Redis-安装部署运维
Redis 相关笔记
redis官方命令手册
https://redis.io/commands
redis官方文档
https://redis.io/documentation
Redis 命令参考
http://doc.redisfans.com/index.html
《Redis 设计与实现》(第一版)
https://redisbook.readthedocs.io/en/latest/index.html
Redis中文官网 - redis文档中心
http://www.redis.cn/documentation.html
redis中文网 - redis教程
http://www.redis.net.cn/tutorial/3501.html
《今天面试了吗》-Redis
https://juejin.im/post/5dccf260f265da0bf66b626d
Redis部署
Redis单例、主从模式、sentinel以及集群的配置方式及优缺点对比
https://mp.weixin.qq.com/s/jg4wzsiBGkm0B9SWYDGVbw
单点
master/slave主从模式
主从复制
Redis 支持简单且易用的主从复制(master-slave replication)功能, 该功能可以让从服务器(slave server)成为主服务器(master server)的精确复制品。
一个主服务器可以有多个从服务器。
不仅主服务器可以有从服务器, 从服务器也可以有自己的从服务器, 多个从服务器之间可以构成一个图状结构。
复制功能不会阻塞主服务器: 即使有一个或多个从服务器正在进行初次同步, 主服务器也可以继续处理命令请求。
Redis主从同步策略
主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。当然,如果有需要,slave 在任何时候都可以发起全量同步。redis 策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
slave启动时全量复制
Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份。具体步骤如下:
1)从服务器连接主服务器,发送SYNC命令;
2)主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
3)主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
4)从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
5)主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
6)从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;
完成上面几个步骤后就完成了从服务器数据初始化的所有操作,从服务器此时可以接收来自用户的读请求。
即使有多个从服务器同时向主服务器发送 SYNC , 主服务器也只需执行一次 BGSAVE 命令, 就可以处理所有这些从服务器的同步请求。
slave运行中增量同步
Redis增量复制是指Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。
增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
Redis主从复制原理
https://www.cnblogs.com/hepingqingfeng/p/7263782.html
部分重同步(2.8之后,psync)
从服务器可以在主从服务器之间的连接断开时进行自动重连, 在 Redis 2.8 版本之前, 断线之后重连的从服务器总要执行一次完整重同步(full resynchronization)操作, 但是从 Redis 2.8 版本开始, 从服务器可以根据主服务器的情况来选择执行完整重同步还是部分重同步(partial resynchronization)。
从 Redis 2.8 开始, 在网络连接短暂性失效之后, 主从服务器可以尝试继续执行原有的复制进程(process), 而不一定要执行完整重同步操作。
这个特性需要主服务器为被发送的复制流创建一个内存缓冲区(in-memory backlog), 并且主服务器和所有从服务器之间都记录一个 复制偏移量(replication offset) 和一个 **主服务器 ID(master run id)**, 当出现网络连接断开时, 从服务器会重新连接, 并且向主服务器请求继续执行原来的复制进程:
- 如果从服务器记录的主服务器 ID 和当前要连接的主服务器的 ID 相同, 并且从服务器记录的偏移量所指定的数据仍然保存在主服务器的复制流缓冲区里面, 那么主服务器会向从服务器发送断线时缺失的那部分数据, 然后复制工作可以继续执行。
- 否则的话, 从服务器就要执行完整重同步操作。
Redis 2.8 的这个部分重同步特性会用到一个新增的 PSYNC 内部命令, 而 Redis 2.8 以前的旧版本只有 SYNC 命令, 不过, 只要从服务器是 Redis 2.8 或以上的版本, 它就会根据主服务器的版本来决定到底是使用 PSYNC 还是 SYNC :
如果主服务器是 Redis 2.8 或以上版本,那么从服务器使用 PSYNC 命令来进行同步。
如果主服务器是 Redis 2.8 之前的版本,那么从服务器使用 SYNC 命令来进行同步。
复制(Replication)
http://doc.redisfans.com/topic/replication.html
redis不保证主从的强一致性
Redis采用了乐观复制(optimistic replication)的复制策略,容忍在一定时间内主从库的内容是不同的,但是两者的数据会最终同步。
具体来说,Redis在主从库之间复制数据的过程本身是异步的,这意味着,主库执行完客户端请求的命令后会立即将命令在主库的执行结果返回给客户端,并异步地将命令同步给从库,而不会等待从库接收到该命令后再返回给客户端。
这一特性保证了启用复制后主库的性能不会受到影响,但另一方面也会产生一个主从库数据不一致的时间窗口,当主库执行了一条写命令后,主库的数据已经发生的变动,然而在主库将该命令传送给从库之前,如果两个数据库之间的网络连接断开了,此时二者之间的数据就会是不一致的。
从这个角度来看,主库是无法得知某个命令最终同步给了多少个从库的,不过 Redis 提供了两个配置选项,来限制只有当数据至少同步给指定数量的从库时,主库才是可写的:
min-slaves-to-write 3
min-slaves-max-lag 10
min-slaves-to-write 表示只有当3个(或以上)的从库连接到主库时,主库才是可写的,否则会返回错误:
min-slaves-max-lag 表示允许从库最长失去连接的时间,如果从库最后与主库联系(即发送“replconf ack”命令)的时间小于这个值,则认为从库还在保持与主库的连接。
举个例子,按上面的配置,假设主库与3个从库相连,其中一个从库上一次与主库联系是 9 秒前,这时主库可以正常接受写入,一旦1秒过后这台从库依旧没有活动,则主库则认为目前连接的从库只有2个,从而拒绝写入。这一特性默认是关闭的,在分布式系统中,打开并合理配置该选项后可以降低主从架构中因为网络分区导致的数据不一致的问题。
07Redis入门指南笔记(主从复制、哨兵)
https://blog.csdn.net/gqtcgq/article/details/50273431
sentinel哨兵模式
Redis 的 Sentinel 系统用于管理多个 Redis 服务器(instance), 该系统执行以下三个任务:
- 监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
- 提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
- 自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
启动sentinel
对于 redis-sentinel 程序, 你可以用以下命令来启动 Sentinel 系统:
redis-sentinel /path/to/sentinel.conf
对于 redis-server 程序, 你可以用以下命令来启动一个运行在 Sentinel 模式下的 Redis 服务器:
redis-server /path/to/sentinel.conf –sentinel
两种方法都可以启动一个 Sentinel 实例。
启动 Sentinel 实例必须指定相应的配置文件, 系统会使用配置文件来保存 Sentinel 的当前状态, 并在 Sentinel 重启时通过载入配置文件来进行状态还原。
如果启动 Sentinel 时没有指定相应的配置文件, 或者指定的配置文件不可写(not writable), 那么 Sentinel 会拒绝启动。
sentinel 选举与故障恢复过程
主观下线
Sentinel集群的每一个Sentinel节点会定时对redis集群的所有节点发心跳包检测节点是否正常。如果一个节点在 down-after-milliseconds 时间内没有回复Sentinel节点的心跳包,则该redis节点被该Sentinel节点主观下线。
如果服务器在给定的毫秒数之内, 没有返回 Sentinel 发送的 PING 命令的回复, 或者返回一个错误, 那么 Sentinel 将这个服务器标记为 主观下线(subjectively down,简称 SDOWN )。
sentinel down-after-milliseconds mymaster 60000
down-after-milliseconds 参数指定了 Sentinel 认为服务器已经断线所需的毫秒数。
客观下线
不过只有一个 Sentinel 将服务器标记为主观下线并不一定会引起服务器的自动故障迁移: 只有在足够数量的 Sentinel 都将一个服务器标记为主观下线之后, 服务器才会被标记为 客观下线(objectively down, 简称 ODOWN ), 这时自动故障迁移才会执行。
将服务器标记为客观下线所需的 Sentinel 数量由对主服务器的配置决定。
主观下线(Subjectively Down, 简称 SDOWN)指的是单个 Sentinel 实例对服务器做出的下线判断。
客观下线(Objectively Down, 简称 ODOWN)指的是多个 Sentinel 实例在对同一个服务器做出 SDOWN 判断, 并且通过 SENTINEL is-master-down-by-addr 命令互相交流之后, 得出的服务器下线判断。 (一个 Sentinel 可以通过向另一个 Sentinel 发送 SENTINEL is-master-down-by-addr 命令来询问对方是否认为给定的服务器已下线。)
当节点被一个Sentinel节点记为主观下线时,并不意味着该节点肯定故障了,还需要Sentinel集群的其他Sentinel节点共同判断为主观下线才行。
该Sentinel节点会询问其他Sentinel节点,如果Sentinel集群中超过quorum数量的Sentinel节点认为该redis节点主观下线,则该redis客观下线。
如果客观下线的redis节点是从节点或者是Sentinel节点,则操作到此为止,没有后续的操作了;如果客观下线的redis节点为主节点,则开始故障转移,从从节点中选举一个节点升级为主节点。
Sentinel集群选举Leader
如果需要从redis集群选举一个节点为主节点,首先需要从Sentinel集群中选举一个Sentinel节点作为Leader。
每一个Sentinel节点都可以成为Leader,当一个Sentinel节点确认redis集群的主节点主观下线后,会请求其他Sentinel节点要求将自己选举为Leader。被请求的Sentinel节点如果没有同意过其他Sentinel节点的选举请求,则同意该请求(选举票数+1),否则不同意。
如果一个Sentinel节点获得的选举票数达到Leader最低票数(quorum和Sentinel节点数/2+1的最大值),则该Sentinel节点选举为Leader;否则重新进行选举。
sentinel leader 选举过程如下图:
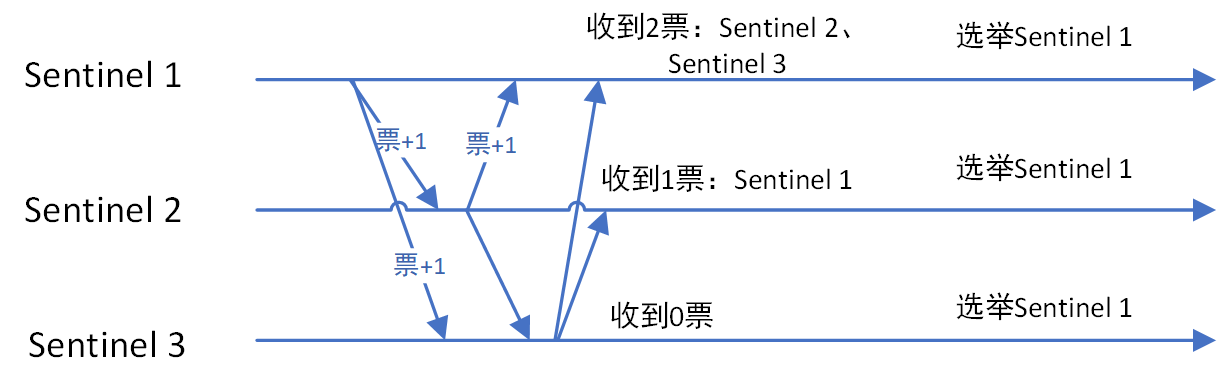
Sentinel Leader决定新主节点
当Sentinel集群选举出Sentinel Leader后,由Sentinel Leader从redis从节点中选择一个redis节点作为主节点:
1、过滤故障的节点
2、选择优先级 slave-priority 最大的从节点作为主节点,如不存在则继续
3、选择 复制偏移量(数据写入量的字节,记录写了多少数据。主服务器会把偏移量同步给从服务器,当主从的偏移量一致,则数据是完全同步)最大的从节点作为主节点,如不存在则继续
4、选择runid(redis每次启动的时候生成随机的runid作为redis的标识)最小的从节点作为主节点
sentinel选举是一种raft近似算法
Sentinel集群正常运行的时候每个节点epoch相同,当需要故障转移的时候会在集群中选出Leader执行故障转移操作。Sentinel采用了Raft协议实现了Sentinel间选举Leader的算法,不过也不完全跟论文描述的步骤一致。Sentinel集群运行过程中故障转移完成,所有Sentinel又会恢复平等。Leader仅仅是故障转移操作出现的角色。
选举流程
1、某个Sentinel认定master客观下线的节点后,该Sentinel会先看看自己有没有投过票,如果自己已经投过票给其他Sentinel了,在2倍故障转移的超时时间自己就不会成为Leader。相当于它是一个Follower。
2、如果该Sentinel还没投过票,那么它就成为Candidate。
3、和Raft协议描述的一样,成为Candidate,Sentinel需要完成几件事情
1)更新故障转移状态为start
2)当前epoch加1,相当于进入一个新term,在Sentinel中epoch就是Raft协议中的term。
3)更新自己的超时时间为当前时间随机加上一段时间,随机时间为1s内的随机毫秒数。
4)向其他节点发送is-master-down-by-addr命令请求投票。命令会带上自己的epoch。
5)给自己投一票,在Sentinel中,投票的方式是把自己master结构体里的leader和leader_epoch改成投给的Sentinel和它的epoch。
4、其他Sentinel会收到Candidate的is-master-down-by-addr命令。如果Sentinel当前epoch和Candidate传给他的epoch一样,说明他已经把自己master结构体里的leader和leader_epoch改成其他Candidate,相当于把票投给了其他Candidate。投过票给别的Sentinel后,在当前epoch内自己就只能成为Follower。
5、Candidate会不断的统计自己的票数,直到他发现认同他成为Leader的票数超过一半而且超过它配置的quorum(quorum可以参考《redis sentinel设计与实现》)。Sentinel比Raft协议增加了quorum,这样一个Sentinel能否当选Leader还取决于它配置的quorum。
6、如果在一个选举时间内,Candidate没有获得超过一半且超过它配置的quorum的票数,自己的这次选举就失败了。
7、如果在一个epoch内,没有一个Candidate获得更多的票数。那么等待超过2倍故障转移的超时时间后,Candidate增加epoch重新投票。
8、如果某个Candidate获得超过一半且超过它配置的quorum的票数,那么它就成为了Leader。
9、与Raft协议不同,Leader并不会把自己成为Leader的消息发给其他Sentinel。其他Sentinel等待Leader从slave选出master后,检测到新的master正常工作后,就会去掉客观下线的标识,从而不需要进入故障转移流程。
主从切换后如何知道master的ip?
主从切换后,master ip变了,如何知道往哪个里面写入?
java后台使用jedis来操作redis,配置一个JedisSentinelPool,传入sentinel哨兵集群中每个节点的地址,JedisSentinelPool初始化时会与所有sentinel沟通,确定当前sentinel集群所监视的master是哪一个。主从切换后通过sentinel集群还能读出新的master的地址,所以写入不会出错。
sentinel如何知道其他sentinel的存在?(发布订阅)
一个 Sentinel 可以与其他多个 Sentinel 进行连接, 各个 Sentinel 之间可以互相检查对方的可用性, 并进行信息交换。
你无须为运行的每个 Sentinel 分别设置其他 Sentinel 的地址, 因为 Sentinel 可以通过发布与订阅功能来自动发现正在监视相同主服务器的其他 Sentinel , 这一功能是通过向频道 sentinel:hello 发送信息来实现的。
与此类似, 你也不必手动列出主服务器属下的所有从服务器, 因为 Sentinel 可以通过询问主服务器来获得所有从服务器的信息。
- 每个 Sentinel 会以每两秒一次的频率, 通过发布与订阅功能, 向被它监视的所有主服务器和从服务器的 sentinel:hello 频道发送一条信息, 信息中包含了 Sentinel 的 IP 地址、端口号和运行 ID (runid)。
- 每个 Sentinel 都订阅了被它监视的所有主服务器和从服务器的 sentinel:hello 频道, 查找之前未出现过的 sentinel (looking for unknown sentinels)。 当一个 Sentinel 发现一个新的 Sentinel 时, 它会将新的 Sentinel 添加到一个列表中, 这个列表保存了 Sentinel 已知的, 监视同一个主服务器的所有其他 Sentinel 。
- Sentinel 发送的信息中还包括完整的主服务器当前配置(configuration)。 如果一个 Sentinel 包含的主服务器配置比另一个 Sentinel 发送的配置要旧, 那么这个 Sentinel 会立即升级到新配置上。
- 在将一个新 Sentinel 添加到监视主服务器的列表上面之前, Sentinel 会先检查列表中是否已经包含了和要添加的 Sentinel 拥有相同运行 ID 或者相同地址(包括 IP 地址和端口号)的 Sentinel , 如果是的话, Sentinel 会先移除列表中已有的那些拥有相同运行 ID 或者相同地址的 Sentinel , 然后再添加新 Sentinel 。
cluster集群模式(3.0之后)
redis 集群分为服务端集群和客户端分片,redis3.0 以上版本实现了集群机制,即服务端集群,3.0 以下使用客户端分片(Sharding)。
Redis Cluster 是一种服务器 Sharding 技术,3.0 版本开始正式提供。
Redis 集群使用数据分片(sharding)而非一致性哈希(consistency hashing)来实现
Redis Cluster 中,Sharding采用slot(槽)的概念,一共分成16384个槽,这有点儿类 pre sharding 思路。对于每个进入 Redis 的键值对,根据 key 进行散列,分配到这 16384 个slot 中的某一个中。使用的 hash 算法也比较简单,就是 CRC16 后 16384 取模。
HASH_SLOT = CRC16(key) mod 16384
Redis集群中的每个node(节点)负责分摊这16384个slot中的一部分,也就是说,每个 slot 都对应一个 node 负责处理。
集群中的每个节点负责处理一部分哈希槽。 举个例子,一个集群可以有三个结点, 其中:
节点 A 负责处理 0 号至 5500 号哈希槽。
节点 B 负责处理 5501 号至 11000 号哈希槽。
节点 C 负责处理 11001 号至 16384 号哈希槽。
redis集群增减结点的操作步骤
当动态添加或减少node节点时,需要将16384个槽做个再分配,槽中的键值也要迁移。当然,这一过程,在目前实现中,还处于半自动状态,需要人工介入:
1、如果用户将新节点 D 添加到集群中, 那么集群只需要将节点 A 、B 、 C 中的某些槽移动到节点 D 就可以了。
2、与此类似, 如果用户要从集群中移除节点 A , 那么集群只需要将节点 A 中的所有哈希槽移动到节点 B 和节点 C , 然后再移除空白(不包含任何哈希槽)的节点 A 就可以了。
因为将一个哈希槽从一个节点移动到另一个节点不会造成节点阻塞, 所以无论是添加新节点还是移除已存在节点, 又或者改变某个节点包含的哈希槽数量, 都不会造成集群下线。
Redis 集群中的主从复制
Redis集群,要保证16384个槽对应的node都正常工作,如果某个node发生故障,那它负责的slots也就失效,整个集群将不能工作。
为了增加集群的可访问性,官方推荐的方案是将node配置成主从结构,即一个master主节点,挂n个slave从节点。
这时,如果主节点失效,Redis Cluster会根据选举算法从slave节点中选择一个上升为主节点,整个集群继续对外提供服务。这非常类似前篇文章提到的Redis Sharding场景下服务器节点通过Sentinel监控架构成主从结构,只是Redis Cluster本身提供了故障转移容错的能力。
为了使得集群在一部分节点下线或者无法与集群的大多数(majority)节点进行通讯的情况下, 仍然可以正常运作, Redis 集群对节点使用了主从复制功能: 集群中的每个节点都有 1 个至 N 个复制品(replica), 其中一个复制品为主节点(master), 而其余的 N-1 个复制品为从节点(slave)。
在之前列举的节点 A 、B 、C 的例子中, 如果节点 B 下线了, 那么集群将无法正常运行, 因为集群找不到节点来处理 5501 号至 11000 号的哈希槽。
另一方面, 假如在创建集群的时候(或者至少在节点 B 下线之前), 我们为主节点 B 添加了从节点 B1 , 那么当主节点 B 下线的时候, 集群就会将 B1 设置为新的主节点, 并让它代替下线的主节点 B , 继续处理 5501 号至 11000 号的哈希槽, 这样集群就不会因为主节点 B 的下线而无法正常运作了。
不过如果节点 B 和 B1 都下线的话, Redis 集群还是会停止运作。
Redis Cluster的新节点识别能力、故障判断及故障转移能力是通过集群中的每个node都在和其它nodes进行通信,这被称为集群总线(cluster bus)。它们使用特殊的端口号,即对外服务端口号加10000。例如如果某个node的端口号是6379,那么它与其它nodes通信的端口号是16379。nodes之间的通信采用特殊的二进制协议。
对客户端来说,整个cluster被看做是一个整体,客户端可以连接任意一个node进行操作,就像操作单一Redis实例一样,当客户端操作的key没有分配到该node上时,Redis会返回转向指令,指向正确的node,这有点儿像浏览器页面的302 redirect跳转。
Redis Cluster是Redis 3.0以后才正式推出,时间较晚,目前能证明在大规模生产环境下成功的案例还不是很多,需要时间检验。
Redis 集群的一致性保证
Redis 集群不保证数据的强一致性(strong consistency): 在特定条件下, Redis 集群可能会丢失已经被执行过的写命令。
使用异步复制(asynchronous replication)是 Redis 集群可能会丢失写命令的其中一个原因。 考虑以下这个写命令的例子:
客户端向主节点 B 发送一条写命令。
主节点 B 执行写命令,并向客户端返回命令回复。
主节点 B 将刚刚执行的写命令复制给它的从节点 B1 、 B2 和 B3 。
如你所见, 主节点对命令的复制工作发生在返回命令回复之后, 因为如果每次处理命令请求都需要等待复制操作完成的话, 那么主节点处理命令请求的速度将极大地降低 —— 我们必须在性能和一致性之间做出权衡。
如果真的有必要的话, Redis 集群可能会在将来提供同步地(synchronou)执行写命令的方法。
网络分裂
Redis 集群另外一种可能会丢失命令的情况是, 集群出现网络分裂(network partition), 并且一个客户端与至少包括一个主节点在内的少数(minority)实例被孤立。
举个例子, 假设集群包含 A 、 B 、 C 、 A1 、 B1 、 C1 六个节点, 其中 A 、B 、C 为主节点, 而 A1 、B1 、C1 分别为三个主节点的从节点, 另外还有一个客户端 Z1 。
假设集群中发生网络分裂, 那么集群可能会分裂为两方, 大多数(majority)的一方包含节点 A 、C 、A1 、B1 和 C1 , 而少数(minority)的一方则包含节点 B 和客户端 Z1 。
在网络分裂期间, 主节点 B 仍然会接受 Z1 发送的写命令:
如果网络分裂出现的时间很短, 那么集群会继续正常运行;
但是, 如果网络分裂出现的时间足够长, 使得大多数一方将从节点 B1 设置为新的主节点, 并使用 B1 来代替原来的主节点 B , 那么 Z1 发送给主节点 B 的写命令将丢失。
注意, 在网络分裂出现期间, 客户端 Z1 可以向主节点 B 发送写命令的最大时间是有限制的, 这一时间限制称为节点超时时间(node timeout), 是 Redis 集群的一个重要的配置选项:
对于大多数一方来说, 如果一个主节点未能在节点超时时间所设定的时限内重新联系上集群, 那么集群会将这个主节点视为下线, 并使用从节点来代替这个主节点继续工作。
对于少数一方, 如果一个主节点未能在节点超时时间所设定的时限内重新联系上集群, 那么它将停止处理写命令, 并向客户端报告错误。
cluster集群的问题
存在如下限制:
- key批量操作支持有限。只支持具有相同slot值的key执行批量操作。
- 事务操作支持有限。只支持同一个节点上的多个key的事务操作。
- key是数据分区的最小粒度,因为不能讲一个大的键值对象,如hash,list等映射到不同的节点上。
- 不支持多数据库,单机下的Redis可以支持16个数据库,但集群之只能使用一个数据库空间,即db 0。
- 复制结构只支持一层,从节点只能复制主节点,不支持嵌套树状复制结构。
Failover的流程
一、主观下线
集群中每个节点都会定期向其他节点发送ping消息,接收节点回复pong消息作为响应。如果在cluster-node-timeout时间内通信一直失败,则发送节点会认为接收节点存在故障,把接收节点标记为主观下线(pfail)状态。
二、客观下线
当某个节点判断另一个节点主观下线后,相应的节点状态会跟随消息在集群内传播。通过Gossip消息传播,集群内节点不断收集到故障节点的下线报告。当半数以上持有槽的主节点都标记某个节点是主观下线时,触发客观下线流程。
集群中的节点每次接收到其他节点的pfail状态,都会尝试触发客观下线,流程说明:
- 首先统计有效的下线报告数量,如果小于集群内持有槽的主节点总数的一半则退出。
- 当下线报告大于槽主节点数量一半时,标记对应故障节点为客观下线状态。
- 向集群广播一条fail消息,通知所有的节点将故障节点标记为客观下线,fail消息的消息体只包含故障节点的ID。
广播fail消息是客观下线的最后一步,它承担着非常重要的职责:
- 通知集群内所有的节点标记故障节点为客观下线状态并立刻生效。
- 通知故障节点的从节点触发故障转移流程。
三、故障切换
故障节点变为客观下线后,如果下线节点是持有槽的主节点则需要在它的从节点中选出一个替换它,从而保证集群的高可用。下线主节点的所有从节点承担故障恢复的义务,当从节点通过内部定时任务发现自身复制的主节点进入客观下线时,将会触发故障切换流程。
1.资格检查
每个从节点都要检查最后与主节点断线时间,判断是否有资格替换故障的主节点。如果从节点与主节点断线时间超过cluster-node-time*cluster-slave-validity-factor,则当前从节点不具备故障转移资格。参数cluster-slavevalidity-factor用于从节点的有效因子,默认为10。
2.准备选举时间
当从节点符合故障切换资格后,更新触发切换选举的时间,只有到达该时间后才能执行后续流程。
这里之所以采用延迟触发机制,主要是通过对多个从节点使用不同的延迟选举时间来支持优先级问题。复制偏移量越大说明从节点延迟越低,那么它应该具有更高的优先级来替换故障主节点。
3.发起选举
当从节点定时任务检测到达故障选举时间(failover_auth_time)到达后,发起选举流程如下:
1> 更新配置纪元 epoch(相当于term加1)
2> 广播选举消息
在集群内广播选举消息(FAILOVER_AUTH_REQUEST),并记录已发送过消息的状态,保证该从节点在一个配置纪元内只能发起一次选举。
4.选举投票
只有持有槽的主节点才会处理故障选举消息(FAILOVER_AUTH_REQUEST),因为每个持有槽的节点在一个配置纪元内都有唯一的一张选票,当接到第一个请求投票的从节点消息时回复FAILOVER_AUTH_ACK消息作为投票,之后相同配置纪元内其他从节点的选举消息将忽略。
Redis集群没有直接使用从节点进行领导者选举,主要因为从节点数必须大于等于3个才能保证凑够N/2+1个节点,将导致从节点资源浪费。使用集群内所有持有槽的主节点进行领导者选举,即使只有一个从节点也可以完成选举过程。
5.替换主节点
当从节点收集到足够的选票之后,触发替换主节点操作:
1> 当前从节点取消复制变为主节点。
2> 执行clusterDelSlot操作撤销故障主节点负责的槽,并执行clusterAddSlot把这些槽委派给自己。
3> 向集群广播自己的pong消息,通知集群内所有的节点当前从节点变为主节点并接管了故障主节点的槽信息。
故障切换时间
在介绍完故障发现和恢复的流程后,我们估算下故障切换时间:
1> 主观下线(pfail)识别时间=cluster-node-timeout。
2> 主观下线状态消息传播时间<=cluster-node-timeout/2。消息通信机制对超过cluster-node-timeout/2未通信节点会发起ping消息,消息体在选择包含哪些节点时会优先选取下线状态节点,所以通常这段时间内能够收集到半数以上主节点的pfail报告从而完成故障发现。
3> 从节点转移时间<=1000毫秒。由于存在延迟发起选举机制,偏移量最大的从节点会最多延迟1秒发起选举。通常第一次选举就会成功,所以从节点执行转移时间在1秒以内。
根据以上分析可以预估出故障转移时间,如下:
failover-time(毫秒) ≤ cluster-node-timeout + cluster-node-timeout/2 + 1000
因此,故障转移时间跟cluster-node-timeout参数息息相关,默认15秒。
Redis Cluster的相关参数
cluster-enabled <yes/no>:是否开启集群模式。
cluster-config-file
cluster-node-timeout
cluster-slave-validity-factor
cluster-migration-barrier
cluster-require-full-coverage <yes/no>:默认情况下当集群中16384个槽,有任何一个没有指派到节点时,整个集群是不可用的。对应在线上,如果某个主节点宕机,而又没有从节点的话,是不允许对外提供服务的。建议将该参数设置为no,避免某个主节点的故障导致其它主节点不可用。
深入理解Redis Cluster
https://www.cnblogs.com/ivictor/p/9762394.html
Redis集群方案应该怎么做?
https://www.zhihu.com/question/21419897
集群教程(redis3.0官方集群方案)
http://doc.redisfans.com/topic/cluster-tutorial.html
集群模式中哪些命令不能用?(集群模式如何兼容multi key操作)
Redis 集群是在多个 Redis 节点之间进行数据共享,它 不支持跨结点的 multi-key 操作(即执行的命令需要在多个Redis节点之间移动数据,比如Set类型的并集、交集等(除非这些key属于同一个node),即Cluster不能进行跨Nodes操作。
Redis为了兼容 multi-key 操作,提供了“hash tags”操作,每个key可以包含自定义的“tags”,在存储的时候根据tags计算此key应该映射到哪个node上。通过“hash tags”可以强制某些keys被保存到同一个节点上,便于进行“multi key”操作。
集群模式下无法使用 select 选库
集群模式下 keys * 命令只能匹配本机上的键
集群模式下如何使用pipeline
redis-trib.rb
Redis 3.0 及其之后的版本提供了 redis-cluster 集群支持,用于在多个redis节点间共享数据,以提高服务的可用性。
构建 redis-cluster 集群可以通过 redis-trib.rb 工具来完成。redis-trib.rb 是redis官方提供的一个集群管理工具,集成在redis安装包的 src 目录下。redis-trib.rb 封装了redis提供的集群命令,使用简单、便捷。
因为 redis-trib.rb 是由ruby语言编写的,所以使用该工具需要ruby语言环境的支持。
create 创建集群
check 检查集群
info 查看集群信息
fix 修复集群
reshard 在线迁移slot
rebalance 平衡集群节点slot数量
add-node 添加新节点
del-node 删除节点
set-timeout 设置节点的超时时间
call 在集群所有节点上执行命令
import 将外部redis数据导入集群
redis-trib.rb create 创建集群
redis-trib.rb create --replicas 1 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384
--replicas 参数指定集群中每个主节点配备几个从节点
redis-cluster集群至少需要3个可用节点。
主从节点选择及槽分配算法
主从节点选择及槽分配算法如下:
1> 把节点按照host分类,这样保证master节点能分配到更多的主机中。
2> 遍历host列表,从每个host列表中弹出一个节点,放入interleaved数组。直到所有的节点都弹出为止。
3> 将interleaved数组中前master个数量的节点保存到masters数组中。
4> 计算每个master节点负责的slot数量,16384除以master数量取整,这里记为N。
5> 遍历masters数组,每个master分配N个slot,最后一个master,分配剩下的slot。
6> 接下来为master分配slave,分配算法会尽量保证master和slave节点不在同一台主机上。对于分配完指定slave数量的节点,还有多余的节点,也会为这些节点寻找master。分配算法会遍历两次masters数组。
7> 第一次遍历master数组,在余下的节点列表找到replicas数量个slave。每个slave为第一个和master节点host不一样的节点,如果没有不一样的节点,则直接取出余下列表的第一个节点。
8> 第二次遍历是分配节点数除以replicas不为整数而多出的一部分节点。
redis-trib.rb check 检查集群状态
redis-trib.rb check 127.0.0.1:6379
指定任意一个节点即可。
redis-trib.rb info 查看集群信息
redis-trib.rb info 127.0.0.1:6383
./redis-trib.rb info 127.0.0.1:6383
127.0.0.1:6380 (3b27d00d...) -> 0 keys | 5462 slots | 1 slaves.
127.0.0.1:6381 (d874f003...) -> 1 keys | 5461 slots | 1 slaves.
127.0.0.1:6379 (bc775f9c...) -> 0 keys | 5461 slots | 1 slaves.
[OK] 1 keys in 3 masters.
0.00 keys per slot on average.
redis-trib.rb reshard 在线迁移slot
redis-trib.rb reshard 127.0.0.1:6379 指定任意一个节点即可。
这是一个交互命令
1、它首先会提示需要迁移多个槽
How many slots do you want to move (from 1 to 16384)? 200
输入200。
2、接着它会提示需要将槽迁移到哪个节点
What is the receiving node ID? 3b27d00d13706a032a92ff6b0a914af272dcaaf2
这里必须写节点ID。
3、紧跟着它会提示槽从哪些节点中迁出。
Please enter all the source node IDs.
Type ‘all’ to use all the nodes as source nodes for the hash slots.
Type ‘done’ once you entered all the source nodes IDs.
如果指定为all,则待迁移的槽在剩余节点中平均分配,在这里,127.0.0.1:6379和127.0.0.1:6381各迁移100个槽出来。
也可从指定节点中迁出,这个时候,必须指定源节点的节点ID,最后以done结束
redis-trib.rb rebalance 平衡slot
平衡集群节点slot数量
redis-trib.rb del-node 删除节点
redis-trib.rb del-node host:port node_id
在删除节点之前,其对应的槽必须为空,所以,在进行节点删除动作之前,必须使用redis-trib.rb reshard将其迁移出去。
需要注意的是,如果某个节点的槽被完全迁移出去,其对应的slave也会随着更新,指向迁移的目标节点。
redis-trib add-node 添加新节点
redis-trib add-node new_host:new_port existing_host:existing_port --slave --master-id <arg>
new_host:new_port:待添加的节点,必须确保其为空或不在其它集群中。
existing_host:existing_port:集群中任意一个节点的地址。
如果添加的是主节点,只需指定源节点和目标节点的地址即可。
redis-trib.rb add-node 127.0.0.1:6379 127.0.0.1:6384
如果添加的是从节点,其语法如下,
redis-trib.rb add-node –slave –master-id f413fb7e6460308b17cdb71442798e1341b56cbc 127.0.0.1:6379 127.0.0.1:6384
所以,线上建议使用redis-trib.rb添加新节点,因为其会对新节点的状态进行检查。如果手动使用cluster meet命令加入已经存在于其它集群的节点,会造成被加入节点的集群合并到现有集群的情况,从而造成数据丢失和错乱,后果非常严重,线上谨慎操作。
redis-trib.rb call 在集群所有节点上执行命令
redis-trib.rb call host:port command arg arg .. arg
使用redis-trib.rb call在所有节点上执行keys命令
./redis-trib.rb call 127.0.0.1:6379 keys \*
结果
ip:port: [此节点上的key数组]
ip:port: [此节点上的key数组]
ip:port: [此节点上的key数组]
ip:port: [此节点上的key数组]
ip:port: [此节点上的key数组]
ip:port: [此节点上的key数组]
master/slave 上的key数组是相同的。
cluster nodes 查看集群节点状态
查看节点状态,输出是空格分割的CSV字符串,每行代表集群中的一个节点。
例如
07c37dfeb235213a872192d90877d0cd55635b91 127.0.0.1:30004 slave e7d1eecce10fd6bb5eb35b9f99a514335d9ba9ca 0 1426238317239 4 connected
67ed2db8d677e59ec4a4cefb06858cf2a1a89fa1 127.0.0.1:30002 master - 0 1426238316232 2 connected 5461-10922
292f8b365bb7edb5e285caf0b7e6ddc7265d2f4f 127.0.0.1:30003 master - 0 1426238318243 3 connected 10923-16383
6ec23923021cf3ffec47632106199cb7f496ce01 127.0.0.1:30005 slave 67ed2db8d677e59ec4a4cefb06858cf2a1a89fa1 0 1426238316232 5 connected
824fe116063bc5fcf9f4ffd895bc17aee7731ac3 127.0.0.1:30006 slave 292f8b365bb7edb5e285caf0b7e6ddc7265d2f4f 0 1426238317741 6 connected
e7d1eecce10fd6bb5eb35b9f99a514335d9ba9ca 127.0.0.1:30001 myself,master - 0 0 1 connected 0-5460
<id> <ip:port> <flags> <master> <ping-sent> <pong-recv> <config-epoch> <link-state> <slot> <slot> ... <slot>
节点ID, ip:port, master/slave标志,master_id(只slave有), 最后发送PING的时间, 最后接收PONG的时间, epoch,连接状态,节点负责处理的槽(只master有)。
id: 节点ID,是一个40字节的随机字符串,这个值在节点启动的时候创建,并且永远不会改变(除非使用CLUSTER RESET HARD命令)。
ip:port: 客户端与节点通信使用的地址.
flags: 逗号分割的标记位,可能的值有: myself, master, slave, fail?, fail, handshake, noaddr, noflags. 下一部分将详细介绍这些标记.
master: 如果节点是slave,并且已知master节点,则这里列出master节点ID,否则的话这里列出”-“。
ping-sent: 最近一次发送ping的时间,这个时间是一个unix毫秒时间戳,0代表没有发送过.
pong-recv: 最近一次收到pong的时间,使用unix时间戳表示.
config-epoch: 节点的epoch值(or of the current master if the node is a slave)。每当节点发生失败切换时,都会创建一个新的,独特的,递增的epoch。如果多个节点竞争同一个哈希槽时,epoch值更高的节点会抢夺到。
link-state: node-to-node集群总线使用的链接的状态,我们使用这个链接与集群中其他节点进行通信.值可以是 connected 和 disconnected.
slot: 哈希槽值或者一个哈希槽范围. 从第9个参数开始,后面最多可能有16384个 数(limit never reached)。代表当前节点可以提供服务的所有哈希槽值。如果只是一个值,那就是只有一个槽会被使用。如果是一个范围,这个值表示为起始槽-结束槽,节点将处理包括起始槽和结束槽在内的所有哈希槽。
reids 集群客户端
redis-cli 对集群的支持是非常基本的, 所以它总是依靠 Redis 集群节点来将它转向(redirect)至正确的节点。
一个真正的(serious)集群客户端应该做得比这更好: 它应该用缓存记录起哈希槽与节点地址之间的映射(map), 从而直接将命令发送到正确的节点上面。
这种映射只会在集群的配置出现某些修改时变化, 比如说, 在一次故障转移(failover)之后, 或者系统管理员通过添加节点或移除节点来修改了集群的布局(layout)之后, 诸如此类。
集群教程
http://redisdoc.com/topic/cluster-tutorial.html
redis3.0之前的集群方案:客户端sharding
Redis 3正式推出了官方集群技术,解决了多Redis实例协同服务问题。Redis Cluster可以说是服务端Sharding分片技术的体现,即将键值按照一定算法合理分配到各个实例分片上,同时各个实例节点协调沟通,共同对外承担一致服务。多Redis实例服务,比单Redis实例要复杂的多,这涉及到定位、协同、容错、扩容等技术难题。
redis3.0之前一般使用客户端分片(Sharding)来实现集群。
Redis Sharding可以说是Redis Cluster出来之前,业界普遍使用的多Redis实例集群方法。其主要思想是采用哈希算法将Redis数据的key进行散列,通过hash函数,特定的key会映射到特定的Redis节点上。这样,客户端就知道该向哪个Redis节点操作数据。
庆幸的是,java redis客户端驱动jedis,已支持Redis Sharding功能,即ShardedJedis以及结合缓存池的ShardedJedisPool。
Jedis的Redis Sharding实现具有如下特点:
1、采用 一致性哈希算法(consistent hashing) ,将key和节点name同时hashing,然后进行映射匹配,采用的哈希算法是 MURMUR_HASH。采用一致性哈希而不是采用简单类似哈希求模映射的主要原因是当增加或减少节点时,不会产生由于重新匹配造成的rehashing。一致性哈希只影响相邻节点key分配,影响量小。
2、为了避免一致性哈希只影响相邻节点造成节点分配压力,ShardedJedis会对每个Redis节点根据名字(没有,Jedis会赋予缺省名字)会虚拟化出160个 虚拟节点 进行散列。根据权重weight,也可虚拟化出160倍数的虚拟节点。用虚拟节点做映射匹配,可以在增加或减少Redis节点时,key在各Redis节点移动再分配更均匀,而不是只有相邻节点受影响。
3、ShardedJedis支持keyTagPattern模式,即抽取key的一部分keyTag做sharding,这样通过合理命名key,可以将一组相关联的key放入同一个Redis节点,这在避免跨节点访问相关数据时很重要。
客户端sharding扩容方案-presharding
Redis Sharding采用客户端Sharding方式,服务端Redis还是一个个相对独立的Redis实例节点,没有做任何变动。同时,我们也不需要增加额外的中间处理组件,这是一种非常轻量、灵活的Redis多实例集群方法。
当然,Redis Sharding这种轻量灵活方式必然在集群其它能力方面做出妥协。比如扩容,当想要增加Redis节点时,尽管采用一致性哈希,毕竟还是会有key匹配不到而丢失,这时需要键值迁移。
作为轻量级客户端sharding,处理Redis键值迁移是不现实的,这就要求应用层面允许Redis中数据丢失或从后端数据库重新加载数据。但有些时候,击穿缓存层,直接访问数据库层,会对系统访问造成很大压力。有没有其它手段改善这种情况?
Redis作者给出了一个比较讨巧的办法–presharding,即预先根据系统规模尽量部署好多个Redis实例,这些实例占用系统资源很小,一台物理机可部署多个,让他们都参与sharding,当需要扩容时,选中一个实例作为主节点,新加入的Redis节点作为从节点进行数据复制。数据同步后,修改sharding配置,让指向原实例的Shard指向新机器上扩容后的Redis节点,同时调整新Redis节点为主节点,原实例可不再使用。
presharding是预先分配好足够的分片,扩容时只是将属于某一分片的原Redis实例替换成新的容量更大的Redis实例。参与sharding的分片没有改变,所以也就不存在key值从一个区转移到另一个分片区的现象,只是将属于同分片区的键值从原Redis实例同步到新Redis实例。
Redis集群方案应该怎么做?
https://www.zhihu.com/question/21419897
redis集群(Sharding)和在线扩容(Pre-Sharding)
https://blog.csdn.net/rosanu_blog/article/details/68066756
redis代理中间件twemproxy
twitter / twemproxy
https://github.com/twitter/twemproxy
Redis代理中间件twemproxy就是这样一种利用中间件做sharding的技术。
twemproxy处于客户端和服务器的中间,将客户端发来的请求,进行一定的处理后(如sharding),再转发给后端真正的Redis服务器。也就是说,客户端不直接访问Redis服务器,而是通过twemproxy代理中间件间接访问。
存储
redis持久化
Redis的所有数据都是保存在内存中,然后不定期的通过异步方式保存到磁盘上(这称为“半持久化模式”);也可以把每一次数据变化都写入到一个append only file(aof)里面(这称为“全持久化模式”)。
由于Redis的数据都存放在内存中,如果没有配置持久化,redis重启后数据就全丢失了,于是需要开启redis的持久化功能,将数据保存到磁 盘上,当redis重启后,可以从磁盘中恢复数据。
redis提供两种方式进行持久化:
一种是RDB持久化(原理是将Reids在内存中的数据库记录定时 dump 到磁盘上的RDB持久化),
另外一种是AOF(append only file)持久化(原理是将Reids的操作日志以追加的方式写入文件)。
redis还可以同时使用AOF持久化和RDB持久化,在这种情况下,当redis重启时,它会有限使用AOF文件来还原数据集,因为AOF文件保存的数据集通常比RDB文件所保存的数据集更加完
RDB持久化(磁盘快照)
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。
RDB持久化配置
注意:save的两个条件都要满足才dump快照
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,则dump内存快照。
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,则dump内存快照。
save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,则dump内存快照。
dbfilename "dump.rdb" #持久化文件名称
dir "/data/dbs/redis/6381" #持久化数据文件存放的路径
配置文件修改需要重启redis服务,我们还可以在命令行里进行配置,即时生效,服务器重启后需重新配置
save(阻塞)和bgsave(异步非阻塞)
而RDB持久化也分两种:SAVE和BGSAVESAVE 是阻塞式的RDB持久化,当执行这个命令时redis的主进程把内存里的数据库状态写入到RDB文件(即上面的dump.rdb)中,直到该文件创建完毕的这段时间内redis将不能处理任何命令请求。BGSAVE 属于非阻塞式的持久化,它会创建一个子进程专门去把内存中的数据库状态写入RDB文件里,同时主进程还可以处理来自客户端的命令请求。但子进程基本是复制的父进程,这等于两个相同大小的redis进程在系统上运行,会造成内存使用率的大幅增加。
bgsave命令
background save
在后台异步(Asynchronously)保存当前数据库的数据到磁盘。
BGSAVE 命令执行之后立即返回 OK ,然后 Redis fork 出一个新子进程,原来的 Redis 进程(父进程)继续处理客户端请求,而子进程则负责将数据保存到磁盘,然后退出。
客户端可以通过 LASTSAVE 命令查看相关信息,判断 BGSAVE 命令是否执行成功。
AOF持久化
AOF(Append Only File) 持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。
AOF相关配置项:
dir "/data/dbs/redis/6381" #AOF文件存放目录
appendonly yes #开启AOF持久化,默认关闭
appendfilename "appendonly.aof" #AOF文件名称(默认)
appendfsync no #AOF持久化策略,有三个选项:always、everysec和no
auto-aof-rewrite-percentage 100 #触发AOF文件重写的条件(默认)
auto-aof-rewrite-min-size 64mb #触发AOF文件重写的条件(默认)
要弄明白上面几个配置就得从AOF的实现去理解,AOF的持久化是通过命令追加、文件写入和文件同步三个步骤实现的。
当reids开启AOF后,服务端每执行一次写操作(如set、sadd、rpush)就会把该条命令追加到一个单独的AOF缓冲区的末尾,这就是命令追加;然后把AOF缓冲区的内容写入AOF文件里。
看上去第二步就已经完成AOF持久化了那第三步是干什么的呢?这就需要从系统的文件写入机制说起:一般我们现在所使用的操作系统,为了提高文件的写入效率,都会有一个写入策略,即当你往硬盘写入数据时,操作系统不是实时的将数据写入硬盘,而是先把数据暂时的保存在一个内存缓冲区里,等到这个内存缓冲区的空间被填满或者是超过了设定的时限后才会真正的把缓冲区内的数据写入硬盘中。也就是说当redis进行到第二步文件写入的时候,从用户的角度看是已经把AOF缓冲区里的数据写入到AOF文件了,但对系统而言只不过是把AOF缓冲区的内容放到了另一个内存缓冲区里而已,之后redis还需要进行文件同步把该内存缓冲区里的数据真正写入硬盘上才算是完成了一次持久化。而何时进行文件同步则是根据配置的appendfsync来进行。
何时进行AOF持久化(always,everysec,no)
appendfsync有三个选项:always、everysec和no:
always(每个写操作)
1、选择always的时候服务器会在每执行一个事件就把AOF缓冲区的内容强制性的写入硬盘上的AOF文件里,可以看成你每执行一个redis写入命令就往AOF文件里记录这条命令,这保证了数据持久化的完整性,但效率是最慢的,却也是最安全的;
everysec(每秒)
2、配置成everysec的话服务端每执行一次写操作(如set、sadd、rpush)也会把该条命令追加到一个单独的AOF缓冲区的末尾,并将AOF缓冲区写入AOF文件,然后每隔一秒才会进行一次文件同步把内存缓冲区里的AOF缓存数据真正写入AOF文件里,这个模式兼顾了效率的同时也保证了数据的完整性,即使在服务器宕机也只会丢失一秒内对redis数据库做的修改;
no(由系统决定)
3、配置成no则意味redis数据库里的数据就算丢失你也可以接受,它也会把每条写命令追加到AOF缓冲区的末尾,然后写入文件,但什么时候进行文件同步真正把数据写入AOF文件里则由系统自身决定,即当内存缓冲区的空间被填满或者是超过了设定的时限后系统自动同步。这种模式下效率是最快的,但对数据来说也是最不安全的,如果redis里的数据都是从后台数据库如mysql中取出来的,属于随时可以找回或者不重要的数据,那么可以考虑设置成这种模式。
AOF重写(bgrewriteaof)
因为 AOF 的运作方式是不断地将命令追加到文件的末尾, 所以随着写入命令的不断增加, AOF 文件的体积也会变得越来越大。
举个例子, 如果你对一个计数器调用了 100 次 INCR , 那么仅仅是为了保存这个计数器的当前值, AOF 文件就需要使用 100 条记录(entry)。
然而在实际上, 只使用一条 SET 命令已经足以保存计数器的当前值了, 其余 99 条记录实际上都是多余的。
为了处理这种情况, Redis 支持一种有趣的特性: 可以在不打断服务客户端的情况下, 对 AOF 文件进行重建(rebuild)。
执行 BGREWRITEAOF 命令, Redis 将生成一个新的 AOF 文件, 这个文件包含重建当前数据集所需的最少命令。
Redis 2.2 需要自己手动执行 BGREWRITEAOF 命令; Redis 2.4 则可以自动触发 AOF 重写, 具体信息请查看 2.4 的示例配置文件。
RDB与AOF对比及合理选择持久化策略
RDB 和 AOF ,我应该用哪一个?
一般来说, 如果想达到足以媲美 PostgreSQL 的数据安全性, 你应该同时使用两种持久化功能。
如果你非常关心你的数据, 但仍然可以承受数分钟以内的数据丢失, 那么你可以只使用 RDB 持久化。
有很多用户都只使用 AOF 持久化, 但我们并不推荐这种方式: 因为定时生成 RDB 快照(snapshot)非常便于进行数据库备份, 并且 RDB 恢复数据集的速度也要比 AOF 恢复的速度要快, 除此之外, 使用 RDB 还可以避免之前提到的 AOF 程序的 bug 。
因为以上提到的种种原因, 未来我们可能会将 AOF 和 RDB 整合成单个持久化模型。 (这是一个长期计划。)
redis——持久化篇
https://www.cnblogs.com/dengtr/p/5085287.html
redis持久化的几种方式
https://www.cnblogs.com/AndyAo/p/8135980.html
redis两种持久化方式的优缺点
https://www.cnblogs.com/ssssdy/p/7132856.html
MISCONF Redis is configured to save RDB snapshots…
jedis 报错如下
redis.clients.jedis.exceptions.JedisDataException: MISCONF Redis is configured to save RDB snapshots, but is currently not able to persist on disk. Commands that may modify the data set are disabled. Please check Redis logs for details about the error.
Redis被配置为保存数据库快照,但它目前不能持久化到硬盘。用来修改集合数据的命令不能用。请查看Redis日志的详细错误信息。
解决
将 stop-writes-on-bgsave-error 设置为 no
#进入redis
redis-cli -h 127.0.0.1 -p 6379
#设置
config set stop-writes-on-bgsave-error no
redis过期策略
redis过期时间设置(expire)与查看(ttl)
expire key second 为key设置过期时间
返回1表明设置成功,返回0表明key不存在或者不能成功设置过期时间。
此外还有如下几个命令可设置过期时间:
EXPIRE key seconds //将key的生存时间设置为ttl秒
PEXPIRE key milliseconds //将key的生成时间设置为ttl毫秒
EXPIREAT key timestamp //将key的过期时间设置为timestamp所代表的的秒数的时间戳
PEXPIREAT key milliseconds-timestamp //将key的过期时间设置为timestamp所代表的的毫秒数的时间戳
TTL key
以秒为单位,返回给定 key 的剩余生存时间(TTL, time to live)。
redis有3种过期策略:
每个key定时删除
含义:在设置key的过期时间的同时,为该key创建一个定时器,让定时器在key的过期时间来临时,对key进行删除
优点:保证内存被尽快释放
缺点:
若过期key很多,删除这些key会占用很多的CPU时间,在CPU时间紧张的情况下,CPU不能把所有的时间用来做要紧的事儿,还需要去花时间删除这些key
定时器的创建耗时,若为每一个设置过期时间的key创建一个定时器(将会有大量的定时器产生),性能影响严重
没人用
惰性删除(访问key时再删除)
含义:key过期的时候不删除,每次从数据库获取key的时候去检查是否过期,若过期,则删除,返回null。
优点:删除操作只发生在从数据库取出key的时候发生,而且只删除当前key,所以对CPU时间的占用是比较少的,而且此时的删除是已经到了非做不可的地步(如果此时还不删除的话,我们就会获取到了已经过期的key了)
缺点:若大量的key在超出超时时间后,很久一段时间内,都没有被获取过,那么可能发生内存泄露(无用的垃圾占用了大量的内存)
对于惰性删除而言,并不是只有获取key的时候才会检查key是否过期,在某些设置key的方法上也会检查(eg.setnx key2 value2:该方法类似于memcached的add方法,如果设置的key2已经存在,那么该方法返回false,什么都不做;如果设置的key2不存在,那么该方法设置缓存key2-value2。假设调用此方法的时候,发现redis中已经存在了key2,但是该key2已经过期了,如果此时不执行删除操作的话,setnx方法将会直接返回false,也就是说此时并没有重新设置key2-value2成功,所以对于一定要在setnx执行之前,对key2进行过期检查)
周期性删除
含义:每隔一段时间执行一次删除(在redis.conf配置文件设置hz,1s刷新的频率)过期key操作
优点:
通过限制删除操作的时长和频率,来减少删除操作对CPU时间的占用–处理”定时删除”的缺点
定期删除过期key–处理”惰性删除”的缺点
缺点
在内存友好方面,不如”定时删除”
在CPU时间友好方面,不如”惰性删除”
难点
合理设置删除操作的执行时长(每次删除执行多长时间)和执行频率(每隔多长时间做一次删除)(这个要根据服务器运行情况来定了)
定时删除和定期删除为主动删除:Redis会定期主动淘汰一批已过去的key
惰性删除为被动删除:用到的时候才会去检验key是不是已过期,过期就删除
惰性删除为redis服务器内置策略
定期删除可以通过:
第一、配置redis.conf 的hz选项,默认为10 (即1秒执行10次,100ms一次,值越大说明刷新频率越快,最Redis性能损耗也越大)
第二、配置redis.conf的maxmemory最大值,当已用内存超过maxmemory限定时,就会触发主动清理策略
Redis学习笔记–Redis数据过期策略详解
http://www.cnblogs.com/xuliangxing/p/7151812.html
关于Redis数据过期策略
https://www.cnblogs.com/chenpingzhao/p/5022467.html
redis内存淘汰策略
maxmemory开启内存淘汰策略
maxmemory bytes 配置限制使用的最大内存,也就是说配置 maxmemory 后会开启内存淘汰功能
maxmemory 为 0 的时候表示我们对 Redis 的内存使用没有限制。
当我们程序达到最大值时, Redis使用了多种策略进行置换.Redis建议最大内存设置为物理内存的一半。
maxmemory-policy内存淘汰策略
maxmemory-policy noeviction 配置内存淘汰策略:
Redis提供了下面几种淘汰策略供用户选择,其中默认的策略为 noeviction 策略:
noeviction:不淘汰,当内存使用达到阈值的时候,所有引起申请内存的命令会报错。
allkeys-lru:在主键空间中,优先移除最近未使用的key。
volatile-lru:在设置了过期时间的键空间中,优先移除最近未使用的key。
allkeys-random:在主键空间中,随机移除某个key。
volatile-random:在设置了过期时间的键空间中,随机移除某个key。
volatile-ttl:在设置了过期时间的键空间中,具有更早过期时间的key优先移除。
下面看看几种策略的适用场景:
allkeys-lru:如果我们的应用对缓存的访问符合幂律分布(也就是存在相对热点数据),或者我们不太清楚我们应用的缓存访问分布状况,我们可以选择allkeys-lru策略。
allkeys-random:如果我们的应用对于缓存key的访问概率相等,则可以使用这个策略。
volatile-ttl:这种策略使得我们可以向Redis提示哪些key更适合被eviction。
另外,volatile-lru 策略和 volatile-random 策略适合我们将一个Redis实例既应用于缓存和又应用于持久化存储的时候,然而我们也可以通过使用两个Redis实例来达到相同的效果,值得一提的是将key设置过期时间实际上会消耗更多的内存,因此我们建议使用allkeys-lru策略从而更有效率的使用内存。
Redis中的LRU实现(近似LRU)
LRU(Least Recently Used),即最近最少使用
Redis使用的是近似LRU算法,它跟常规的LRU算法还不太一样。近似LRU算法通过随机采样法淘汰数据,每次随机出5(默认)个key,从里面淘汰掉最近最少使用的key。
可以通过 maxmemory-samples 参数修改采样数量:
例:maxmemory-samples 10
maxmenory-samples 配置的越大,淘汰的结果越接近于严格的LRU算法
Redis为了实现近似LRU算法,给每个key增加了一个额外增加了一个24bit的字段,用来存储该key最后一次被访问的时间。
Redis3.0对近似LRU的优化
Redis3.0 对近似LRU算法进行了一些优化。
新算法会维护一个候选池(大小为16),池中的数据根据访问时间进行排序,第一次随机选取的key都会放入池中,随后每次随机选取的key只有在访问时间小于池中最小的时间才会放入池中,直到候选池被放满。当放满后,如果有新的key需要放入,则将池中最后访问时间最大(最近被访问)的移除。
当需要淘汰的时候,则直接从池中选取最近访问时间最小(最久没被访问)的 key 淘汰掉就行。
Redis4.0新增LFU算法
LFU算法是Redis4.0里面新加的一种淘汰策略。它的全称是 Least Frequently Used,它的核心思想是根据key的最近被访问的频率进行淘汰,很少被访问的优先被淘汰,被访问的多的则被留下来。
LFU算法能更好的表示一个key被访问的热度。假如你使用的是LRU算法,一个key很久没有被访问到,只刚刚是偶尔被访问了一次,那么它就被认为是热点数据,不会被淘汰,而有些key将来是很有可能被访问到的则被淘汰了。如果使用LFU算法则不会出现这种情况,因为使用一次并不会使一个key成为热点数据。
LFU一共有两种策略:
volatile-lfu:在设置了过期时间的key中使用LFU算法淘汰key
allkeys-lfu:在所有的key中使用LFU算法淘汰数据
设置使用这两种淘汰策略跟前面讲的一样,不过要注意的一点是这两周策略只能在Redis4.0及以上设置,如果在Redis4.0以下设置会报错
如何选择合适的内存淘汰策略?
开发者还需要根据自身系统特征,正确选择淘汰策略:
在Redis中,数据有一部分访问频率较高,其余部分访问频率较低,或者无法预测数据的使用频率时,设置 allkeys-lru 是比较合适的。
如果所有数据访问概率大致相等时,可以选择 allkeys-random
如果研发者需要通过设置不同的 ttl 来判断数据过期的先后顺序,此时可以选择 volatile-ttl 策略。
如果希望一些数据能长期被保存,而一些数据可以被淘汰掉时,选择 volatile-lru 或 volatile-random 都是比较不错的。
由于设置 expire 会消耗额外的内存,如果计划避免 Redis 内存在此项上的浪费,可以选用 allkeys-lru 策略,这样就可以不再设置过期时间,高效利用内存了。
主键空间和过期键空间
主键空间和设置了过期时间的键空间,举个例子,假设我们有一批键存储在Redis中,则有那么一个哈希表用于存储这批键及其值,如果这批键中有一部分设置了过期时间,那么这批键还会被存储到另外一个哈希表中,这个哈希表中的值对应的是键被设置的过期时间。
设置了过期时间的键空间为主键空间的子集。
Redis 内存淘汰机制
https://www.cnblogs.com/changbosha/p/5849982.html
Redis 配置
Redis 的配置文件位于 Redis 安装目录下,文件名为 redis.conf
可以通过 config 命令查看或设置配置项。
config get 读取配置
使用 config get 命令读取配置,语法:config get CONFIG_SETTING_NAME
其中 CONFIG_SETTING_NAME 为配置项名称,可包含通配符
例如 config get * 获取所有配置项,config get *log* 获取所有包含log的配置项
config set 修改配置
可以通过修改 redis.conf 文件或使用 config set 命令修改配置,语法:config set CONFIG_SETTING_NAME NEW_CONFIG_VALUE
redis集群中各节点配置是独立的
常用配置项
daemonize
daemonize no
Redis默认不是以守护进程的方式运行,可以通过该配置项修改,使用yes启用守护进程
pidfile
pidfile /var/run/redis.pid
当Redis以守护进程方式运行时,Redis默认会把pid写入/var/run/redis.pid文件,可以通过pidfile指定
port
port 6379
指定Redis监听端口,默认端口为6379,作者在自己的一篇博文中解释了为什么选用6379作为默认端口,因为6379在手机按键上MERZ对应的号码,而MERZ取自意大利歌女Alessia Merz的名字
bind
bind 127.0.0.1
绑定的主机地址
timeout
timeout 300
当 客户端闲置多长时间后关闭连接,如果指定为0,表示关闭该功能
logfile
logfile stdout
指定日志文件名,默认为标准输出,如果配置Redis为守护进程方式运行,而这里又配置为日志记录方式为标准输出,则日志将会发送给/dev/null
databases
databases 16
设置数据库的数量,默认数据库为0,可以使用SELECT <dbid>命令在连接上指定数据库id
dir
dir ./
指定本地数据库存放目录
dbfilename
dbfilename dump.rdb
指定本地数据库文件名,默认值为dump.rdb
slaveof
slaveof <masterip> <masterport>
设置当本机为slav服务时,设置master服务的IP地址及端口,在Redis启动时,它会自动从master进行数据同步
stop-writes-on-bgsave-error
默认情况下,当 RDB 快照打开且最近一次 bgsave 失败时,redis会停止接受写操作并报错。
这是一种数据安全考虑,因为此时无法写入抛出的异常会使用户意识到数据无法正确的持久化到磁盘上,假如没有这种机制,用户持续写入而无法持久化当redis重启时会有数据丢失。
当 bgsave 进程可正常进行持久化操作后,redis也会自动允许写入。
如果你不在乎持久化数据丢失,想要 redis 在无法进行数据持久化的情况下依然可以正常工作,可以将此选项设置为 no
redis慢查询
slowlog-log-slower-than 慢查询阈值
slowlog-log-slower-than 慢查询阈值,单位微秒,默认值 10000 微秒,即 10 毫秒
127.0.0.1:6379> config get slowlog-log-slower-than
1) "slowlog-log-slower-than"
2) "10000"
slowlog-max-len 慢查询历史条数
slowlog-max-len 慢查询日志最多存储多少条,超过后最早的被删除
127.0.0.1:6379> config get slowlog-max-len
1) "slowlog-max-len"
2) "128"
修改慢查询阈值(默认10毫秒)
重设慢查询告警阈值为1秒 config set slowlog-log-slower-than 1000000
127.0.0.1:6379> config set slowlog-log-slower-than 1000000
OK
127.0.0.1:6379> config get slowlog-log-slower-than
1) "slowlog-log-slower-than"
2) "1000000"
slowlog len 查看慢查询个数
slowlog len 查询当前慢查询队列长度,即慢查询条数
https://redis.io/commands/slowlog-len
127.0.0.1:6379> slowlog len
(integer) 80
slowlog get n 查看redis慢查询日志列表
slowlog get n 查询慢查询日志,默认查10条
https://redis.io/commands/slowlog-get
每个log的6个字段分别是:
- 唯一性(unique)的日志标识符
- 被记录命令的执行时间点,以 UNIX 时间戳格式表示
- 查询执行时间,以微秒为单位
- 执行的命令,命令和多个参数以数组的形式排列
- 客户端ip和端口
- 客户端名字(通过 CLIENT SETNAME 设置了才有)
127.0.0.1:6379> slowlog get 3
1) 1) (integer) 79
2) (integer) 1640078160
3) (integer) 45025
4) 1) "KEYS"
2) "prefix*"
5) "10.233.75.0:59070"
6) ""
2) 1) (integer) 78
2) (integer) 1640071500
3) (integer) 44705
4) 1) "KEYS"
2) "prefix*"
5) "10.233.72.0:53178"
6) ""
3) 1) (integer) 77
2) (integer) 1640071350
3) (integer) 48283
4) 1) "KEYS"
2) "prefix*"
5) "10.233.111.0:52446"
6) ""
slowlog reset 清理慢查询日志
清理慢查询日志队列
https://redis.io/commands/slowlog-reset
127.0.0.1:6379> slowlog reset
OK
127.0.0.1:6379> slowlog len
(integer) 0
redis集群各节点需单独清理
redis 集群中多个节点需要分别处理,集群节点的配置是各自独立的
安装 Redis
Mac 安装 RedisDesktopManager
新版 Redis Desktop Manager(RDM) 要自己编译才可以(除非你在官网上进行付费),通过 brew 安装的也只能安装 0.8 的版本,所有最新的版本需要我们自己编译。
Mac OS X下编译Redis Desktop Manager(RDM)
https://onew.me/2018/03/29/mac-compile-RDM/index.html
如果不想自己编译,这里有编译好的mac dmg版本
RedisDesktopManager-Mac
https://github.com/onewe/RedisDesktopManager-Mac
Redis Desktop Manager
https://redisdesktop.com/download
Intel/M1 Mac Brew 安装 Redis
brew install redis
安装目录:
- Intel Mac 安装目录 /usr/local/Cellar/redis/6.2.4
- M1 Mac 安装目录 /opt/homebrew/Cellar/redis/6.2.6
使用 brew services 启动 redis 服务并添加开机启动:brew services start redis
前台启动:
Intel Mac 上 redis-server /usr/local/etc/redis.conf
M1 Mac 上 /opt/homebrew/opt/redis/bin/redis-server /opt/homebrew/etc/redis.conf
推荐使用 brew services 启动,可自动添加开机启动,避免每次重启后还要再启动redis
redis-server 命令
redis-server 是 redis 服务端的启动程序,也就是 reids 服务端的命令行。
--port 配置端口--slaveof 将当前服务器转变为指定服务器的从属服务器--loglevel 配置日志级别--sentinel 以哨兵模式运行-v 显示版本号
实例:
./redis-server [/path/to/redis.conf] [options]
./redis-server - (read config from stdin)
./redis-server -v or --version
./redis-server -h or --help
./redis-server --test-memory <megabytes>
实例:
1、用默认配置文件启动 redis
./redis-server
2、指定配置文件启动 redis
注意:为了能顺利读取配置文件,Redis 启动时要将配置文件路径作为第一个参数
./redis-server /etc/myredis.conf
3、指定端口启动 redis
./redis-server --port 7777
4、作为 slave 服务启动 redis
./redis-server --port 7777 --slaveof 127.0.0.1 8888
5、启动 redis 并配置日志类级别:
./redis-server /etc/myredis.conf --loglevel verbose
6、以哨兵模式运行 redis
./redis-server /etc/sentinel.conf --sentinel
redis-cli 命令
Redis CLI
https://redis.io/docs/latest/develop/connect/cli/
-h <hostname> 指定host,默认是 127.0.0.1-p <port> 指定端口,默认 6379-a <password> 指定连接密码,可以使用 REDISCLI_AUTH 环境变量更安全的传递密码-n <db> 指定数据库编号,相当于select db
redis-cli 连接localhost:6379
redis-cli,redis-cli 命令不加任何参数,默认用 6379 端口连接本地redis服务
redis-cli -h host -p port 指定host和端口连接
redis-cli -a passwd 指定密码连接
redis-cli -h host -p port -a passwd 连接指定地址
redis-cli -h host -p port -a password,连接远程redis服务器,指定密码
redis-cli 后 auth passwd 认证登录
可以先 redis-cli -h host -p port 无密码登录,然后 auth passwd 输入密码认证,和登录时用 -a passwd 指定密码相同。
redis-cli command 连接并执行命令
redis-cli -h host -p port command,直接得到命令的返回结果
redis-cli -n 1 指定db连接
Redis 默认有 16 个数据库,编号从 0 到 15,每个新的连接都默认使用 0 号数据库。redis-cli -n 1 command 指定db连接redis-cli -n 1 command 连接db 1并执行命令
redis 集群模式下不允许指定db
注意:Redis集群模式下,不允许指定db连接,也不允许连接后使用 select 1 切换 db
因为在集群模式下,Redis的数据是分布在不同的节点上的,不再像单机模式下那样可以按数据库编号进行划分。
127.0.0.1:6379> select 1
(error) ERR SELECT is not allowed in cluster mode
127.0.0.1:6379>
redis-cluster6-0:/$ redis-cli -c -n 1
SELECT 1 failed: ERR SELECT is not allowed in cluster mode
redis-cli –raw 解决中文乱码
Redis 默认情况下,存储的中文在通过 redis-cli 查询时,会以转义的形式显示。例如”测试”,会显示为”\xe6\xb5\x8b\xe8\xaf\x95”。
redis-cli –raw 登录即可在命令行看到中文
Redis 在使用命令行操作时,如果查看内容中包含中文,会显示 16 进制的字符串”\xe4\xb8\xad\xe5\x9b\xbd”
127.0.0.1:6379> set k1 '中国'
OK
127.0.0.1:6379> get k1
"\xe4\xb8\xad\xe5\x9b\xbd"
如果想要看到的中文不乱码,解决方案有两种:
一、使用echo
$ echo -e `redis-cli get k1`
中国
二、redis-cli 后面加上 –raw
$ redis-cli -h redis-host --raw
127.0.0.1:6379> get k1
中国
redis-cli -c 连接redis集群
-c 开启集群模式。
开启集群模式后,client 会根据 server 返回的 -ASK 和 -MOVED 命令进行重定向(redirection)。
不加 -c 也可以直接连接 redis 集群中的某个节点,但可能报 (error) MOVED 1127 127.0.0.2:8110 这种错误。
redis-cli -c -h localhost -p 8479 以集群模式连接到集群中的一个 redis 结点上。
$ redis-cli -c -h localhost -p 8479
localhost:8479> set redis-cluster-test 121
OK
localhost:8479> get redis-cluster-test
"121"
localhost:8479> set redis-cluster-test2 121111
-> Redirected to slot [9200] located at localhost:8579
OK
localhost:8579> set redis-cluster-test3 1lele
-> Redirected to slot [13265] located at localhost:8679
OK
redis-cli 对集群的支持是非常基本的, 所以它总是依靠 Redis 集群节点来将它转向(redirect)至正确的节点。
一个真正的(serious)集群客户端应该做得比这更好: 它应该用缓存记录起哈希槽与节点地址之间的映射(map), 从而直接将命令发送到正确的节点上面。
这种映射只会在集群的配置出现某些修改时变化, 比如说, 在一次故障转移(failover)之后, 或者系统管理员通过添加节点或移除节点来修改了集群的布局(layout)之后, 诸如此类。
redis-cli –cluster call 集群全部节点上执行命令
redis-cli --cluster call host:port command arg arg .. arg 在集群的所有节点执行相关命令
例如 redis-cli --cluster call localhost:6379 keys "user-*" 在集群全部节点执行 keys 命令
在全部节点删除模糊匹配keys
redis-cli -c 集群方式连接到redis集群的单个节点后,执行 keys * 命令依然无法看到全部节点的key
1、先连接任意节点,查询 keys
redis-cli --cluster call localhost:6379 keys "user-*"
>>> Calling keys user-*
127.0.0.1:6379: user-336
user-9
127.0.0.2:6379: user-75
user-10
2、xargs 连接 del 命令删除
redis-cli –cluster call localhost:6379 keys “LOCATION*”| xargs -n1 redis-cli –cluster call localhost:6379 del
-n1将参数拆成每个一行,给后续命令
redis-cli –bigkeys 查找元素多的大key
Redis CLI - Big keys
https://redis.io/docs/latest/develop/connect/cli/#big-keys
redis-cli --bigkeys 是一个用于查找 Redis 中大 key 的工具。它会扫描整个数据库,寻找并报告以下四种类型的大key:
- String 类型的 key,它的长度(以 bytes 计)最大。
- List、Set、Zset 类型的key,它们的元素数量最多。
- Hash 类型的key,它的字段数量最多。
扫描阶段会逐步打出目前为止发现的各种类型的最大 key
summary 中是汇总报告,包括:
- 总共扫描了多少key
- 各种类型的最大key分别是哪个,占多少bytes或有多少元素
- 各种类型的key分别有多少个,总bytes/元素数,平均bytes/元素数,及数据量占比。
内部使用 scan 命令扫描,不影响在线数据操作性能。
可以增加 -i 参数指定 sleep 时间:redis-cli --bigkeys -i 0.01 每个 scan 命令后 sleep 0.01 秒。
redis-cluster6-4:/$ redis-cli --bigkeys
# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
# per 100 SCAN commands (not usually needed).
[00.00%] Biggest string found so far '"pod-deployment-nubwj1vi-778c764bcb-bddk4:KEY"' with 1 bytes
[00.13%] Biggest zset found so far '"zset:218"' with 9 members
[00.30%] Biggest hash found so far '"hash:174"' with 25 fields
[00.85%] Biggest list found so far '"USER_ID_312"' with 1 items
[01.26%] Biggest string found so far '"b4b43081-d34b-4c43-9b18-72c2beab0698"' with 7616 bytes
[03.16%] Biggest list found so far '"USER_ID_159"' with 81 items
[04.26%] Biggest list found so far '"USER_ID_71"' with 387 items
[15.78%] Biggest zset found so far '"zset:169"' with 25 members
[20.32%] Biggest list found so far '"USER_ID_322"' with 576 items
[23.07%] Biggest list found so far '"USER_ID_210"' with 1052 items
[58.93%] Biggest set found so far '"set:1"' with 3 members
[75.06%] Biggest string found so far '"fdf178f5-8a97-4a54-bf07-b388a24505fa"' with 7624 bytes
[85.54%] Biggest list found so far '"USER_ID_258"' with 1238 items
[94.80%] Biggest list found so far '"USER_ID_221"' with 1856 items
-------- summary -------
Sampled 7446 keys in the keyspace!
Total key length in bytes is 524177 (avg len 70.40)
Biggest list found '"USER_ID_221"' has 1856 items
Biggest hash found '"hash:174"' has 25 fields
Biggest string found '"fdf178f5-8a97-4a54-bf07-b388a24505fa"' has 7624 bytes
Biggest set found '"set:1"' has 3 members
Biggest zset found '"zset:169"' has 25 members
93 lists with 11585 items (01.25% of keys, avg size 124.57)
37 hashs with 131 fields (00.50% of keys, avg size 3.54)
7285 strings with 379465 bytes (97.84% of keys, avg size 52.09)
0 streams with 0 entries (00.00% of keys, avg size 0.00)
1 sets with 3 members (00.01% of keys, avg size 3.00)
30 zsets with 199 members (00.40% of keys, avg size 6.63)
TYPE returned an error: MOVED
如果执行报错 TYPE returned an error: MOVED 4827 10.233.67.26:6379
说明操作的不是集群 master 节点,执行 cluster nodes 看集群内哪个节点是 master,在 master 节点上操作。
redis-cli –memkeys 查找内存占用高的大key
https://redis.io/docs/latest/develop/connect/cli/#memory-usage
redis-cli --memkeys 可以找出占用内存最大的key,和 redis-cli --bigkeys 输出结果类似,只不过是以内存占用大小统计的。
$ redis-cli --memkeys
# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
# per 100 SCAN commands (not usually needed).
[00.00%] Biggest string found so far '"USER:-deployment-nubwj1vi-778c764bcb-bddk4:KEY"' with 120 bytes
[00.13%] Biggest zset found so far '"USER:218"' with 405 bytes
[00.30%] Biggest hash found so far '"USER:174"' with 6928 bytes
[00.85%] Biggest list found so far '"USER_ID_312"' with 212 bytes
[01.26%] Biggest string found so far '"b4b43081-d34b-4c43-9b18-72c2beab0698"' with 8272 bytes
[03.14%] Biggest list found so far '"USER_ID_159"' with 4973 bytes
[04.24%] Biggest list found so far '"USER_ID_71"' with 28642 bytes
[06.15%] Biggest hash found so far '"USER::tasks"' with 29032 bytes
[15.77%] Biggest zset found so far '"USER:169"' with 837 bytes
[20.31%] Biggest list found so far '"USER_ID_322"' with 34889 bytes
[23.06%] Biggest list found so far '"USER_ID_210"' with 73120 bytes
[58.93%] Biggest set found so far '"USER:11"' with 376 bytes
[60.73%] Biggest zset found so far '"USER::162"' with 849 bytes
[94.80%] Biggest list found so far '"USER_ID_221"' with 113722 bytes
-------- summary -------
Sampled 7445 keys in the keyspace!
Total key length in bytes is 524164 (avg len 70.40)
Biggest list found '"USER_ID_221"' has 113722 bytes
Biggest hash found '"USER::tasks"' has 29032 bytes
Biggest string found '"b4b43081-d34b-4c43-9b18-72c2beab0698"' has 8272 bytes
Biggest set found '"USER:"' has 376 bytes
Biggest zset found '"USER::162"' has 849 bytes
93 lists with 757293 bytes (01.25% of keys, avg size 8142.94)
38 hashs with 70386 bytes (00.51% of keys, avg size 1852.26)
7283 strings with 1280695 bytes (97.82% of keys, avg size 175.85)
0 streams with 0 bytes (00.00% of keys, avg size 0.00)
1 sets with 376 bytes (00.01% of keys, avg size 376.00)
30 zsets with 10003 bytes (00.40% of keys, avg size 333.43)
上一篇 Redis-命令与数据类型
下一篇 jQuery
页面信息
location:protocol: host: hostname: origin: pathname: href: document:referrer: navigator:platform: userAgent: