
TIME_WAIT 时长是多少?(2MSL)
TIME_WAIT 的时长应该保证关闭连接后这个连接在网络中的所有数据包都过期。
数据包的寿命由 最大分段寿命(MSL, Maximum Segment Lifetime)决定,它表示一个 TCP 分段可以存在于互联网系统中的最大时间,由 TCP 的实现,超出这个寿命的分片都会被丢弃。
TIME_WAIT 状态由主动关闭的 A 来保持,那么我们来考虑对于 A 来说,可能接到上一个连接的数据包的最大时长:A 刚发出的数据包,能保持 MSL 时长的寿命,它到了 B 端后,B 端由于关闭连接了,会响应 RST 包,这个 RST 包最长也会在 MSL 时长后到达 A,那么 A 端只要保持 TIME_WAIT 到达 2MST 就能保证网络中这个连接的包都会消失。
MSL 的时长被 RFC 定义为 2 分钟,但在不同的 unix 实现上,这个值不并确定,我们常用的 CentOS 上,它被定义为 30s,我们可以通过 /proc/sys/net/ipv4/tcp_fin_timeout 这个文件查看和修改这个值。
即一般 TIME_WAIT 是 60 秒。
为什么压测时server端会出现大量TIME_WAIT状态?
由于 TIME_WAIT 的存在,每个连接被主动关闭后,这个连接就要保留 2MSL(60s) 时长,一个网络五元组 (tcp/udp, src_ip:src_port, dst_ip:dst_port) 也要被冻结 60s。而我们机器默认可被分配的端口号约有 30000 个(可通过 /proc/sys/net/ipv4/ip_local_port_range 文件查看)。
由于服务器监听的端口会复用,这些 TIME_WAIT 状态的连接并不会对服务器造成太大影响,只是会占用一些系统资源。
但如果并发请求过多,还是会造成无法及时响应。造成
Non HTTP response code: java.net.NoRouteToHostException/Non HTTP response message: Can’t assign requested address (Address not available)
错误
如何解决服务器的大量TIME_OUT状态?
解决方法:
1、修改 ipv4.ip_local_port_range,增大可用端口范围cat /proc/sys/net/ipv4/ip_local_port_range 查看可使用的端口范围,默认值是 net.ipv4.ip_local_port_range = 32768 61000
改为 net.ipv4.ip_local_port_range = 1024 65535
执行:sudo sysctl -p 使设置立即生效。
2、修改 /etc/sysctl.conf 编辑文件,加入以下内容:
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_fin_timeout = 30
net.ipv4.ip_local_port_range = 1024 65000
然后执行 sudo sysctl -p 让参数生效。
net.ipv4.tcp_tw_reuse = 1 表示开启重用。允许将 TIME-WAIT sockets 重新用于新的 TCP 连接,默认为 0,表示关闭;
net.ipv4.tcp_tw_recycle = 1 表示开启 TCP 连接中 TIME-WAIT sockets 的快速回收,默认为0,表示关闭。
net.ipv4.tcp_fin_timeout 修改系統默认的 TIMEOUT 时间
系统调优你所不知道的TIME_WAIT和CLOSE_WAIT
https://zhuanlan.zhihu.com/p/40013724
Dec 15, 2018 - 谈谈 TCP 的 TIME_WAIT
https://zhenbianshu.github.io/2018/12/talk_about_tcp_timewait.html
RST 标志
正常情况下,tcp 通过四次挥手来关闭连接:
1、A 没有数据要发送后发 FIN 给 B
2、B 返回 ACK,之后还可以继续发送数据
3、B 也没有数据要发送后,发 FIN 给 A
4、A 返回 ACK,之后等待 TIME_WAIT 后关闭连接。
但还有一种紧急关闭连接的方法:
1、一方发送 RST 标志给另一方,表明自己既不发送也不接收了,也就是直接关闭了双向的通信。
2、另一方收到 RST 标志后,抛弃连接。
SO_LINGER 选项
SO_LINGER 选项用来设置延迟关闭的时间,等待套接字发送缓冲区中的数据发送完成。
没有设置该选项时,在调用 close() 后,在发送完 FIN 后会立即进行一些清理工作并返回。如果设置了 SO_LINGER 选项,并且等待时间为正值,则在清理之前会等待一段时间。
以调用close()主动关闭为例,在发送完FIN包后,会进入FIN_WAIT_1状态。如果没有延迟关闭(即设置SO_LINGER选项),在调用tcp_send_fin()发送FIN后会立即调用sock_orphan()将sock结构从进程上下文中分离。分离后,用户层进程不会再接收到套接字的读写事件,也不知道套接字发送缓冲区中的数据是否被对端接收。
如果设置了SO_LINGER选项,并且等待时间为大于0的值,会等待 SO_LINGER 超时时间后从FIN_WAIT_1迁移到FIN_WAIT_2状态。我们知道套接字进入FIN_WAIT_2状态是在发送的FIN包被确认后,而FIN包肯定是在发送缓冲区中的最后一个字节,所以FIN包的确认就表明发送缓冲区中的数据已经全部被接收。当然,如果等待超过SO_LINGER选项设置的时间后,还是没有收到FIN的确认,则继续进行正常的清理工作,Linux下也没有返回错误。
从这里看来,SO_LINGER选项的作用是等待发送缓冲区中的数据发送完成,但是并不保证发送缓冲区中的数据一定被对端接收(对端宕机或线路问题),只是说会等待一段时间让这个过程完成。如果在等待的这段时间里接收到了带数据的包,还是会给对端发送RST包,并且会reset掉套接字,因为此时已经关闭了接收通道。
设置SO_LINGER为0来减少TIME_WAIT状态
SO_LINGER 还有一个作用就是用来减少 TIME_WAIT 套接字的数量。在设置 SO_LINGER 选项时,指定等待时间为0,此时调用主动关闭时不会发送 FIN 来结束连接,而是直接将连接设置为 CLOSE 状态,清除套接字中的发送和接收缓冲区,直接对对端发送 RST 包。
具体的,在调用 close() 之前,设置 SO_LINGER 的超时时间为 0,此时调用 close() 会发送一个 RST 给对端,可以立即结束TCP连接,但这不是正常的 TCP 连接结束,典型的会导致 Connection reset by peer 错误。
慎重使用 SO_LINGER(timeout=0) 选项,使用 RST 代替 FIN 直接强制关闭连接,主动关闭的一方也不会进入 TIME_WAIT 阶段,会减少系统的连接数,提高并发连接能力,但是这种异常关闭连接的方式,TCP 连接关闭的 TIME_WAIT 的作用也就没有了,是个有利有弊的用法,尽量不要使用,而是通过设计应用层协议来避免 TIME_WAIT 连接过多的问题。
When is TCP option SO_LINGER (0) required?
https://stackoverflow.com/questions/3757289/when-is-tcp-option-so-linger-0-required
setsockopt 设置TCP的选项SO_LINGER
https://www.cnblogs.com/kex1n/p/7401042.html
TCP长连接/短连接
短连接最大的优点是方便,特别是脚本语言,由于执行完毕后脚本语言的进程就结束了,基本上都是用短连接。
但短连接最大的缺点是将占用大量的系统资源,例如:本地端口、socket句柄。
导致这个问题的原因其实很简单:tcp协议层并没有长短连接的概念,因此不管长连接还是短连接,连接建立->数据传输->连接关闭的流程和处理都是一样的。
正常的TCP客户端连接在关闭后,会进入一个 TIME_WAIT 的状态,持续的时间一般在 14 分钟,对于连接数不高的场景,14 分钟其实并不长,对系统也不会有什么影响,
但如果短时间内(例如1s内)进行大量的短连接,则可能出现这样一种情况:客户端所在的操作系统的socket端口和句柄被用尽,系统无法再发起新的连接!
举例来说:假设每秒建立了 1000 个短连接,假设 TIME_WAIT 的时间是1分钟,则 1 分钟内需要建立 6W 个短连接,
由于 TIME_WAIT 时间是 1 分钟,这些短连接1分钟内都处于TIME_WAIT状态,都不会释放,而Linux默认的本地端口范围配置是:net.ipv4.ip_local_port_range = 32768 61000
不到3W,因此这种情况下新的请求由于没有本地端口就不能建立了。
tcp短连接TIME_WAIT问题解决方法大全(1)——高屋建瓴
https://blog.csdn.net/yunhua_lee/article/details/8146830
最大传输单元MTU和最大段大小MSS
以太网中 MSS = 1500(MTU) - 20(IP Header) - 20(TCP Header) = 1460 byte
MTU(Maximum Transmit Unit) 最大传输单元,是数据链路层的一个物理属性,由硬件决定,表示数据链路层提供给其上层(通常是 IP 层)最大单次传输数据的大小,以太网缺省 MTU=1500 Byte. MTU 是数据链路层对 IP 层的约束。
如果 IP 层要发送的数据小于 1500 byte, 只需要一个 IP 包就可以完成发送;如果 IP 层要发送的数据大于 1500 byte, 需要分片才能完成发送。分片传输的 IP 数据报不一定按序到达,但 IP 首部中的信息能让这些数据报片按序组装。
IP 数据报的分片与重组是在网络层完成的。
MSS(Maximum Segment Size) TCP 最大段大小,是 TCP 协议的一个属性,表示 TCP 提交给 IP 层的最大分段大小,MSS 是传输层用来限制应用层的最大单次发送字节数。
MSS 不包含 TCP Header 和 TCP Option, 只包含 TCP Payload. MSS 的大小一般为 MTU 值减去 IP 首部大小和 TCP 首部大小,在以太网中就是 MSS = 1500(MTU) - 20(IP Header) - 20 (TCP Header) = 1460 byte
如果应用层有 2000 byte 要发送,需要两个 segment 才可以完成发送,第一个 TCP segment = 1460, 第二个 TCP segment = 540.
TCP 报文段的分段与重组是在传输层完成的。
TCP 分段的原因是 MSS, IP 分片的原因是 MTU, 由于一直有 MSS<=MTU, 很明显,分段后的每一段 TCP 报文段再加上 IP 首部后的长度不可能超过 MTU, 因此也就不需要在网络层进行 IP 分片了。因此 TCP 报文段很少会发生 IP 分片的情况。
此外,UDP 报文和 ICMP 报文都会出现超过 MTU 大小而需要在网络层进行 IP 数据包分片的情况。
比如 UDP 协议规定报文长度为 16 位,所以 UDP 的报文长度最大可达 2^16 = 65536 字节,如果 UDP 报文长度超过 1500(MTU) - 20(IP Header) = 1480 byte, 则会在网络层进行 IP 分片。
TCP粘包/半包
TCP 传输中,客户端发送数据,实际是把数据写入到了 TCP 的缓存(缓冲区)中,粘包和半包也就会在此时产生。
如果客户端发送的包的大小比 TCP 的缓存容量小,并且 TCP 缓存可以存放多个包,那么客户端和服务端的一次通信就可能传递了多个包,这时候服务端从 TCP 缓存就可能一下读取了多个包,这种现象就叫粘包。即接收方一次收到了多个数据包,粘合在一起,被称为 TCP 粘包
如果客户端发送的包的大小比 TCP 的缓存容量大,那么这个数据包就会被分成多个包,通过 Socket 多次发送到服务端,服务端第一次从接受缓存里面获取的数据,实际是整个包的一部分,这时候就产生了半包(半包不是说只收到了全包的一半,是说收到了全包的一部分)。即接收方一次只读取到数据包的一部分,分多次才读完整个数据包,成为 TCP 半包或拆包。
粘包和半包问题可能混杂在一起,比如接收方一次接收了数据包 A 和数据包 B-part1, 第二次才接收 B-part2, 则同时发生了粘包和半包问题。
原因
粘包原因:
1、发送方每次写入数据 < 套接字(Socket)缓冲区大小
2、服务器在接收到数据后,放到缓冲区中,如果消息没有被及时从缓存区取走,下次在取数据的时候可能就会出现一次取出多个数据包的情况,造成粘包现象。
即接收方读取套接字(Socket)缓冲区数据不够及时
半包原因:
1、发送方每次写入数据 > 套接字(Socket)缓冲区大小
2、发送的数据大于协议的 MTU (Maximum Transmission Unit,最大传输单元),因此必须拆包,或者说数据大于TCP MSS大小,必须分段。
从收发的角度看,便是一个发送可能被多次接收(半包),多个发送可能被一次接收(粘包)。
从传输的角度看,便是一个发送可能占用多个传输包(半包),多个发送可能共用一个传输包(粘包)。
根本原因:TCP 是流式协议,消息无边界。UDP面向报文,消息有边界,所以无粘包、半包问题。
解决
TCP 层无法解决粘包、半包问题,只能在应用层解决。
为什么在 TCP 层无法解决粘包、半包问题?
因为 TCP 是面向连接的传输协议,TCP 传输的数据是以流的形式,而流数据是没有明确的开始结尾边界,所以 TCP 也没办法判断哪一段流属于一个消息。
解决半包粘包的问题其实就是定义消息边界的问题,在应用层划分消息边界。
可参考 Netty 的三种编解码方式,也就是 Netty 解决粘包半包的方式 Netty
固定长度
每个消息都是固定大小的。
优点就是实现很简单,缺点就是空间有极大的浪费,如果传递的消息中大部分都比较短,这样就会有很多空间是浪费的。
一般不推荐。
分隔符
指定分隔符,消息边界也就是分隔符本身。
优点是空间不再浪费,实现也比较简单。缺点是当内容本身出现分割符时需要转义,所以无论是发送还是接受,都需要进行整个内容的扫描。
效率也不是很高,但可以尝试使用。
专门的length字段
类似 Http 请求中的 Content-Length,有一个专门的字段存储消息的长度。作为服务端,接受消息时,先解析固定长度的字段(length字段)获取消息总长度,然后读取后续内容。
优点是精确定位用户数据,内容也不用转义。缺点是长度理论上有限制,需要提前限制可能的最大长度从而定义长度占用字节数。
推荐使用这种方式。
Socket通信
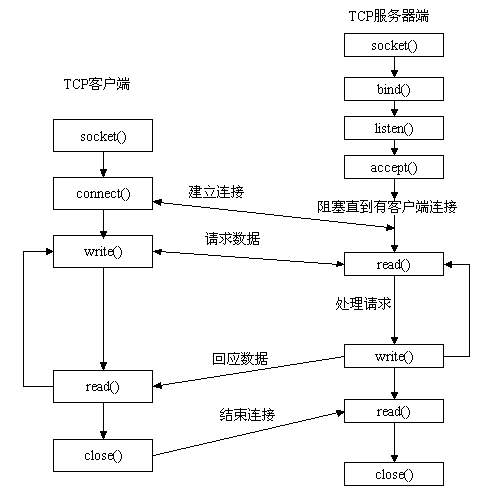
Socket简介
Socket 是对 TCP/IP 协议族的一种封装,是应用层与 TCP/IP 协议族通信的中间软件抽象层。从设计模式的角度看来,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。
Socket 还可以认为是一种网络间不同计算机上的进程通信的一种方法,利用三元组(ip地址,协议,端口)就可以唯一标识网络中的进程,网络中的进程通信可以利用这个标志与其它进程进行交互。
Socket 起源于 Unix ,Unix/Linux 基本哲学之一就是“一切皆文件”,都可以用“打开(open) –> 读写(write/read) –> 关闭(close)”模式来进行操作。因此 Socket 也被处理为一种特殊的文件。
Linux Socket编程(不限Linux)
https://www.cnblogs.com/skynet/archive/2010/12/12/1903949.html
网络字节序与主机字节序
主机字节序就是我们平常说的大端和小端模式:不同的CPU有不同的字节序类型,这些字节序是指整数在内存中保存的顺序,这个叫做主机序。
标准的 Big-Endian 和 Little-Endian 的定义如下:
a) Little-Endian 就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
b) Big-Endian 就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
网络字节序:4个字节的32 bit值以下面的次序传输:首先是0~7bit,其次8~15bit,然后16~23bit,最后是24~31bit。这种传输次序称作大端字节序。由于TCP/IP首部中所有的二进制整数在网络中传输时都要求以这种次序,因此它又称作网络字节序。字节序,顾名思义字节的顺序,就是大于一个字节类型的数据在内存中的存放顺序,一个字节的数据没有顺序的问题了。
所以:在将一个地址绑定到socket的时候,请先将主机字节序转换成为网络字节序,而不要假定主机字节序跟网络字节序一样使用的是Big-Endian。由于这个问题曾引发过血案!公司项目代码中由于存在这个问题,导致了很多莫名其妙的问题,所以请谨记对主机字节序不要做任何假定,务必将其转化为网络字节序再赋给socket。
socket通信流程
socket() 创建socket
#include <sys/socket.h>
int socket(int domain, int type, int protocol);
socket 函数对应于普通文件的打开操作。普通文件的打开操作返回一个文件描述字,而socket()用于创建一个socket描述符(socket descriptor),它唯一标识一个socket。这个socket描述字跟文件描述字一样,后续的操作都有用到它,把它作为参数,通过它来进行一些读写操作。
domain 即协议域,又称为协议族(family)。常用的协议族有,AF_INET、AF_INET6、AF_LOCAL(或称AF_UNIX,Unix域socket)、AF_ROUTE等等。协议族决定了socket的地址类型,在通信中必须采用对应的地址,如 AF_INET 表示32位IPv4地址加16位端口号,AF_UNIX表示绝对路径名作为地址。type socket类型,SOCK_STREAM表示TCP,SOCK_DGRAM表示UDPprotocol 协议类型,一般设为0,自动选择type对应的协议
当我们调用socket创建一个socket时,返回的socket描述字它存在于协议族(address family,AF_XXX)空间中,但没有一个具体的地址。如果想要给它赋值一个地址,就必须调用bind()函数,否则就当调用connect()、listen()时系统会自动随机分配一个端口。
bind() 给socket绑定地址
#include <sys/socket.h>
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
sockfd socket() 函数返回的 socket 描述符addr 要绑定给 sockfd 的地址(IP+端口),指向要绑定给sockfd的协议地址。这个地址结构根据地址创建socket时的地址协议族的不同而不同,比如 ipv4 地址是 sockaddr_in 结构,ipv6 地址是 sockaddr_in6 结构addrlen 地址长度
其中
struct sockaddr_in {
sa_family_t sin_family; /* address family: AF_INET */
in_port_t sin_port; /* 端口号,16位网络字节顺序,要用htons()转换 */
struct in_addr sin_addr; /* IP地址 */
};
struct in_addr {
uint32_t s_addr; /* IP地址,32位网络字节顺序,要用htonl()转换 */
};
listen() 服务端监听socket
#include <sys/socket.h>
int listen(int sockfd, int backlog);
sockfd 要监听的socket描述符backlog 此socket的最大连接个数(队列长度)
connect() 客户端连接
#include <sys/socket.h>
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
sockfd 客户端的socket描述符addr 服务器的socket地址(IP+端口)addrlen 地址长度
connect 函数时由客户端发起调用的。
accept() 服务器接受请求
#include <sys/socket.h>
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
sockfd 服务器的socket描述符,即监听的socket描述符addr addr在函数调用后被填入客户端的地址addrlen 客户端地址长度
如果 accpet() 成功,那么其返回值是由内核自动生成的一个全新的描述字,代表与返回客户的TCP连接。
accept() 为阻塞函数
TCP 服务器端依次调用 socket(), bind(), listen() 之后,就会监听指定的 socket 地址了。TCP 客户端依次调用 socket(), connect() 之后就向 TCP 服务器发送了一个连接请求。TCP 服务器监听到这个请求之后,就会调用 accept() 函数取接收请求,这样连接就建立好了。之后就可以开始网络I/O操作了,即类同于普通文件的读写I/O操作。
注意:accept() 的第一个参数为服务器的 socket 描述字,是服务器开始调用 socket() 函数生成的,称为监听socket描述字;而 accept() 函数返回的是已连接的 socket 描述字。
一个服务器通常通常仅仅只创建一个监听 socket 描述字,它在该服务器的生命周期内一直存在。内核为每个由服务器进程接受的客户连接创建了一个已连接 socket 描述字,当服务器完成了对某个客户的服务,相应的已连接 socket 描述字就被关闭。
read()/write() I/O操作
网络I/O操作有下面几组可用的方法:
read()/write()
recv()/send()
readv()/writev()
recvmsg()/sendmsg()
recvfrom()/sendto()
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);
#include <sys/types.h>
#include <sys/socket.h>
ssize_t send(int sockfd, const void *buf, size_t len, int flags);
ssize_t recv(int sockfd, void *buf, size_t len, int flags);
ssize_t sendto(int sockfd, const void *buf, size_t len, int flags, const struct sockaddr *dest_addr, socklen_t addrlen);
ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *src_addr, socklen_t *addrlen);
ssize_t sendmsg(int sockfd, const struct msghdr *msg, int flags);
ssize_t recvmsg(int sockfd, struct msghdr *msg, int flags);
用的比较多的是 read()/write()read() 函数是负责从 fd 中读取内容。当读成功时,read返回实际所读的字节数,如果返回的值是0表示已经读到文件的结束了,小于0表示出现了错误。如果错误为EINTR说明读是由中断引起的,如果是ECONNREST表示网络连接出了问题。write() 函数将 buf 中的 count 字节内容写入文件描述符fd。成功时返回写的字节数。失败时返回-1,并设置errno变量。
在网络程序中,当我们向套接字文件描述符写时有俩种可能。
- write的返回值大于0,表示写了部分或者是全部的数据。
- 返回的值小于0,此时出现了错误。
我们要根据错误类型来处理。如果错误为 EINTR 表示在写的时候出现了中断错误。如果为EPIPE表示网络连接出现了问题(对方已经关闭了连接)。
close() 关闭socket
#include <unistd.h>
int close(int fd);
关闭本进程的 socket 连接。
成功则返回0,错误返回-1,错误码errno:EBADF表示fd不是一个有效描述符;EINTR表示close函数被信号中断;EIO表示一个IO错误。
close 只是减少描述符 sockfd 的参考数,并不直接关闭连接,只有当描述符的参考数为 0 时才关闭连接。
也就是说
也可以选择单向关闭连接
#include<sys/socket.h>
int shutdown(int sockfd, int how);
how:SHUT_RD 或 0 禁止接收 关闭sockfd上的读功能,此选项将不允许sockfd进行读操作。SHUT_WR 或 1 禁止发送 关闭sockfd的写功能,此选项将不允许sockfd进行写操作。SHUT_RDWR 或 2 禁止发送和接收 关闭sockfd的读写功能。
成功则返回0,错误返回-1,错误码errno:EBADF表示sockfd不是一个有效描述符;ENOTCONN表示sockfd未连接;ENOTSOCK表示sockfd是一个文件描述符而不是socket描述符。
该函数允许你只停止在某个方向上的数据传输,而一个方向上的数据传输继续进行,比如可以关闭某socket的写操作而允许继续在该socket上接受数据直至读入所有数据。
shutdown()和close()的区别
1、close 关闭本进程的socket id,但链接还是开着的,用这个socket id的其它进程还能用这个链接,能读或写这个socket id
2、shutdown 则破坏了socket 链接,读的时候可能侦探到EOF结束符,写的时候可能会收到一个SIGPIPE信号,这个信号可能直到socket buffer被填充了才收到。shutdown 可直接关闭描述符,不考虑描述符的参考数,可选择中止一个方向的连接。
3、如果有多个进程共享一个套接字,close每被调用一次,计数减1,直到计数为0时,也就是所用进程都调用了close,套接字将被释放。
在多进程中如果一个进程中shutdown(sfd, SHUT_RDWR)后其它的进程将无法进行通信,但一个进程close(sfd)将不会影响到其它进程。
更多关于close和shutdown的说明
1、只要 TCP 栈的读缓冲里还有未读取(read)数据,则调用close时会直接向对端发送RST。
2、shutdown与socket描述符没有关系,即使调用shutdown(fd, SHUT_RDWR)也不会关闭fd,最终还需close(fd)(理解不了,是不是说错了?)。
3、可以认为shutdown(fd, SHUT_RD)是空操作,因为shutdown后还可以继续从该socket读取数据,这点也许还需要进一步证实。在已发送FIN包后write该socket描述符会引发EPIPE/SIGPIPE。
4、当有多个socket描述符指向同一socket对象时,调用close时首先会递减该对象的引用计数,计数为0时才会发送FIN包结束TCP连接。shutdown不同,只要以SHUT_WR/SHUT_RDWR方式调用即发送FIN包。
5、SO_LINGER与close,当SO_LINGER选项开启但超时值为0时,调用close直接发送RST(这样可以避免进入TIME_WAIT状态,但破坏了TCP协议的正常工作方式),SO_LINGER对shutdown无影响。
6、TCP连接上出现RST与随后可能的TIME_WAIT状态没有直接关系,主动发FIN包方必然会进入TIME_WAIT状态,除非不发送FIN而直接以发送RST结束连接。
Socket通信示例代码
socket通信示意图
服务端:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<errno.h>
#include<sys/types.h>
#include<sys/socket.h>
#include<netinet/in.h>
#define MAXLINE 4096
int main(int argc, char** argv)
{
int listenfd, connfd;
struct sockaddr_in servaddr;
char buff[4096];
int n;
if( (listenfd = socket(AF_INET, SOCK_STREAM, 0)) == -1 ){
printf("create socket error: %s(errno: %d)\n",strerror(errno),errno);
exit(0);
}
memset(&servaddr, 0, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = htonl(INADDR_ANY);
servaddr.sin_port = htons(6666);
if( bind(listenfd, (struct sockaddr*)&servaddr, sizeof(servaddr)) == -1){
printf("bind socket error: %s(errno: %d)\n",strerror(errno),errno);
exit(0);
}
if( listen(listenfd, 10) == -1){
printf("listen socket error: %s(errno: %d)\n",strerror(errno),errno);
exit(0);
}
printf("======waiting for client's request======\n");
while(1){
if( (connfd = accept(listenfd, (struct sockaddr*)NULL, NULL)) == -1){
printf("accept socket error: %s(errno: %d)",strerror(errno),errno);
continue;
}
n = recv(connfd, buff, MAXLINE, 0);
buff[n] = '\0';
printf("recv msg from client: %s\n", buff);
close(connfd);
}
close(listenfd);
}
客户端:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<errno.h>
#include<sys/types.h>
#include<sys/socket.h>
#include<netinet/in.h>
#define MAXLINE 4096
int main(int argc, char** argv)
{
int sockfd, n;
char recvline[4096], sendline[4096];
struct sockaddr_in servaddr;
if( argc != 2){
printf("usage: ./client <ipaddress>\n");
exit(0);
}
if( (sockfd = socket(AF_INET, SOCK_STREAM, 0)) < 0){
printf("create socket error: %s(errno: %d)\n", strerror(errno),errno);
exit(0);
}
memset(&servaddr, 0, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_port = htons(6666);
if( inet_pton(AF_INET, argv[1], &servaddr.sin_addr) <= 0){
printf("inet_pton error for %s\n",argv[1]);
exit(0);
}
if( connect(sockfd, (struct sockaddr*)&servaddr, sizeof(servaddr)) < 0){
printf("connect error: %s(errno: %d)\n",strerror(errno),errno);
exit(0);
}
printf("send msg to server: \n");
fgets(sendline, 4096, stdin);
if( send(sockfd, sendline, strlen(sendline), 0) < 0)
{
printf("send msg error: %s(errno: %d)\n", strerror(errno), errno);
exit(0);
}
close(sockfd);
exit(0);
}
ping命令原理
ping命令,ping在应用层,但是直接使用网络层的 ICMP 协议,跳过了传输层。
只能用ping命令测试ip,不能ping端口。
网络安全
加密算法
对称加密(DES/AES/SM1/SM4)
对称加密指的就是加密和解密使用同一个秘钥,所以叫做对称加密。对称加密只有一个秘钥,作为私钥。
安全的对称加密算法:AES(Advanced Encryption Standard)(密钥长度>=128bits)
不安全的对称加密算法:DES(Data Encryption Standard)、3DES、RC2、RC4
非对称加密(RSA/SM2)
非对称加密指的是:加密和解密使用不同的秘钥,一把作为公开的公钥,另一把作为私钥。公钥加密的信息,只有私钥才能解密。私钥加密的信息,只有公钥才能解密。
推荐使用密钥长度大于 2048 位的 RSA 加密算法,更安全。
即公钥加密,私钥解密,或私钥加密,公钥解密。
加密密码和解密密码是相对的,如果用加密密码加密那么只有解密密码才能解密,如果用解密密码加密则只有加密密码能解密,所以它们被称为密码对,其中的一个可以在网络上发送、公布,叫做公钥,而另一个则只有密钥对的所有人才持有,叫做私钥,私钥不以任何形式传播。
非对称加密算法需要两个密钥:公开密钥(public key)和私有密钥(private key)。公开密钥与私有密钥是一对,如果用公开密钥对数据进行加密,只有用对应的私有密钥才能解密;如果用私有密钥对数据进行加密,那么只有用对应的公开密钥才能解密。因为加密和解密使用的是两个不同的密钥,所以这种算法叫作非对称加密算法。
非对称加密算法实现机密信息交换的基本过程是:
甲方生成一对密钥并将其中的一把作为公用密钥向其它方公开;得到该公用密钥的乙方使用该密钥对机密信息进行加密后再发送给甲方;甲方再用自己保存的另一把专用密钥对加密后的信息进行解密。
另一方面,甲方可以使用自己的私密钥对机密信息进行加密后再发送给乙方;乙方再用甲方的公钥对加密后的信息进行解密。
使用过程:
乙方生成两把密钥(公钥和私钥)
甲方获取乙方的公钥,然后用它对信息加密。
乙方得到加密后的信息,用私钥解密,乙方也可用私钥加密字符串
甲方获取乙方私钥加密数据,用公钥解密
非对称加密的好处在于,现在A可以保留private key,通过网络传递public key。这样,就算public key被C拦截了,因为没有private key,C还是没有办法完成信息的破解。既然不怕C知道public key,那现在A和B不用再见面商量密钥,直接通过网络传递public key就行。
常见的非对称加密算法:RSA,ECC
对称加密和非对称加密对比
1、对称加密算法加密速度快、加密效率高
非对称加密算法速度慢
2、对称加密的密钥管理不安全,尤其是涉及到网络通信时。
在数据传送前,发送方和接收方必须商定好秘钥,然后双方都必须要保存好秘钥,如果一方的秘钥被泄露,那么加密信息也就不安全了。
对称加密和非对称加密结合使用
在实际的网络环境中,会将两者混合使用:
例如针对C/S模型,
1、服务端计算出一对秘钥pub/pri。将私钥保密,将公钥公开。
2、客户端请求服务端时,拿到服务端的公钥pub。
3、客户端通过AES计算出一个对称加密的秘钥X。 然后使用pub将X进行加密。
4、客户端将加密后的密文发送给服务端。服务端通过pri解密获得X。
5、然后两边的通讯内容就通过对称密钥X以对称加密算法来加解密。
非对称加密算法比对称加密算法要复杂的多,处理起来也要慢得多。如果所有的网络数据都用非对称加密算法来加密,那效率会很低。所以在实际中,非对称加密只会用来传递一条信息,那就是用于对称加密的密钥。当用于对称加密的密钥确定了,A和B还是通过对称加密算法进行网络通信。这样,既保证了网络通信的安全性,又不影响效率,A和B也不用见面商量密钥了。
对称加密与非对称加密,以及RSA的原理
https://blog.csdn.net/u014079662/article/details/61169607
信息摘要(MD5/SHA/SM3)
信息摘要是一个唯一对应一个消息或文本的固定长度的值,它由一个单向Hash加密函数对消息进行作用而产生。如果消息在途中改变了,则接收者通过对收到消息的新产生的摘要与原摘要比较,就可知道消息是否被改变了。因此消息摘要保证了消息的完整性。消息摘要采用单向Hash 函数将需加密的明文”摘要”成一串密文,这一串密文亦称为数字指纹(Finger Print)。它有固定的长度,且不同的明文摘要成密文,其结果总是不同的,而同样的明文其摘要必定一致。这样这串摘要便可成为验证明文是否是”真身”的”指纹”了。
消息摘要,其实就是将需要摘要的数据作为参数,经过哈希函数(Hash)的计算,得到的散列值。
消息摘要具有以下特点:
(1)唯一性:数据只要有一点改变,那么再通过消息摘要算法得到的摘要也会发生变化。虽然理论上有可能会发生碰撞,但是概率极其低。
(2)不可逆:消息摘要算法的密文无法被解密。
(3)不需要密钥,可使用于分布式网络。
(4)无论输入的明文有多长,计算出来的消息摘要的长度总是固定的。
常用算法
消息摘要算法包括MD(Message Digest,消息摘要算法)、SHA(Secure Hash Algorithm,安全散列算法)、MAC(Message AuthenticationCode,消息认证码算法)共3大系列,常用于验证数据的完整性,是数字签名算法的核心算法。
MD5和SHA1分别是MD、SHA算法系列中最有代表性的算法。
如今,MD5已被发现有许多漏洞,从而不再安全。SHA算法比MD算法的摘要长度更长,也更加安全。
Java生成MD5和SHA信息摘要
JDK中使用MD5和SHA这两种消息摘要的方式基本一致,步骤如下:
(1)初始化MessageDigest对象
(2)更新要计算的内容
(3)生成摘要
import java.io.UnsupportedEncodingException;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import org.apache.commons.codec.binary.Base64;
public class MsgDigestDemo {
public static void main(String args[]) throws NoSuchAlgorithmException, UnsupportedEncodingException {
String msg = "Hello World!";
MessageDigest md5Digest = MessageDigest.getInstance("MD5");
// 更新要计算的内容
md5Digest.update(msg.getBytes());
// 完成哈希计算,得到摘要
byte[] md5Encoded = md5Digest.digest();
MessageDigest shaDigest = MessageDigest.getInstance("SHA");
// 更新要计算的内容
shaDigest.update(msg.getBytes());
// 完成哈希计算,得到摘要
byte[] shaEncoded = shaDigest.digest();
System.out.println("原文: " + msg);
System.out.println("MD5摘要: " + Base64.encodeBase64URLSafeString(md5Encoded));
System.out.println("SHA摘要: " + Base64.encodeBase64URLSafeString(shaEncoded));
}
}
[Java 安全]消息摘要与数字签名
https://www.cnblogs.com/jingmoxukong/p/5700906.html
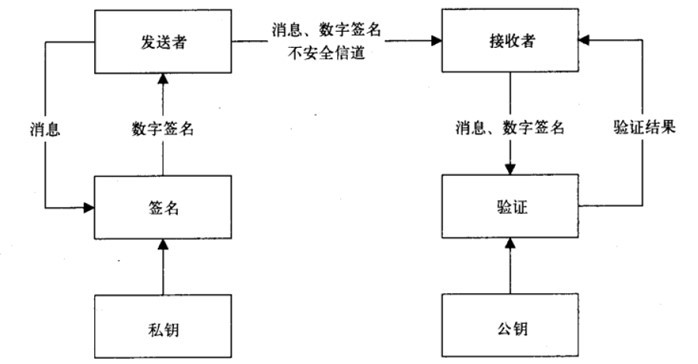
数字签名(摘要加密后就是签名)
数字签名算法可以看做是一种带有密钥的消息摘要算法,并且这种密钥包含了公钥和私钥。也就是说,数字签名算法是非对称加密算法和消息摘要算法的结合体。
数字签名是由信本身的内容经过hash算法计算得到digest摘要,然后用A的私钥加密而来的。
签名,使用私钥对需要传输的文本的摘要进行加密,得到的密文即被称为该次传输过程的签名。
特点
数字签名算法要求能够验证数据完整性、认证数据来源,并起到抗否认的作用。
原理
数字签名算法包含签名和验证两项操作,遵循私钥签名,公钥验证的方式。
签名时要使用私钥和待签名数据,验证时则需要公钥、签名值和待签名数据,其核心算法主要是消息摘要算法。
跳跃表
常用算法
RSA、DSA、ECDSA
Java实现数字签名和验证
签名
用私钥为消息计算签名
验证
用公钥验证摘要
import java.security.KeyFactory;
import java.security.KeyPair;
import java.security.KeyPairGenerator;
import java.security.PrivateKey;
import java.security.PublicKey;
import java.security.Signature;
import java.security.spec.PKCS8EncodedKeySpec;
import java.security.spec.X509EncodedKeySpec;
import org.apache.commons.codec.binary.Base64;
public class DsaCoder{
public static final String KEY_ALGORITHM = "DSA";
public enum DsaTypeEn {
MD5withDSA, SHA1withDSA
}
/**
* DSA密钥长度默认1024位。 密钥长度必须是64的整数倍,范围在512~1024之间
*/
private static final int KEY_SIZE = 1024;
private KeyPair keyPair;
public DsaCoder() throws Exception {
keyPair = initKey();
}
public byte[] signature(byte[] data, byte[] privateKey) throws Exception {
PKCS8EncodedKeySpec keySpec = new PKCS8EncodedKeySpec(privateKey);
KeyFactory keyFactory = KeyFactory.getInstance(KEY_ALGORITHM);
PrivateKey key =keyFactory.generatePrivate(keySpec);
Signature signature = Signature.getInstance(DsaTypeEn.SHA1withDSA.name());
signature.initSign(key);
signature.update(data);
return signature.sign();
}
public boolean verify(byte[] data, byte[] publicKey, byte[] sign) throws Exception {
X509EncodedKeySpec keySpec = new X509EncodedKeySpec(publicKey);
KeyFactory keyFactory = KeyFactory.getInstance(KEY_ALGORITHM);
PublicKey key =keyFactory.generatePublic(keySpec);
Signature signature = Signature.getInstance(DsaTypeEn.SHA1withDSA.name());
signature.initVerify(key);
signature.update(data);
return signature.verify(sign);
}
private KeyPair initKey() throws Exception {
// 初始化密钥对生成器
KeyPairGenerator keyPairGen = KeyPairGenerator.getInstance(KEY_ALGORITHM);
// 实例化密钥对生成器
keyPairGen.initialize(KEY_SIZE);
// 实例化密钥对
return keyPairGen.genKeyPair();
}
public byte[] getPublicKey() {
return keyPair.getPublic().getEncoded();
}
public byte[] getPrivateKey() {
return keyPair.getPrivate().getEncoded();
}
public static void main(String[] args) throws Exception {
String msg = "Hello World";
DsaCoder dsa = new DsaCoder();
byte[] sign = dsa.signature(msg.getBytes(), dsa.getPrivateKey());
boolean flag = dsa.verify(msg.getBytes(), dsa.getPublicKey(), sign);
String result = flag ? "数字签名匹配" : "数字签名不匹配";
System.out.println("数字签名:" + Base64.encodeBase64URLSafeString(sign));
System.out.println("验证结果:" + result);
}
}
[Java 安全]消息摘要与数字签名
https://www.cnblogs.com/jingmoxukong/p/5700906.html
数字证书(经过CA认证的加密的公钥)
数字签名是由信本身的内容经过hash算法计算得到digest摘要,然后用A的私钥加密而来的。
数字证书是A向数字证书中心(CA)申请的,是由A的个人信息,公钥等经过CA的私钥加密而来的。
什么是数字证书?
经CA认证加密后的公钥,即是证书,又称为CA证书,证书中包含了很多信息,最重要的是申请者的公钥。
假设A给B写一份信。那么这封将包含如下三部分内容:
1.信本身的内容(直接可以看到,未加密)
2.A的数字签名
3.A的数字证书
然后B收到了这封信。B会想这封确定是A发过来的吗?这封信在发送过程中有被篡改,还是完整的吗?只有当B确认清楚,才能判断出信的内容是否可靠。
然后B先用CA提供的公钥解开数字证书,根据得到的内容如A的个人信息,确定是A发过来的,然后拿到了A的公钥。
接着,用A的公钥解开A的数字签名就能得到,信本身内容的摘要。然后将信的第一部分即信的本身内容经hash计算得到又一个摘要,将两个摘要比较,如果相同说明信的内容没有被篡改。
最后,便能确定信的可靠性了。
公钥,私钥,数字签名,数字证书个人总结
https://blog.csdn.net/sum_rain/article/details/36897095
为什么需要数字证书?
首先要知道数字签名的验证过程:
签名验证,数据接收端,拿到传输文本,但是需要确认该文本是否就是发送发出的内容,中途是否曾经被篡改。因此拿自己持有的发送方公钥对签名进行解密,得到了文本的摘要,然后使用与发送方同样的HASH算法计算摘要值,再与解密得到的摘要做对比,发现二 者完全一致,则说明文本没有被篡改过。
1、在签名验证的过程中,有一点很关键,收到数据的一方,需要自己保管好公钥,但是要知道每一个发送方都有一个公钥,那么接收数据的人需要保存非常多的公钥,这根本 就管理不过来。
2、并且本地保存的公钥有可能被篡改替换,无从发现。
怎么解决这一问题了?
由一个统一的证书管理机构来管理所有需要发送数据方的公钥,对公钥进 行认证和加密。这个机构也就是我们常说的CA。认证加密后的公钥,即是证书,又称为CA证书,证书中包含了很多信息,最重要的是申请者的公钥。
CA 机构在给公钥加密时,用的是一个统一的密钥对,在加密公钥时,用的是其中的私钥。这样,申请者拿到证书后,在发送数据时,用自己的私钥生成签名,将签名、 证书和发送内容一起发给对方,对方拿到了证书后,需要对证书解密以获取到证书中的公钥,解密需要用到CA机构的”统一密钥对“中的公钥,这个公钥也就是我 们常说的CA根证书,通常需要我们到证书颁发机构去下载并安装到相应的收取数据的客户端,如浏览器上面。这个公钥只需要安装一次。有了这个公钥之后,就可 以解密证书,拿到发送方的公钥,然后解密发送方发过来的签名,获取摘要,重新计算摘要,作对比,以验证数据内容的完整性。
公钥私钥加密解密数字证书数字签名详解
https://www.cnblogs.com/kex1n/p/5582530.html
HTTPS
SM2 国密非对称加密算法
SM2(ShangMi2)是国家密码管理局发布的椭圆曲线公钥密码算法。
SM2 非对称加密的结果由 C1,C2,C3 三部分组成:
- C1 是根据生成的随机数计算出的椭圆曲线点
- C2 是密文数据
- C3 是SM3的摘要值
旧的国密标准的结果是按 C1,C2,C3 顺序存放的,新标准的是按 C1,C3,C2 顺序存放的
SM2 在线加解密
https://the-x.cn/cryptography/Sm2.aspx 解密好用
https://www.lzltool.com/SM2 可生成密钥对
SM2 国密算法 Java 实现
1、hutool
// 密码解密后加盐 md5存储
private String passwordSalt(String salt, String password) {
return md5(salt.concat(sm2Decrypt(password)));
}
// 解密
private String sm2Decrypt(String encrypted) {
SM2 sm2 = SmUtil.sm2(sm2PrivateKey("私钥"), "公钥");
return new String(sm2.decryptFromBcd(sm2EncryptedText(encrypted), KeyType.PrivateKey));
}
// 私钥前加00
private String sm2PrivateKey(String privateKey) {
return "00" + privateKey;
}
// 密文前加04
private String sm2EncryptedText(String cipherText) {
return "04" + cipherText;
}
2、sm-crypto
https://gitee.com/mezu/sm-crypto
// cipherMode 1 - C1C3C2,0 - C1C2C3,默认为1
String encryptData = Sm2.doEncrypt(msg, publicKey); // 加密结果
String decryptData = Sm2.doDecrypt(encryptData, privateKey); // 解密结果
使用时报错了:
Caused by: java.lang.NullPointerException: Cannot invoke "javax.script.ScriptEngine.eval(java.io.Reader)" because "engine" is null
at com.antherd.smcrypto.sm2.Sm2.<clinit>(Sm2.java:21)
解密报错 Invalid point encoding 0x-75
背景:
Postman 通过 js 脚本 用 sm2 公钥对注册接口的 password 字段加密,java controller 中 hutool 用对应的私钥对 password 字段解密
问题:
解密报错
java.lang.IllegalArgumentException: Invalid point encoding 0x-75
at org.bouncycastle.math.ec.ECCurve.decodePoint(ECCurve.java:443)
at org.bouncycastle.crypto.engines.SM2Engine.decrypt(Unknown Source)
at org.bouncycastle.crypto.engines.SM2Engine.processBlock(Unknown Source)
at cn.hutool.crypto.asymmetric.SM2.decrypt(SM2.java:299)
解决:
java 代码进行 sm2 解密时,私钥前加00,密文前加04
私钥前加00,密文前加04,公钥前加04
Java 代码进行 sm2 加解密时,需要在私钥前加00,密文前加04,公钥前加04
SM2私钥解密文件报错Invalid point encoding 0x30
https://gitee.com/dromara/hutool/issues/I3AEPJ
再探国密,SM2和SM4实现的数字信封对接国企
https://www.cnblogs.com/lylhqy/p/15693757.html
SM2 国密算法 js 实现
https://gitee.com/mezu/sm-crypto-js
Postman js 实现 SM2 加解密
postman实现sm2加解密
https://zhuanlan.zhihu.com/p/674363410
国内使用时 https://raw.githubusercontent.com/JuneAndGreen/sm-crypto/master/dist/sm2.js 经常连不上导致 js 脚本拉不下来
替换为 https://gitee.com/mezu/sm-crypto-js/raw/master/dist/sm2.js 更稳定
// 加载sm2.js
pm.sendRequest("https://raw.githubusercontent.com/JuneAndGreen/sm-crypto/master/dist/sm2.js", (err, res) => {
pm.collectionVariables.set("sm2js", res.text());
eval(pm.collectionVariables.get("sm2js"));
// 自动生成公钥私钥
// var keypair = this.sm2.generateKeyPairHex();
// var publicKey = keypair.publicKey;
// var privateKey = keypair.privateKey;
// 指定公钥私钥
var publicKey = "04c33e2ea7e5025b8fa2ebd0356c6105e357791af551d8c0cbcaca8035debd6fa2d42b71a84e246d4c732f592ad3a8e6ed7e69bec1ce68984cade59919d8edbdbc";
var privateKey = "04eacd3f3debeef3839cb2fd10c6eec3501cad00d0c5a5ee3e25ec135c2a372f";
console.log("公钥:", publicKey);
console.log("私钥:", privateKey);
console.log(`原始请求body: ${pm.request.body.raw}`);
var requestBody = JSON.parse(pm.request.body.raw);
var plaintext = requestBody.Password;
console.log('要加密的内容:', plaintext);
// 使用公钥加密,C1C3C2
var ciphertext = this.sm2.doEncrypt(plaintext, publicKey);
console.log('加密后的密文:', ciphertext);
// 使用私钥解密
var decrypted = this.sm2.doDecrypt(ciphertext, privateKey);
console.log("解密后的明文:", decrypted);
requestBody.Password = ciphertext; // 更新 Password 字段
pm.request.body.raw = JSON.stringify(requestBody); // 更新请求body
})
SM3 国密杂凑算法
SM3 杂凑值在线计算
https://the-x.cn/hash/ShangMi3Algorithm.aspx
https://lzltool.com/SM3
计算文件的 SM3
https://www.btool.cn/file-sm3
SM3 js 实现
https://gitee.com/mezu/sm-crypto-js/
const sm3 = require('sm-crypto').sm3;
var hashData = sm3('要计算sm3的文本'); // 杂凑
Postman js 实现 SM3 杂凑签名
// 获取排序后的query string
function getSortedQueryString() {
queryList = pm.request.url.query.all();
let normalizedQueryList = [];
for (let i = 0; i < queryList.length; i++) {
normalizedQueryList.push(queryList[i].key + "=" + queryList[i].value);
}
normalizedQueryList.sort();
return normalizedQueryList.join('&');
}
function sortObjectKeys(obj) {
return Object
.keys(obj)
.sort()
.reduce((acc, key) => {
if (typeof obj[key] === 'object' && !Array.isArray(obj[key]) && obj[key] !== null) {
acc[key] = sortObjectKeys(obj[key]);
} else {
acc[key] = obj[key];
}
return acc;
}, {});
}
// 获取按key排序后的序列化json串
function sortedJsonStringify(obj) {
const sortedObj = sortObjectKeys(obj);
return JSON.stringify(sortedObj);
}
// 加载sm3.js
pm.sendRequest("https://gitee.com/mezu/sm-crypto-js/raw/master/dist/sm3.js", (err, res) => {
pm.collectionVariables.set("sm3js", res.text());
eval(pm.collectionVariables.get("sm3js"));
var token = "xxxxxxxxxxxxxxxxxxxxxxxxx";
var queryStr = getSortedQueryString(); // 获取排序后的query string
var bodyJson = JSON.parse(pm.request.body.raw);
var bodyJsonStr = sortedJsonStringify(bodyJson); // 获取key有序的json序列化串
var deviceId = bodyJson["Code"];
console.log(`token: ${token}, deviceId: ${deviceId}, queryStr: ${queryStr}, bodyJsonStr: ${bodyJsonStr}`);
// 签名文本=token+设备或平台编码+排序查询字符串+请求体信息
var text = token+deviceId+queryStr+bodyJsonStr;
console.log('sm3 待签名文本:', text);
var sm3HexStr = this.sm3(text); // 结果是十六进制字符串
console.log('sm3 签名十六进制值:', sm3HexStr);
const crypto = require('crypto-js');
var sign = crypto.enc.Base64.stringify(crypto.enc.Hex.parse(sm3HexStr));
console.log('sm3 签名base64值:', sign);
pm.request.headers.upsert({key: "Signature", value: sm3HexStr}); // 使用hex str
pm.request.headers.upsert({key: "DeviceID", value: deviceId});
})
Java 实现 SM3 杂凑
直接使用 hutool 提供的工具类
cn.hutool.crypto.SmUtil.sm3(content);
Python 实现 SM3 杂凑
cryptography 35.0.0 已支持国密SM3/SM4
import argparse
import os
from cryptography.hazmat.primitives import hashes
from cryptography.hazmat.backends import default_backend
def get_sm3_file(filename, block_size=4 * 1024 * 1024):
file_size = os.path.getsize(filename)
processed = 0
algorithm = hashes.SM3()
digest = hashes.Hash(algorithm, backend=default_backend())
with open(filename, 'rb') as f:
while True:
chunk = f.read(block_size)
if not chunk:
break
digest.update(chunk)
processed += len(chunk)
print(f"\r进度: {processed * 100 / file_size :.2f}%", end="", flush=True)
print() # 换行
return digest.finalize().hex().upper()
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="计算文件的 SM3 杂凑值")
parser.add_argument("file", type=str, nargs="?", help='要处理的文件路径')
args = parser.parse_args()
file = args.file if args.file else 'calc_sm3.py'
hash_value = get_sm3_file(file)
print(f"{file} SM3 杂凑值: {hash_value}")
上一篇 面试准备15-算法
下一篇 面试准备13-操作系统
页面信息
location:protocol: host: hostname: origin: pathname: href: document:referrer: navigator:platform: userAgent: