面试准备04-Java虚拟机
Java面试准备笔记之JVM虚拟机
JDK工具
JDK Mission Control(JMC)
openjdk / jmc
https://github.com/openjdk/jmc
JDK Mission Control
https://www.oracle.com/java/technologies/jdk-mission-control.html
JVisualVM
JProfiler
https://www.ej-technologies.com/jprofiler
jconsole
JVM 监测、故障排除、分析工具,主要以图形化界面的方式提供运行于指定虚拟机的Java应用程序的详细信息。
wsimport
XML Web Service 2.0的Java API,主要用于根据服务端发布的wsdl文件生成客户端存根及框架
javap
Java 反编译工具,主要用于根据Java字节码文件反汇编为Java源代码文件。
相关工具
Java动态追踪技术探究 - 美团技术团队
https://tech.meituan.com/2019/02/28/java-dynamic-trace.html
ASM
ASM:直接操作字节码指令,执行效率高,但涉及到 JVM 的操作和指令,要求使用者掌握 Java 类字节码文件格式及指令,对使用者的要求比较高。
AOP 的利器:ASM 3.0 介绍
https://www.ibm.com/developerworks/cn/java/j-lo-asm30/index.html
Javassist
Javassist:提供了更高级的API,执行效率相对较差,但无需掌握字节码指令的知识,简单、快速,对使用者要求较低。
基于 Javassist 和 Javaagent 实现动态切面
https://www.cnblogs.com/chiangchou/p/javassist.html
BCEL
Apache Byte Code Engineering Library (BCEL)
用 BCEL 设计字节码
https://www.ibm.com/developerworks/cn/java/j-dyn0414/
btrace
btraceio/btrace
https://github.com/btraceio/btrace
JVM-SANDBOX 阿里开源沙箱容器
alibaba/jvm-sandbox
https://github.com/alibaba/jvm-sandbox
JVM-SANDBOX用户手册
https://github.com/alibaba/jvm-sandbox/wiki/USER-GUIDE
JVM-SANDBOX能做什么?
在JVM沙箱(以下简称沙箱)的世界观中,任何一个Java方法的调用都可以分解为BEFORE、RETURN和THROWS三个环节,由此在三个环节上引申出对应环节的事件探测和流程控制机制。
// BEFORE
try {
/*
* do something...
*/
// RETURN
return;
} catch (Throwable cause) {
// THROWS
}
基于BEFORE、RETURN和THROWS三个环节事件,可以完成很多类AOP的操作。
- 可以感知和改变方法调用的入参
- 可以感知和改变方法调用返回值和抛出的异常
- 可以改变方法执行的流程
- 在方法体执行之前直接返回自定义结果对象,原有方法代码将不会被执行
- 在方法体返回之前重新构造新的结果对象,甚至可以改变为抛出异常
- 在方法体抛出异常之后重新抛出新的异常,甚至可以改变为正常返回
JVM 虚拟机
《深入理解Java虚拟机》作者周志明的博客
http://icyfenix.iteye.com/
随笔分类 - Java虚拟机
http://www.cnblogs.com/xiaoxi/category/961347.html
专栏 - 深入java虚拟机
http://blog.csdn.net/column/details/java-vm.html
专栏 - java面试-深入理解JVM
https://blog.csdn.net/qq_34173549/article/category/7473988
JVM包括哪几部分?(哪几个子系统)
1、类加载子系统
2、内存管理子系统(内存划分、分配、垃圾回收)
3、执行子系统,包括解释执行和编译执行(即时编译JIT)
有哪些主流虚拟机?
SUN/Oracle HostSpot
Sun JDK 与 Open JDK 中自带的 Java 虚拟机。
HotSpot VM是绝对的主流。从Java SE 7开始,HotSpot VM就是Java规范的“参考实现”(RI,Reference Implementation)。把它叫做“标准JVM”完全不为过。
HotSpot VM 最令人称道的是其热点探测能力,可以通过执行计数器找到最具有编译价值的代码,然后通过 JIT 编译器以方法为单位进行编译。如果一个方法被频繁调用,或者方法中有效循环次数很多,将会分别触发标准编译和 OSR(栈上替换)编译动作。通过编译器和解释器恰当的协同工作,可以在最优化的程序响应事件与最佳执行性能中取得平衡
Oracle JRocket
JRockit 虚拟机是 BEA 公司于 2002 年从 Appeal Virtual Machines 收购获得的虚拟机。它是一款面向服务器硬件和服务端使用场景高度优化过得虚拟机,曾经号称是“世界上速度最快的虚拟机”。由于专注于服务端应用,它的内部不包含解析器的实现,全部代码都靠即时编译器编译后执行。
Oracle 在收购了 SUN 和 BEA 公司后,JDK8 的 HotSpot VM 已经是以前的 HotSpot VM 与 JRockit VM 的合并版。合并方式是把 JRockit VM一些有价值的功能在HotSpot里重新实现一遍。移除 PermGen、Java Flight Recorder、jcmd 等都属于合并项目的一部分。
IMB J9
J9 VM 的性能水平大致跟 HotSpot VM 是一个档次的。有时 HotSpot 快些,有时 J9 快些。一般情况下使用 IBM 自己的软件或者服务器,可以考虑用 J9,因为 J9 本身就是为 IBM 自己的系统做专门优化的。
Zing VM
Zing VM是一个从Sun HotSpot VM fork出来的一个高性能JVM,可以运行在Linux/x86-64平台上。Azul为它重新写了一套GC,也修改了VM内的许多实现细节,所以从我们自己的角度看,与其说它是HotSpot VM的一个变种,还不如把它看作“一个全新的JVM、只是凑巧与HotSpot VM很像”更合适。
JVM内存管理
主内存和线程本地内存
JMM主要是为了规定了线程和内存之间的一些关系。
根据JMM的设计,系统存在一个主内存(Main Memory),Java中所有变量都储存在主存中,对于所有线程都是共享的。每条线程都有自己的工作内存(Working Memory),工作内存中保存的是主存中某些变量的拷贝,线程对所有变量的操作都是在工作内存中进行,线程之间无法相互直接访问,变量传递均需要通过主存完成。
Java内存模型规定了所有的变量都存储在主内存中。每个线程还有自己的工作内存,线程的工作内存中保存了被该线程中使用到的变量的主内存拷贝副本,线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存中的变量。不同的线程之间也无法直接访问对方工作内存中的变量,线程间变量值的传递均需要通过主内存来完成。
Java内存模型规定所有的变量都是存在主存当中(类似于前面说的物理内存),每个线程都有自己的工作内存(类似于前面的高速缓存)。线程对变量的所有操作都必须在工作内存中进行,而不能直接对主存进行操作。并且每个线程不能访问其他线程的工作内存。
线程之间的共享变量存储在主内存(main memory)中,每个线程都有一个私有的本地内存(local memory),本地内存中存储了该线程以读/写共享变量的副本。
线程若要对某变量进行操作,必须经过一系列步骤:首先从主存复制/刷新数据到工作内存,然后执行代码,进行引用/赋值操作,最后把变量内容写回Main Memory。Java语言规范(JLS)中对线程和主存互操作定义了6个行为,分别为load,save,read,write,assign和use,这些操作行为具有原子性,且相互依赖,有明确的调用先后顺序。
对于普通变量,如果一个线程中那份主内存变量值的拷贝更新了,并不能马上反应在其他变量中
A,B两条线程直接读or写的都是线程的工作内存!而A、B使用的数据从各自的工作内存传递到同一块主内存的这个过程是有时差的,或者说是有隔离的!通俗的说他们之间看不见!也就是之前说的一个线程中的变量被修改了,是无法立即让其他线程看见的!如果需要在其他线程中立即可见,需要使用 volatile 关键字。
哪些变量分配在堆上哪些变量分配在栈上?
所有基本类型的local变量(方法本地变量)( boolean, byte, short, char, int, long, float, double)全都被存储在线程栈里,而且对其他线程是不可见的,一个线程可能会传递一份基本类型的变量值的一份拷贝给另一个线程,但是自己本身的变量是不能共享的,只能传递拷贝。很好理解,因为方法是线程隔离的。
堆中存储着java程序中new出来的对象,不管是哪个线程new出来的对象,都存在一起,而且不区分是哪个线程的对象。这些对象里面也包括那些原始类型的对象版本(e.g. Byte, Integer, Long etc.). 不管这个对象是分配给本地变量还是成员变量,最终都是存在堆里。
一个原始数据类型的本地变量将完全被存储在线程栈中。
本地变量也可以是指向对象的引用,在这种情况下,本地变量存在线程栈上,但是对象本身是存在堆上。
一个对象可能包含方法这些方法同时也会包含本地变量,这些本地变量也是存储在线程栈上面,即使他们所属于的对象和方法是存在堆上的。
一个对象的成员变量是跟随着对象本身存储在堆上的,不管成员变量是原始数据类型还是指向对象的引用。
静态的类变量一般也存储在堆上,根据类的定义。
存储在堆上的对象可以被所有的线程通过引用来访问。当一个线程持有一个对象的引用时,他同时也就可以访问这个对象的成员变量了。如果两个线程同时调用同一个对象的一个方法,他们就会都拥有这个对象的成员变量,但是每一个线程会享有自己私有的本地变量。
深度解析Java多线程的内存模型(剖析的非常透彻深入)
https://www.jianshu.com/p/a3f9f2c3ecf8
假设有个 Person 对象,有姓名、年龄等字段,还有说话speak() 吃饭eat() 等行为(方法),请问Person类及其实例在jvm中是怎么存储的?
对象是类的事例,每个对象的属性都属于对象本身,但是每个对象的行为却是公共的。
比如 personA和personB有各自的姓名和年龄,但是有共同的行为:speak
想象一下,如果我们是Java语言的设计者,我们会怎么存储对象的行为和属性呢?
很简单,属性跟着对象走,每个对象都存一份。行为是公共的东西,抽离出来,单独放到一个地方。
所以 ,Java对象的行为(方法、函数)是存储在方法区的, 所有实例共享。对象的属性随对象存储在堆上,各个实例不同。
为什么Java进程使用的内存比-Xmx大很多?
1、JVM包括很多子系统:垃圾收集器、类加载系统、JIT编译器等等,这些子系统各自都需要一定数量的RAM才能正常工作。
2、当一个Java进程运行时,也不仅仅是JVM在消耗RAM,很多本地库(Java类库中引用的本地库)可能需要分配原生内存(堆外内存),这些内存无法被JVM的Native Memory Tracking机制监控到。Java应用自身也可能通过DirectByteBuffers等类来使用堆外内存。
一个Java进程运行时,有哪些部分在消耗内存?
一、JVM部分
Java Heap: 最明显的部分,Java对象在这个区域分配和回收,Heap的最大值由-Xmx决定。
Garbage Collector:GC的数据结构和算法需要额外的内存对堆内存进行管理。这些数据结构包括:Mark Bitmap、Mark Stack(用于跟踪存活的对象)、Remembered Sets(用于记录region之间的引用)等等。这些数据结构中的一些是可以直接调整的,例如:-XX:MarkStackSizeMax,其他的则依赖于堆的分布,例如:分区大小,-XX:G1HeapRegionSize,这个值越大Remembered Sets的值越小。不同的GC算法需要的额外内存是不同的,-XX:+UseSerialGC和-XX:+UseShenandoahGC需要较小的额外内存,G1和CMS则需要Heap size的10%作为额外内存。
Code Cache:用于存放动态生成的代码:JIT编译的方法、拦截器和运行时存根。这个区域的大小由-XX:ReservedCodeCacheSize确定(默认是240M)。使用-XX-TieredCompilation关掉多层编译,可以减少需要编译的代码,从而减少Code Cache的使用。
Compiler:JIT编译器需要一些内存来才能工作。这个值可以通过关闭多层编译或减少执行编译的线程数(-XX:CICompilerCount)来调整.
Class loading:类的元数据(方法的字节码、符号表、常量池、注解等)被存放在off-heap区域,也叫Metaspace。当前JVM进程加载了越多的类,就会使用越多的metaspace。通过设置-XX:MaxMetaspaceSize(默认是无限)或-XX:CompressedClassSpaceSize(默认是1G)可以限制元空间的大小
Symbol tables:JVM中维护了两个重要的哈希表:Symbol表包括类、方法、接口等语言元素的名称、签名、ID等,String table记录了被interned过的字符串的引用。如果Native Tracking表明String table使用了很大的内存,那么说明该Java应用存在对String.intern方法的滥用。
Threads:线程栈也会使用RAM,栈的大小由-Xss确定。默认是1个线程最大有1M的线程栈,幸运得失事情并没有这么糟糕——OS使用惰性策略分配内存页,实际上每个Java线程使用的RAM很小(一般80~200K),作者使用这个脚本 https://github.com/apangin/jstackmem 来统计有多少RSS空间是属于Java线程的。
二、堆外内存(Direct buffers)
Java应用可以通过ByteBuffer.allocateDirect显式申请堆外内存;默认的堆外内存大小是-Xmx,但是这个值可被-XX:MaxDirectMemorySize覆盖。在JDK11之前,Direct ByteBuffers被NMT(Native Memory Tracking)列举在other部分,可以通过JMC观察到堆外内存的使用情况。
除了DirectByteBuffers,MappedByteBuffers也会使用本地内存,MappedByteBuffers的作用是将文件内容映射到进程的虚拟内存中,NMT没有跟踪它们,想要限制这部分的大小并不容易,可以通过 pmap -x pid 命令观察当前进程使用的实际大小。
三、本地库(Native libraries)
由System.loadLibrary加载的JNI代码也会按需分配RAM,并且这部分内存不受JVM管理。在这里需要关注的是Java类库,未关闭的Java资源会导致本地内存泄漏,典型的例子是:ZipInputStream或DirectoryStream。
JVMTI agent,特别是jdwp调试agent,也可能导致内存的过量使用。
所以, 很难准确统计一个Java进程使用的总内存大小。
为什么Java进程使用的RAM比Heap Size大?
https://segmentfault.com/a/1190000020456190
JVM运行时内存划分(JDK8之前)
JVM内存管理——JAVA语言的内存管理概述 - zuoxiaolong(左潇龙)
http://www.cnblogs.com/zuoxiaolong/p/jvm1.html
JVM的内存区域划分 - 平凡希
http://www.cnblogs.com/xiaoxi/p/6421526.html
java面试-深入理解JVM(一)——JVM内存模型
https://blog.csdn.net/qq_34173549/article/details/79612540
Java虚拟机(JVM)内部定义了程序在运行时需要使用到的内存区域
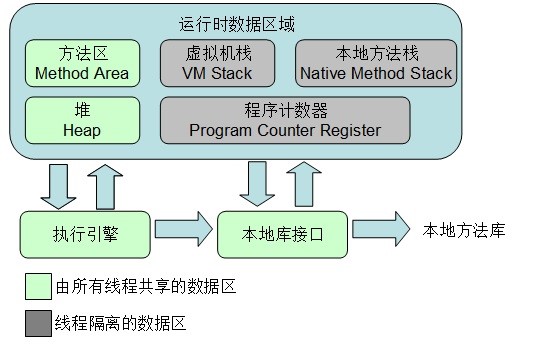
JVM内存模型
之所以要划分这么多区域出来是因为这些区域都有自己的用途,以及创建和销毁的时间。有些区域随着虚拟机进程的启动而存在,有的区域则依赖用户线程的启动和结束而销毁和建立。图中绿色部分就是所有线程之间共享的内存区域,而其余部分则是线程运行时独有的数据区域
堆内存和非堆内存
堆(Heap)内存和非堆(Non-Heap)内存
按照官方的说法:“Java 虚拟机具有一个堆,堆是运行时数据区域,所有类实例和数组的内存均从此处分配。堆是在 Java 虚拟机启动时创建的。”“在JVM中堆之外的内存称为非堆内存(Non-heap memory)”。可以看出JVM主要管理两种类型的内存:堆和非堆。简单来说堆就是Java代码可及的内存,是留给开发人员使用的;非堆就是JVM留给 自己用的,所以方法区、JVM内部处理或优化所需的内存(如JIT编译后的代码缓存)、每个类结构(如运行时常数池、字段和方法数据)以及方法和构造方法 的代码都在非堆内存中。
堆内存
JVM留给开发者用的内存。一般存放对象以及数组。
JVM初始分配的堆内存由-Xms指定,默认是物理内存的1/64;JVM最大分配的堆内存由-Xmx指定,默认是物理内存的1/4。
默认空余堆内存小于40%时,JVM就会增大堆内存直到-Xmx的最大限制;空余堆内存大于70%时,JVM会减少堆内存直到-Xms的最小限制。因此服务器一般设置-Xms、-Xmx相等以避免在每次GC后调整堆内存的大小。
如果-Xmx不指定或者指定偏小,应用可能会导致java.lang.OutOfMemory错误,此错误来自JVM,不是Throwable的,无法用try…catch捕捉。
非堆内存
JVM留给自己用的内存。方法区、JVM内部处理或优化所需的内存(如JIT编译后的代码缓存)、每个类结构(如运行时常数池、字段和方法数据)以及方法和构造方法的代码都在非堆内存中。
JVM初始分配的非堆内存由-XX:PermSize指定,默认是物理内存的1/64;JVM最大分配的非堆内存由-XX:MaxPermSize指定,默认是物理内存的1/4。(还有一说:MaxPermSize缺省值和-server -client选项相关,-server选项下默认MaxPermSize为64m,-client选项下默认MaxPermSize为32m)
-XX:MaxPermSize设置过小会导致java.lang.OutOfMemoryError: PermGen space,原因如下:
PermGen space用于存放Class和Meta的信息,GC不会对PermGen space进行处理,所以如果Load很多Class的话,就会出现上述Error。这种Error在web服务器对JSP进行pre compile的时候比较常见
线程独有内存区域(随线程启动创建)
对于线程独有的这部分内存,都是随着线程的启动而创建,而当线程被销毁时,内存也就随之释放。这一部分内存,不需要垃圾搜集器的管理,而是JAVA虚拟机来主动管理,每当一个线程被创建的时候,JAVA虚拟机就会为其分配相应的PC寄存器和JAVA虚拟机栈,如果需要的话,还会有本地方法栈。相应的,当一个线程被销毁的时候,JAVA虚拟机也会将这个线程所占有的内存全部释放。
PC程序计数器(线程独有)
这块内存区域很小,它是当前线程所执行的字节码的行号指示器,字节码解释器通过改变这个计数器的值来选取下一条需要执行的字节码指令。
它的作用就是用来支持多线程,线程的阻塞、恢复、挂起等一系列操作,直观的想象一下,要是没有记住每个线程当前运行的位置,又如何恢复呢。依据这一点,每一个线程都有一个PC寄存器,也就是说PC寄存器是线程独有的。
VM Stack虚拟机栈(线程独有)
Java栈也称作虚拟机栈(Java Vitual Machine Stack),也就是我们常常所说的栈
Java栈中存放的是一个个的栈帧,每个栈帧对应一个被调用的方法。当线程执行一个方法时,就会随之创建一个对应的栈帧,并将建立的栈帧压栈。当方法执行完毕之后,便会将栈帧出栈。因此可知,线程当前执行的方法所对应的栈帧必定位于Java栈的顶部。
讲到这里,大家就应该会明白为什么在使用递归方法的时候容易导致栈内存溢出的现象了以及为什么栈区的空间不用程序员去管理了
NATIVE METHOD STACK本地方法栈(线程独有)
用来支持native方法的执行
在JVM规范中,并没有对本地方发展的具体实现方法以及数据结构作强制规定,虚拟机可以自由实现它。在HotSopt虚拟机中直接就把本地方法栈和Java栈合二为一。
Java栈帧(Stack Frame)结构
Java栈帧如下图
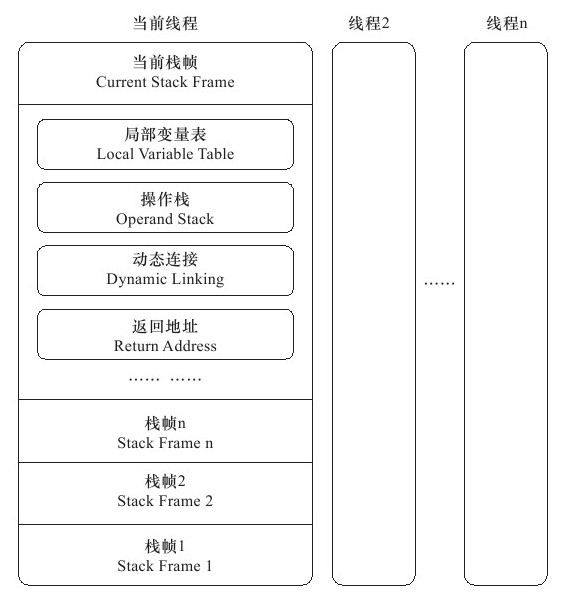
Java栈帧结构
局部变量表
局部变量表(Local Variables):是一组变量值存储空间,用来存储方法中的局部变量(包括在方法中声明的非静态变量以及函数形参)。
对于基本数据类型的变量,则直接存储它的值。
对于引用类型的变量,则存的是指向对象的引用。
局部变量表的大小在编译器就可以确定其大小了,因此在程序执行期间局部变量表的大小是不会改变的。
变量槽(Variable Slot)
局部变量表的容量以变量槽为最小单位,每个变量槽都可以存储32位长度的内存空间,例如boolean、byte、char、short、int、float、reference。
如果执行的是实例方法(当前栈帧是实例方法),那局部变量表中第0位索引的Slot默认是用于传递方法所属对象实例的引用,也就是this指针。
其余参数则按照参数表顺序排列,占用从1开始的局部变量Slot。
Slot复用
为了尽可能节省栈帧空间,局部变量表中的变量槽Slot是复用的,也就是说当PC计数器的指令指已经超出了某个变量的作用域(执行完毕),那这个变量对应的Slot就可以交给其他变量使用。
优点 : 节省栈帧空间。
缺点 : 影响到系统的垃圾收集行为。(如大方法占用较多的Slot,执行完该方法的作用域后没有对Slot赋值或者清空设置null值,垃圾回收器便不能及时的回收该内存。)
动态连接
指向当前方法所属的类的运行时常量池的引用(Reference to runtime constant pool):因为在方法执行的过程中有可能需要用到类中的常量,所以必须要有一个引用指向运行时常量。
每个栈帧都包含一个指向运行时常量池中该栈帧所属方法的引用,持有这个引用是为了支持方法调用过程中的动态连接(Dynamic Linking)。
在类加载阶段中的解析阶段会将符号引用转为直接引用,这种转化也称为静态解析。另外的一部分将在每一次运行时期转化为直接引用。这部分称为动态连接。
操作数栈
操作数栈(Operand Stack)
操作数栈和局部变量表一样,在编译时期就已经确定了该方法所需要分配的局部变量表的最大容量。
操作数栈的每一个元素可用是任意的Java数据类型,包括long和double。32位数据类型所占的栈容量为1,64位数据类型占用的栈容量为2。
当一个方法刚刚开始执行的时候,这个方法的操作数栈是空的,在方法执行的过程中,会有各种字节码指令往操作数栈中写入和提取内容,也就是 出栈 / 入栈 操作。
例如,在做算术运算的时候是通过操作数栈来进行的,又或者在调用其它方法的时候是通过操作数栈来进行参数传递的。
jvm对操作数栈的优化
在概念模型中,两个栈帧是相互独立的。但是大多数虚拟机的实现都会进行优化,令两个栈帧出现一部分重叠。令下面的部分操作数栈与上面的局部变量表重叠在一块,这样在方法调用的时候可以共用一部分数据,无需进行额外的参数复制传递。
索然两个栈帧作为虚拟机栈的元素是完全独立的,但是虚拟机会做出相应的优化,令连续的两个栈帧出现一部分重叠来共享数据。
如上图所示,栈帧的部分操作数栈与上一个栈帧的局部变量表重叠在一起,这样在进行方法调用时就可以共用一部分数据,无须进行额外的参数复制传递。
方法返回地址
方法返回地址(Return Address):当一个方法执行完毕之后,要返回之前调用它的地方,因此在栈帧中必须保存一个方法返回地址。
当一个方法开始执行后,只有2种方式可以退出这个方法 :
- 方法返回指令 : 执行引擎遇到一个方法返回的字节码指令,这时候有可能会有返回值传递给上层的方法调用者,这种退出方式称为正常完成出口。
- 异常退出 : 在方法执行过程中遇到了异常,并且没有处理这个异常,就会导致方法退出。
无论采用任何退出方式,在方法退出之后,都需要返回到方法被调用的位置,程序才能继续执行,方法返回时可能需要在栈帧中保存一些信息。
一般来说,方法正常退出时,调用者的PC计数器的值可以作为返回地址,栈帧中会保存这个计数器值。
而方法异常退出时,返回地址是要通过异常处理器表来确定的,栈帧中一般不会保存这部分信息。
线程间共享内存区域(随虚拟机启动创建)
相对于线程独有的那部分内存,全局共享的这部分内存更加难以处理,不过这只是针对于虚拟机的实现来说,因为这一部分内存是要实现自动内存管理系统(GC)的。
全局共享的这部分内存(以下简称堆),内存分配主要是由程序员显示的使用new关键字来触发的,至于new出来的这部分内存在哪分配,如何分配,则是JAVA虚拟机来决定。而这部分内存的释放,则是由自动内存管理系统(以下简称GC)来管理的。
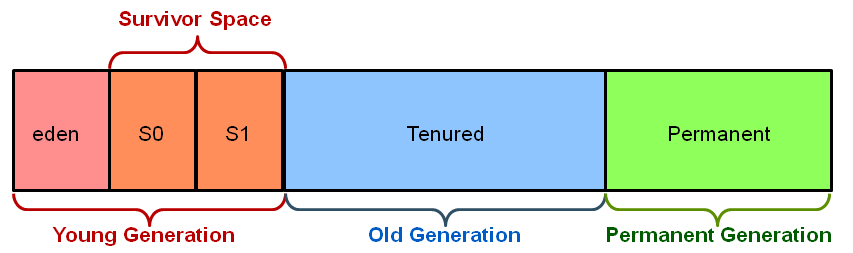
HEAP堆(新生代+老年代)
这一部分是JAVA内存中最重要的一部分,之所以说是最重要的一部分,并不是因为它的重要性,而是指作为开发人员最应该关注的一部分。
它随着JAVA虚拟机的启动创建,储存着所有对象实例以及数组对象,而且内置了“自动内存管理系统”,也就是我们常说的垃圾搜集器(GC)。JAVA堆中的内存释放是不受开发人员控制的,完全由JAVA虚拟机一手操办。对于JAVA虚拟机如何实现垃圾搜集器,JAVA虚拟机规范没有明确的规定,也正因如此,我们平时使用的JAVA虚拟机中提供了许多种垃圾搜集器,它们采用不同的算法以及实现方式,已满足多方面的性能需求。
由于现在垃圾收集器采用的基本都是分代收集算法,所以堆还可以细分为新生代和老年代,再细致一点还有Eden区、From Survivior区、To Survivor区。
METHOD AREA方法区(持久代)
这块区域用于存储虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据,虚拟机规范是把这块区域描述为堆的一个逻辑部分的。
持久代中存的内容
- JVM中类的元数据在Java堆中的存储区域。
- Java类对应的HotSpot虚拟机中的内部表示也存储在这里。
- 类的层级信息,字段,名字。
- 方法的编译信息及字节码。
- 变量
- 常量池和符号解析
它与JAVA堆的区别除了存储的信息与JAVA堆不一样之外,最大的区别就是这一部分JAVA虚拟机规范不强制要求实现自动内存管理系统(GC)。
从上面提到的分代收集算法的角度看,HotSpot中,方法区≈永久代。不过JDK 7之后,我们使用的HotSpot应该就没有永久代这个概念了,会采用Native Memory来实现方法区的规划了。
方法区中有一部分叫RUNTIME CONSTANT POOL,运行时常量池,用于存放编译期间生成的各种字面量和符号引用,这部分内容将在类加载后进入方法区的运行时常量池中,另外翻译出来的直接引用也会存储在这个区域中。
方法区和永久代的区别?
方法区(Method Area)是java虚拟机规范中的概念,表示用于存储类信息、常量、静态变量、JIT即时编译后代码等数据的内存区域。具体放在哪里,不同的虚拟机实现可以放在不同的地方。
永久代(Permanent Generation)是Hotspot虚拟机中特有的概念,Hotspot用永久代来实现方法区。别的虚拟机如BEA JRockit、IBM J9等都没有永久代。
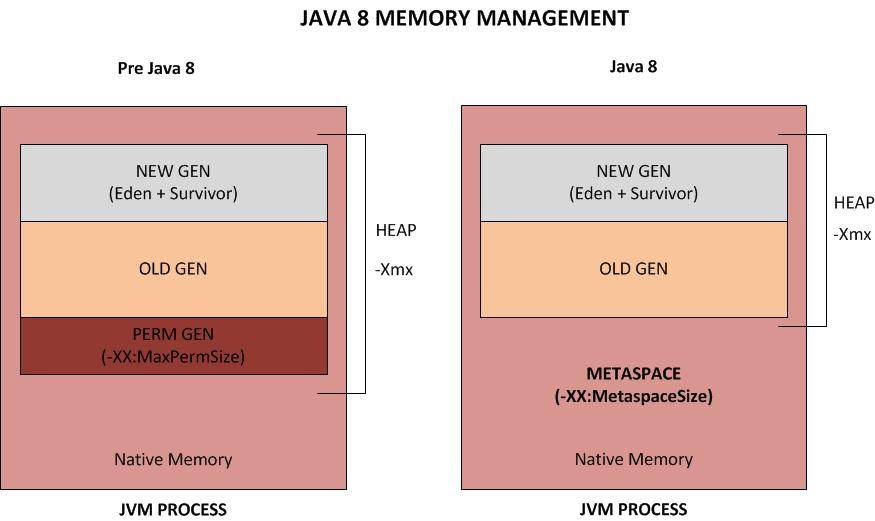
在Java 8中,永久代被彻底移除,取而代之的是另一块与堆不相连的本地内存——元空间(Metaspace), ‑XX:MaxPermSize 参数失去了意义,取而代之的是 -XX:MaxMetaspaceSize。
方法区的Class信息,又称为永久代,是否属于Java堆? - 毛海山的回答 - 知乎
https://www.zhihu.com/question/49044988/answer/113961406
JVM中MemoryUsage中init,committed,used,max的含义
Java Doc 中搜索 MemoryUsage 类
https://docs.oracle.com/javase/8/docs/api/index.html
java.lang.management 包中的 MemoryUsage 类表示当前内存使用的快照数据, 包含4个值 init, used, committed, max
init represents the initial amount of memory (in bytes) that the Java virtual machine requests from the operating system for memory management during startup. The Java virtual machine may request additional memory from the operating system and may also release memory to the system over time. The value of init may be undefined.used represents the amount of memory currently used (in bytes).committed represents the amount of memory (in bytes) that is guaranteed to be available for use by the Java virtual machine. The amount of committed memory may change over time (increase or decrease). The Java virtual machine may release memory to the system and committed could be less than init. committed will always be greater than or equal to used.max represents the maximum amount of memory (in bytes) that can be used for memory management. Its value may be undefined. The maximum amount of memory may change over time if defined. The amount of used and committed memory will always be less than or equal to max if max is defined. A memory allocation may fail if it attempts to increase the used memory such that used > committed even if used <= max would still be true (for example, when the system is low on virtual memory).
下图是JVM内存使用示例图
+----------------------------------------------+
+//////////////// | +
+//////////////// | +
+----------------------------------------------+
|--------|
init
|---------------|
used
|---------------------------|
committed
|----------------------------------------------|
max
结论:**init 约等于 -Xms 的值,max 约等于 -Xmx 的值。used 是已经被使用的内存大小,committed 是当前可使用的内存大小(包括已使用的),committed >= used。committed 不足时jvm向系统申请,若超过max则发生 OutOfMemoryError 错误**
JDK7将永久代的常量移到堆中
从JDK7开始永久代的移除工作,贮存在永久代的一部分数据已经转移到了Java Heap或者是Native Heap。但永久代仍然存在于JDK7,并没有完全的移除。
符号引用(Symbols)转移到了native heap;
字面量(interned strings)转移到了java heap;
类的静态变量(class statics)转移到了java heap。
永久代在JDK8中被完全的移除了。所以永久代的参数-XX:PermSize和-XX:MaxPermSize也被移除了。
Java 8: 从永久代(PermGen)到元空间(Metaspace)
https://blog.csdn.net/zhushuai1221/article/details/52122880
JDK8中的内存划分
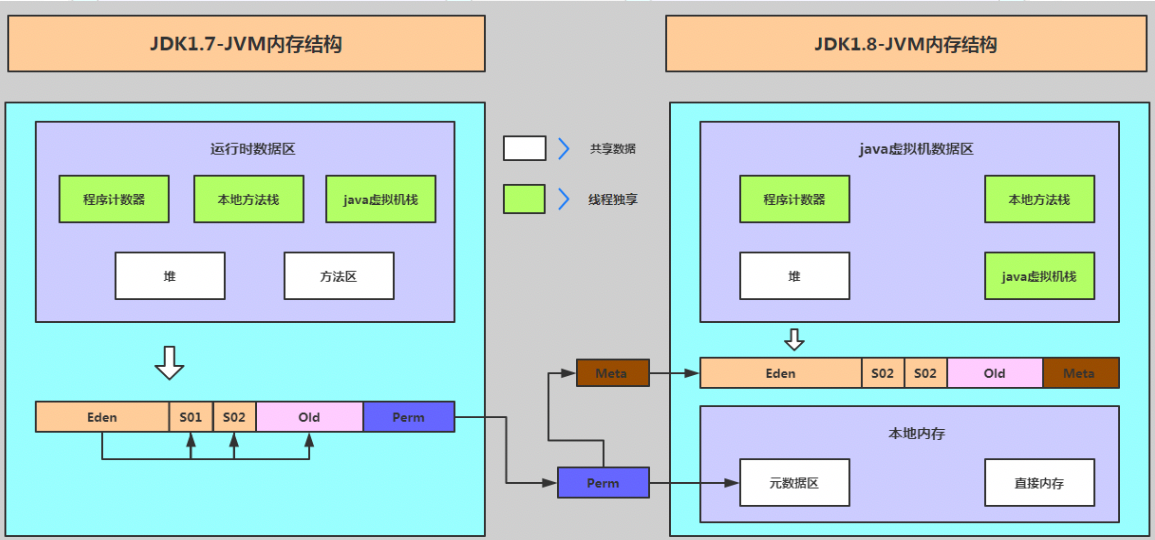
Java8中的内存划分
Java8中为什么用元空间代替永久代?(合并JRocket/内存限制)
1、移除永久代是为融合 HotSpot JVM 与 JRockit VM 而做出的努力,因为 JRockit 没有永久代,不需要配置永久代。
JDK 8 的一个非常重要的变化就是,Oracle 开始将 JRocket 与 HotSpot 合并,JDK8 的 HotSpot VM 已经是以前的 HotSpot VM 与 JRockit VM 的合并版,也就是传说中的 “HotRockit”,只是产品里名字还是叫 HotSpot VM。这个合并并不是要把 JRockit 的部分代码插进 HotSpot 里,而是把前者一些有价值的功能在后者里重新实现一遍。移除 PermGen、Java Flight Recorder、jcmd 等都属于合并项目的一部分。
与 Oracle JRockit 和 IBM JVM 类似,JDK 8 HotSpot JVM 开始使用本地化的内存存放类的元数据,这个空间叫做元空间(Metaspace)。
2、由于永久代内存经常不够用或发生内存泄露,抛出异常 java.lang.OutOfMemoryError: PermGen, JVM 的开发者希望这一块内存可以更灵活地被管理,不要再经常出现这样的 OOM。
使用本地内存有什么好处呢?
最直接的表现就是 java.lang.OutOfMemoryError: PermGen 问题将不复存在,因为默认的类的元数据分配只受本地内存大小的限制,也就是说本地内存剩余多少,理论上 Metaspace 就可以有多大(貌似容量还与操作系统的虚拟内存有关?这里不太清楚),这解决了空间不足的问题。
Metaspace元空间和永久代的区别?
元空间的本质和永久代类似,都是对 JVM 规范中方法区的实现
不过元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。因此,默认情况下,元空间的大小仅受本地内存限制,但可以通过参数来指定元空间的大小。
元空间的容量
让 Metaspace 变得无限大显然是不现实的,因此我们也要限制 Metaspace 的大小:使用 -XX:MaxMetaspaceSize 参数来指定 Metaspace 区域的大小。JVM 默认在运行时根据需要动态地设置 MaxMetaspaceSize 的大小。
默认情况下,类元数据分配受到可用的本机内存容量的限制(容量依然取决于你使用32位JVM还是64位操作系统的虚拟内存的可用性)。
一个新的参数 (MaxMetaspaceSize)可以使用。允许你来限制用于类元数据的本地内存。如果没有特别指定,元空间将会根据应用程序在运行时的需求动态设置大小。
元空间的特点:
充分利用了Java语言规范中的好处:类及相关的元数据的生命周期与类加载器的一致。
每个加载器有专门的存储空间
只进行线性分配
不会单独回收某个类
省掉了GC扫描及压缩的时间
元空间里的对象的位置是固定的
如果GC发现某个类加载器不再存活了,会把相关的空间整个回收掉
元空间配置参数
jdk8 中,-XX:PermSize, -XX:MaxPermSize 参数已移除,代替他的是元空间的配置参数。
-XX:MetaspaceSize
初始化的Metaspace大小,控制元空间发生GC的阈值。GC后,动态增加或降低MetaspaceSize。在默认情况下,这个值大小根据不同的平台在12M到20M浮动。使用java -XX:+PrintFlagsInitial命令查看本机的初始化参数
-XX:MaxMetaspaceSize
限制Metaspace增长的上限,防止因为某些情况导致Metaspace无限的使用本地内存,影响到其他程序。在本机上该参数的默认值为4294967295B(大约4096MB)。
元空间的垃圾回收
如果类元数据的空间占用达到参数 MaxMetaspaceSize 设置的值,将会触发对死亡对象和类加载器的垃圾回收。
为了限制垃圾回收的频率和延迟,适当的监控和调优元空间是非常有必要的。元空间过多的垃圾收集可能表示类,类加载器内存泄漏或对你的应用程序来说空间太小了。
JDK8-废弃永久代(PermGen)迎来元空间(Metaspace)
https://www.cnblogs.com/yulei126/p/6777323.html
JAVA8 JVM的变化: 元空间(Metaspace)
https://blog.csdn.net/bigtree_3721/article/details/51248377
压缩类空间(CCS)
一般对象指针(oop, ordinary object pointer) 也就是原始指针。它的大小通常和本地指针是一样的。Java Runtime 可以用这个指针直接访问指针对应的内存,做相应的操作。
在 64 位 系统中,指针需要使用 64 位来表示,32 位系统中则只需要 32 位
所以, 64bit 的 JVM 出现后,OOPS 的尺寸也变成了 64bit,比之前的大了一倍。这会引入性能损耗——占的内存 double 了,并且同尺寸的 CPU Cache 要少存一倍的 OOPS。
于是,就有了 UseCompressedOops 这个选项。打开后,OOPS 变成了 32bit。
从 JDK6_u23 开始 UseCompressedOops 被默认打开了。因此既能享受 64bit 带来的好处,又避免了 64bit 带来的性能损耗。当然,如果你有机会使用超过 32G 的堆内存,记得把这个选项关了。
如果 UseCompressedOops 是打开的,则以下对象的指针会被压缩:
所有对象的klass属性
所有对象指针实例的属性
所有对象指针数组的元素(objArray)
Compressed class space 压缩类空间
到了Java8,永久代被干掉了,有了“meta space”的概念,存储jvm中的元数据,包括byte code,class等信息。
Java8 在 UseCompressedOops 之外,额外增加了一个新选项叫做 UseCompressedClassPointer。这个选项打开后,class 信息中的指针也用 32bit 的 Compressed 版本。而这些指针指向的空间被称作 Compressed Class Space。默认大小是1G,但可以通过 CompressedClassSpaceSize 调整。
堆内存分配策略
TLAB(内存分配的线程安全考虑)
首先讲讲什么是TLAB。内存分配的动作,可以按照线程划分在不同的空间之中进行,即 **每个线程在Java堆中预先分配一小块内存,称为本地线程分配缓冲(Thread Local Allocation Buffer,TLAB)**。哪个线程需要分配内存,就在哪个线程的TLAB上分配。虚拟机是否使用TLAB,可以通过 -XX:+/-UseTLAB 参数来设定。这么做的目的之一,也是为了并发创建一个对象时,保证创建对象的线程安全性。
TLAB比较小,直接在TLAB上分配内存的方式称为快速分配方式,而TLAB大小不够,导致内存被分配在Eden区的内存分配方式称为慢速分配方式。
一、对象优先在Eden区分配
对象通常在新生代的Eden区进行分配,当Eden区没有足够空间进行分配时,虚拟机将发起一次Minor GC,与Minor GC对应的是Major GC、Full GC。
Minor GC:指发生在新生代的垃圾收集动作,非常频繁,速度较快。
Major GC:指发生在老年代的GC,出现Major GC,经常会伴随一次Minor GC,同时Minor GC也会引起Major GC,一般在GC日志中统称为GC,不频繁。
Full GC:指发生在老年代和新生代的GC,速度很慢,需要Stop The World。
二、大对象直接进入老年代
需要大量连续内存空间的Java对象称为大对象,大对象的出现会导致提前触发垃圾收集以获取更大的连续的空间来进行大对象的分配。虚拟机提供了 -XX:PretenureSizeThreadshold (默认值是0,意思是不管多大都是先在eden中分配内存) 参数来设置大对象的阈值,超过阈值的对象直接分配到老年代。
三、长期存活的对象进入老年代
每个对象有一个对象年龄计数器,与前面的对象的存储布局中的GC分代年龄对应。对象出生在Eden区、经过一次Minor GC后仍然存活,并能够被Survivor容纳,设置年龄为1,对象在Survivor区每次经过一次Minor GC,年龄就加1,当年龄达到一定程度(默认15),就晋升到老年代,虚拟机提供了-XX:MaxTenuringThreshold来进行设置。
四、动态对象年龄判断
对象的年龄到达了MaxTenuringThreshold可以进入老年代,同时,如果在survivor区中相同年龄所有对象大小的总和大于survivor区的一半,年龄大于等于该年龄的对象就可以直接进入老年代。无需等到MaxTenuringThreshold中要求的年龄。
五、老年代空间分配担保
冒险是指经过一次Minor GC后有大量对象存活,而新生代的survivor区很小,放不下这些大量存活的对象,所以需要老年代进行分配担保,把survivor区无法容纳的对象直接进入老年代。
JVM之内存分配与回收策略 - 平凡希
http://www.cnblogs.com/xiaoxi/p/6557473.html
Java内存溢出与内存泄露
内存溢出:简单地说内存溢出就是指程序运行过程中申请的内存大于系统能够提供的内存,导致无法申请到足够的内存,于是就发生了内存溢出。
内存泄漏:内存泄露是指无用对象(不再使用的对象)持续占有内存或无用对象的内存得不到及时释放,从而造成的内存空间的浪费称为内存泄露。
Java内存溢出
堆溢出(OOM:HeapSpace)
java.lang.OutOfMemoryError: Java heap space (堆溢出)
发生这种溢出的原因一般是创建的对象太多,在进行垃圾回收之前对象数量达到了最大堆的容量限制。
解决这个区域异常的方法一般是通过内存映像分析工具对Dump出来的堆转储快照进行分析,看到底是内存溢出还是内存泄漏。如果是内存泄漏,可进一步通过工具查看泄漏对象到GC Roots的引用链,定位出泄漏代码的位置,修改程序或算法;如果不存在泄漏,就是说内存中的对象确实都还必须存活,那就应该检查虚拟机的堆参数-Xmx(最大堆大小)和-Xms(初始堆大小),与机器物理内存对比看是否可以调大。
深递归导致栈溢出(StackOverflow)
写个方法,不断递归调用自己,会导致栈溢出。因为不断向虚拟机栈中压入栈帧,最终导致虚拟机栈(jvm内存划分中的虚拟机栈)内存溢出。
如果线程请求的栈深度大于虚拟机所允许的最大深度,将抛出 StackOverflowError
如果虚拟机在扩展栈时无法申请到足够的内存空间,则抛出 OutOfMemoryError
Java 应用程序唤起一个方法调用时就会在调用栈上分配一个栈帧, 这个栈帧包含引用方法的参数,本地参数,以及方法的返回地址。
这个返回地址是被引用的方法返回后程序能够继续执行的执行点。如果没有一个新的栈帧所需空间,Java 虚拟机就会抛出 StackOverflowError。
java内存溢出示例(堆溢出、栈溢出)
https://www.cnblogs.com/panxuejun/p/5882424.html
Builder 建造者链式递归调用过长导致栈溢出
QueryDSL 的 CaseBuilder 在处理大量 when-then 分支时,采用了递归的数据结构,导致递归深度太大,最终栈溢出。
/**
* Java 版本:21
* QueryDSL 的 CaseBuilder 在处理大量 when-then 分支时,采用了递归的数据结构,导致递归深度太大,最终栈溢出。
*/
@Test
public void testQueryDSLCaseBuilderStackOverFlow() {
int count = 10_000; // 1万层即可打爆JVM默认栈
// 构造 CaseBuilder.Cases 链
CaseBuilder.Cases<Integer, NumberExpression<Integer>> cases = null;
CaseBuilder caseBuilder = new CaseBuilder();
try {
for (int i = 0; i < count; i++) {
NumberExpression<Integer> left = Expressions.numberTemplate(Integer.class, "{0}", i);
NumberExpression<Integer> right = Expressions.numberTemplate(Integer.class, "{0}", -1);
if (Objects.isNull(cases)) {
cases = caseBuilder.when(left.eq(right)).then(i);
} else {
cases = cases.when(left.eq(right)).then(i);
}
}
NumberExpression<Integer> result = cases.otherwise(0);
System.out.println("拼接成功,不应出现此行: " + result);
} catch (StackOverflowError e) {
e.printStackTrace();
}
}
永久代溢出(OOM:PermGen)
永久代是有大小限制的,因此如果加载的类太多,很有可能导致永久代内存溢出,即万恶的 java.lang.OutOfMemoryError: PermGen
1、我们知道jvm通过持久带实现了java虚拟机规范中的方法区,而运行时常量池就是保存在方法区中的,因此发生这种溢出可能是运行时常量池溢出,但 Java 7 之后不可能由于常量池导致 PermGen OOM 溢出了,因为移到了堆里。
2、jvm加载的class信息也是存储在永久代的,所以,由于程序中使用了大量的jar或class,可能使得方法区中保存的class对象没有被及时回收或者class信息占用的内存超过了配置的大小,导致 PermGen OOM。
永久代内存溢出会报 java.lang.OutOfMemoryError: PermGen 异常
内存溢出与内存泄漏 - 平凡希
http://www.cnblogs.com/xiaoxi/p/7354857.html
字符串常量溢出测试(如何写一个方法区溢出的代码?)
通过一段代码来比较 JDK 1.6 与 JDK 1.7及 JDK 1.8 的区别,以字符串常量为例:
public class StringOomMock {
static String base = "string";
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
for (int i=0; i < Integer.MAX_VALUE; i++){
String str = base + base;
base = str;
list.add(str.intern());
}
}
}
JDK 1.6中,报错java.lang.OutOfMemoryError: PermGen space
JDK 1.7中,报错java.lang.OutOfMemoryError: Java heap space
JDK 1.8中,报错java.lang.OutOfMemoryError: Java heap space,此外还会提示PermSize和MaxPermSize参数已失效。
MetaSpace元空间溢出(OOM:MetaSpace)
Java 8 之后使用 元空间 metaspace 代替永久代,元空间在 native heap 上分配,但也是可以指定最大空间的。-XX:MaxMetaspaceSize=100m 设置元空间的最大值。
当我们把 元空间 的最大值设置的过小,而又加载大量类时,就可能出现 OutOfMemoryError: MetaSpace 错误
@Test
public void testMetaspaceOOM() {
while (true) {
// Enhancer可能是CGLIB中最常用的一个类,和Java1.3动态代理中引入的Proxy类差不多。和Proxy不同的是,Enhancer既能够代理普通的class,也能够代理接口。
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(OOMObject.class);
enhancer.setUseCache(false);
enhancer.setCallback((MethodInterceptor) (obj, method, args, proxy) -> proxy.invokeSuper(obj, args));
enhancer.create();
}
}
static class OOMObject {
}
运行一段时间后报错
Exception in thread “main” java.lang.OutOfMemoryError: Metaspace
压缩类空间溢出(OOM:CCS)
到了Java8,永久代被干掉了,有了“meta space”的概念,存储jvm中的元数据,包括 byte code,class 等信息。
Java8 增加了一个新选项叫做 UseCompressedClassPointer
这个选项打开后,class信息中的指针也用32bit的Compressed版本。
而这些指针指向的空间被称作“Compressed Class Space”。默认大小是1G,
但可以通过 CompressedClassSpaceSize 调整。
如果你的java程序引用了太多的包,有可能会造成这个空间不够用,于是会看到
java.lang.OutOfMemoryError: Compressed class space
这时,一般调大CompreseedClassSpaceSize就可以了。
OOM:GC overhead limit exceeded
OutOfMemoryError: GC overhead limit exceeded
JVM 花费了 98% 的时间进行垃圾回收,但只回收了 2% 的堆内存,且进行了5次连续的垃圾回收,JVM 就会曝出 java.lang.OutOfMemoryError: GC overhead limit exceeded 错误。
解决:
增加堆内存大小
Java内存泄露
Java中的内存泄露,广义并通俗的说,就是:不再会被使用的对象的内存不能被回收,就是内存泄露。
在Java中,我们不用(也没办法)自己释放内存,无用的对象由GC自动清理,这也极大的简化了我们的编程工作。但,实际有时候一些不再会被使用的对象,在GC看来不能被释放,就会造成内存泄露。
内存泄漏的根本原因是长生命周期的对象持有短生命周期对象的引用,尽管短生命周期的对象已经不再需要,但由于长生命周期对象持有它的引用而导致不能被回收。
下面总结几种常见的内存泄漏:
集合类中引用不需要的对象
1、静态集合类引起的内存泄漏:
像HashMap、Vector等的使用最容易出现内存泄露,这些静态变量的生命周期和应用程序一致,他们所引用的所有的对象Object也不能被释放,从而造成内存泄漏,因为他们也将一直被Vector等引用着。
Vector<Object> v = new Vector<Object>(100);
for (int i = 1; i<100; i++) {
Object o = new Object();
v.add(o);
o = null;
}
在这个例子中,代码栈中存在Vector 对象的引用 v 和 Object 对象的引用 o 。在 For 循环中,我们不断的生成新的对象,然后将其添加到 Vector 对象中,之后将 o 引用置空。问题是当 o 引用被置空后,如果发生 GC ,我们创建的 Object 对象是否能够被 GC 回收呢?答案是否定的。因为, GC 在跟踪代码栈中的引用时,会发现 v 引用,而继续往下跟踪,就会发现 v 引用指向的内存空间中又存在指向 Object 对象的引用。也就是说尽管 o 引用已经被置空,但是 Object 对象仍然存在其他的引用,是可以被访问到的,所以 GC 无法将其释放掉。如果在此循环之后, Object 对象对程序已经没有任何作用,那么我们就认为此 Java 程序发生了内存泄漏。
放入HashMap/HashSet中的对象取不出
2、修改HashSet中对象的参数值,且参数是计算哈希值的字段
当一个对象被存储到HashSet集合中以后,修改了这个对象中那些参与计算哈希值的字段后,这个对象的哈希值与最初存储在集合中的就不同了,这种情况下,用contains方法在集合中检索对象是找不到的,这将会导致无法从HashSet中删除当前对象,造成内存泄漏
监听器
3、监听器
在 java 编程中,我们都需要和监听器打交道,通常一个应用当中会用到很多监听器,我们会调用一个控件的诸如 addXXXListener() 等方法来增加监听器,但往往在释放对象的时候却没有记住去删除这些监听器,从而增加了内存泄漏的机会。
Connect/File/Session用完不关闭
4、各种连接
比如数据库连接(dataSourse.getConnection()),网络连接(socket)和io连接,除非其显式的调用了其close() 方法将其连接关闭,否则是不会自动被GC 回收的。对于Resultset 和Statement 对象可以不进行显式回收,但Connection 一定要显式回收,因为Connection 在任何时候都无法自动回收,而Connection一旦回收,Resultset 和Statement 对象就会立即为NULL。但是如果使用连接池,情况就不一样了,除了要显式地关闭连接,还必须显式地关闭Resultset Statement 对象(关闭其中一个,另外一个也会关闭),否则就会造成大量的Statement 对象无法释放,从而引起内存泄漏。这种情况下一般都会在try里面去连接,在finally里面释放连接。
单例对象引用外部对象
5、单例模式
如果单例对象持有外部对象的引用,那么这个外部对象将不能被jvm正常回收,导致内存泄露。
不正确使用单例模式是引起内存泄露的一个常见问题,单例对象在被初始化后将在JVM的整个生命周期中存在(以静态变量的方式),如果单例对象持有外部对象的引用,那么这个外部对象将不能被jvm正常回收,导致内存泄露
缓存
缓存通常都是以动态方式实现的,如果缓存设置不正确而大量使用缓存的话则会出现内存溢出的后果,因此需要将所使用的内存容量与检索数据的速度加以平衡。
常用的解决途径是使用 java.lang.ref.SoftReference 类将对象放入缓存。这个方法可以保证当虚拟机用完内存或者需要更多堆的时候,可以释放这些对象的引用。
内存溢出与内存泄漏 - 平凡希
http://www.cnblogs.com/xiaoxi/p/7354857.html
java内存溢出示例(堆溢出、栈溢出)
https://www.cnblogs.com/panxuejun/p/5882424.html
Java内存泄漏分析与解决方案
https://www.cnblogs.com/guozhenqiang/p/5433202.html
堆外内存(直接内存)
使用堆外内存的优点与缺点
堆外内存的好处是:
1、可以扩展至更大的内存空间。比如超过1TB甚至比主存还大的空间(基于操作系统的动态内存换入换出)。
2、理论上能减少GC暂停时间。
3、可以在进程间共享,减少JVM间的对象复制,使得JVM的分割部署更容易实现。
4、它的持久化存储可以支持快速重启,同时还能够在测试环境中重现生产数据。
缺点是:
1、堆外内存难以控制,如果内存泄漏,那么很难排查
2、堆外内存相对来说,不适合存储很复杂的对象。一般简单的对象或者扁平化的比较适合。
Java堆外内存的使用
http://www.importnew.com/14292.html
-XX:MaxDirectMemorySize=40M 参数设置最大堆外内存
通过 sun.misc.Unsafe 类使用堆外内存
Unsafe 类是在 sun.misc 包下,不属于 Java 标准。但是很多 Java 的基础类库(JDK 类库下的 NIO 和 concurrent 包下的很多类都使用到了 Unsafe 类,如 AtomicInteger 和AbstractQueuedSynchronizer 等。),包括一些被广泛使用的高性能开发库都是基于 Unsafe 类开发的,比如 Netty、Cassandra、Hadoop、Kafka 等。Unsafe 类在提升 Java 运行效率、增强 Java 语言底层操作能力方面起了很大的作用。
如何获取Unsafe类实例(反射)
Unsafe 类使用了单例模式,需要通过一个静态方法 getUnsafe() 来获取。但 Unsafe 类做了限制,如果是普通的调用的话,它会抛出一个 SecurityException 异常;只有由主类加载器加载的类才能调用这个方法。
但是我们可以通过反射,在我们的应用代码中获取 Unsafe 类的实例:
public static Unsafe getUnsafeInstance() throws Exception {
// 通过反射获取rt.jar下的Unsafe类
Field theUnsafeInstance = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafeInstance.setAccessible(true);
// return (Unsafe) theUnsafeInstance.get(null);是等价的
return (Unsafe) theUnsafeInstance.get(Unsafe.class);
}
在 eclipse 编写完这个函数之后,会出现错误或者警告提示:
Access restriction: The type Unsafe is not accessible due to restriction on required library C:\Program Files\Java\jdk1.6.0_32\jre\lib\rt.jar。
虽然这段代码在 eclipse 里面会报经过或者报错,但它的却是可以运行的。我们可以在 eclipse 进行如下设置,来取消警告或错误:Window–>Preferences–>Java–>Compiler–>Errors/Warnings,将里面的 Deprecated and restricted API 中的 Forbidden references(access rules) 设置成Ignore,这样eclipse就不会再报警告或者错误了。
java获取Unsafe类的实例和取消eclipse编译的错误和警告
https://blog.csdn.net/aitangyong/article/details/38276681
allocateMemory() 分配堆外内存
import sun.misc.Unsafe;
public class TestUnsafeMemo {
// -XX:MaxDirectMemorySize=40M
public static void main(String[] args) throws Exception {
Unsafe unsafe = GetUsafeInstance.getUnsafeInstance();
while (true) {
long pointer = unsafe.allocateMemory(1024 * 1024 * 20);
System.out.println(unsafe.getByte(pointer + 1));
// 如果不释放内存,运行一段时间会报错java.lang.OutOfMemoryError
// unsafe.freeMemory(pointer);
}
}
}
这段程序会报 OutOfMemoryError 错误,也就是说 allocateMemory 和 freeMemory,相当于 c 语音中的 malloc 和 free,必须手动释放分配的内存。
java中使用堆外内存,关于内存回收需要注意的事和没有解决的遗留问题(等大神解答)
https://blog.csdn.net/aitangyong/article/details/39323125
Unsafe 类提供的功能
Unsafe类提供了以下这些功能:
一、内存管理。包括分配内存、释放内存等。
该部分包括了allocateMemory(分配内存)、reallocateMemory(重新分配内存)、copyMemory(拷贝内存)、freeMemory(释放内存 )、getAddress(获取内存地址)、addressSize、pageSize、getInt(获取内存地址指向的整数)、getIntVolatile(获取内存地址指向的整数,并支持volatile语义)、putInt(将整数写入指定内存地址)、putIntVolatile(将整数写入指定内存地址,并支持volatile语义)、putOrderedInt(将整数写入指定内存地址、有序或者有延迟的方法)等方法。getXXX和putXXX包含了各种基本类型的操作。
利用copyMemory方法,我们可以实现一个通用的对象拷贝方法,无需再对每一个对象都实现clone方法,当然这通用的方法只能做到对象浅拷贝。
二、非常规的对象实例化。allocateInstance() 方法提供了另一种创建实例的途径。通常我们可以用new或者反射来实例化对象,使用allocateInstance()方法可以直接生成对象实例,且无需调用构造方法和其它初始化方法。
这在对象反序列化的时候会很有用,能够重建和设置final字段,而不需要调用构造方法。
三、操作类、对象、变量。
这部分包括了staticFieldOffset(静态域偏移)、defineClass(定义类)、defineAnonymousClass(定义匿名类)、ensureClassInitialized(确保类初始化)、objectFieldOffset(对象域偏移)等方法。
通过这些方法我们可以获取对象的指针,通过对指针进行偏移,我们不仅可以直接修改指针指向的数据(即使它们是私有的),甚至可以找到JVM已经认定为垃圾、可以进行回收的对象。
四、数组操作。
这部分包括了arrayBaseOffset(获取数组第一个元素的偏移地址)、arrayIndexScale(获取数组中元素的增量地址)等方法。arrayBaseOffset与arrayIndexScale配合起来使用,就可以定位数组中每个元素在内存中的位置。
由于Java的数组最大值为Integer.MAX_VALUE,使用Unsafe类的内存分配方法可以实现超大数组。实际上这样的数据就可以认为是C数组,因此需要注意在合适的时间释放内存。
五、多线程同步。包括锁机制、CAS操作等。
这部分包括了monitorEnter、tryMonitorEnter、monitorExit、compareAndSwapInt、compareAndSwap 等方法。
其中monitorEnter、tryMonitorEnter、monitorExit已经被标记为deprecated,不建议使用。
Unsafe类的CAS操作可能是用的最多的,它为Java的锁机制提供了一种新的解决办法,比如AtomicInteger等类都是通过该方法来实现的。
compareAndSwap方法是原子的,可以避免繁重的锁机制,提高代码效率。这是一种乐观锁,通常认为在大部分情况下不出现竞态条件,如果操作失败,会不断重试直到成功。
六、挂起与恢复。
这部分包括了park、unpark等方法。
将一个线程进行挂起是通过park方法实现的,调用 park后,线程将一直阻塞直到超时或者中断等条件出现。unpark可以终止一个挂起的线程,使其恢复正常。整个并发框架中对线程的挂起操作被封装在 LockSupport类中,LockSupport类中有各种版本pack方法,但最终都调用了Unsafe.park()方法。
七、内存屏障。
这部分包括了loadFence、storeFence、fullFence等方法。这是在Java 8新引入的,用于定义内存屏障,避免代码重排序。
loadFence() 表示该方法之前的所有load操作在内存屏障之前完成。同理storeFence()表示该方法之前的所有store操作在内存屏障之前完成。fullFence()表示该方法之前的所有load、store操作在内存屏障之前完成。
说一说Java的Unsafe类
https://www.cnblogs.com/pkufork/p/java_unsafe.html
compareAndSwapInt(对象, 地址, 预期旧值, 新值)
//var1:当前对象,var2:内存地址,var4:预期的旧值,var5:拟更新的新值
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
CAS的用处(原子类/轻量级锁)
1、AtomicInteger 的 自增 incrementAndGet(), 比较交换 compareAndSet() 都是通过 Unsafe 的 compareAndSwapInt() 实现的。
2、synchronized 处于 轻量级 锁状态时,竞争锁的线程通过 CAS 自旋将 锁对象头 中的 mark word 修改为指向自己的指针,如果修改成功则获取锁,修改失败则自旋等待。
通过 NIO 中的 ByteBuffer 使用堆外内存
java.nio 包中的 ByteBuffer 既可以申请堆外直接内存 buffer,也可以申请堆内 buffer。
Understanding Java Buffer Pool
https://dzone.com/articles/understanding-java-buffer-pool
ByteBuffer 属性字段
mark记录了当前所标记的索引下标;position对于写入模式,表示当前可写入数据的下标,对于读取模式,表示接下来可以读取的数据的下标;limit对于写入模式,表示当前可以写入的数组大小,默认为数组的最大长度,对于读取模式,表示当前最多可以读取的数据的位置下标;capacity表示当前数组的容量大小;byte[] array存储数据的字节数组。对于 HeapByteBuffer 就存储在 ByteBuffer 类的byte[] hb字段,对于 DirectByteBuffer 存储在操作系统的内存中。
这些属性总是满足:
0 <= mark <= position <= limit <= capacity
HeapByteBuffer 堆内缓冲区
DirectByteBuffer 通过 ByteBuffer.allocate() 分配获得,是 JVM 堆上的一个 buffer,底层本质是一个字节数组,由 JVM 负责 GC
public abstract class ByteBuffer extends Buffer implements Comparable<ByteBuffer> {
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity);
}
}
DirectByteBuffer 堆外缓冲区
DirectByteBuffer 通过 ByteBuffer.allocateDirect() 分配获得,内部是通过 native 方法 sun.misc.Unsafe.allocateMemory(size); 分配的堆外内存,不在堆中,数据在操作系统的内存中,不受 GC 管理,底层是通过 c 的 malloc 方法申请的内存。
DirectByteBuffer 里维护了一个引用 address 指向操作系统的内存数据,从而操作数据。
优点:跟外设(IO设备)打交道时会快很多,因为外设读取jvm堆里的数据时,不是直接读取的,而是把jvm里的数据读到一个内存块里,再在这个块里读取的,如果使用 DirectByteBuffer,则可以省去这一步,也就是零拷贝(zero copy)
public abstract class ByteBuffer extends Buffer implements Comparable<ByteBuffer> {
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
}
为什么allocateDirect()申请的堆外内存也可以被gc回收?
理论上来说,堆外内存不受 gc 管理,Unsafe.allocateMemory() 申请的内存必须手动通过 Unsafe.freeMemory() 释放。
但用下面的实例测试会发现,ByteBuffer.allocateDirect() 申请的内存也是可以被自动回收的
import java.nio.ByteBuffer;
public class TestDirectByteBuffer {
// -verbose:gc -XX:+PrintGCDetails -XX:MaxDirectMemorySize=40M
public static void main(String[] args) throws Exception {
while (true) {
ByteBuffer buffer = ByteBuffer.allocateDirect(10 * 1024 * 1024);
}
}
}
将最大堆外内存设置成40M,运行这段代码会发现:程序可以一直运行下去,不会报 OutOfMemoryError。如果使用了 -verbose:gc -XX:+PrintGCDetails,会发现程序频繁的进行垃圾回收活动。于是我们可以得出结论:ByteBuffer.allocateDirect 分配的堆外内存不需要我们手动释放,而且 ByteBuffer 中也没有提供手动释放的 API。也即是说,使用 ByteBuffer 不用担心堆外内存的释放问题,除非堆内存中的 ByteBuffer 对象由于错误编码而出现内存泄露。
前提是不加增加 -XX:+DisableExplicitGC 参数,NIO直接内存的回收,需要依赖于 System.gc(),增加 -XX:+DisableExplicitGC 禁用显式 System.gc() 后运行会报错 java.lang.OutOfMemoryError: Direct buffer memory
为什么呢?
因为 DirectByteBuffer 帮我们简化了直接内存的使用,我们不需要直接操作 Unsafe 类来进行直接内存的申请与释放。
class DirectByteBuffer extends MappedByteBuffer implements DirectBuffer {
private final Cleaner cleaner;
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
Bits.reserveMemory(size, cap);
long base = 0;
try {
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}
}
通过 DirectByteBuffer 构造方法的源码,可以看到:
1、直接内存的申请:
DirectByteBuffer 构造方法中通过 base = unsafe.allocateMemory(size); 申请堆外内存
2、直接内存的释放:
申请的直接内存不在 GC 范围之内,但 JDK 提供一种机制,可以为堆内存对象注册一个钩子函数,当堆内存对象被 GC 回收的时候,会回调 run 方法,Unsafe.freeMemory() 就是在此回调方法中被调用从而释放堆外内存的。
可以看到 DirectByteBuffer 构造方法的最后,通过 cleaner = Cleaner.create(this, new Deallocator(base, size, cap)); 创建了一个 Cleaner 对象,保存在 DirectByteBuffer 的 cleaner 字段中。Cleaner 的构造方法 public static Cleaner create(Object ob, Runnable thunk) 第一个参数 ob 是 DirectByteBuffer 对象本身的引用,第二个参数 thunk 是个 Runnable,是清理的代码。
Cleaner 类继承了虚引用 PhantomReference 类,是个虚引用,Java 虚引用允许对象被回收之前做一些清理工作,并且在自己的 clean() 方法中启动了清理线程,当 DirectByteBuffer 被 GC 之前 cleaner 对象会被放入一个引用队列(ReferenceQueue),JVM 会启动一个低优先级线程扫描这个队列,并且执行 Cleaner 的 clean 方法来做清理工作。
public class Cleaner extends PhantomReference<Object> {
public void clean() {
if (!remove(this))
return;
try {
thunk.run();
} catch (final Throwable x) {
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
if (System.err != null)
new Error("Cleaner terminated abnormally", x)
.printStackTrace();
System.exit(1);
return null;
}});
}
}
}
Cleaner 的 clean() 方法中调用了 Deallocator 的 run 方法,其中会调用 unsafe.freeMemory(address); 释放直接内存:
private static class Deallocator implements Runnable {
private static Unsafe unsafe = Unsafe.getUnsafe();
private long address;
private long size;
private int capacity;
private Deallocator(long address, long size, int capacity) {
assert (address != 0);
this.address = address;
this.size = size;
this.capacity = capacity;
}
public void run() {
if (address == 0) {
// Paranoia
return;
}
unsafe.freeMemory(address);
address = 0;
Bits.unreserveMemory(size, capacity);
}
}
3、此外,DirectByteBuffer 构造方法中分配内存之前调用了 Bits.reserveMemory() 方法,如果分配失败调用了 Bits.unreserveMemory(),同时在 Deallocator 释放完直接内存的时候,也调用了 Bits.unreserveMemory 方法。这两个方法,主要是记录jdk已经使用的直接内存的数量,当分配直接内存时,需要进行增加,当释放时,需要减少。
可以认为 Bits 类是直接内存的分配担保,当有足够的直接内存可以用时,增加直接内存应用计数,否则,调用 System.gc(),进行垃圾回收,需要注意的是,System.gc() 只会回收堆内存中的对象,但是我们前面已经讲过,DirectByteBuffer 对象被回收时其引用的直接内存也会被回收,试想现在刚好有其他的 DirectByteBuffer 可以被回收,那么其被回收的直接内存就可以用于本次 DirectByteBuffer 直接的内存的分配。
因此,在使用 Nio 的时候,不要禁用显式 System.gc() 即不要传入 -XX:+DisableExplicitGC 参数,否则可能会造成直接内存溢出
Bits.reserveMemory 流程:
(1)检查当前内存是否超过允许的最大堆外内存(可由 -XX:MaxDirectMemorySize 配置)
(2)如果超出,则会先尝试将不可达的 Reference 对象加入 Reference 链表中,依赖 Reference 的内部守护线程触发可以被回收 DirectByteBuffer 关联的 Cleaner 的 run() 方法
(3)如果内存还是不足, 则执行 System.gc(),触发 full gc,来回收堆内存中的 DirectByteBuffer 对象来触发堆外内存回收
(4)如果还是超过限制,则抛出 java.lang.OutOfMemoryError
static void reserveMemory(long size, int cap) {
// VM.maxDirectMemory() 就是 -XX:MaxDirectMemorySize 的值
if (!memoryLimitSet && VM.isBooted()) {
maxMemory = VM.maxDirectMemory();
memoryLimitSet = true;
}
// optimist! 尝试分配内存
if (tryReserveMemory(size, cap)) {
return;
}
// 尝试将不可达 reference 回收
final JavaLangRefAccess jlra = SharedSecrets.getJavaLangRefAccess();
// retry while helping enqueue pending Reference objects
// which includes executing pending Cleaner(s) which includes
// Cleaner(s) that free direct buffer memory
while (jlra.tryHandlePendingReference()) {
if (tryReserveMemory(size, cap)) {
return;
}
}
// 触发显式gc
// trigger VM's Reference processing
System.gc();
// a retry loop with exponential back-off delays
// (this gives VM some time to do it's job)
boolean interrupted = false;
try {
long sleepTime = 1;
int sleeps = 0;
while (true) {
if (tryReserveMemory(size, cap)) {
return;
}
if (sleeps >= MAX_SLEEPS) {
break;
}
if (!jlra.tryHandlePendingReference()) {
try {
Thread.sleep(sleepTime);
sleepTime <<= 1;
sleeps++;
} catch (InterruptedException e) {
interrupted = true;
}
}
}
// no luck
throw new OutOfMemoryError("Direct buffer memory");
} finally {
if (interrupted) {
// don't swallow interrupts
Thread.currentThread().interrupt();
}
}
}
MappedByteBuffer 文件内存映射缓冲区
MappedByteBuffer 通过 FileChannel.map() 获得,也是一种 DirectByteBuffer,内部通过 c 的 mmap64 零拷贝将文件映射到虚拟内存(本质上是系统调用 mmap()),并记录一个内存地址 addr 在 MappedByteBuffer 中。
Buffers那些事:零拷贝, mmap and Java NIO
https://z.itpub.net/article/detail/693972BA70C6C301E54AD0DFAAA1DE10
MappedByteBuffer 适用于访问磁盘上文件的场景,而DirectByteBuffer 适用于 Java 应用层创建的直接内存;
map 源码如下,如果第一次文件映射导致OOM,则手动触发垃圾回收,休眠100ms后再次尝试映射,如果失败,则抛出异常
public class FileChannelImpl extends FileChannel {
public MappedByteBuffer map(MapMode mode, long position, long size) throws IOException {
... ...
long addr = -1;
int ti = -1;
try {
begin();
ti = threads.add();
if (!isOpen())
return null;
long mapSize;
int pagePosition;
synchronized (positionLock) {
... ...
pagePosition = (int)(position % allocationGranularity);
long mapPosition = position - pagePosition;
mapSize = size + pagePosition;
try {
// If map0 did not throw an exception, the address is valid
addr = map0(imode, mapPosition, mapSize);
} catch (OutOfMemoryError x) {
// An OutOfMemoryError may indicate that we've exhausted
// memory so force gc and re-attempt map
System.gc();
try {
Thread.sleep(100);
} catch (InterruptedException y) {
Thread.currentThread().interrupt();
}
try {
addr = map0(imode, mapPosition, mapSize);
} catch (OutOfMemoryError y) {
// After a second OOME, fail
throw new IOException("Map failed", y);
}
}
} // synchronized
// On Windows, and potentially other platforms, we need an open
// file descriptor for some mapping operations.
FileDescriptor mfd;
try {
mfd = nd.duplicateForMapping(fd);
} catch (IOException ioe) {
unmap0(addr, mapSize);
throw ioe;
}
assert (IOStatus.checkAll(addr));
assert (addr % allocationGranularity == 0);
int isize = (int)size;
Unmapper um = new Unmapper(addr, mapSize, isize, mfd);
if ((!writable) || (imode == MAP_RO)) {
return Util.newMappedByteBufferR(isize,
addr + pagePosition,
mfd,
um);
} else {
return Util.newMappedByteBuffer(isize,
addr + pagePosition,
mfd,
um);
}
} finally {
threads.remove(ti);
end(IOStatus.checkAll(addr));
}
}
}
内存分代与垃圾回收
HotSpot 虚拟机 GC 调节官方手册
Java Platform, Standard Edition HotSpot Virtual Machine Garbage Collection Tuning Guide
https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/index.html
为什么要分代?(生命周期不同)
分代的垃圾回收策略,是基于这样一个事实:不同的对象的生命周期是不一样的。因此,不同生命周期的对象可以采取不同的收集方式,以便提高回收效率。
在Java程序运行的过程中,会产生大量的对象,其中有些对象是与业务信息相关,比如Http请求中的Session对象、线程、Socket连接,这类对象跟业务直接挂钩,因此生命周期比较长。但是还有一些对象,主要是程序运行过程中生成的临时变量,这些对象生命周期会比较短,比如:String对象,由于其不变类的特性,系统会产生大量的这些对象,有些对象甚至只用一次即可回收。
试想,在不进行对象存活时间区分的情况下,每次垃圾回收都是对整个堆空间进行回收,花费时间相对会长,同时,因为每次回收都需要遍历所有存活对象,但实际上,对于生命周期长的对象而言,这种遍历是没有效果的,因为可能进行了很多次遍历,但是他们依旧存在。因此,分代垃圾回收采用分治的思想,进行代的划分,把不同生命周期的对象放在不同代上,不同代上采用最适合它的垃圾回收方式进行回收。
如何分代?
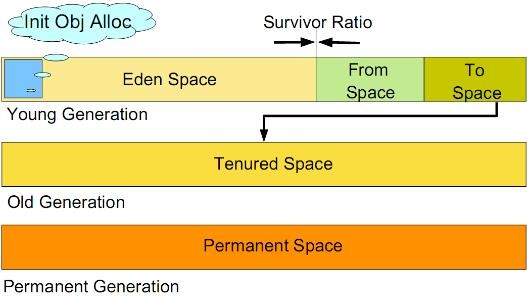
JVM内存分代
https://www.oracle.com/webfolder/technetwork/tutorials/obe/java/gc01/index.html
虚拟机中的共划分为三个代:年轻代(Young Generation)、年老代(Old Generation)和持久代(Permanent Generation)。其中持久代主要存放的是Java类的类信息,与垃圾收集要收集的Java对象关系不大。年轻代和年老代的划分是对垃圾收集影响比较大的。
绝大部分的objec被分配在young generation(生命周期短),并且大部分的object在这里die。当young generation满了之后,将引发minor collection(YGC, young gc)。在minor collection后存活的object会被移动到tenured(old) generation(生命周期比较长)。最后,tenured(old) generation满之后触发major collection(FGC, full gc)。major collection(Full gc)会触发整个heap的回收,包括回收young generation。permanet generation区域比较稳定,主要存放classloader信息。
java 8 之后 jvm 内存分代划分如图,去掉了 永久代,改为 metaspace 元空间。
Java 8前后内存分代对比
新生代(young gen)
新生代又划分为Eden、From Survivor和To Survivor三个部分,他们对应的内存空间的大小比例为8:1:1,也就是,为对象分配内存的时候,首先使用Eden空间,经过GC后,没有被回收的会首先进入From Survivor区域,任何时候,都会保持一个Survivor区域(From Survivor或To Survivor)完全空闲,也就是说新生代的内存利用率最大为90%。From Survivor和To Survivor两个区域会根据GC的实际情况,进行互换,将From Survivor区域中的对象全部复制到To Survivor区域中,或者反过来,将To Survivor区域中的对象全部复制到From Survivor区域中。
为什么需要survivor区?(避免快速填满老年代)
如果没有Survivor,Eden区每进行一次Minor GC,存活的对象就会被送到老年代。老年代很快被填满,触发Major GC(因为Major GC一般伴随着Minor GC,也可以看做触发了Full GC)。老年代的内存空间远大于新生代,进行一次Full GC消耗的时间比Minor GC长得多。
为什么新生代内存需要有两个Survivor区
https://blog.csdn.net/antony9118/article/details/51425581
为什么需要两个survivor区?(避免垃圾碎片)
设置两个Survivor区最大的好处就是解决了碎片化
假设现在只有一个survivor区,我们来模拟一下流程:
1、第一种情况,只在eden分配,survivor只用于接收幸存对象:
刚刚新建的对象在Eden中,一旦Eden满了,触发一次Minor GC,Eden中的存活对象就会被移动到Survivor区。这样继续循环下去,下一次Eden满了的时候,问题来了,此时进行Minor GC,Eden和Survivor各有一些存活对象,如果此时把Eden区的存活对象硬放到Survivor区,很明显这两部分对象所占有的内存是不连续的,也就导致了内存碎片化。
2、第二种情况,像原始 复制清除算法一样,eden 和 survivor 中都可以创建对象
在 HotSpot 虚拟机里, Eden 空间和 Survivor 空间默认的比例是 8:1 。我们来看看在只有一个 Survivor 空间的情况下,这个 8:1 会有什么问题。此处为了方便说明,我们假设新生代一共为 9 MB 。对象优先在 Eden 区分配,当 Eden 空间满 8 MB 时,触发第一次 Minor GC 。比如说有 0.5 MB 的对象存活,那这 0.5 MB 的对象将由 Eden 区向 Survivor 区复制。这次 Minor GC 过后, Eden 区被清理干净, Survivor 区被占用了 0.5 MB ,还剩 0.5 MB 。到这里一切都很美好,但问题马上就来了:从现在开始所有对象将会在这剩下的 0.5 MB 的空间上被分配,很快就会发现空间不足,于是只好触发下一次 Minor GC 。可以看出在这种情况下,当 Survivor 空间作为对象“出生地”的时候,很容易触发 Minor GC ,这种 8:1 的不对称分配不但没能在总体上降低 Minor GC 的频率,还会把 gc 的时间间隔搞得很不平均。
两个survivor区大小一定相等吗?(scavenge动态调节)
两个 survivor 区大小一定相等吗?不一定,可动态调节
Parallel Scavenge 收集器有个参数 -XX:+UseAdaptiveSizePolicy,设置此选项后,并行收集器会自动选择年轻代大小(-Xmn)、eden和Survivor区比例(-XX:SurvivorRatio)、晋升老年代年龄(-XX:PretenureSizeThreshold)等参数,以达到目标系统规定的最低相应时间或者收集频率等,此值建议使用并行收集器时,一直打开。
Java 垃圾回收的log,为什么 from和to大小不等?
https://www.zhihu.com/question/65601024
如何配置新生代大小?(-XX:NewRatio=4)
-XX:NewRatio
年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代)
-XX:NewRatio=4表示年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5
Xms=Xmx并且设置了Xmn的情况下,该参数不需要进行设置。
-XX:NewRatio=n,表示老年代是年轻代的n倍,即老年代:年轻代 = n:1,即年轻代占堆大小的1/(n+1)
一般情况下,不允许-XX:Newratio值小于1,即Old要比Yong大。
如何配置survivor区大小?(-XX:SurvivorRatio=8)
-XX:SurvivorRatio
Eden区与Survivor区的大小比值
设置为8,则两个Survivor区与一个Eden区的比值为2:8,一个Survivor区占整个年轻代的1/10
-XX:SurvivorRatio=n,表示eden和两个survivor区的比值为n:2,即2个survivor占年轻代总大小的2/(n+2)
-XX:+UseAdaptiveSizePolicy,JVM默认开启survivor区大小自动变化的参数
老年代(tenured(old) gen)
在年轻代中经历了N次垃圾回收后仍然存活的对象,就会被放到年老代中。因此,可以认为年老代中存放的都是一些生命周期较长的对象。
GC过程中,当某些对象经过多次GC都没有被回收,可能会进入到年老代。或者,当新生代没有足够的空间来为对象分配内存时,可能会直接在年老代进行分配。
什么情况下对象会进入老年代?
有以下几种情况:
1、大对象:占用空间超过 -XX:PretenureSizeThreadshold (默认值是0,意思是不管多大都是先在eden中分配内存)的大对象直接分配到老年代。
2、老对象:年轻代中每经过一次 minor gc,对象年龄加1,当年龄超过 -XX:MaxTenuringThreshold 默认值15,则进入老年代。
3、年龄相同的多数对象:在survivor区中相同年龄所有对象大小的总和大于survivor区的一半,年龄大于等于该年龄的对象就可以直接进入老年代。无需等到 MaxTenuringThreshold 中要求的年龄。
4、老年代分配担保:年轻代 minor gc 后,幸存的对象如果 survivor 放不下,老年代会进行担保分配,这时会有对象进入老年代。
什么时候会触发Full GC?
Full gc是对整个堆进行整理,包括Young、Tenured和Perm。
Full GC因为需要对整个块进行回收,所以比young GC要慢,因此应该尽可能减少Full GC的次数。
在对JVM调优的过程中,很大一部分工作就是对于FullGC的调节。
有如下原因可能导致Full GC:
- 年老代(Tenured)被写满,又分为两种情况:Promotion Failed(老年代担保失败),Concurrent Mode Failed(GC完成前老年代再次被填满)
- 持久代(Perm)被写满
- System.gc()被显示调用
- heap dump会触发full gc
Promotion Failed(老年代担保失败)
当准备要触发一次young GC时,如果发现统计数据说之前young GC的平均晋升大小比目前old gen剩余的空间大,则不会触发young GC而是转为触发full GC
Concurrent Mode Failed(GC完成前老年代再次被填满)
如果老年代回收比较慢,在 old GC 完成前老年代再次被填满,则会再次触发 full gc,这叫做 “并发模式失败”
永久代perm gen被填满
手动调用System.gc()
heap dump会触发full gc
持久代(方法区)(permanent gen)
用于存放静态文件,如今Java类、方法等。
持久代对垃圾回收没有显著影响,但是有些应用可能动态生成或者调用一些class,例如Hibernate等,在这种时候需要设置一个比较大的持久代空间来存放这些运行过程中新增的类。持久代大小通过-XX:MaxPermSize进行设置。
永久代实际上对应着虚拟机运行时数据区的“方法区”,这里主要存放类信息、静态变量、常量等数据。一般情况下,永久代中对应的对象的GC效率非常低,因为这里的的大部分对象在运行都不要进行GC,它们会一直被利用,直到JVM退出。
JVM分代垃圾回收策略的基础概念 - 平凡希
http://www.cnblogs.com/xiaoxi/p/6602166.html
方法区gc(废弃常量,无用的类)
永久代的垃圾收集主要回收两部分内容:废弃常量和无用的类。
废弃常量
回收废弃常量与回收Java堆中的对象非常类似。以常量池中字面量的回收为例,假如一个字符串“abc”已经进入了常量池中,但是当前系统没有任何一个String对象是叫做“abc”的,换句话说是没有任何String对象引用常量池中的“abc”常量,也没有其他地方引用了这个字面量,如果在这时候发生内存回收,而且必要的话,这个“abc”常量就会被系统“请”出常量池。常量池中的其他类(接口)、方法、字段的符号引用也与此类似。
无用的类
方法区中的类需要同时满足以下三个条件才能被标记为无用的类:
1、该类所有的实例都已经被回收,也就是Java堆中不存在该类的任何实例。
2、加载该类的类加载器 ClassLoader 已经被回收。
3、该类对应的 java.lang.Class 对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
当满足上述三个条件的类才可以被回收,但是并不是一定会被回收,需要参数进行控制,例如 HotSpot 虚拟机提供了 -Xnoclassgc 参数进行控制是否回收。
虚拟机可以对满足上述3个条件的无用类进行回收,这里说的仅仅是“可以”,而不是和对象一样,不使用了就必然会回收。是否对类进行回收,HotSpot虚拟机提供了-Xnoclassgc参数进行控制,还可以使用-verbose:class及-XX:+TraceClassLoading、 -XX:+TraceClassUnLoading查看类的加载和卸载信息。
什么情况下要关注方法区gc?(反射,代理等动态生成类时)
在大量使用反射、动态代理、CGLib等bytecode框架的场景,以及动态生成JSP和OSGi这类频繁自定义ClassLoader的场景都需要虚拟机具备类卸载的功能,以保证永久代不会溢出。
jvm回收方法区
https://www.cnblogs.com/vinozly/p/5076920.html
哪些内存(对象)需要被回收?
哪些内存需要回收是垃圾回收机制第一个要考虑的问题,所谓“要回收的垃圾”无非就是那些不可能再被任何途径使用的对象。那么如何找到这些对象?
引用计数法
这个算法的实现是,给对象中添加一个引用计数器,每当一个地方引用这个对象时,计数器值+1;当引用失效时,计数器值-1。任何时刻计数值为0的对象就是不可能再被使用的。这种算法使用场景很多,但是,Java中却没有使用这种算法,因为这种算法很难解决对象之间相互引用的情况。
可达性分析法(根搜索算法root tracing)
这个算法的基本思想是通过一系列称为“GC Roots”的对象作为起始点,从这些节点向下搜索,搜索所走过的路径称为引用链,当一个对象到GC Roots没有任何引用链(即GC Roots到对象不可达)时,则证明此对象是不可用的。
那么问题又来了,如何选取GC Roots对象呢?
在Java语言中,可以作为GC Roots的对象包括下面几种:
(1) 虚拟机栈(栈帧中的局部变量区,也叫做局部变量表)中引用的对象。
(2) 本地方法栈中JNI(Native方法)引用的对象。
(3) 方法区中的类静态属性引用的对象。
(4) 方法区中常量引用的对象。
不可达对象一定被回收吗?(两次标记,finalize()方法)
对于可达性分析算法而言,未到达的对象并非是“非死不可”的,若要宣判一个对象死亡,至少需要经历两次标记阶段。
1、 如果对象在进行可达性分析后发现没有与GCRoots相连的引用链,则该对象被第一次标记并进行一次筛选,筛选条件为是否有必要执行该对象的finalize方法,
当遇到以下两种情况时,虚拟机将视为“没有必要执行”:
- 若对象没有覆盖finalize方法
- finalize方法已经被虚拟机执行过了
则均视作不必要执行该对象的finalize方法,即该对象将会被回收。
反之,若对象覆盖了finalize方法并且该finalize方法并没有被执行过,那么,这个对象会被放置在一个叫 F-Queue 的队列中,之后会由虚拟机自动建立的、优先级低的 Finalizer 线程去执行,而虚拟机不必要等待该线程执行结束,即虚拟机只负责建立线程,其他的事情交给此线程去处理。
2、对 F-Queue 中对象进行第二次标记,如果对象在finalize方法中拯救了自己,即关联上了GCRoots引用链,如把this关键字赋值给其他变量,那么在第二次标记的时候该对象将从“即将回收”的集合中移除,如果对象还是没有拯救自己,那就会被回收。如下代码演示了一个对象如何在finalize方法中拯救了自己,然而,它只能拯救自己一次,第二次就被回收了。
Java垃圾回收(GC)机制详解 - 平凡希
http://www.cnblogs.com/xiaoxi/p/6486852.html
Java中的四种引用方式(强软弱虚)
java对象的引用包括:强引用,软引用,弱引用,虚引用
Java 如何有效地避免OOM:善于利用软引用和弱引用 - 海子
http://www.cnblogs.com/dolphin0520/p/3784171.html
强引用(StrongReference)
强引用就是指在程序代码之中普遍存在的,比如下面这段代码中的 object 和 str 都是强引用:
Object object = new Object();
String str = "hello";
只要某个对象有强引用与之关联,JVM 必定不会回收这个对象,即使在内存不足的情况下,JVM 宁愿抛出 OutOfMemory 错误也不会回收这种对象。
如果想中断强引用和某个对象之间的关联,可以显示地将引用赋值为null,这样一来的话,JVM在合适的时间就会回收该对象。
强引用在实际中有非常重要的用处,举个 ArrayList 的实现源代码:
private transient Object[] elementData;
public void clear() {
modCount++;
// Let gc do its work
for (int i = 0; i < size; i++)
elementData[i] = null;
size = 0;
}
在 ArrayList 类中定义了一个私有的变量 elementData 数组,在调用方法清空数组时可以看到为每个数组内容赋值为null。不同于elementData=null,强引用仍然存在,避免在后续调用 add() 等方法添加元素时进行重新的内存分配。使用如 clear() 方法中释放内存的方法对数组中存放的引用类型特别适用,这样就可以及时释放内存。
软引用(SoftReference)
软引用是用来描述一些有用但并不是必需的对象,在 Java 中用 java.lang.ref.SoftReference 类来表示。对于软引用关联着的对象,只有在内存不足的时候JVM才会回收该对象。因此,这一点可以很好地用来解决 OOM 的问题,并且这个特性很适合用来实现缓存:比如网页缓存、图片缓存等。
软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被JVM回收,这个软引用就会被加入到与之关联的引用队列中。下面是一个使用示例:
import java.lang.ref.SoftReference;
public class Main {
public static void main(String[] args) {
SoftReference<String> sr = new SoftReference<String>(new String("hello"));
System.out.println(sr.get());
}
}
弱引用(WeakReference)
弱引用也是用来描述非必需对象的,当 JVM 进行垃圾回收时,无论内存是否充足,都会回收被弱引用关联的对象。
package java.lang.ref;
public class WeakReference<T> extends Reference<T> {
public WeakReference(T referent) {
super(referent);
}
public WeakReference(T referent, ReferenceQueue<? super T> q) {
super(referent, q);
}
}
使用示例:
import java.lang.ref.WeakReference;
public class Main {
public static void main(String[] args) {
WeakReference<String> sr = new WeakReference<String>(new String("hello"));
System.out.println(sr.get());
System.gc(); //通知JVM的gc进行垃圾回收
System.out.println(sr.get());
}
}
输出结果为:
hello
null
第二个输出结果是null,这说明只要JVM进行垃圾回收,被弱引用关联的对象必定会被回收掉。不过要注意的是,这里所说的被弱引用关联的对象是指只有弱引用与之关联,如果存在强引用同时与之关联,则进行垃圾回收时也不会回收该对象(软引用也是如此)。
弱引用队列
弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被JVM回收,这个弱引用就会被加入到与之关联的引用队列中。
WeakReference 有个带引用队列的构造方法,在对象被回收后,会把弱引用对象,也就是 WeakReference 对象或者其子类的对象,放入队列 ReferenceQueue 中,注意不是被弱引用的对象,被弱引用的对象已经被回收了。
ReferenceQueue<Object> referenceQueue = new ReferenceQueue<>();
WeakReference weakReference2 = new WeakReference<>(new Object(), referenceQueue);
等 weakReference2 引用的对象被 GC 回收后,weakReference2 会被加入到 referenceQueue 队列中
虚引用(PhantomReference)
虚引用和前面的软引用、弱引用不同,它并不影响对象的生命周期。在java中用 java.lang.ref.PhantomReference 类表示。如果一个对象与虚引用关联,则跟没有引用与之关联一样,在任何时候都可能被垃圾回收器回收。
要注意的是,虚引用必须和引用队列关联使用,当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会把这个虚引用加入到与之关联的引用队列中。程序可以通过判断引用队列中是否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。如果程序发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动。
import java.lang.ref.PhantomReference;
import java.lang.ref.ReferenceQueue;
public class Main {
public static void main(String[] args) {
ReferenceQueue<String> queue = new ReferenceQueue<String>();
PhantomReference<String> pr = new PhantomReference<String>(new String("hello"), queue);
System.out.println(pr.get());
}
}
为什么需要软引用和弱引用?(干预gc和生命周期)
java内存管理分为内存分配和内存回收,都不需要程序员负责,垃圾回收的机制主要是看对象是否有引用指向该对象。
在Java中,虽然不需要程序员手动去管理对象的生命周期,但是如果希望某些对象具备一定的生命周期的话(比如内存不足时JVM就会自动回收某些对象从而避免OutOfMemory的错误)就需要用到软引用和弱引用了。
Java中提供这四种引用类型主要有两个目的:
第一是可以让程序员通过代码的方式决定某些对象的生命周期;
第二是有利于JVM进行垃圾回收。
什么情况下使用软/弱/虚引用?
使用得最多的就是软引用和弱引用,这2种既有相似之处又有区别。它们都是用来描述非必需对象的,但是被软引用关联的对象只有在内存不足时才会被回收,而被弱引用关联的对象在JVM进行垃圾回收时总会被回收。
弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。
什么时候使用软引用?
想让对象保留尽量长的时间,但又不会因此导致内存溢出OOM,此时应使用软引用
软引用非常适合于创建缓存。当系统内存不足的时候,缓存中的内容是可以被释放的。比如考虑一个图像编辑器的程序。该程序会把图像文件的全部内容都读取到内存中,以方便进行处理。而用户也可以同时打开多个文件。当同时打开的文件过多的时候,就可能造成内存不足。如果使用软引用来指向图像文件内容的话,垃圾回收器就可以在必要的时候回收掉这些内存。
什么时候使用弱引用?
如果这个对象是偶尔的使用,并且希望在使用时随时就能获取到,但又不想影响此对象的垃圾收集(或者说不想介入这个对象的生命周期),那么你应该用 Weak Reference 来记住此对象。
虚引用有什么用?
虚引用允许你知道具体何时其引用的对象从内存中移除。
而实际上这是Java中唯一的方式。这一点尤其表现在处理类似图片的大文件的情况。当你确定一个图片数据对象应该被回收,你可以利用虚引用来判断这个对象回收之后在继续加载下一张图片。这样可以尽可能地避免可怕的内存溢出错误。
Java 7之基础 - 强引用、弱引用、软引用、虚引用
http://blog.csdn.net/mazhimazh/article/details/19752475
Java的四种引用方式
https://www.cnblogs.com/huajiezh/p/5835618.html
垃圾收集算法
标记-清除(Mark-Sweep)算法
这是最基础的算法,标记-清除算法就如同它的名字样,分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,标记完成后统一回收所有被标记的对象。
这种算法的不足主要体现在效率和空间,从效率的角度讲,标记和清除两个过程的效率都不高;从空间的角度讲,标记清除后会产生大量不连续的内存碎片, 内存碎片太多可能会导致以后程序运行过程中在需要分配较大对象时,无法找到足够的连续内存而不得不提前触发一次垃圾收集动作。
复制(Copying)算法(新生代)
复制算法是为了解决效率问题而出现的,它将可用的内存分为两块,每次只用其中一块,当这一块内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已经使用过的内存空间一次性清理掉。这样每次只需要对整个半区进行内存回收,内存分配时也不需要考虑内存碎片等复杂情况,只需要移动指针,按照顺序分配即可。
把一块内存一分为二, gc 时把存活的对象从一块空间(From space)复制到另外一块空间(To space),再把原先的那块内存(From space)清理干净,最后调换 From space 和 To space 的逻辑角色(这样下一次 gc 的时候还可以按这样的方式进行)。
为什么新生代分为eden和survivor(基于复制算法)
不过这种算法有个缺点,内存缩小为了原来的一半,这样代价太高了。现在的商用虚拟机都采用这种算法来回收新生代,不过研究表明1:1的比例非常不科学,因此新生代的内存被划分为一块较大的Eden空间和两块较小的Survivor空间,每次使用Eden和其中一块Survivor。每次回收时,将Eden和Survivor中还存活着的对象一次性复制到另外一块Survivor空间上,最后清理掉Eden和刚才用过的Survivor空间。HotSpot虚拟机默认Eden区和Survivor区的比例为8:1:1,意思是每次新生代中可用内存空间为整个新生代容量的90%。当然,我们没有办法保证每次回收都只有不多于10%的对象存活,当Survivor空间不够用时,需要依赖老年代进行分配担保(Handle Promotion)。
标记-整理(Mark-Compact)算法(老年代)
复制算法在对象存活率较高的场景下要进行大量的复制操作,效率很低。万一对象100%存活,那么需要有额外的空间进行分配担保。老年代都是不易被回收的对象,对象存活率高,因此一般不能直接选用复制算法。根据老年代的特点,有人提出了另外一种标记-整理算法,过程与标记-清除算法一样,不过不是直接对可回收对象进行清理,而是让所有存活对象都向一端移动,然后直接清理掉边界以外的内存。
分代应用不同回收算法
现代商用虚拟机基本都采用分代收集算法来进行垃圾回收。这种算法没什么特别的,无非是上面内容的结合罢了,根据对象的生命周期的不同将内存划分为几块,然后根据各块的特点采用最适当的收集算法。
大批对象死去、少量对象存活的(新生代),使用复制算法,复制成本低;
对象存活率高、没有额外空间进行分配担保的(老年代),采用标记-清理算法或者标记-整理算法。
Java垃圾回收(GC)机制详解 - 平凡希
http://www.cnblogs.com/xiaoxi/p/6486852.html
GC执行方式(collector种类)
jvm中GC执行的三种方式,即串行收集、并行收集、并发收集;
默认情况下,JDK5.0以前都是使用串行收集器,如果想使用其他收集器需要在启动时加入相应参数。JDK5.0以后,JVM会根据当前系统配置进行判断。
- 串行收集(SerialGC),是jvm的默认GC方式,一般适用于小型应用和单处理器,算法比较简单,GC效率也较高,但可能会给应用带来停顿。
- 并行收集(ParallelGC),是指GC运行时,对应用程序运行没有影响,GC和app两者的线程在并发执行,这样可以最大限度不影响app的运行。并行收集器主要以到达一定的吞吐量为目标,适用于科学技术和后台处理等。
- 并发收集(ConcMarkSweepGC),是指多个线程并发执行GC,一般适用于多处理器系统中,可以提高GC的效率,但算法复杂,系统消耗较大。并发收集器主要是保证系统的响应时间,减少垃圾收集时的停顿时间。适用于应用服务器、电信领域等。
垃圾收集器
jvm中GC执行的三种方式,即串行收集、并行收集、并发收集;
默认情况下,JDK5.0以前都是使用串行收集器,如果想使用其他收集器需要在启动时加入相应参数。JDK5.0以后,JVM会根据当前系统配置进行判断。
Serial收集器(-XX:+UseSerialGC)
串行收集(SerialGC),是jvm的默认GC方式,一般适用于小型应用和单处理器,算法比较简单,GC效率也较高,但可能会给应用带来停顿。
最基本、发展历史最久的收集器,这个收集器是一个采用复制算法的单线程的收集器,单线程一方面意味着它只会使用一个CPU或一条线程去完成垃圾收集工作,另一方面也意味着它进行垃圾收集时必须暂停其他线程的所有工作,直到它收集结束为止。后者意味着,在用户不可见的情况下要把用户正常工作的线程全部停掉,这对很多应用是难以接受的。
不过实际上到目前为止,Serial收集器依然是虚拟机运行在Client模式下的默认新生代收集器,因为它简单而高效。
用户桌面应用场景中,分配给虚拟机管理的内存一般来说不会很大,收集几十兆甚至一两百兆的新生代停顿时间在几十毫秒最多一百毫秒,只要不是频繁发生,这点停顿是完全可以接受的。
ParNew收集器(-XX:+UseParNewGC)
ParNew收集器其实就是Serial收集器的多线程版本,除了使用多条线程进行垃圾收集外,其余行为和Serial收集器完全一样,包括使用的也是复制算法。
ParNew收集器除了多线程以外和Serial收集器并没有太多创新的地方,但是它却是Server模式下的虚拟机首选的新生代收集器,其中有一个很重要的和性能无关的原因是,除了Serial收集器外,目前只有它能与CMS收集器配合工作。
CMS收集器是一款几乎可以认为有划时代意义的垃圾收集器,因为它第一次实现了让垃圾收集线程与用户线程基本上同时工作。
新生代 ParNew 最适合与 老年代 CMS 搭配使用,所以使用很广泛:-XX:+UseConcMarkSweepGC -XX:+UseParNewGC
ParNew收集器在单CPU的环境中绝对不会有比Serial收集器更好的效果,甚至由于线程交互的开销,该收集器在两个CPU的环境中都不能百分之百保证可以超越Serial收集器。
当然,随着可用CPU数量的增加,它对于GC时系统资源的有效利用还是很有好处的。
它默认开启的收集线程数与CPU数量相同,在CPU数量非常多的情况下,可以使用-XX:ParallelGCThreads参数来限制垃圾收集的线程数。
Parallel Scavenge收集器(-XX:+UseParallelGC)
Parallel Scavenge 收集器也是一个新生代收集器,也是用复制算法的收集器,也是并行的多线程收集器,但是它的特点是它的关注点和其他收集器不同。
介绍这个收集器主要还是介绍吞吐量的概念。CMS等收集器的关注点是尽可能缩短垃圾收集时用户线程的停顿时间,而Parallel Scavenge收集器的目标则是达到一个可控制的吞吐量。
所谓吞吐量的意思就是CPU用于运行用户代码时间与CPU总消耗时间的比值,即吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间),虚拟机总运行100分钟,垃圾收集1分钟,那吞吐量就是99%。
另外,Parallel Scavenge收集器是虚拟机运行在Server模式下的默认垃圾收集器。
停顿时间短适合需要与用户交互的程序,良好的响应速度能提升用户体验;高吞吐量则可以高效率利用CPU时间,尽快完成运算任务,主要适合在后台运算而不需要太多交互的任务。
虚拟机提供了-XX:MaxGCPauseMillis和-XX:GCTimeRatio两个参数来精确控制最大垃圾收集停顿时间和吞吐量大小。
不过不要以为前者越小越好,GC停顿时间的缩短是以牺牲吞吐量和新生代空间换取的。
由于与吞吐量关系密切,Parallel Scavenge收集器也被称为吞吐量优先收集器。
Parallel Scavenge收集器有一个-XX:+UseAdaptiveSizePolicy参数,这是一个开关参数,这个参数打开之后,就不需要手动指定新生代大小、Eden区和Survivor参数等细节参数了,虚拟机会根据当前系统的运行情况手机性能监控信息,动态调整这些参数以提供最合适的停顿时间或者最大的吞吐量。如果对于垃圾收集器运作原理不太了解,以至于在优化比较困难的时候,使用Parallel Scavenge收集器配合自适应调节策略,把内存管理的调优任务交给虚拟机去完成将是一个不错的选择。
新生代 Scavenge 收集器 -XX:+UseParallelGC 和 老年代 ParOld 收集器是不错的搭档 -XX:+UseParallelOldGC ,是 java 7,8中的默认收集器配置
Serial Old收集器
Serial收集器的老年代版本,同样是一个单线程收集器,使用标记-整理算法,
这个收集器的主要意义也是在于给Client模式下的虚拟机使用。
Parallel Old收集器(-XX:+UseParallelOldGC)
Parallel Scavenge收集器的老年代版本,使用多线程和标记-整理算法。
这个收集器在JDK 1.6之后的出现,“吞吐量优先收集器”终于有了比较名副其实的应用组合,在注重吞吐量以及CPU资源敏感的场合,都可以优先考虑Parallel Scavenge收集器+Parallel Old收集器的组合。
CMS收集器(-XX:+UseConcMarkSweepGC)
CMS(Conrrurent Mark Sweep)收集器是以获取最短回收停顿时间为目标的收集器。使用标记-清除算法,收集过程分为如下四步:
收集步骤
初始标记(STW)
(1) 初始标记(initial mark) 需要 STW(Stop The World)
标记 GC Roots 能直接关联到的对象,时间很短。
本阶段需要 stop the world,一是标记老年代中所有的 GC Roots 所指的直接对象;二是标记被年轻代中存活对象引用的直接对象。因为仅标记少量节点,所以很快就能完成。
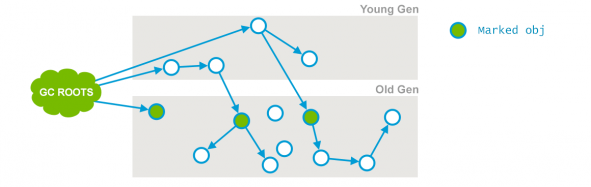
CMS初始标记
并发标记
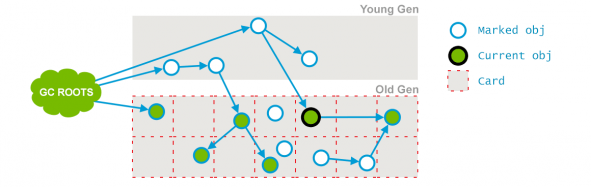
(2) 并发标记(concurrent mark)
进行 GC Roots Tracing(可达性分析)过程,由前阶段标记过的对象出发,所有可到达的对象都在本阶段中标记。时间很长。
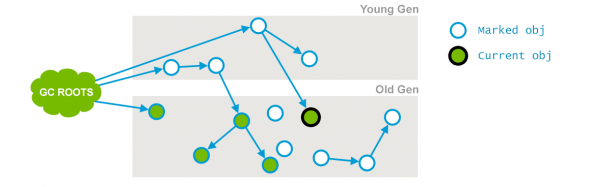
CMS并发标记
在初始标记的基础上继续往下遍历其他的对象引用并进行标记,该过程会和用户线程并发地执行,不会发生停顿。这个阶段会从 initial mark 阶段中所标记的节点往下检索,标记出所有老年代中存活的对象。注意此时会有部分对象的引用被改变,如上图中的 current obj 原本所引用的节点已经失去了关联。
并发预清理
(3) 并发预清理(concurrent preclean)
前一个阶段在并行运行的时候,一些对象的引用已经发生了变化,当这些引用发生变化的时候,JVM会标记堆的这个区域为Dirty Card,这就是 Card Marking。
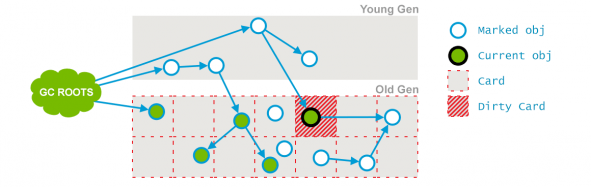
引用发生变化的card table 页标为dirty
current obj 的引用发生了变化后,所在的块被标记为了 dirty card
CMS并发预清理
在本阶段,那些能够从 dirty card 对象到达的对象也会被标记,这个标记做完之后,dirty card 标记就会被清除了,如上图所示。
总的来说,本阶段会并发地更新并发标记阶段的引用变化和查找在并发标记阶段新进入老年代的对象,如刚晋升的对象和直接被分配在老年代的对象。通过重新扫描,以减少下一阶段的工作。
(4) 可中止的并发预清理(concurrent abortable preclean)
这个阶段尝试着去承担 STW 的 Final Remark 阶段足够多的工作。这个阶段持续的时间依赖好多的因素,由于这个阶段是重复的做相同的事情直到发生 aboart 的条件之一(比如:重复的次数、多少量的工作、持续的时间等等)才会停止。
最终标记(STW)
(5) 重新标记/最终标记 (final remark) 需要 STW(Stop The World)
修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,时间较长。
本阶段需要 stop the world,通常来说此次暂时都会比较长,因为并发预清理是并发执行的,对象的引用可能会发生进一步的改变,需要确保在清理之前保持一个正确的对象引用视图,那么就需要stop the world来处理复杂的情况。
并发清除
(6) 并发清除(concurrent sweep)
回收内存空间,时间很长。
CMS并发清理
1 对CPU资源非常敏感,可能会导致应用程序变慢,吞吐率下降。
2 无法处理浮动垃圾,因为在并发清理阶段用户线程还在运行,自然就会产生新的垃圾,而在此次收集中无法收集他们,只能留到下次收集,这部分垃圾为浮动垃圾,同时,由于用户线程并发执行,所以需要预留一部分老年代空间提供并发收集时程序运行使用。
3 由于采用的标记 - 清除算法,会产生大量的内存碎片,不利于大对象的分配,可能会提前触发一次Full GC。虚拟机提供了 -XX:+UseCMSCompactAtFullCollection 参数来进行碎片的合并整理过程,这样会使得停顿时间变长,虚拟机还提供了一个参数配置 -XX:+CMSFullGCsBeforeCompaction,用于设置执行多少次不压缩的Full GC后,接着来一次带压缩的GC。
G1收集器与CMS收集器的对比与实战(CMS和G1的过程非常详细,都有配图)
https://blog.chriscs.com/2017/06/20/g1-vs-cms/
Card Table 卡表
现代JVM,堆空间通常被划分为新生代和老年代。由于新生代的垃圾收集通常很频繁,如果老年代对象引用了新生代的对象,那么,需要跟踪从老年代到新生代的所有引用,从而避免每次YGC时扫描整个老年代,减少开销。
对于HotSpot JVM,使用了卡标记(Card Marking)技术来解决老年代到新生代的引用问题。具体是,使用卡表(Card Table)和写屏障(Write Barrier)来进行标记并加快对GC Roots的扫描。
基于卡表(Card Table)的设计,通常将堆空间划分为一系列2次幂大小的卡页(Card Page)。
卡表(Card Table),用于标记卡页的状态,每个卡表项对应一个卡页。
HotSpot JVM的卡页(Card Page)大小为512字节,卡表(Card Table)被实现为一个简单的字节数组,即卡表的每个标记项为1个字节。
当对一个对象引用进行写操作时(对象引用改变),写屏障逻辑将会标记对象所在的卡页为dirty。
card table 卡表的用处(加速查找跨代引用)
1、young gc时,扫描 card table 的 dirty card 就可以知道哪些老年代对象引用了新生代对象。也就是 加速查找跨代引用。
2、cms 并发标记阶段会把 增量变化对象的 Card 标识为 Dirty,这样后续阶段就只需要扫描这些 Dirty Card 的对象,从而避免扫描整个老年代。
CMS垃圾回收机制
https://www.cnblogs.com/Leo_wl/p/5393300.html?utm_medium=referral&utm_source=itdadao
Promotion Failed(老年代担保失败)
由于CMS没有任何的碎片整理机制,所以会产生大量的堆碎片。
因此可能会发生即使堆的大小没有耗尽,但是从新生代晋升至老年代却失败的情况。
此时会fallback为Serial Old从而引起一次full GC(会进行碎片整理)。
可以增加老年代的大小和Survivor区的大小以减少full GC的发生。
Concurrent Mode Failed(GC完成前老年代再次被填满)
如果对象分配率高于CMS回收的效率,将导致在CMS完成之前老年代就被填满,这种状况成为“并发模式失败”,同样也会引起full GC。
可以调节-XX:CMSInitiatingOccupancyFraction和新生代的堆大小。
G1收集器与CMS收集器的对比与实战(CMS和G1的过程非常详细,都有配图)
https://blog.chriscs.com/2017/06/20/g1-vs-cms/
G1收集器(-XX:+UseG1GC)
Getting Started with the G1 Garbage Collector - Oracle 官方文档
https://www.oracle.com/technetwork/tutorials/tutorials-1876574.html
G1 GC,全称 Garbage-First Garbage Collector,通过 -XX:+UseG1GC 参数来启用,作为体验版随着 JDK 6u14 版本面世,在 JDK 7u4 版本发行时被正式推出。
在 JDK 9 中,G1 被提议设置为默认垃圾收集器(JEP 248)。
G1 是一种 服务器端的垃圾收集器,应用在多处理器和大容量内存环境中,在实现高吞吐量的同时,尽可能的满足垃圾收集暂停时间的要求。
它是专门针对以下应用场景设计的:
- 像 CMS 收集器一样,能与应用程序线程并发执行。
- 整理空闲空间更快。
- 需要 GC 停顿时间更好预测。
- 不希望牺牲大量的吞吐性能。
- 不需要更大的 Java Heap。
G1 收集器的设计目标是取代CMS收集器,它同 CMS 相比,在以下方面表现的更出色:
- G1 是一个有整理内存过程的垃圾收集器,不会产生很多内存碎片。
- G1 的 Stop The World(STW) 更可控,G1 在停顿时间上添加了预测机制,用户可以指定期望停顿时间。
G1 是目前技术发展的最前沿成果之一,HotSpot 开发团队赋予它的使命是未来可以替换掉 JDK1.5 中发布的 CMS 收集器。与其他 GC 收集器相比,G1 收集器有以下特点:
(1) 并行和并发。使用多个 CPU 来缩短 Stop The World 停顿时间,与用户线程并发执行。
(2) 分代收集。独立管理整个堆,但是能够采用不同的方式去处理新创建对象和已经存活了一段时间、熬过多次GC的旧对象,以获取更好的收集效果。
(3) 空间整合。基于标记 - 整理算法,无内存碎片产生。
(4) 可预测的停顿。能简历可预测的停顿时间模型,能让使用者明确指定在一个长度为M毫秒的时间片段内,消耗在垃圾收集上的时间不得超过N毫秒。
内存分布(不连续的Region块)
在 G1 之前的垃圾收集器,收集的范围都是整个新生代或者老年代,而 G1 不再是这样。使用 G1 收集器时,Java 堆的内存布局与其他收集器有很大差别,它将整个 Java 堆划分为多个大小相等的独立区域(Region),虽然还保留有新生代和老年代的概念,但新生代和老年代不再是物理隔离的了,它们都是一部分(可以不连续)Region的集合。
传统的 GC 收集器将连续的内存空间划分为新生代、老年代、永久代(JDK 8之后永久代改为元空间Metaspace),这种划分的特点是各代的存储地址是连续的。
而G1的各代存储地址是不连续的,每一代都使用了n个不连续的大小相同的Region,每个Region占有一块连续的虚拟内存地址。如下图所示:
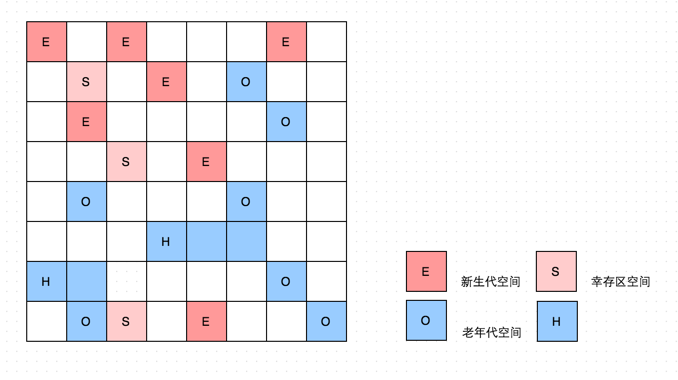
G1垃圾收集器内存布局
一个Region的大小可以通过参数 -XX:G1HeapRegionSize 设定,取值范围从1M到32M,且是2的指数。如果不设定,那么G1会根据Heap大小自动决定。
H,它代表Humongous,这表示这些Region存储的是巨大对象(humongous object,H-obj)
GC过程
G1 GC是启发式算法,会动态调整年轻代的空间大小。目标也就是为了达到接近预期的暂停时间。
G1提供了两种GC模式,Young GC和Mixed GC,两种都是完全 Stop The World的。
- Young GC:选定所有年轻代里的Region。通过控制年轻代的region个数,即年轻代内存大小,来控制young GC的时间开销。
- Mixed GC:选定所有年轻代里的Region,外加根据 global concurrent marking 统计得出收集收益高的若干老年代Region。在用户指定的开销目标范围内尽可能选择收益高的老年代Region。
由上面的描述可知,Mixed GC不是full GC,它只能回收部分老年代的Region,如果mixed GC实在无法跟上程序分配内存的速度,导致老年代填满无法继续进行Mixed GC,就会使用 serial old GC(full GC)来收集整个GC heap。
所以我们可以知道,G1是不提供full GC的。
新生代比例:一般不需要设置新生代大小。让G1自己根据最大停顿时间动态调整。新生代比例有两个数值指定,下限:
-XX:G1NewSizePercent,默认值5%,上限:-XX:G1MaxNewSizePercent,默认值60%。G1会根据实际的GC情况(主要是暂停时间)来动态的调整新生代的大小,主要是Eden Region的个数。最好是Eden的空间大一点,毕竟Young GC的频率更大,大的Eden空间能够降低Young GC的发生次数。但是Mixed GC是伴随着Young GC一起的,如果暂停时间短,那么需要更加频繁的Young GC,同时也需要平衡好Mixed GC中新生代和老年代的Region,因为新生代的所有Region都会被回收,如果Eden很大,那么留给老年代回收空间就不多了,最后可能会导致Full GC。
global concurrent marking,它的执行过程类似CMS,但是不同的是,在G1 GC中,它主要是为Mixed GC提供标记服务的,并不是一次GC过程的一个必须环节。
global concurrent marking 的执行过程分为四个步骤:
- 初始标记(initial mark,STW)。它标记了从GC Root开始直接可达的对象。
- 并发标记(Concurrent Marking)。这个阶段从GC Root开始对heap中的对象标记,标记线程与应用程序线程并行执行,并且收集各个Region的存活对象信息。
- 最终标记(Remark,STW)。标记那些在并发标记阶段发生变化的对象,将被回收。
- 清除垃圾(Cleanup)。清除空Region(没有存活对象的),加入到free list。
G1和CMS对比
1、cms 会产生 内存碎片,不及时清理会导致 promotion failure 和 concurrent mode failure
g1 有内存整理过程,不会产生内存碎片。
2、CMS 只负责老年代回收,需要配合一个 年轻代 收集器一起工作。
G1 将内存分为 region 块,eden, survivor, old 都是一些 region 集合,可以一起清理 年轻代 和 老年代。
3、处理 跨代引用时
cms 使用 card table 卡表
g1 使用每个 region 都维护的一个 rememberd set(RSet) 。每个region都会维护一个RSet,记录着引用到本region中的对象的其他region的Card。
4、可预测的停顿
这是G1相对于CMS的另一个大优势,降低停顿时间是G1和CMS共同的关注点,但G1除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为M毫秒的时间片段内,
G1收集器与CMS收集器的对比与实战(CMS和G1的过程非常详细,都有配图)
https://blog.chriscs.com/2017/06/20/g1-vs-cms/
Java Hotspot G1 GC的一些关键技术 - 美团技术博客
https://tech.meituan.com/2016/09/23/g1.html
Java垃圾回收(GC)机制详解 - 平凡希
http://www.cnblogs.com/xiaoxi/p/6486852.html
JVM类加载子系统
Java的类加载机制
http://www.cnblogs.com/xiaoxi/p/6959615.html
虚拟机把描述类的数据从.class字节码文件加载到内存,并对数据进行校验,转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型,这就是虚拟机的类加载机制。
class文件结构
魔数(Magic Number)
每个Class文件的头4个字节称为魔数(Magic Number), 魔数值为 0xCAFEBABE,其作用是确定这个文件是否为一个能被虚拟机接受的 Class 文件
使用魔数而不是扩展名来进行识别主要是基于安全方式的考虑,因为文件扩展名可以随意的改动。
版本号
紧接着魔数的4个字节存储的是Class文件的版本号:第5和第6个字节是次版本号(Minor Version),第7和第8个字节是主版本号(Major Version)。
版本号表示编译这个 class 文件的 java 编译器的 JDK 版本号。
Java的版本号是从45开始的,JDK 1.1之后的每个JDK大版本发布主版本号向上加1
高版本的JDK能向下兼容以前版本的Class文件,但不能运行以后版本的Class文件,即使文件格式并未发生任何变化,虚拟机也必须拒绝执行超过其版本号的Class文件。
LocalVariableTable属性
LocalVariableTable 属性表用于描述栈帧中局部变量表中的变量与Java源码中定义的变量之间的关系,它不是运行时必须的属性,默认也不会生成到Class文件之中,可以使用 -g:none 或 -g:vars 选项来取消或要求生成这项信息。
如果没有生成这项属性,最大的影响就是当其它人引用这个方法时,所有参数名称都丢失,IDE 可能会使用诸如 arg0、arg1 之类的占位符来替换原有的参数名称,这对程序运行没有影响,但是会给代码编写带来较大的不便,而且在调试期间无法根据参数名称从运行上下文件中获取参数值。
为什么有的class反编译后变量全变成arg0…了?
因为这个 class 编译的时候没加 -g:vars 参数,导致本地变量表 LocalVariableTable 属性没有编译到 class 文件中。不影响 class 执行,但反编译或debug时会丢失 local 变量名信息。
类加载过程
类装载器就是寻找类的字节码文件,并构造出类在JVM内部表示的对象组件。在Java中,类装载器把一个类装入JVM中,到卸载出内存为止,它的整个生命周期包括:
- (1) 装载(Loading:查找和导入Class文件;
- (2) 链接(Linking):把类的二进制数据合并到JRE中;
- (a)校验(Verification):检查载入Class文件数据的正确性;
- (b)准备(Preparation):给类的静态变量分配存储空间;
- (c)解析(Resolution):将符号引用转成直接引用;
- (3) 初始化(Initialization):对类的静态变量,静态代码块执行初始化操作
- (4) 使用(Using)
- (5) 卸载(Unloading)
Java程序可以动态扩展是由运行期动态加载和动态链接实现的;比如:如果编写一个使用接口的应用程序,可以等到运行时再指定其实际的实现(多态),解析过程有时候还可以在初始化之后执行;比如:动态绑定(多态);
类加载器
深入探讨 Java 类加载器
https://www.ibm.com/developerworks/cn/java/j-lo-classloader/
类加载器负责读取 Java 字节代码(.class文件),并转换成 java.lang.Class 类的一个实例。每个这样的实例用来表示一个 Java 类。
java.lang.ClassLoader 类的基本职责就是根据一个指定的类的名称,找到或者生成其对应的字节代码,然后从这些字节代码中定义出一个 Java 类,即 java.lang.Class 类的一个实例。
Java 中的类加载器大致可以分成两类,一类是系统提供的,另外一类则是由 Java 应用开发人员编写的。系统提供的类加载器主要有下面三个:
启动类加载器(Bootstrap ClassLoader)
c++ 编写,是用本地代码实现的类装入器
它用来加载 Java 的核心库,是用原生代码来实现的,并不继承自 java.lang.ClassLoader
将存放于 JAVA_HOME\lib 目录中的,或者被 -Xbootclasspath 参数所指定的路径中的,并且是虚拟机识别的(仅按照文件名识别,如 rt.jar 。名字不符合的类库即使放在 lib 目录中也不会被加载)类库加载到虚拟机内存中。启动类加载器无法被 Java 程序直接引用扩展类加载器(Extension ClassLoader)
ExtClassLoader 用来加载 Java 的扩展库。Java 虚拟机的实现会提供一个扩展库目录。该类加载器在此目录里面查找并加载 Java 类。
将 JAVA_HOME\lib\ext 目录下的,或者被java.ext.dirs系统变量所指定的路径中的所有类库加载。开发者可以直接使用扩展类加载器。应用类加载器(Application ClassLoader)
AppClassLoader 根据 Java 应用的类路径(CLASSPATH)来加载 Java 类。一般来说,Java 应用的类都是由它来完成加载的。可以通过 ClassLoader.getSystemClassLoader() 来获取它。
负责加载用户类路径(ClassPath)上所指定的类库,开发者可直接使用。
它负责在 JVM 被启动时,加载来自在命令 java 中的 -classpath 或者 java.class.path 系统属性或者 CLASSPATH 操作系统属性所指定的 JAR 类包和类路径。
除了系统提供的类加载器以外,开发人员可以通过继承 java.lang.ClassLoader 类的方式实现自己的类加载器,以满足一些特殊的需求。
每个 Java 类都维护着一个指向定义它的类加载器的引用,通过 Class 类的 getClassLoader() 方法就可以获取到此引用。
AppClassLoader 系统类加载器中包含一个 parent 指针指向扩展类加载器 ExtClassLoader,ExtClassLoader 中的 parent 指针指向为空,因为其上一层为启动类加载器,启动类加载器是用C++写的,因此在java 中没有启动类加载器。
在我们一般代码中默认的类加载器就是系统类加载器 AppClassLoader,但是无论是 AppClassLoader 还是 ExtClassLoader,他们都继承自基类 ClassLoader,在 ClassLoader 中存在一个成员变量 parent,该变量指向了自己名义上的双亲。
AppClassLoader 和 ExtClassLoader 两个类都是 sun.misc.Launcher 类下的静态内部类,因此在调试时我们看到的系统类加载器名称为 Launcher$AppClassLoader
URLClassLoader
URLClassLoader 是 AppClassLoader 和 ExtClassLoader 两个类的父类
系统类加载器和扩展类加载器都继承自 URLClassLoader 类加载器,不同的是初始化的 url 不同,这也导致了扩展类加载器只会加载到固定位置的类,而系统类加载器会加载到当前程序中所有可以加载到的类。
URLClassLoader 初始化时将 urls 列表存入 ucp 字段,
public class URLClassLoader extends SecureClassLoader implements Closeable {
/* The search path for classes and resources */
private final URLClassPath ucp;
public URLClassLoader(URL[] urls, ClassLoader parent) {
super(parent);
// this is to make the stack depth consistent with 1.1
SecurityManager security = System.getSecurityManager();
if (security != null) {
security.checkCreateClassLoader();
}
this.acc = AccessController.getContext();
ucp = new URLClassPath(urls, acc);
}
}
urls 就是类加载器的 jar 包列表,比如:
14 = {URL@22203} "file:/Library/Java/JavaVirtualMachines/zulu-8.jdk/Contents/Home/jre/lib/jfr.jar"
15 = {URL@22204} "file:/Library/Java/JavaVirtualMachines/zulu-8.jdk/Contents/Home/jre/lib/jsse.jar"
16 = {URL@22205} "file:/Library/Java/JavaVirtualMachines/zulu-8.jdk/Contents/Home/jre/lib/management-agent.jar"
17 = {URL@22206} "file:/Library/Java/JavaVirtualMachines/zulu-8.jdk/Contents/Home/jre/lib/resources.jar"
18 = {URL@22207} "file:/Library/Java/JavaVirtualMachines/zulu-8.jdk/Contents/Home/jre/lib/rt.jar"
双亲委派模型
双亲委派模型的工作流程是:
如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把请求委托给父加载器去完成,依次向上,因此,所有的类加载请求最终都应该被传递到顶层的启动类加载器中,只有当父加载器在它的搜索范围中没有找到所需的类时,即无法完成该加载,子加载器才会尝试自己去加载该类。
采用双亲委派的一个好处是比如加载位于rt.jar包中的类java.lang.Object,不管是哪个加载器加载这个类,最终都是委托给顶层的启动类加载器进行加载,这样就保证了使用不同的类加载器最终得到的都是同样一个Object对象。
双亲委派机制:
1、当AppClassLoader加载一个class时,它首先不会自己去尝试加载这个类,而是把类加载请求委派给父类加载器ExtClassLoader去完成。
2、当ExtClassLoader加载一个class时,它首先也不会自己去尝试加载这个类,而是把类加载请求委派给BootStrapClassLoader去完成。
3、如果BootStrapClassLoader加载失败(例如在$JAVA_HOME/jre/lib里未查找到该class),会使用ExtClassLoader来尝试加载;
4、若ExtClassLoader也加载失败,则会使用AppClassLoader来加载,如果AppClassLoader也加载失败,则会报出异常ClassNotFoundException。
loadClass()
loadClass 方法源码如下:
protected Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException {
synchronized (getClassLoadingLock(name)) {
// First, check if the class has already been loaded
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
long t1 = System.nanoTime();
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
1、首先 findLoadedClass 查找 class 是否被加载过
2、如果 class 文件没有被加载过(c == null),通过 parent 指针找到自己的父加载器,如果父加载器不为空(表示不是Bootstrap ClassLoader),递归调用 parent 的 loadClass 方法来让父类先加载,从而实现双亲委派机制。如果父加载器为空(说明是Bootstrap ClassLoader),findBootstrapClassOrNull 内部通过 native 方法调用 Bootstrap ClassLoader 加载类。
3、父加载器加载成功就返回一个 java.lang.Class ,加载不成功就抛出一个 ClassNotFoundException,则通过本加载器的 findClass 函数自己来加载该类
4、如果要解析这个 .class 文件的话,就解析一下,解析主要就是将符号引用替换为直接引用的过程。
findClass 就是留给开发者自己去定义类加载器的载方法
protected Class<?> findClass(String name) throws ClassNotFoundException {
throw new ClassNotFoundException(name);
}
如何判断一个类是否用户自定义类
Class 类的 getClassLoader() 可以返回该类的类加载器,但 bootstrap 类加载器返回的是 null ,所以如果某个类的类加载器是 null,说明其是被 bootstrap 类加载器加载的,说明是 java 自己的类型。
// 判断一个类是JAVA类型还是用户定义类型,true:java类型,false:自定义类
public static boolean isJavaClass(Class<?> clz) {
return clz != null && clz.getClassLoader() == null;
}
public static void main(String[] args) {
System.out.println(isJavaClass(Integer.class)); // true
System.out.println(isJavaClass(BugMeNot.class)); // false
}
Class.forName做了什么
Class.forName(xxx.xx.xx) 的作用就是要求JVM查找并加载指定的类,如果在类中有静态初始化器的话,JVM必然会执行该类的静态代码段。
java里面任何class都要装载在虚拟机上才能运行,而静态代码是和class绑定的,class装载成功就表示执行了你的静态代码了,而且以后不会再走这段静态代码了。
Class.forName()做了什么?
假设一个类以前从来没有被装进内存过,Class.forName(String className)这个方法会做以下几件事情:
1、装载。将字节码读入内存,并产生一个与之对应的java.lang.Class类对象
2、连接。这一步会验证字节码,为static变量分配内存,并赋默认值(0或null),并可选的解析符号引用(这里不理解没关系)
3、初始化。为类的static变量赋初始值,假如有static int a = 1;这个将a赋值为1的操作就是这个时候做的。除此之外,还要调用类的static块。(这一步是要点)
Class.forName()和ClassLoader.loadClass()区别
Class.forName() 将类的.class文件加载到jvm中之外,还会对类进行解释,执行类中的static块;
ClassLoader.loadClass() 只干一件事情,就是将.class文件加载到jvm中,不会执行static中的内容,只有在newInstance才会去执行static块。
注:Class.forName(name, initialize, loader)带参函数也可控制是否加载static块。并且只有调用了newInstance()方法采用调用构造函数,创建类的对象 。
Java的类加载机制 - 平凡希
http://www.cnblogs.com/xiaoxi/p/6959615.html
ClassNotFoundException 和 NoClassDefFoundError
正如它们的名字所说明的:NoClassDefFoundError 是一个错误 Error ,而 ClassNOtFoundException 是一个异常 Exception,在 Java 中错误和异常是有区别的,我们可以从异常中恢复程序但却不应该尝试从错误中恢复程序。
在根据类名加载类的 class 文件时如果在 classpath 下找不到会抛出 ClassNOtFoundException
某个类在编译时没问题,但在运行时初始化失败会抛出 NoClassDefFoundError
什么情况下会抛出 ClassNotFoundException 异常?
Class.forName() 或 ClassLoader.loadClass() 或 ClassLoader.findSystemClass() 根据类名加载类时,如果类加载器 ClassLoader 在 classpath 中找不到这个类名对应的 .class 文件,也就是从引导类路径lib,扩展类路径lib/ext,到当前的classpath下全部没有找到,就会抛出 ClassNotFoundException 异常
例1、最常见的例子就是 Class.forName("oracle.jdbc.driver.OracleDriver"); 加载 JDBC 驱动包的时候,它的依赖 jar 并不在classpath里面。
例2、例如下面的代码会抛出 ClassNOtFoundException 异常
@Test
public void testClassNotFoundException() throws Exception {
Class.forName("a.b.c");
}
java.lang.ClassNotFoundException: a.b.c
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:264)
at com.masikkk.common.jvm.ClassNotFoundExceptionTest.testCNF(ClassNotFoundExceptionTest.java:11)
什么情况下会抛出 NoClassDefFoundError 错误?
情况1、当 JVM 在加载一个类的时候,如果 这个类在编译时是存在的,但是在运行时找不到这个类的定义的时候,JVM 就会抛出一个 NoClassDefFoundError 错误
比如当我们在 new 一个类的实例的时候,如果在运行时类找不到,则会抛出一个 NoClassDefFoundError 的错误。
情况2、类初始化失败但还继续使用,常见于类的静态代码块中抛出了异常,此时编译没问题,但运行时类会初始化失败
编译后删除 class 文件直接运行
例1、NoClassDefFoundError 示例1
如下代码,保存为 ClassA.java,执行命令 javac ClassA.java 后编译生成 ClassA.class 和 ClassA$ClassB.class ,注意没有 package 信息。
public class ClassA {
public static class ClassB {
}
public static void main(String[] args) {
ClassB classB = new ClassB();
System.out.println("new ClassB 完成");
}
}
正常情况下,执行 java ClassA 会输出 “new ClassB 完成”
如果此时删除 ClassA$ClassB.class,再执行就会抛 NoClassDefFoundError 错误
java ClassA
Exception in thread "main" java.lang.NoClassDefFoundError: ClassA$ClassB
at ClassA.main(ClassA.java:6)
Caused by: java.lang.ClassNotFoundException: ClassA$ClassB
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
静态代码中抛异常导致类初始化失败
例2、如下代码会抛出 NoClassDefFoundError 错误,因为 ClassWithInitErrors 初始化会抛异常但我们捕获后让代码继续执行,后面继续调用 ClassWithInitErrors 的 print() 方法时就会抛出 NoClassDefFoundError
private static class ClassWithInitErrors {
// 静态变量data初始化会失败。注意这个变量是静态的,所以编译是通过的。
static int divideZero = 1 / 0;
public static void print(){
System.out.println("123");
}
}
@Test
public void testNoClassDefFoundError() {
try {
double divideZero = ClassWithInitErrors.divideZero;
} catch (Throwable e) {
// 抛出的异常是 ExceptionInInitializerError,此处,必须用Throwable,用Exception会直接退出.
// System.out.println(e);
}
// 继续使用.
ClassWithInitErrors.print();
}
java.lang.NoClassDefFoundError: Could not initialize class com.masikkk.common.jvm.ClassNotFoundExceptionTest$ClassWithInitErrors
at com.masikkk.common.jvm.ClassNotFoundExceptionTest.testNoClassDefFoundError(ClassNotFoundExceptionTest.java:32)
例3,比如下面的 static 代码块,假如其中的配置项 MAX_CONNECT 不存在,也就是 null,但 setMaxConnTotal(int) 必须接收一个 int,就会导致初始化失败,编译时没问题,但运行时使用 HttpClient 中的方法时会抛出 NoClassDefFoundError
public class HttpClient {
private static HttpClient httpClient;
static {
httpClient = HttpClients.custom()
.setMaxConnTotal(MAX_CONNECT)
.setMaxConnPerRoute(MAX_PER_ROUTE)
.build();
}
}
ClassNotFoundException 的常用排查方法
1、首先确定出现异常的类或者 jar 是否在 classpath 里面,如果没有,要添加进去。最常见的情况就是 pom 里面缺少依赖的jar包
2、依赖包发生了冲突,比如应该依赖高版本 jar 包,但又其它包传递依赖了低版本 jar 包,导致高版本中某些类找不到
3、如果发现类在 classpath 里面,很有可能是 classpath 被重写了,需要再次确定应用准确的 classpath
4、如上面的例子,检查日志中是否含有 ExceptionInInitializerError 异常,静态成员初始化失败是也会导致
5、如果应用中有多个类加载器也可能会出现这种情况,因为一个类加载器加载的类有可能无法在另一个类加载器中使用
ClassNotFoundException和NoClassDefFoundError的区别
https://segmentfault.com/a/1190000021292121
理解ClassNotFoundException与NoClassDefFoundError的区别
https://cloud.tencent.com/developer/article/1356060
一次 ClassNotFoundException 启动异常排查
问题:
SpringBoot 启动失败,报错:
15:10:30.166 [main] ERROR o.s.boot.SpringApplication
- Application run failed
org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'com.masikkk.MyService': Lookup method resolution failed; nested exception is java.lang.IllegalStateException: Failed to introspect Class [com.masikkk.MyService] from ClassLoader [sun.misc.Launcher$AppClassLoader@18b4aac2]
at org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor.determineCandidateConstructors(AutowiredAnnotationBeanPostProcessor.java:289)
at com.app.all.data.defense.MyApp.main(MyApp.java:43)
Caused by: java.lang.IllegalStateException: Failed to introspect Class [com.masikkk.MyService] from ClassLoader [sun.misc.Launcher$AppClassLoader@18b4aac2]
at org.springframework.util.ReflectionUtils.getDeclaredMethods(ReflectionUtils.java:481)
... 18 common frames omitted
Caused by: java.lang.NoClassDefFoundError: com/masikkk/MyService
at java.lang.Class.getDeclaredMethods0(Native Method)
at java.lang.Class.privateGetDeclaredMethods(Class.java:2701)
at java.lang.Class.getDeclaredMethods(Class.java:1975)
at org.springframework.util.ReflectionUtils.getDeclaredMethods(ReflectionUtils.java:463)
... 20 common frames omitted
Caused by: java.lang.ClassNotFoundException: com.masikkk.MyService
at java.net.URLClassLoader.findClass(URLClassLoader.java:387)
at java.lang.ClassLoader.loadClass(ClassLoader.java:419)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:352)
at java.lang.ClassLoader.loadClass(ClassLoader.java:352)
... 24 common frames omitted
排查:
看到有 ClassNotFoundException 和 NoClassDefFoundError,一般来说就是类依赖冲突,因为同时引入了 1.0.0 版本的 sdk 和 1.0.1 版本的 sdk,应该是其中某些类在两个包中不一致导致。
在抛异常的类 ReflectionUtils.getDeclaredMethods(ReflectionUtils.java:481) 的 catch 中打断点,等抛异常断住后 alt+f8 执行 com.masikkk.MyService 类 clazz.getClassLoader() 看类加载器,展开类加载器的属性能看到 AppClassLoader 的 URLClassPath ucp 属性是加载的 jar 包列表,inspect 查看 url 列表字段,拷贝出来搜索 sdk 看到版本是 1.0.1,看到最终加载的 sdk jar 包是 1.0.1 版本,所以里面是肯定没有 1.0.0 里的类的。
解决:
修改 maven 依赖版本,解决冲突
依赖冲突排查方法
发生依赖冲突主要表现为系统启动或运行中会发生异常,99%表现为三种 NoClassDefFoundError、ClassNotFoundException、NoSuchMethodError
在JVM启动参数中增加 -XX:+TraceClassLoading,然后重新启动系统,在系统工程日志中即可看到JVM加载类的信息。从中即可找到JVM是从哪个jar包中加载的。
URLClassLoader是ClassLoader子类,其内部存一个类型为URLClassPath属性为ucp,ucp负责管理被当前类加载器加载Class文件资源路径。
同时加载同包同名类的多个版本
https://www.cnblogs.com/grey-wolf/p/13253014.html
TypeNotPresentExceptionProxy
SpringBoot 启动报错:
2023-07-19 16:09:41.568 [main] ERROR org.springframework.boot.SpringApplication.reportFailure:870 - Application run failed
org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name Unexpected exception during bean creation; nested exception is java.lang.ArrayStoreException: sun.reflect.annotation.TypeNotPresentExceptionProxy
...
Caused by: java.lang.ArrayStoreException: sun.reflect.annotation.TypeNotPresentExceptionProxy
at sun.reflect.annotation.AnnotationParser.parseClassArray(AnnotationParser.java:724)
排查:
可能是 java.lang.ClassNotFoundException 引起的,在 sun.reflect.annotation.TypeNotPresentExceptionProxy 类的构造方法中打断点,能看到具体抛 ClassNotFoundException 异常的类。
对象的创建过程
类加载检查
1、虚拟机遇到一条 new 指令,首先去检查这个指令的参数能否在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已经被加载、解析和初始化。如果没有,那么必须先执行类的初始化过程。
在堆上为对象分配内存
2、类加载检查通过后,虚拟机为新生对象分配内存。对象所需内存大小在类加载完成后便可以完全确定,为对象分配空间无非就是从Java堆中划分出一块确定大小的内存而已。这个地方会有两个问题:
指针碰撞法
(1)如果内存是规整的,那么虚拟机将采用的是 指针碰撞法 来为对象分配内存。意思是所有用过的内存在一边,空闲的内存在另外一边,中间放着一个指针作为分界点的指示器,分配内存就仅仅是把指针向空闲那边挪动一段与对象大小相等的距离罢了。如果垃圾收集器选择的是Serial、ParNew这种基于压缩算法的,虚拟机采用这种分配方式。
空闲列表法
(2)如果内存不是规整的,已使用的内存和未使用的内存相互交错,那么虚拟机将采用的是 空闲列表法 来为对象分配内存。意思是虚拟机维护了一个列表,记录上哪些内存块是可用的,在分配的时候从列表中找到一块足够大的空间划分给对象实例,并更新列表上的内容。如果垃圾收集器选择的是CMS这种基于标记-清除算法的,虚拟机采用这种分配方式。
new对象时的线程安全(CAS/TLAB)
另外一个问题是保证new对象时候的线程安全性。因为可能出现虚拟机正在给对象A分配内存,指针还没有来得及修改,对象B又同时使用了原来的指针来分配内存的情况。虚拟机采用了CAS加失败重试的方式保证更新更新操作的原子性和TLAB两种方式来解决这个问题。
对象内存初始化
3、内存分配结束,虚拟机将分配到的内存空间都初始化为零值(不包括对象头)。这一步保证了对象的实例字段在Java代码中可以不用赋初始值就可以直接使用,程序能访问到这些字段的数据类型所对应的零值。
对象头设置
4、对对象进行必要的设置,例如这个对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希码、对象的GC分代年龄等信息,这些信息存放在对象的对象头中。
对象初始化
5、执行init方法,把对象按照程序员的意愿进行初始化,这样一个真正可用的对象才算完全产生出来。
JVM的内存区域划分 - 平凡希
http://www.cnblogs.com/xiaoxi/p/6421526.html
自定义类加载器
为什么需要自定义类加载器?
为什么我们要自定义类加载器?
因为虽然Java中给用户提供了很多类加载器,但是和实际使用比起来,功能还是匮乏。
举一个例子来说吧,主流的Java Web服务器,比如Tomcat,都实现了自定义的类加载器(一般都不止一个)。因为一个功能健全的Web服务器,要解决如下几个问题:
1、部署在同一个服务器上的两个Web应用程序所使用的Java类库可以实现相互隔离。这是最基本的要求,两个不同的应用程序可能会依赖同一个第三方类库的不同版本,不能要求一个类库在一个服务器中只有一份,服务器应当保证两个应用程序的类库可以互相使用
2、部署在同一个服务器上的两个Web应用程序所使用的Java类库可以相互共享。这个需求也很常见,比如相同的Spring类库10个应用程序在用不可能分别存放在各个应用程序的隔离目录中
3、支持热替换,我们知道JSP文件最终要编译成.class文件才能由虚拟机执行,但JSP文件由于其纯文本存储特性,运行时修改的概率远远大于第三方类库或自身.class文件,而且JSP这种网页应用也把修改后无须重启作为一个很大的优势看待
由于存在上述问题,因此Java提供给用户使用的ClassLoader就无法满足需求了。Tomcat服务器就有自己的ClassLoader架构
1)加密:Java代码可以轻易的被反编译,如果你需要把自己的代码进行加密以防止反编译,可以先将编译后的 class 用某种加密算法加密,类加密后就不能再用Java的ClassLoader去加载类了,这时就需要自定义ClassLoader在加载类的时候先解密类,然后再加载。
2)从非标准的来源加载代码:如果你的字节码是放在数据库、甚至是在云端,就可以自定义类加载器,从指定的来源加载类。
3)以上两种情况在实际中的综合运用:比如你的应用需要通过网络来传输 Java 类的字节码,为了安全性,这些字节码经过了加密处理。这个时候你就需要自定义类加载器来从某个网络地址上读取加密后的字节代码,接着进行解密和验证,最后定义出在Java虚拟机中运行的类。
自定义类加载器
从上面对于java.lang.ClassLoader的loadClass(String name, boolean resolve)方法的解析来看,可以得出以下2个结论:
1、如果不想打破双亲委派模型,那么只需要重写findClass方法即可
2、如果想打破双亲委派模型,那么就重写整个loadClass方法
类卸载
什么情况下class会被卸载?
class 被卸载指的就是从方法区中删除 class 类元信息,也就是方法区中哪些类会被gc,当然是 无用的类 会被gc,那哪些类是无用的类,如何判断呢?
方法区中的类需要同时满足以下三个条件才能被标记为无用的类:
1、该类所有的实例都已经被回收,也就是Java堆中不存在该类的任何实例。
2、加载该类的类加载器 ClassLoader 已经被回收。
3、该类对应的 java.lang.Class 对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
能手动指定卸载某个class吗?
方法区 GC 的时机我们是不可控的,同样的我们对于 Class 的卸载也是不可控的。
我们可控的是,通过参数 -Xnoclassgc 关闭整个方法区的 class 信息回收,但这样可能造成方法区占用内存过多或方法区 OOM,要谨慎。
什么情况下要关注及时卸载类/方法区gc?(反射,代理等动态生成类时)
在大量使用反射、动态代理、CGLib等bytecode框架的场景,以及动态生成JSP和OSGi这类频繁自定义ClassLoader的场景都需要虚拟机具备类卸载的功能,以保证永久代不会溢出。
JVMTI 虚拟机工具接口
JVMTI 全称 JVM Tool Interface,是 JVM 暴露出来的一些供用户扩展的接口集合。JVMTI 是基于事件驱动的,JVM 每执行到一定的逻辑就会调用一些事件的回调接口(如果有的话),这些接口可以供开发者扩展自己的逻辑。但JVMTI都是一些接口合集,需要有接口的实现,这就用到了 java 的 instrument,可以理解 instrument 是 JVMTI 的一种实现,为 JVM 提供外挂支持。
比如最常见的,我们想在某个类的字节码文件读取之后、类定义之前修改相关的字节码,从而使创建的 class 对象是我们修改之后的字节码内容,那就可以实现一个回调函数赋给 jvmtiEnv(JVMTI 的运行时,通常一个 JVMTIAgent 对应一个 jvmtiEnv,但是也可以对应多个)的回调方法集合里的 ClassFileLoadHook,这样在接下来的类文件加载过程中都会调用到这个函数中。
JVMTIAgent
JVMTIAgent 其实就是一个动态库,利用 JVMTI 暴露出来的一些接口来干一些我们想做、但是正常情况下又做不到的事情,不过为了和普通的动态库进行区分,它一般会实现如下的一个或者多个函数:Agent_OnLoad 函数,如果 agent 是在启动时加载的,也就是在 vm 参数里通过 -agentlib 来指定的,那在启动过程中就会去执行这个 agent 里的 Agent_OnLoad 函数。Agent_OnAttach 函数,如果 agent 不是在启动时加载的,而是我们先 attach 到目标进程上,然后给对应的目标进程发送 load 命令来加载,则在加载过程中会调用 Agent_OnAttach 函数。Agent_OnUnload 函数,在 agent 卸载时调用,不过貌似基本上很少实现它。
instrument
instrument 是一个 JVMTIAgent, javaagent 功能就是它来实现的。另外 instrument agent 还有个别名叫 JPLISAgent(Java Programming Language Instrumentation Services Agent),这个名字也完全体现了其最本质的功能:就是专门为 Java 语言编写的插桩服务提供支持的。
instrument 支持启动时加载和运行时加载两种方式,分别通过实现 Agent_OnLoad 和 Agent_OnAttach 方法实现,也就是说在使用时,agent 既可以在启动时加载,也可以在运行时动态加载。其中启动时加载还可以通过类似 -javaagent:myagent.jar 的方式来间接加载 instrument agent,运行时动态加载依赖的是 JVM 的 attach 机制,通过发送 load 命令来加载 agent。
启动时加载 instrument agent
启动时加载 instrument agent,具体过程都在 InvocationAdapter.c 的 Agent_OnLoad 方法里,简单描述过程:
1、创建并初始化 JPLISAgent
2、监听 VMInit 事件,在 vm 初始化完成之后做下面的事情:
- 创建 InstrumentationImpl 对象
- 监听 ClassFileLoadHook 事件
- 调用 InstrumentationImpl 的
loadClassAndCallPremain方法,在这个方法里会调用 javaagent 里 MANIFEST.MF 里指定的Premain-Class类的 premain 方法
3、解析 javaagent 里 MANIFEST.MF 里的参数,并根据这些参数来设置 JPLISAgent 里的一些内容
运行时加载 instrument agent
在运行时加载的方式,大致按照下面的方式来操作:
VirtualMachine vm = VirtualMachine.attach(pid);
vm.loadAgent(agentPath, agentArgs);
上面会通过 JVM 的 attach 机制来请求目标 JVM 加载对应的 agent,过程大致如下:
1、创建并初始化 JPLISAgent
2、解析 javaagent 里 MANIFEST.MF 里的参数
3、创建 InstrumentationImpl 对象
4、监听 ClassFileLoadHook 事件
5、调用 InstrumentationImpl 的 loadClassAndCallAgentmain 方法,在这个方法里会调用 javaagent 里 MANIFEST.MF 里指定的 Agent-Class 类的 agentmain 方法
ClassFileLoadHook 事件回调
不管是启动时还是运行时加载的 instrument agent,都关注着同一个 jvmti 事件 ClassFileLoadHook,这个事件是在读取字节码文件之后回调时用的,这样可以对原来的字节码做修改。
JVM 源码分析之 javaagent 原理完全解读
https://www.infoq.cn/article/javaagent-illustrated
javaagent agent
javaagent 就是 Java 代理,比如我们接入 Pinpoint 调用链监控时在启动参数中使用 -javaagent 指定 pinpoint 的 jar 包:java -javaagent:/Users/acheron/pinpoint/pp-agent/pinpoint-bootstrap-1.6.0.jar -Dpinpoint.agentId=myservice-001 -Dpinpoint.applicationName=myservice -jar myapp.jar
javaagent 的主要功能如下:
1、可以在加载 class 文件之前做拦截,对字节码做修改
2、可以在运行期对已加载类的字节码做变更,但是这种情况下会有很多的限制
3、还有其他一些小众的功能
获取所有已经加载过的类
获取所有已经初始化过的类(执行过 clinit 方法,是上面的一个子集)
获取某个对象的大小
将某个 jar 加入到 bootstrap classpath 里作为高优先级被 bootstrapClassloader 加载
将某个 jar 加入到 classpath 里供 AppClassloard 去加载
设置某些 native 方法的前缀,主要在查找 native 方法的时候做规则匹配
JVM Attach 机制
Attach机制是什么?
说简单点就是jvm提供一种jvm进程间通信的能力,能让一个进程传命令给另外一个进程,并让它执行内部的一些操作,比如说我们为了让另外一个jvm进程把线程dump出来,那么我们跑了一个jstack的进程,然后传了个pid的参数,告诉它要哪个进程进行线程dump,既然是两个进程,那肯定涉及到进程间通信,以及传输协议的定义,比如要执行什么操作,传了什么参数等
Attach能做些什么
总结起来说,比如内存dump,线程dump,类信息统计(比如加载的类及大小以及实例个数等),动态加载agent(使用过btrace的应该不陌生),动态设置vm flag(但是并不是所有的flag都可以设置的,因为有些flag是在jvm启动过程中使用的,是一次性的),打印vm flag,获取系统属性等
JVM Attach机制实现
http://lovestblog.cn/blog/2014/06/18/jvm-attach/
pinpoint的实现原理
见笔记 Pinpoint
Java 安全
Java 安全沙箱的构成
组成Java沙箱的基本组件如下:
1、类加载体系结构
2、class 文件校验器
3、内置于 Java 虚拟机(及语言)的安全特性
4、安全管理器及Java API
Jar 包签名和验证
首先要明白以下概念:非对称加密、信息摘要、数字签名、数字证书,以及他们之间的关系,如何工作的。
对Jar包的数字签名和验证过程和网络安全中的数字签名原理和过程一致。Jar包是待发送的消息,经过签名后,Jar包内置入了数字签名和public key,验证者可以使用这两项数据进行验证。
实际上,经签名的Jar包内包含了以下内容:
1、原Jar包内的class文件和资源文件
2、签名文件 META-INF/.SF:这是一个文本文件,包含原Jar包内的class文件和资源文件的Hash
3、签名block文件 META-INF/.DSA:这是一个数据文件,包含签名者的 certificate 和数字签名。其中 certificate 包含了签名者的有关信息和 public key;数字签名是对 *.SF 文件内的 Hash 值使用 private key 加密得来
用keytool生成keystore密钥对
JDK 提供了 keytool 和 jarsigner 两个工具用来进行 Jar 包签名和验证。
keytool 用来生成和管理 keystore。keystore 是一个数据文件,存储了 key pair 有关的2种数据:private key 和 certificate,而 certificate 包含了 public key。整个 keystore 用一个密码进行保护,keystore 里面的每一对 key pair 单独用一个密码进行保护。每对 key pair 用一个 alias 进行指定,alias 不区分大小写。
keytool 支持的算法是:
如果公钥算法为 DSA,则摘要算法使用 SHA-1。这是默认的
如果公钥算法为 RSA,则摘要算法采用 MD5
用jarsigner对jar包签名和验证
jarsigner 读取 keystore,为 Jar 包进行数字签名。jarsigner 也可以对签名的 Jar 包进行验证。
1、创建密钥库并生成密钥myKey
keytool -genkey -keystore myKeyStore.store -alias myKey
2、用密钥对jar包进行签名
jarsigner -keystore myKeyStore xxx.jar myKey
3、对签名后的jar包进行验证
jarsigner -keystore myKeyStore -verify xxx.jar -verbose -certs
Jar 包签名
https://www.cnblogs.com/jackofhearts/archive/2013/07/17/jar_signing.html
java之jvm学习笔记八(实践对jar包的代码签名)
https://blog.csdn.net/yfqnihao/article/details/8267669
class 文件校验器(4趟扫描)
class文件校验器,通过四趟扫描,保证了class文件正确
第一趟是,检查class文件的结构是否正确。比较典型的就是,检查class文件是否以魔数OxCAFEBABE打头。通过这趟检查,可以过滤掉大部分可能损坏的,或者压根就不是class的文件,来冒充装载。
第二趟是,检查它是否符合java语言特性里的编译规则。比如发现一个类的超类不是Object,就抛出异常。
第三趟是,字节码验证,检查字节码是否能被JVM安全的执行,而不会导致JVM崩溃。
第四趟是,符号引用验证。
总结:
第一趟扫描,在类被装载时进行,校验class文件的内部结构,保证能够被正常安全的编译
第二趟和第三趟在连接的过程中进行,这两趟基本上是语法校验,词法校验
第四趟是解析符号引用和直接引用时进行的,这次校验确认被引用的类,字段以及方法确实存在
java之jvm学习笔记三(Class文件检验器)
https://blog.csdn.net/yfqnihao/article/details/8258228
java安全沙箱机制介绍
https://blog.csdn.net/chdhust/article/details/42343473
SecurityManager 安全管理器
Java 从应用层给我们提供了安全管理机制————安全管理器,每个 Java 应用都可以拥有自己的安全管理器,它会在运行阶段检查需要保护的资源的访问权限及其它规定的操作权限,保护系统免受恶意操作攻击,以达到系统的安全策略。
SecurityManager 在 Java 中被用来检查应用程序是否能访问一些有限的资源,例如文件、套接字(socket)等等。它可以用在那些具有高安全性要求的应用程序中。通过打开这个功能,我们的系统资源可以只允许进行安全的操作。
安全管理器的工作过程
当运行 Java 程序时,安全管理器会根据 policy 文件所描述的策略给程序不同模块分配权限,假设把应用程序分成了三块,每块都有不同的权限,第一块有读取某文件的权限,第二块同时拥有读取某文件跟内存的权限,第三块有监听 socket 的权限。通过这个机制就能很好地控制程序各个部分的各种操作权限,从应用层上为我们提供了安全管理策略。
以安全管理器对文件操作进行管理的工作过程为例:
当应用程序要读取本地文件时,securitymanager 就会在读取前进行拦截,判断是否有读取此文件的权限,如果有则顺利读取,否则将抛出访问异常。
如何启动安全管理器?
一般而言,Java 程序启动时并不会自动启动安全管理器,可以通过以下两种方法启动安全管理器:
添加java启动参数-Djava.security.manager
启动默认的安全管理器最简单的方法就是:直接在启动命令中添加 -Djava.security.manager 参数即可。
若要同时指定配置文件的位置那么示例如下:
-Djava.security.manager -Djava.security.policy="E:/java.policy"
代码中可以 System.getProperty("java.security.manager") 查看该属性
指定安全策略文件java.policy
在启动安全管理器时可以通过 -Djava.security.policy 选项来指定安全策略文件。例如:-Djava.security.policy=”E:/java.policy”
需要说明一下的是,=表示这个策略文件将和默认的策略文件一同发挥作用;==表示只使用这个策略文件。
如果没有指定策略文件的路径,那么安全管理器将使用默认的安全策略文件,它位于 %JAVA_HOME%/jre/lib/security 目录下面的 java.policy。
policy 文件包含了多个 grant 语句,每一个 grant 描述某些代码拥有某些操作的权限。在启动安全管理器时会根据policy文件生成一个Policy对象,任何时候一个应用程序只能有一个Policy对象。
在启用安全管理器的时候,配置遵循以下基本原则:
没有配置的权限表示没有。
只能配置有什么权限,不能配置禁止做什么。
同一种权限可多次配置,取并集。
统一资源的多种权限可用逗号分割。
策略和保护域
java之jvm学习笔记十(策略和保护域)
https://blog.csdn.net/yfqnihao/article/details/8271415
编码方式启动System.setSecurityManager
也可以通过编码方式启动,不过不建议。
实例化一个 java.lang.SecurityManager 或继承它的子类的对象,然后通过 System.setSecurityManager() 来设置并启动一个安全管理器。
System.setSecurityManager(new SecurityManager());
其实通过配置java参数启动,本质上也是通过编码启动,不过参数启动更加灵活。
源码如下,在sun.misc.Launcher中,也是通过System.setSecurityManager()设置一个默认的SecurityManager
String s = System.getProperty("java.security.manager");
if (s != null) {
SecurityManager sm = null;
if ("".equals(s) || "default".equals(s)) {
sm = new java.lang.SecurityManager();
} else {
try {
sm = (SecurityManager)loader.loadClass(s).newInstance();
} catch (IllegalAccessException e) {
} catch (InstantiationException e) {
} catch (ClassNotFoundException e) {
} catch (ClassCastException e) {
}
}
if (sm != null) {
System.setSecurityManager(sm);
} else {
throw new InternalError(
"Could not create SecurityManager: " + s);
}
}
注意:System.setSecurityManager() 方式启动安全管理器只有你在位于 ${JAVA_HOME}/jre/lib/security 目录下或者其他指定目录下的 java.policy 文件中指定了一个权限才会奏效。 这个权限是:
permission java.lang.RuntimePermission "setSecurityManager";
上面的一行将被用来允许代码设置 SecurityManager
Java安全管理器——SecurityManager
https://blog.csdn.net/hjh200507609/article/details/50330773
java安全管理器SecurityManager入门
https://www.cnblogs.com/yiwangzhibujian/p/6207212.html
实现一个安全管理器
安全管理器SecurityManager的核心方法是checkPerssiom,这个方法里又调用AccessController的checkPerssiom方法,访问控制器AccessController的栈检查机制又遍历整个PerssiomCollection来判断具体拥有什么权限,一旦发现栈中一个权限不允许的时候就抛出异常,否则简单的返回。
自定义安全管理器,实现对指定文件名的读权限进行限制:
第一步,定义一个类继承自SecurityManger重写它的checkRead方法,
package com.yfq.test;
public class MySecurityManager extends SecurityManager {
@Override
public void checkRead(String file) {
//super.checkRead(file, context);
if (file.endsWith("test"))
throw new SecurityException("你没有读取的本文件的权限");
}
}
第二步,定义一个有main函数的public类来验证自己的安全管理器是不是器作用了。
package com.yfq.test;
import java.io.FileInputStream;
import java.io.IOException;
public class TestMySecurityManager {
public static void main(String[] args) {
System.setSecurityManager(new MySecurityManager());
try {
FileInputStream fis = new FileInputStream("test");
System.out.println(fis.read());
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行代码看到控制台输出:Exception in thread “main” java.lang.SecurityException: 你没有读取的本文件的权限
原因是FileInputStream的构造函数里会先获取安全管理器,并调用checkRead(name)方法检查是否有此文件的读权限。
public FileInputStream(File file) throws FileNotFoundException {
String name = (file != null ? file.getPath() : null);
SecurityManager security = System.getSecurityManager();
if (security != null) {
security.checkRead(name);
}
if (name == null) {
throw new NullPointerException();
}
fd = new FileDescriptor();
open(name);
}
java之jvm学习笔记六(实践写自己的安全管理器)
https://blog.csdn.net/yfqnihao/article/details/8263358
访问控制器
java之jvm学习笔记十一(访问控制器)
https://blog.csdn.net/yfqnihao/article/details/8271665
JIT 即时编译
HotSpot和IBM J9中既有解释执行又有编译执行。
JRocket内部没有解释器,完全靠编译执行,所以存在启动时间较长的特点。
解释运行与编译运行
HotSpot虚拟机中内置了两个即时编译器,分别称为Client Compiler和Server Compiler,或者简称为 C1编译器 和 C2编译器(也叫Opto编译器)。目前主流的HotSpot虚拟机(Sun系列JDK1.7及之前版本的虚拟机)中,默认采用解释器与其中一个编译器直接配合的方式工作,程序使用哪个编译器,取决于虚拟机运行的模式,HotSpot虚拟机会根据自身版本与宿主机器的硬件性能自动选择运行模式,用户也可以使用”-client”或”-server”参数去强制指定虚拟机运行在Client模式或Server模式。
无论采用的编译器是Client Compiler还是Server Compiler,解释器与编译器搭配使用的方式在虚拟机中称为“混合模式”(Mixed Mode),用户可以使用参数”-Xint”强制虚拟机运行于“解释模式”(Interpreted Mode),这时编译器完全不介入工作,全部代码都使用解释方式执行。另外,也可以使用参数”-Xcomp”强制虚拟机运行于“编译模式”(Compiled Mode),这时将优先采用编译方式执行程序,但是解释器仍然要在编译无法进行的情况下介入执行过程。
热点代码探测
什么是热点代码?
在运行过程中会被即时编译器编译的“热点代码”有两类,即:
- 被多次调用的方法。
- 被多次执行的循环体。
前者很好理解,一个方法被调用得多了,方法体内代码执行的次数自然就多,它成为“热点代码”是理所当然的。
而后者则是为了解决一个方法只被调用过一次或少量的几次,但是方法体内部存在循环次数较多的循环体的问题,这样循环体的代码也被重复执行多次,因此这些代码也应该认为是“热点代码”。
对于第一种情况,由于是由方法调用触发的编译,因此编译器理所当然地会以整个方法作为编译对象,这种编译也是虚拟机中标准的JIT编译方式。
而对于后一种情况,尽管编译动作是由循环体所触发的,但编译器依然会以整个方法(而不是单独的循环体)作为编译对象。这种编译方式因为编译发生在方法执行过程之中,因此形象地称之为栈上替换(On Stack Replacement,简称为OSR编译,即方法栈帧还在栈上,方法就被替换了)。
栈上替换(OSR)
当方法内部存在循环次数较多的循环体时,这些循环体会被当做 “热点代码”,这时尽管JIT即时编译是被循环体触发的,还是会以整个方法(而不是单独的循环体)作为编译对象。这种编译方式因为编译发生在方法执行过程之中,因此形象地称之为栈上替换(On Stack Replacement,简称为OSR编译,即方法栈帧还在栈上,方法就被替换了)。
如何确定热点代码(热点探测)
判断一段代码是否是热点代码,是否需要触发即使编译,这样的行为称为热点探测,热点探测并不一定知道方法具体被调用了多少次,目前主要的热点探测判定方式有两种:
1、基于采样的热点探测
2、基于计数器的热点探测
基于采样的热点探测
采用这种方法的虚拟机会周期性地检查各个线程的栈顶如果发现某个(或某些)方法经常出现在栈顶,那这个方法就是“热点方法”
优点:实现简单高效,容易获取方法调用关系(将调用堆栈展开即可)
缺点:不精确,容易因为因为受到线程阻塞或别的外界因素的影响而扰乱热点探测
基于计数器的热点探测
采用这种方法的虚拟机会为每个方法(甚至是代码块)建立计数器,统计方法的执行次数,如果次数超过一定的阈值就认为它是“热点方法”
优点:统计结果精确严谨
缺点:实现麻烦,需要为每个方法建立并维护计数器,不能直接获取到方法的调用关系
基于计数器的热点探测(Counter Based Hot Spot Detection):采用这种方法的虚拟机会为每个方法(甚至是代码块)建立计数器,统计方法的执行次数,如果执行次数超过一定的阈值就认为它是“热点方法”。这种统计方法实现起来麻烦一些,需要为每个方法建立并维护计数器,而且不能直接获取到方法的调用关系,但是它的统计结果相对来说更加精确和严谨。
在 HotSpot虚拟机中使用的是第二种——基于计数器的热点探测方法,因此它为每个方法准备了两类计数器:方法调用计数器(Invocation Counter)和回边计数器(Back Edge Counter)。
在确定虚拟机运行参数的前提下,这两个计数器都有一个确定的阈值,当计数器超过阈值溢出了,就会触发JIT编译。
我们首先来看看方法调用计数器。顾名思义,这个计数器就用于统计方法被调用的次数,它的默认阈值在Client模式下是1500次,在Server模式下是10000次,这个阈值可以通过虚拟机参数 -XX:CompileThreshold 来人为设定。当一个方法被调用时,会先检查该方法是否存在被JIT编译过的版本,如果存在,则优先使用编译后的本地代码来执行。如果不存在已被编译过的版本,则将此方法的调用计数器值加1,然后判断方法调用计数器与回边计数器值之和是否超过方法调用计数器的阈值。如果已超过阈值,那么将会向即时编译器提交一个该方法的代码编译请求。
如果不做任何设置,执行引擎并不会同步等待编译请求完成,而是继续进入解释器按照解释方式执行字节码,直到提交的请求被编译器编译完成。当编译工作完成之后,这个方法的调用入口地址就会被系统自动改写成新的,下一次调用该方法时就会使用已编译的版本。
如果不做任何设置,方法调用计数器统计的并不是方法被调用的绝对次数,而是一个相对的执行频率,即一段时间之内方法被调用的次数。当超过一定的时间限度,如果方法的调用次数仍然不足以让它提交给即时编译器编译,那这个方法的调用计数器就会被减少一半,这个过程称为方法调用计数器热度的衰减(Counter Decay),而这段时间就称为此方法统计的半衰周期(Counter Half Life Time)。进行热度衰减的动作是在虚拟机进行垃圾收集时顺便进行的,可以使用虚拟机参数-XX:-UseCounterDecay来关闭热度衰减,让方法计数器统计方法调用的绝对次数,这样,只要系统运行时间足够长,绝大部分方法都会被编译成本地代码。另外,可以使用-XX:CounterHalfLifeTime参数设置半衰周期的时间,单位是秒。
逃逸分析(Escape Analysis)
逃逸分析的基本行为就是分析对象动态作用域:当一个对象在方法中被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他方法中,称为方法逃逸。甚至还有可能被外部线程访问到,譬如赋值给类变量或可以在其他线程中访问的实例变量,称为线程逃逸。
例如:
public static StringBuffer craeteStringBuffer(String s1, String s2) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb;
}
StringBuffer sb是一个方法内部变量,上述代码中直接将sb返回,这样这个StringBuffer有可能被其他方法所改变,这样它的作用域就不只是在方法内部,虽然它是一个局部变量,称其逃逸到了方法外部。甚至还有可能被外部线程访问到,譬如赋值给类变量或可以在其他线程中访问的实例变量,称为线程逃逸。
上述代码如果想要StringBuffer sb不逃出方法,可以这样写:
public static String createStringBuffer(String s1, String s2) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb.toString();
}
不直接返回 StringBuffer,那么StringBuffer将不会逃逸出方法。
如果能证明一个对象不会逃逸到方法或线程之外,也就是别的方法或线程无法通过任何途径访问到这个对象,则可能为这个变量进行一些高效的优化,如下所示。
栈上分配(非逃逸对象直接栈上分配)
栈上分配(StackAllocation)
Java虚拟机中,在Java堆上分配创建对象的内存空间几乎是Java程序员都清楚的常识了,Java堆中的对象对于各个线程都是共享和可见的,只要持有这个对象的引用,就可以访问堆中存储的对象数据。虚拟机的垃圾收集系统可以回收堆中不再使用的对象,但回收动作无论是筛选可回收对象,还是回收和整理内存都需要耗费时间。
如果确定一个对象不会逃逸出方法之外,那让这个对象在栈上分配内存将会是一个很不错的主意,对象所占用的内存空间就可以随栈帧出栈而销毁。
在一般应用中,不会逃逸的局部对象所占的比例很大,如果能使用栈上分配,那大量的对象就会随着方法的结束而自动销毁了,垃圾收集系统的压力将会小很多。
是否所有对象都是在堆中分配内存?
所以,如果以后再有人问你:是不是所有的对象和数组都会在堆内存分配空间?
那么你可以告诉他:不一定,随着JIT编译器的发展,在编译期间,如果JIT经过逃逸分析,发现有些对象没有逃逸出方法,那么有可能堆内存分配会被优化成栈内存分配。但是这也并不是绝对的。就像我们前面看到的一样,在开启逃逸分析之后,也并不是所有User对象都在堆上分配。
对象并不一定都是在堆上分配内存的。
https://mp.weixin.qq.com/s?__biz=MzI3NzE0NjcwMg==&mid=2650121307&idx=1&sn=5526473d0248cca8385d2a18ba6b25af
同步消除
同步消除(SynchronizationElimination):线程同步本身是一个相对耗时的过程,如果逃逸分析能够确定一个变量不会逃逸出线程,无法被其他线程访问,那这个变量的读写肯定就不会有竞争,对这个变量实施的同步措施也就可以消除掉。
标量替换
标量替换(ScalarReplacement)
标量(Scalar)是指一个数据已经无法再分解成更小的数据来表示了,Java虚拟机中的原始数据类型(int、long等数值类型以及reference类型等)都不能再进一步分解,它们就可以称为标量。
相对的,如果一个数据可以继续分解,那它就称作聚合量(Aggregate),Java中的对象就是最典型的聚合量。
如果把一个Java对象拆散,根据程序访问的情况,将其使用到的成员变量恢复原始类型来访问就叫做标量替换。
如果逃逸分析证明一个对象不会被外部访问,并且这个对象可以被拆散的话,那程序真正执行的时候将可能不创建这个对象,而改为直接创建它的若干个被这个方法使用到的成员变量来代替。将对象拆分后,除了可以让对象的成员变量在栈上(栈上存储的数据,有很大的概率会被虚拟机分配至物理机器的高速寄存器中存储)分配和读写之外,还可以为后续进一步的优化手段创建条件。
开启逃逸分析
在Java代码运行时,通过JVM参数可指定是否开启逃逸分析,
-XX:+DoEscapeAnalysis : 表示开启逃逸分析
-XX:-DoEscapeAnalysis : 表示关闭逃逸分析
开启逃逸分析之后可以通过参数-XX:+PrintEscapeAnalysis来查看分析结果。
有了逃逸分析支持之后,用户可以使用参数-XX:+EliminateAllocations来开启标量替换,使用+XX:+EliminateLocks来开启同步消除,使用参数-XX:+PrintEliminateAllocations查看标量的替换情况。
从jdk 1.7开始已经默认开始逃逸分析,如需关闭,需要指定-XX:-DoEscapeAnalysis
JVM参数
java 命令官方文档,包括所有可选参数的官方解释(JavaSE 8)
https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html
java 命令官方文档,包括所有可选参数的官方解释(JavaSE 13)
https://docs.oracle.com/en/java/javase/13/docs/specs/man/java.html
JVM启动参数共分为三类:
- 其一是标准参数
-,所有的JVM实现都必须实现这些参数的功能,而且向后兼容; - 其二是非标准参数
-X,默认jvm(HotSopt JVM)实现这些参数的功能,但是并不保证所有jvm实现都满足,且不保证向后兼容; - 其三是高级参数
-XX,此类参数各个jvm实现会有所不同,将来可能会随时取消,需要慎重使用;
为什么需要参数调优?
JVM启动参数在一般开发中默认即可,不需要任何配置。但是在生产环境中,并不保证所有jvm实现都满足,所以为了提高性能,往往需要调整这些参数,以求系统达到最佳性能。另外,-X和-XX参数不保证向后兼容,也即是说“如有变更,恕不在后续版本的JDK通知”(这是官网上的原话);
标准参数
-Dproperty=value
设置系统属性名/值对,运行在此jvm之上的应用程序可用System.getProperty("property")得到value的值。
如果value中有空格,则需要用双引号将该值括起来,如-Dname=”space string”。
该参数通常用于设置系统级全局变量值,如配置文件路径,以便该属性在程序中任何地方都可访问。
-X
输出非标准的参数列表及其描述。
-cp
-cp classpath 或 -classpath classpath
指定一个分号 ; 分割的目录、jar包或zip文档列表作为 classpath,这会覆盖 CLASSPATH 环境变量中的 classpath。
如果没指定 -cp 参数和 CLASSPATH 环境变量,则 classpath 为当前目录。
目录中包含 * 相当于指定目录下的全部 .jar 和 .JAR 文件,例如 mydir 中包含 a.jar 和 b.JAR ,则路径 mydir/* 相当于 A.jar:b.JAR
-client
设置 jvm 使用 client 模式,特点是启动速度比较快,但运行时性能和内存管理效率不高,通常用于客户端应用程序或者PC应用开发和调试。
64 位版本 JDK 会忽略此选项,全都使用 server 模式。
-server
设置jvm使用server模式,特点是启动速度比较慢,但运行时性能和内存管理效率很高,适用于生产环境。在具有64位能力的jdk环境下将默认启用该模式,而忽略-client参数。
64 位版本 JDK 只支持server模式,所以此选项为默认值。
-jar filename
执行 JAR 包中的 java 代码。
jar 包中的 META-INF/MANIFEST.MF 文件应包含 Main-Class:classname 行指定应用的启动入口类,此类应包含 public static void main(String[] args) 方法。
例如 spring boot 应用的 jar 包中 Main-Class: org.springframework.boot.loader.JarLauncher
-javaagent:jarpath[=options]
加载 java 代理 jar 包
非标准参数
-Xms 堆内存初始值(1/64Mem)
-Xms 等同于 -XX:InitialHeapSize
指定 jvm 堆的初始大小(默认单位为字节 bytes),必须是 1024 的整数倍,且必须大于 1MB。
默认为物理内存的 1/64,最小为 1M;
若不设置,默认为新生代和老年代大小之和。
数值后可跟 k/K, m/M, g/G 来指定单位,若不加单位默认为字节。
例如 -Xms5120m,设置初始堆内存为 5120M,-Xms2g,设置初始堆大小为 2G
-Xmx 堆内存最大值(1/4Mem)
-Xmx 等同于 -XX:MaxHeapSize
指定 jvm 堆的最大值(默认单位为字节 bytes),必须是 1024 的整数倍,且必须大于 2MB。
对于服务端来说,默认为物理内存的 1/4 或者 1G,最小为 2M;单位与 -Xms 一致。服务器一般设置 -Xms, -Xmx 相等以避免在每次 GC 后调整堆内存的大小。
数值后可跟 k/K, m/M, g/G 来指定单位,若不加单位默认为字节。
将最大堆内存设为 80MB :
-Xmx83886080
-Xmx81920k
-Xmx80m
-Xmn 新生代初始值和最大值
指定年轻代的初始大小和最大大小(默认单位为字节 bytes),此处的大小是(eden + 2 survivor space)。
建议年轻代大小在整个 JVM 大小的 1/4 到 1/2 之间。
整个JVM内存大小=年轻代大小 + 年老代大小 + 持久代大小,增大年轻代后,将会减小年老代大小。
数值后可跟 k/K, m/M, g/G 来指定单位,若不加单位默认为字节。
将新生代的初始值和最大值设为 256MB :
-Xmn256m
-Xmn262144k
-Xmn268435456
除了使用 -Xmn 同时设置新生代的初始大小和最大大小,还可以用 -XX:NewSize 和 -XX:MaxNewSize 来分别设置新生代的初始大小和最大大小。
-Xss 线程栈大小
-Xss 等同于 -XX:ThreadStackSize
指定每个线程栈的大小(默认单位为字节bytes)
JDK5.0以后每个线程堆栈大小为1M。
在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成。一般小的应用, 如果栈不是很深, 应该是128k够用的 大的应用建议使用256k。这个选项对性能影响比较大,需要严格的测试。
默认值依赖平台
Linux/ARM (32-bit): 320 KB
Linux/i386 (32-bit): 320 KB
Linux/x64 (64-bit): 1024 KB
OS X (64-bit): 1024 KB
Oracle Solaris/i386 (32-bit): 320 KB
Oracle Solaris/x64 (64-bit): 1024 KB
数值后可跟 k/K, m/M, gG 来指定单位,若不加单位默认为字节。
将线程栈大小设为 1024KB:
-Xss1m
-Xss1024k
-Xss1048576
-Xloggc:../log/gc.log
与-verbose:gc功能类似,只是将每次GC事件的相关情况记录到一个文件中,文件的位置最好在本地,以避免网络的潜在问题。
若与verbose命令同时出现在命令行中,则以-Xloggc为准。
如何配置堆大小(-Xms,-Xmx)
-Xms指定jvm堆的初始大小,默认为物理内存的1/64,最小为1M;可以指定单位,比如k、m、g,若不指定,则默认为单位字节。例如-Xms5120m,设置初始堆内存为5120M;-Xms2g,设置初始堆大小为2G。-Xmx指定jvm堆的最大值,默认为物理内存的1/4或者1G,最小为2M;单位与-Xms一致。服务器一般设置-Xms、-Xmx相等以避免在每次GC后调整堆内存的大小。-Xss指定每个线程的堆大小。JDK5.0以后每个线程堆栈大小为1M。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成。一般小的应用, 如果栈不是很深, 应该是128k够用的 大的应用建议使用256k。这个选项对性能影响比较大,需要严格的测试。
建议
一般建议不要给 JVM 太大的内存,因为 Heap 太大,GC 停顿实在是太久了。所以很多开发者喜欢在大内存机器上开多个 JVM 进程,每个给比如最大 8G 以下的内存。
就是
宁可开 4个 8g 的 java 进程,也不要开 1个 32g 的java进程,否则垃圾回收的 STW 时间会比较长。
java -Xmn1g -Xms2g -Xmx2g -jar -Dspring.profiles.active=test /data/app/myapp.jar
如何配置新生代大小(-Xmn)
-Xmn 指定年轻代大小,此处的大小是(eden + 2 survivor space)。整个JVM内存大小=年轻代大小 + 年老代大小 + 持久代大小,增大年轻代后,将会减小年老代大小。
JVM可支持的最大线程数
能创建的线程数的具体计算公式如下:Number of threads = (MaxProcessMemory - JVMMemory - ReservedOsMemory) / (ThreadStackSize)
MaxProcessMemory 指的是一个进程的最大内存
JVMMemory JVM内存
ReservedOsMemory 保留的操作系统内存
ThreadStackSize 线程栈的大小
在java语言里, 当你创建一个线程的时候,虚拟机会在JVM内存创建一个Thread对象同时创建一个操作系统线程,而这个系统线程的内存用的不是JVMMemory,而是系统中剩下的内存(MaxProcessMemory - JVMMemory - ReservedOsMemory)。
由公式得出结论:你给JVM内存越多,那么你能创建的线程越少,越容易发生java.lang.OutOfMemoryError: unable to create new native thread。
java.lang.OutOfMemoryError: unable to create new native thread
线程最大数量由JVM的堆(-Xmx,-Xms)大小、Thread的栈(-Xss)内存大小、系统最大可创建的线程数的限制参数三个方面影响。不考虑系统限制,可以通过这个公式估算:线程数量 = (机器本身可用内存 - JVM分配的堆内存) / Xss的值
结论1:当给JVM的堆内存分配的越大,系统可创建的线程数量就越少。因为线程占用的是系统空间,所以当JVM的堆内存越大,系统本身的内存就越少,自然可生成的线程数量就越少。
结论2:当-Xss的的值越小,可生成的线程数量就越多。线程可用空间保持不变,每个线程占用的栈内存大小变小,自然可生成的线程数量就越多。
-Xnoclassgc
禁用方法区的 class 类元数据的垃圾收集。
注意,这会导致无用的类也不被回收,占用更多的内存空间,最终可能导致方法区的OOM
高级参数
用-XX作为前缀的参数列表在jvm中可能是不健壮的,SUN也不推荐使用,后续可能会在没有通知的情况下就直接取消了;但是由于这些参数中的确有很多是对我们很有用的,比如我们经常会见到的-XX:PermSize、-XX:MaxPermSize等等;
Java HotSpot VM中-XX:的可配置参数,这些参数可以被松散的聚合成三类:
行为参数(Behavioral Options):用于改变jvm的一些基础行为;
性能调优(Performance Tuning):用于jvm的性能调优;
调试参数(Debugging Options):一般用于打开跟踪、打印、输出等jvm参数,用于显示jvm更加详细的信息;
-XX:InitialHeapSize=size 初始堆大小
-Xms 等同于 -XX:InitialHeapSize
指定jvm堆的初始大小(默认单位为字节bytes),必须是 1024 的整数倍,且必须大于1MB。
默认为物理内存的1/64,最小为1M;
若不设置(或者设为0),默认为新生代和老年代大小之和。
数值后可跟 k/K, m/M, gG 来指定单位,若不加单位默认为字节。
设置初始堆大小为 6MB:
-XX:InitialHeapSize=6291456
-XX:InitialHeapSize=6144k
-XX:InitialHeapSize=6m
-XX:MaxHeapSize=size 最大堆大小
-Xmx 等同于 -XX:MaxHeapSize
指定jvm堆的最大值(默认单位为字节bytes),必须是 1024 的整数倍,且必须大于2MB。
对于服务端来说,默认为物理内存的1/4或者1G,最小为2M;单位与-Xms一致。服务器一般设置-Xms、-Xmx相等以避免在每次GC后调整堆内存的大小。
数值后可跟 k/K, m/M, gG 来指定单位,若不加单位默认为字节。
将最大堆内存设为 80MB :
-XX:MaxHeapSize=83886080
-XX:MaxHeapSize=81920k
-XX:MaxHeapSize=80m
-XX:NewSize=size 新生代初始值
-XX:NewSize 等同于 -Xmn
新生代初始值(默认单位为字节bytes)
数值后可跟 k/K, m/M, gG 来指定单位,若不加单位默认为字节。
将新生代的初始值设为 256MB :
-XX:NewSize=256m
-XX:NewSize=262144k
-XX:NewSize=268435456
-XX:MaxNewSize=size 新生代最大值
新生代最大值(默认单位为字节bytes)
-XX:InitialSurvivorRatio=ratio eden/survivor初始比例
当垃圾收集器为 -XX:+UseParallelGC 或 -XX:+UseParallelOldGC 时,eden/survivor 的初始值。
默认情况下, survivor 区比例动态调节是启动的, 这种情况下 eden/survivor 比例会从设置的初始值开始动态调节。
如果 survivor 区动态调节被 -XX:-UseAdaptiveSizePolicy 关闭,将使用固定的 -XX:SurvivorRatio 比例,此时此初始值的设定是没用的。
设新生代大小为 Y , 初始 survivor 区比例为 R, 即eden和两个survivor区的比值为R:1:1, 则初始单个 survivor 区大小为: S=Y/(R+2)
survivor 初始比例值越大,则初始 survivor 区越小。
默认值为 8-XX:InitialSurvivorRatio=8
-XX:SurvivorRatio=ratio eden/survivor比例
Eden 区与 Survivor 区的大小比值, 默认值为 8,即 eden/survivor = 8,所以 eden 与 两个survivor的比例为 8:1:1-XX:SurvivorRatio=n, 表示eden和两个survivor区的比值为n:2,即n:1:1,即2个survivor占年轻代总大小的2/(n+2)
-XX:+UseAdaptiveSizePolicy 开启动态调节eden/survivor比例
JVM默认开启survivor区大小自动调节。
使用 -XX:-UseAdaptiveSizePolicy 关闭自动调节并使用 -XX:SurvivorRatio 手动指定 eden/survivor 比例
-XX:ThreadStackSize=size 线程栈大小
-XX:ThreadStackSize 等同于 -Xss
指定每个线程栈的大小(默认单位为字节bytes)
默认值依赖平台
Linux/ARM (32-bit): 320 KB
Linux/i386 (32-bit): 320 KB
Linux/x64 (64-bit): 1024 KB
OS X (64-bit): 1024 KB
Oracle Solaris/i386 (32-bit): 320 KB
Oracle Solaris/x64 (64-bit): 1024 KB
数值后可跟 k/K, m/M, gG 来指定单位,若不加单位默认为字节。
将线程栈大小设为 1024KB:
-XX:ThreadStackSize=1m
-XX:ThreadStackSize=1024k
-XX:ThreadStackSize=1048576
-XX:PermSize=size 永久代初始值
设置持久代(perm gen)初始大小(默认单位为字节bytes),超过此大小会触发GC
JDK 8 中此参数被废弃,改用 -XX:MetaspaceSize 设置元空间大小
-XX:MaxPermSize=size 永久代最大值
设置持久代(perm gen)最大大小(默认单位为字节bytes)
JDK 8 中此参数被废弃,改用 -XX:MaxMetaspaceSize 设置元空间最大大小
-XX:MetaspaceSize=size 元空间初始值
设置元空间(metaspace)初始值,超过此值会触发GC,GC后会动态增加或降低MetaspaceSize。
默认值依赖平台。
在默认情况下,这个值大小根据不同的平台在 12M 到 20M 浮动。
使用 java -XX:+PrintFlagsInitial 命令查看本机的初始化参数
$ java -XX:+PrintFlagsInitial|grep Meta
uintx InitialBootClassLoaderMetaspaceSize = 4194304 {product}
uintx MaxMetaspaceExpansion = 5452592 {product}
uintx MaxMetaspaceFreeRatio = 70 {product}
uintx MaxMetaspaceSize = 18446744073709551615 {product}
uintx MetaspaceSize = 21810376 {pd product}
uintx MinMetaspaceExpansion = 340784 {product}
uintx MinMetaspaceFreeRatio = 40 {product}
bool TraceMetadataHumongousAllocation = false {product}
bool UseLargePagesInMetaspace = false {product}
如上是在 4G 物理内存的 AWS EC2 服务器上,此值为 20MB
经测试,在 500MB 内存的 AWS VPS上,此值也是 20MB
在 16G 内存的 Mac 笔记本上,此值也是 20MB
在 256G 内存的高配物理机上,此值也是 20MB
-XX:MaxMetaspaceSize=size 元空间最大值(默认无限)
设置元空间(metaspace)最大值。默认为无限。
一个应用的元数据(metadata)的大小取决于应用本身,机器上的其他应用,以及系统可用内存大小。
设置此阈值可以限制 Metaspace 增长的上限,防止因为某些情况导致 Metaspace 无限的使用本地内存,影响到其他程序。
设置最大元空间大小为 256m
-XX:MaxMetaspaceSize=256m
-XX:+UseSerialGC 启用串行收集器
启用串行收集器, 默认不启用。不指定垃圾收集器时会自动根据机器配置和VM类型选择收集器。
-XX:+UseParNewGC 启用新生代ParNew收集器
启用新生代的 ParNew 并行收集器,默认不启用。不指定垃圾收集器时会自动根据机器配置和VM类型选择收集器。
当设置 -XX:+UseConcMarkSweepGC 时,此选项默认开启。 即当老年代使用CMS收集器时,即新生代默认使用 ParNew收集器。
-XX:+UseParallelGC 启用新生代Parallel Scavenge收集器
启用新生代 Parallel Scavenge 收集器,即吞吐量优先收集器。
默认不开启。不指定垃圾收集器时会自动根据机器配置和VM类型选择收集器。
开启此选项时 -XX:+UseParallelOldGC 默认开启,即新生代使用 Parallel Scavenge 收集器时老年代默认使用 Parallel Old收集器。
-XX:+UseParallelOldGC 启用老年代ParallelOld收集器
启用老年代ParallelOld收集器。默认不开启。不指定垃圾收集器时会自动根据机器配置和VM类型选择收集器。
设置 -XX:+UseParallelGC 后默认开启。
-XX:+UseConcMarkSweepGC 启用老年代CMS收集器
启用老年代CMS(Conrrurent Mark Sweep)收集器,默认不开启。不指定垃圾收集器时会自动根据机器配置和VM类型选择收集器。
当设置 -XX:+UseConcMarkSweepGC 时,-XX:+UseParNewGC 默认开启,
在 JDK 8中,设置-XX:+UseConcMarkSweepGC后不能手动再关闭-XX:-UseParNewGC,否则老年代的CMS也无法开启,因为-XX:+UseConcMarkSweepGC -XX:-UseParNewGC会被忽略。
即 JDK 8中,老年代CMS必须搭配新生代ParNew使用。
-XX:CMSInitiatingOccupancyFraction=70 CMS垃圾回收触发阈值
-XX:CMSInitiatingOccupancyFraction 这个参数是指在使用 CMS 收集器的情况下,老年代使用了指定阈值的内存时,出发FullGC。
如: -XX:CMSInitiatingOccupancyFraction=70 CMS垃圾收集器,当老年代达到70%时,触发CMS垃圾回收。
默认值是 -1
如果 CMSInitiatingOccupancyFraction 在 0~100 之间,那么由 CMSInitiatingOccupancyFraction 决定。否则由按 ((100 - MinHeapFreeRatio) + (double)( CMSTriggerRatio * MinHeapFreeRatio) / 100.0) / 100.0 决定
-XX:+PrintCommandLineFlags 打印默认参数
Enables printing of ergonomically selected JVM flags that appeared on the command line. It can be useful to know the ergonomic values set by the JVM, such as the heap space size and the selected garbage collector. By default, this option is disabled and flags are not printed.
打印出 JVM 自动选择的默认参数,通过此项可了解 JVM 自动选择的堆内存大小和默认的垃圾收集器。
内存大小单位是 bytes 字节。
查看JVM的默认垃圾收集器和堆大小
jdk1.7 默认垃圾收集器 Parallel Scavenge(新生代)+ Parallel Old(老年代)
jdk1.8 默认垃圾收集器 Parallel Scavenge(新生代)+ Parallel Old(老年代)
jdk1.9 默认垃圾收集器 G1
java -XX:+PrintCommandLineFlags -version
在 16G 内存的 mac pro 上
java -XX:+PrintCommandLineFlags -version
-XX:InitialHeapSize=268435456 -XX:MaxHeapSize=4294967296 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC
java version "1.8.0_171"
Java(TM) SE Runtime Environment (build 1.8.0_171-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode)
可以看到有 -XX:+UseParallelGC 选项, 开启此选项时 -XX:+UseParallelOldGC 默认开启,即新生代使用 Parallel Scavenge 收集器时老年代默认使用 Parallel Old收集器。
在 4G 物理内存的 AWS EC2 服务器上
$ java -XX:+PrintCommandLineFlags -version
-XX:InitialHeapSize=60814400 -XX:MaxHeapSize=973030400 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC
openjdk version "1.8.0_171"
OpenJDK Runtime Environment (build 1.8.0_171-b10)
OpenJDK 64-Bit Server VM (build 25.171-b10, mixed mode)
在 500M 内存的 aws lightsail vps上
$ java -XX:+PrintCommandLineFlags -version
-XX:InitialHeapSize=7894720 -XX:MaxHeapSize=130862280 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops
openjdk version "1.8.0_201"
OpenJDK Runtime Environment (build 1.8.0_201-b09)
OpenJDK 64-Bit Server VM (build 25.201-b09, mixed mode)
在 16G 内存的 mac pro 上
java -XX:+PrintCommandLineFlags -version
-XX:InitialHeapSize=268435456 -XX:MaxHeapSize=4294967296 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC
java version "1.8.0_171"
Java(TM) SE Runtime Environment (build 1.8.0_171-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode)
在 64G 内存的 服务器物理机上
# java -XX:+PrintCommandLineFlags -version
-XX:InitialHeapSize=1046564160 -XX:MaxHeapSize=16745026560 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
初始内存 1GB,最大内存 16GB
-XX:+PrintGC
每次GC时打印相关信息
输出形式:
[GC 118250K->113543K(130112K), 0.0094143 secs]
[Full GC 121376K->10414K(130112K), 0.0650971 secs]
-XX:+PrintGCTimeStamps
打印每次GC的时间戳
-XX:+PrintHeapAtGC
打印GC前后的详细堆栈信息
-XX:+HeapDumpOnOutOfMemoryError OOM时dump堆
当首次遭遇 OOM 时导出此时堆中相关信息
当抛出 java.lang.OutOfMemoryError 异常时, 使用 heap profiler (HPROF) 导出堆内存内容到当前目录。
可以使用 -XX:HeapDumpPath 选项指定导出目录
默认不开启。
-XX:HeapDumpPath=path 指定堆dump目录
指定堆 dump 的目录和文件名
默认 dump 到当前工作目录,文件名为 java_pid{pid}.hprof
默认值的设定方式,其中 %p 表示进程号-XX:HeapDumpPath=./java_pid%p.hprof
导出到固定文件 /var/log/java/java_heapdump.hprof,但这样多次 dump 的文件会互相覆盖,只保留了最后一次-XX:HeapDumpPath=/var/log/java/java_heapdump.hprof
如何配置永久代大小(-XX:PermSize)
-XX:PermSize
指定初始分配的非堆内存大小,即持久代(perm gen)初始大小,默认是物理内存的1/64
-XX:MaxPermSize
指定最大非堆内存大小,即持久代最大值,默认是物理内存的1/4。例如-XX:MaxPermSize=256m,设置持久代大小为256M。
如何生成dump文件
1、配置jvm参数,自动在OOM时产生dump文件
-XX:+HeapDumpOnOutOfMemoryError
当首次遭遇OOM时导出此时堆中相关信息
-XX:HeapDumpPath
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-Xloggc:/usr/aaa/dump/heap_trace.txt
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/aaa/dump -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:/usr/aaa/dump/heap_trace.txt
2、在命令行中使用jmap工具手动导出dump文件
3、在图形界面jvisualvm中远程产生dump文件,内部时通过jmx实现的
JVM性能调优之生成堆的dump文件
http://blog.csdn.net/lifuxiangcaohui/article/details/37992725
jvm调优(合理配置堆内存各部分大小)
一步步优化JVM四:决定Java堆的大小以及内存占用
https://blog.csdn.net/zhoutao198712/article/details/7783070
jps
JVM Process Status Tool,显示指定系统内所有具有访问权限的HotSpot虚拟机进程。
命令格式:
jps [options] [hostid]
options参数
-l : 输出主类全名或jar路径
-q : 只显示pid,不显示class名称,jar文件名和传递给main 方法的参数
-m : 输出JVM启动时传递给main()的参数
-v : 输出JVM启动时显示指定的JVM参数
其中[options]、[hostid]参数也可以不写
jps只能看到当前用户的java进程
jps只能显示当前用户的java进程,如果服务器上的java进程是其他用户启动的,需要su到其他账户下查看。
典型的比如服务是 root 账号启动的,用普通账号登录后直接jps是看不到的,需要sudo jps才行。
jps命令原理
jdk 中的 jps 命令可以显示当前运行的 java 进程以及相关参数,它的实现机制如下:
java 程序在启动以后,会在 java.io.tmpdir 指定的目录下,就是临时文件夹里,生成一个类似于 hsperfdata_User 的文件夹,这个文件夹里(在Linux中为 /tmp/hsperfdata_{userName}/),有几个文件,名字就是java进程的pid,因此列出当前运行的java进程,只是把这个目录里的文件名列一下而已。 至于系统的参数什么,就可以解析这几个文件获得。
Java命令学习系列(一)——Jps
https://www.hollischuang.com/archives/105
JVM调优命令-jps
http://www.cnblogs.com/myna/p/7567710.html
jstack
jstack 主要用来查看某个 Java 进程内的线程堆栈信息。
jstack 用于生成 java 虚拟机当前时刻的线程快照。
jstack 可以定位到线程堆栈,根据堆栈信息我们可以定位到具体代码,所以它在 JVM 性能调优中使用得非常多。
线程快照是当前 java 虚拟机内每一条线程正在执行的方法堆栈的集合,生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等。
线程出现停顿的时候通过 jstack 来查看各个线程的调用堆栈,就可以知道没有响应的线程到底在后台做什么事情,或者等待什么资源。
如果 java 程序崩溃生成 core 文件,jstack 工具可以用来获得core文件的java stack和native stack的信息,从而可以轻松地知道java程序是如何崩溃和在程序何处发生问题。
另外,jstack工具还可以附属到正在运行的java程序中,看到当时运行的java程序的java stack和native stack的信息, 如果现在运行的java程序呈现hung的状态,jstack是非常有用的。
命令语法:
jstack [-l] <pid> 连接到正在运行的进程
jstack -F [-m] [-l] <pid> 连接到挂起的进程
jstack [-m] [-l] <executable> <core> 连接到core文件
jstack [-m] [-l] [server_id@]<remote server IP or hostname> 连接到远程主机
参数:
-F:当正常输出请求不被响应时,强制输出线程栈堆。-l 除线程栈堆外,显示关于锁的附加信息。-l long listings,会打印出额外的锁信息,在发生死锁时可以用jstack -l pid来观察锁持有情况
-m:如果调用本地方法的话,可以显示c/c++的栈堆
top -Hp 线程号和jstack结果线程号关联
top -Hp pid 能看到指定进程的线程号
进一步,如果是 java 进程,还可以通过 jstack pid 查看 jvm 线程信息,其中的 nid 就是线程号,是十六进制的。
可以将 top -Hp 结果中最耗cpu的线程号转为十六进制后(比如 d4c)在 jstack 结果中搜索 0xd4c,从而看到指定线程号的堆栈
# jstack 6 |head -100
2022-02-17 12:43:19
Full thread dump Java HotSpot(TM) 64-Bit Server VM (25.101-b13 mixed mode):
"globalEventExecutor-1-691" #3244 prio=5 os_prio=0 tid=0x00007fb1b4002000 nid=0xd57 runnable [0x00007fa953847000]
java.lang.Thread.State: RUNNABLE
at sun.nio.ch.FileDispatcherImpl.preClose0(Native Method)
at sun.nio.ch.SocketDispatcher.preClose(SocketDispatcher.java:59)
at sun.nio.ch.SocketChannelImpl.implCloseSelectableChannel(SocketChannelImpl.java:838)
- locked <0x00000007976c96b0> (a java.lang.Object)
at java.nio.channels.spi.AbstractSelectableChannel.implCloseChannel(AbstractSelectableChannel.java:234)
at java.nio.channels.spi.AbstractInterruptibleChannel.close(AbstractInterruptibleChannel.java:115)
- locked <0x00000007976c9660> (a java.lang.Object)
at io.netty.channel.socket.nio.NioSocketChannel.doClose(NioSocketChannel.java:343)
"Attach Listener" #3233 daemon prio=9 os_prio=0 tid=0x00007fb468013000 nid=0xd4c waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"brpc-client-io-thread-normal:com.xx.xxService:1.0.0-47" #3215 daemon prio=5 os_prio=0 tid=0x00007fb364023000 nid=0xcd1 runnable [0x00007fb4b44c4000]
java.lang.Thread.State: RUNNABLE
at sun.nio.ch.EPollArrayWrapper.epollWait(Native Method)
at sun.nio.ch.EPollArrayWrapper.poll(EPollArrayWrapper.java:269)
"worker-thread-1063" #3197 prio=5 os_prio=0 tid=0x00007faf90030000 nid=0xcbf waiting on condition [0x00007fa93e4f4000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000006c1f2c180> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
jstack -l pid 定位死锁
Found one Java-level deadlock:
=============================
"Thread-1":
waiting to lock monitor 0x00007f0134003ae8 (object 0x00000007d6aa2c98, a java.lang.Object),
which is held by "Thread-0"
"Thread-0":
waiting to lock monitor 0x00007f0134006168 (object 0x00000007d6aa2ca8, a java.lang.Object),
which is held by "Thread-1"
Java stack information for the threads listed above:
===================================================
"Thread-1":
at javaCommand.DeadLockclass.run(JStackDemo.java:40)
- waiting to lock <0x00000007d6aa2c98> (a java.lang.Object)
- locked <0x00000007d6aa2ca8> (a java.lang.Object)
at java.lang.Thread.run(Thread.java:745)
"Thread-0":
at javaCommand.DeadLockclass.run(JStackDemo.java:27)
- waiting to lock <0x00000007d6aa2ca8> (a java.lang.Object)
- locked <0x00000007d6aa2c98> (a java.lang.Object)
at java.lang.Thread.run(Thread.java:745)
Found 1 deadlock.
告诉我们 Found one Java-level deadlock,然后指出造成死锁的两个线程的内容。然后,又通过 Java stack information for the threads listed above 来显示更详细的死锁的信息:
Thread-1在想要执行第40行的时候,当前锁住了资源0x00000007d6aa2ca8,但是他在等待资源0x00000007d6aa2c98
Thread-0在想要执行第27行的时候,当前锁住了资源0x00000007d6aa2c98,但是他在等待资源0x00000007d6aa2ca8
由于这两个线程都持有资源,并且都需要对方的资源,所以造成了死锁。 原因我们找到了,就可以具体问题具体分析,解决这个死锁了。
JVM调优命令-jstack
http://www.cnblogs.com/myna/p/7595414.html
JVM性能调优监控工具专题一:JVM自带性能调优工具(jps,jstack,jmap,jhat,jstat,hprof)
http://josh-persistence.iteye.com/blog/2161848
使用jstack精确找到异常代码的
https://blog.csdn.net/mr__fang/article/details/68496248
jstack简单使用,定位死循环、线程阻塞、死锁等问题
http://www.cnblogs.com/chenpi/p/5377445.html
java命令–jstack 工具
https://www.cnblogs.com/kongzhongqijing/articles/3630264.html
jstat
JVM Statistics Monitoring Tool,是用于监视虚拟机运行时状态信息的命令,它可以显示出虚拟机进程中的类装载、内存、垃圾收集、JIT编译等运行数据。
jstat命令详解
https://blog.csdn.net/zhaozheng7758/article/details/8623549
命令格式jstat [options] VMID [interval] [count]
参数:
[options] : 操作参数,一般使用 -gcutil 查看gc情况
VMID : 本地虚拟机进程ID,即当前运行的java进程号
[-hlines]:每 lines 行显示一次标题,比如 -h3 表示每三行显示一下标题
[interval] : 连续输出的时间间隔,默认单位为毫秒(ms),可选单位有秒(s)或者毫秒(ms),比如5s,5ms
[count] : 连续输出的次数,如果缺省打印无数次
内存以“KB”为单位,耗费时间以“秒”为单位。
例如:
jstat -gc pid 250 6
每250毫秒打印一次,一共打印6次,还可以加上-h3每三行显示一下标题。
jstat -gc pid 2s
每 2s 打印一次
jstat -gc -h10 pid 2s
每 2s 打印一次,每10次打印一次表头
使用 watch 看动态变化更清晰:
watch -n 2 jstat -gc pid
option参数:
-class,类加载的行为统计。显示加载class的数量,及所占空间等信息。-compiler,HotSpot JIT编译器行为统计。-gc,垃圾回收堆的行为统计。-gccapacity,各个垃圾回收代容量(young,old,perm)和他们相应的空间统计。-gcutil,垃圾回收统计概述(百分比)。-gccause,垃圾收集统计概述(同-gcutil),附加最近两次垃圾回收事件的原因。-gcnew,新生代行为统计。-gcnewcapacity,新生代与其相应的内存空间的统计。-gcold,老年代和永久代行为统计。-gcoldcapacity,老年代大小统计。-gcpermcapacity,永久代大小统计。-printcompilation,HotSpot编译方法统计。
使用示例:
jstat -gc -h10 pid 5s 查看gc次数
垃圾回收堆的行为统计,常用命令
其中最后五项,分别是young gc的次数,young gc的时间,full gc的次数,full gc的时间,gc的总时间。
# jstat -gc 1 2s
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
2880.0 2880.0 0.0 635.6 23232.0 5278.6 57800.0 35834.9 70144.0 66356.3 8704.0 8056.8 333 3.632 4 1.121 4.754
2880.0 2880.0 0.0 635.6 23232.0 5748.9 57800.0 35834.9 70144.0 66356.3 8704.0 8056.8 333 3.632 4 1.121 4.754
2880.0 2880.0 0.0 635.6 23232.0 5748.9 57800.0 35834.9 70144.0 66356.3 8704.0 8056.8 333 3.632 4 1.121 4.754
2880.0 2880.0 0.0 635.6 23232.0 5748.9 57800.0 35834.9 70144.0 66356.3 8704.0 8056.8 333 3.632 4 1.121 4.754
2880.0 2880.0 0.0 635.6 23232.0 5780.5 57800.0 35834.9 70144.0 66356.3 8704.0 8056.8 333 3.632 4 1.121 4.754
2880.0 2880.0 0.0 635.6 23232.0 5782.9 57800.0 35834.9 70144.0 66356.3 8704.0 8056.8 333 3.632 4 1.121 4.754
2880.0 2880.0 0.0 635.6 23232.0 5820.1 57800.0 35834.9 70144.0 66356.3 8704.0 8056.8 333 3.632 4 1.121 4.754
2880.0 2880.0 0.0 635.6 23232.0 5820.1 57800.0 35834.9 70144.0 66356.3 8704.0 8056.8 333 3.632 4 1.121 4.754
2880.0 2880.0 0.0 635.6 23232.0 5820.1 57800.0 35834.9 70144.0 66356.3 8704.0 8056.8 333 3.632 4 1.121 4.754
2880.0 2880.0 0.0 635.6 23232.0 6281.1 57800.0 35834.9 70144.0 66356.3 8704.0 8056.8 333 3.632 4 1.121 4.754
C 即 Capacity 总容量,U 即 Used 已使用的容量
S0C 年轻代中第一个survivor(幸存区)的容量 (KB)
S1C 年轻代中第二个survivor(幸存区)的容量 (KB)
S0U 年轻代中第一个survivor(幸存区)目前已使用空间 (KB)
S1U 年轻代中第二个survivor(幸存区)目前已使用空间 (KB)
EC 年轻代中Eden(伊甸园)的容量 (KB)
EU 年轻代中Eden(伊甸园)目前已使用空间 (KB)
OC Old代的容量 (KB)
OU Old代目前已使用空间 (KB)
– Perm有关字段只在 java 8 之前有
PC Perm(持久代)的容量 (KB)
PU Perm(持久代)目前已使用空间 (KB)
– java 8 之后 Metaspace(元空间) 替换 Perm(永久代)
MC Metaspace(元空间)的容量 (KB)
MU Metaspace(元空间)目前已使用空间 (KB)
– java 8 之后新增 压缩类空间
CCSC 压缩类空间大小
CCSU 压缩类空间使用大小
YGC 从应用程序启动到采样时年轻代中gc次数
YGCT 从应用程序启动到采样时年轻代中gc所用时间(s秒)
FGC 从应用程序启动到采样时old代(全gc)gc次数
FGCT 从应用程序启动到采样时old代(全gc)gc所用时间(s秒)
GCT 从应用程序启动到采样时gc用的总时间(s)
G1 垃圾回收器中,堆被划分为多个大小相等的 Region(区域),但逻辑上仍归类为 Eden、Survivor 或 Old 空间
OC/OU 所有被标记为 Old Region 的 总容量/已使用容量(KB)
EC/EU 所有 Eden Region 的 总容量/已使用容量(KB)
S0C/U, S1C/U 所有 Survivor 0/1 Region 的 总容量/已使用容量(KB)
jstat -gccapacity pid 5s 看堆内存最大/小值
同-gc,还会输出Java堆各区域使用到的最大、最小空间
# jstat -gccapacity 1 2s
NGCMN NGCMX NGC S0C S1C EC OGCMN OGCMX OGC OC MCMN MCMX MC CCSMN CCSMX CCSC YGC FGC
10240.0 156992.0 28992.0 2880.0 2880.0 23232.0 20480.0 314048.0 57800.0 57800.0 0.0 1110016.0 70144.0 0.0 1048576.0 8704.0 334 4
10240.0 156992.0 28992.0 2880.0 2880.0 23232.0 20480.0 314048.0 57800.0 57800.0 0.0 1110016.0 70144.0 0.0 1048576.0 8704.0 334 4
10240.0 156992.0 28992.0 2880.0 2880.0 23232.0 20480.0 314048.0 57800.0 57800.0 0.0 1110016.0 70144.0 0.0 1048576.0 8704.0 334 4
10240.0 156992.0 28992.0 2880.0 2880.0 23232.0 20480.0 314048.0 57800.0 57800.0 0.0 1110016.0 70144.0 0.0 1048576.0 8704.0 334 4
10240.0 156992.0 28992.0 2880.0 2880.0 23232.0 20480.0 314048.0 57800.0 57800.0 0.0 1110016.0 70144.0 0.0 1048576.0 8704.0 334 4
10240.0 156992.0 28992.0 2880.0 2880.0 23232.0 20480.0 314048.0 57800.0 57800.0 0.0 1110016.0 70144.0 0.0 1048576.0 8704.0 334 4
10240.0 156992.0 28992.0 2880.0 2880.0 23232.0 20480.0 314048.0 57800.0 57800.0 0.0 1110016.0 70144.0 0.0 1048576.0 8704.0 334 4
10240.0 156992.0 28992.0 2880.0 2880.0 23232.0 20480.0 314048.0 57800.0 57800.0 0.0 1110016.0 70144.0 0.0 1048576.0 8704.0 334 4
10240.0 156992.0 28992.0 2880.0 2880.0 23232.0 20480.0 314048.0 57800.0 57800.0 0.0 1110016.0 70144.0 0.0 1048576.0 8704.0 334 4
10240.0 156992.0 28992.0 2880.0 2880.0 23232.0 20480.0 314048.0 57800.0 57800.0 0.0 1110016.0 70144.0 0.0 1048576.0 8704.0 334 4
NGCMN 年轻代(young)中初始化(最小)的大小(KB)
NGCMX 年轻代(young)的最大容量 (KB)
NGC 年轻代(young)中当前的容量 (KB)
S0C 年轻代中第一个survivor(幸存区)的容量 (KB)
S1C 年轻代中第二个survivor(幸存区)的容量 (KB)
EC 年轻代中Eden(伊甸园)的容量 (KB)
OGCMN old代中初始化(最小)的大小 (KB)
OGCMX old代的最大容量(KB)
OGC old代当前新生成的容量 (KB)
OC Old代的容量 (KB)
– Perm有关字段只在 java 8 之前有
PGCMN perm代中初始化(最小)的大小 (KB)
PGCMX perm代的最大容量 (KB)
PGC perm代当前新生成的容量 (KB)
PC Perm(持久代)的容量 (KB)
– java 8 之后 Metaspace(元空间) 替换 Perm(永久代)
MCMN Metaspace(元空间)中初始化(最小)的大小 (KB)
MCMX Metaspace(元空间)的最大容量 (KB)
MC Metaspace(元空间)的容量 (KB)
– java 8 之后新增 压缩类空间
CCSMN 最小压缩类空间大小
CCSMX 最大压缩类空间大小
YGC 从应用程序启动到采样时年轻代中gc次数
FGC 从应用程序启动到采样时old代(全gc)gc次数
jstat -gcutil pid 5s 查看堆内存百分比
同-gc,输出的是已使用空间占总空间的百分比
# jstat -gcutil 1 2s
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 21.71 91.37 62.02 94.61 92.57 339 3.668 4 1.121 4.789
0.00 21.71 91.38 62.02 94.61 92.57 339 3.668 4 1.121 4.789
0.00 21.71 91.38 62.02 94.61 92.57 339 3.668 4 1.121 4.789
0.00 21.71 93.23 62.02 94.61 92.57 339 3.668 4 1.121 4.789
0.00 21.71 93.40 62.02 94.61 92.57 339 3.668 4 1.121 4.789
0.00 21.71 93.40 62.02 94.61 92.57 339 3.668 4 1.121 4.789
0.00 21.71 93.41 62.02 94.61 92.57 339 3.668 4 1.121 4.789
S0:Survivor 0 区当前使用比例
S1:Survivor 1 区当前使用比例
E:Eden 伊甸园区使用比例
O:Old 老年代使用比例
P 永久代当前使用比例(JDK1.8之前)
M MetaSpace 元空间当前使用比例(JDK1.8之后)
CCS 压缩类空间 当前使用比例(JDK1.8之后)
YGC:年轻代垃圾回收次数
FGC:老年代垃圾回收次数
FGCT:老年代垃圾回收消耗时间
GCT:垃圾回收消耗总时间
S0 Survivor区0使用内存百分比
S1 Survivor区1使用内存百分比
E Eden区使用内存百分比
O 老年代使用内存百分比
YGC 年轻代GC事件数量
YGCT 年轻代GC耗费时间,秒
FGC Full GC事件数量
FGCT Full GC耗费时间,秒
GCT GC耗费总时间
jstat -gccause pid 5s 查看gc原因
垃圾收集统计概述(同-gcutil),附加最近两次垃圾回收事件的原因
[prouser@vm-vmw96712-app bin]$ ./jstat -gccause 105970 2s
S0 S1 E O P YGC YGCT FGC FGCT GCT LGCC GCC
0.00 0.00 2.64 10.10 99.92 684 23.660 509 485.376 509.037 System.gc() No GC
0.00 0.00 2.64 10.10 99.92 684 23.660 509 485.376 509.037 System.gc() No GC
jstat -gcnew pid 5s
统计新生代行为
# jstat -gcnew 1 2s
S0C S1C S0U S1U TT MTT DSS EC EU YGC YGCT
2880.0 2880.0 0.0 849.6 15 15 1440.0 23232.0 2189.6 1009 9.612
2880.0 2880.0 0.0 849.6 15 15 1440.0 23232.0 5038.0 1009 9.612
2880.0 2880.0 0.0 849.6 15 15 1440.0 23232.0 5412.9 1009 9.612
2880.0 2880.0 0.0 849.6 15 15 1440.0 23232.0 5893.8 1009 9.612
2880.0 2880.0 0.0 849.6 15 15 1440.0 23232.0 6016.0 1009 9.612
2880.0 2880.0 0.0 849.6 15 15 1440.0 23232.0 6052.2 1009 9.612
2880.0 2880.0 0.0 849.6 15 15 1440.0 23232.0 6054.5 1009 9.612
DSS:survivor区域大小 (KB)
S0C 年轻代中第一个survivor(幸存区)的容量 (KB)
S1C 年轻代中第二个survivor(幸存区)的容量 (KB)
S0U 年轻代中第一个survivor(幸存区)目前已使用空间 (KB)
S1U 年轻代中第二个survivor(幸存区)目前已使用空间 (KB)
TT Tenuring threshold(提升阈值) 对象在新生代存活的次数
MTT 最大的tenuring threshold 对象在新生代存活的最大次数
DSS 期望的幸存区大小
EC 年轻代中Eden(伊甸园)的容量 (KB)
EU 年轻代中Eden(伊甸园)目前已使用空间 (KB)
YGC 从应用程序启动到采样时年轻代中gc次数
YGCT 从应用程序启动到采样时年轻代中gc所用时间(s)
jstat -gcnewcapacity pid 5s
新生代与其相应的内存空间的统计
# jstat -gcnewcapacity 1 3s
NGCMN NGCMX NGC S0CMX S0C S1CMX S1C ECMX EC YGC FGC
10240.0 156992.0 28992.0 15680.0 2880.0 15680.0 2880.0 125632.0 23232.0 1010 4
10240.0 156992.0 28992.0 15680.0 2880.0 15680.0 2880.0 125632.0 23232.0 1010 4
10240.0 156992.0 28992.0 15680.0 2880.0 15680.0 2880.0 125632.0 23232.0 1010 4
10240.0 156992.0 28992.0 15680.0 2880.0 15680.0 2880.0 125632.0 23232.0 1010 4
NGCMN:新生代最小容量
NGCMX:新生代最大容量
NGC:当前新生代容量
S0CMX:最大幸存1区大小
S0C:当前幸存1区大小
S1CMX:最大幸存2区大小
S1C:当前幸存2区大小
ECMX:最大伊甸园区大小
EC:当前伊甸园区大小
YGC:年轻代垃圾回收次数
FGC:老年代回收次数
jstat -gcold pid 5s
统计老年代行为
[prouser@vm-vmw96692-app bin]$ jstat -gcold 44398 2s
PC PU OC OU YGC FGC FGCT GCT
184128.0 183386.4 4194304.0 2685339.4 10840 387 1045.842 3277.150
184128.0 183386.4 4194304.0 2685339.4 10840 387 1045.842 3277.150
jstat -gcoldcapacity pid 5s
老年代与其相应的内存空间的统计
[prouser@vm-vmw96692-app bin]$ jstat -gcoldcapacity 44398 2s
OGCMN OGCMX OGC OC YGC FGC FGCT GCT
4194304.0 4194304.0 4194304.0 4194304.0 10841 387 1045.842 3277.217
4194304.0 4194304.0 4194304.0 4194304.0 10841 387 1045.842 3277.217
jstat -gcpermcapacity pid 5s
永久代与其相应内存空间的统计
[prouser@vm-vmw96692-app bin]$ jstat -gcpermcapacity 44398 2s
PGCMN PGCMX PGC PC YGC FGC FGCT GCT
21248.0 262144.0 184128.0 184128.0 10841 387 1045.842 3277.217
21248.0 262144.0 184128.0 184128.0 10841 387 1045.842 3277.217
jstat -class pid 5s
监视类装载、卸载数量、总空间以及耗费的时间
# jstat -class 1 2s
Loaded Bytes Unloaded Bytes Time
12759 22375.4 0 0.0 55.28
12759 22375.4 0 0.0 55.28
12759 22375.4 0 0.0 55.28
12759 22375.4 0 0.0 55.28
Loaded : 加载class的数量
Bytes : 装载类所占用的字节数
Unloaded : 未加载class的数量
Bytes : 未加载class的字节大小
Time : 装载和卸载类所花费的时间
jstat -compiler pid 5s
输出JIT编译过的方法数量耗时等
# jstat -compiler 1 2s
Compiled Failed Invalid Time FailedType FailedMethod
12712 0 0 103.88 0
12712 0 0 103.88 0
12712 0 0 103.88 0
Compiled : 编译数量
Failed : 编译失败数量
Invalid : 无效数量
Time : 编译耗时
FailedType : 失败类型
FailedMethod : 失败方法的全限定名
jstat -printcompilation pid 5s
hotspot编译方法统计
[prouser@vm-vmw96692-app bin]$ jstat -printcompilation 44398 2s
Compiled Size Type Method
6966 5 1 com/masikkk/service getFlightDateStart
6966 5 1 com/masikkk/request getFlightDateStart
Compiled:被执行的编译任务的数量
Size:方法字节码的字节数
Type:编译类型
Method:编译方法的类名和方法名。类名使用”/“ 代替 “.” 作为空间分隔符. 方法名是给出类的方法名. 格式是一致于HotSpot - XX:+PrintComplation 选项
JVM调优命令-jstat - 钰火 - 博客园
http://www.cnblogs.com/myna/p/7567769.html
jmap
jmap,Java 内存映射工具(Java Memory Map),主要用于打印指定 Java 进程、核心文件或远程调试服务器的共享对象内存映射或堆内存细节。
JVM Memory Map 命令用于生成 heap dump 文件,如果不使用这个命令,还可以使用 -XX:+HeapDumpOnOutOfMemoryError 参数来让虚拟机出现OOM的时候自动生成dump文件。jmap不仅能生成dump文件,还可以查询 finalize 执行队列、Java 堆和永久代的详细信息,如当前使用率、当前使用的是哪种收集器等。
jmap语法:
jmap [option] <pid>,连接到进程
jmap [option] <executable> <core>,连接到core文件
jmap [option] [server_id@]<remote server IP or hostname>,连接到远程主机
option参数
-heap: 显示Java堆详细信息-histo[:live]: 显示堆中对象的统计信息,若指定live,只统计存活的对象-permstat:显示永久代的统计信息-finalizerinfo: 显示在F-Queue队列等待Finalizer线程执行finalize方法的对象-dump:<dump-options>: 在hprof二进制文件中生成堆转储快照
dump-options:live,只转储存活对象,若不指定则转储堆中所有对象format=b,文件格式为二进制file=<file>,指定文件名-F: 强制。结合jmap -dump或jmap -histo使用,如果指定的pid没有响应,强制生成dump快照。此模式下,不支持live子选项。
使用示例:
jmap -dump:live,format=b,file=a pid
jmap -dump:live,format=b,file=xx.hprof pid dump 堆到文件,format指定输出格式,live指明是活着的对象,file指定文件名jmap -dump:format=b,file=xx.hprof pid dump 到指定文件
注意:JVM 在执行 dump 操作时会 stop the word,也就是说此时所有的用户线程都会暂停运行。
live: 只导出有引用的对象,忽略即将被垃圾回收的对象
$ ./jmap -dump:live,format=b,file=tapi-server.hprof 105970
Dumping heap to /opt/app/appuser/jboss-eap-5.2/jdk1.6.0_43/bin/tapi-server.hprof ...
Heap dump file created
jmap -heap pid 打印堆概要信息
打印heap的概要信息,GC使用的算法,heap的配置及使用情况,可以用此来判断内存目前的使用情况以及垃圾回收情况
jdk8 之后的版本无法使用 jmap -heap pid,改用 jhsdb jmap --heap --pid pid
报错:
Error: -heap option used
Cannot connect to core dump or remote debug server. Use jhsdb jmap instead
$ ./jmap -heap 105970
Attaching to process ID 105970, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 20.14-b01
using thread-local object allocation.
Parallel GC with 8 thread(s)
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 4294967296 (4096.0MB)
NewSize = 1310720 (1.25MB)
MaxNewSize = 17592186044415 MB
OldSize = 5439488 (5.1875MB)
NewRatio = 2
SurvivorRatio = 8
PermSize = 21757952 (20.75MB)
MaxPermSize = 268435456 (256.0MB)
Heap Usage:
PS Young Generation
Eden Space:
capacity = 1418461184 (1352.75MB)
used = 390125360 (372.0525360107422MB)
free = 1028335824 (980.6974639892578MB)
27.503421623414688% used
From Space:
capacity = 6750208 (6.4375MB)
used = 0 (0.0MB)
free = 6750208 (6.4375MB)
0.0% used
To Space:
capacity = 6422528 (6.125MB)
used = 0 (0.0MB)
free = 6422528 (6.125MB)
0.0% used
PS Old Generation
capacity = 2863333376 (2730.6875MB)
used = 290497352 (277.0398635864258MB)
free = 2572836024 (2453.647636413574MB)
10.145425413432543% used
PS Perm Generation
capacity = 130678784 (124.625MB)
used = 130595664 (124.54573059082031MB)
free = 83120 (0.0792694091796875MB)
99.9363936536171% used
jmap -finalizerinfo pid 待回收对象
打印等待回收的对象信息
jmap -finalizerinfo 105970
[prouser@vm-vmw96712-app bin]$ ./jmap -finalizerinfo 105970
Attaching to process ID 105970, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 20.14-b01
Number of objects pending for finalization: 0
说明当前F-QUEUE队列中并没有等待Fializer线程执行finalize方法的对象
jmap -histo:live pid
打印 Java 堆中对象直方图,通过该图可以获取每个 class 的对象数目,占用内存大小和类全名信息
live 参数是可选的,如果指定,会进行fullGC,则只转储堆中的活动对象;如果没有指定,则转储堆中的所有对象。
$ ./jmap -histo:live 105970
num #instances #bytes class name
----------------------------------------------
1: 686127 85776304 [C
2: 1288224 41223168 java.lang.String
3: 179493 27413544 <constMethodKlass>
4: 179493 24422408 <methodKlass>
5: 18092 20337824 <constantPoolKlass>
6: 449738 17989520 java.util.TreeMap$Entry
7: 496918 15901376 java.util.HashMap$Entry
8: 18092 14522336 <instanceKlassKlass>
9: 249163 13915328 <symbolKlass>
10: 14536 11228224 <constantPoolCacheKlass>
11: 132926 10685480 [Ljava.util.HashMap$Entry;
12: 68494 7546160 [Ljava.lang.Object;
13: 41473 6531744 [B
14: 77832 6226560 java.util.jar.JarFile$JarFileEntry
15: 135428 5417120 java.util.concurrent.ConcurrentHashMap$Segment
16: 111130 5334240 java.util.HashMap
17: 159326 5098432 java.util.concurrent.ConcurrentHashMap$HashEntry
18: 124476 4979040 java.util.LinkedHashMap$Entry
19: 77791 4978624 org.jboss.virtual.plugins.context.zip.ZipEntryHandler
20: 152424 4877568 java.util.concurrent.locks.ReentrantLock$NonfairSync
21: 53005 4664440 java.lang.reflect.Method
22: 8114 4543240 <methodDataKlass>
23: 94630 4542240 java.util.TreeMap
24: 135428 4338280 [Ljava.util.concurrent.ConcurrentHashMap$HashEntry;
25: 29725 4042600 org.apache.camel.com.googlecode.concurrentlinkedhashmap.ConcurrentLinkedHashMap$PaddedAtomicReference
26: 21380 3617024 [I
27: 51668 3306752 java.net.URL
28: 103102 3299264 java.util.Hashtable$Entry
29: 77793 2489376 org.jboss.virtual.plugins.context.zip.EntryInfo
30: 43183 2072784 javax.management.modelmbean.ModelMBeanOperationInfo
31: 19087 1985048 java.lang.Class
32: 24062 1469224 [S
33: 89576 1433216 javax.management.modelmbean.DescriptorSupport
34: 29772 1431696 [[I
...
jmap -permstat pid
打印 Java 堆内存的永久代(方法区)的类加载器的智能统计信息。对于每个类加载器而言,它的名称、活跃度、地址、父类加载器、它所加载的类的数量和大小都会被打印。此外,包含的字符串数量和大小也会被打印。
[root@localhost jdk1.7.0_79]# jmap -permstat 24971
Attaching to process ID 24971, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 24.79-b02
finding class loader instances ..done.
computing per loader stat ..done.
please wait.. computing liveness....................................................liveness analysis may be inaccurate ...
class_loader classes bytes parent_loader alive? type
<bootstrap> 3034 18149440 null live <internal>
0x000000070a88fbb8 1 3048 null dead sun/reflect/DelegatingClassLoader@0x0000000703c50b58
0x000000070a914860 1 3064 0x0000000709035198 dead sun/reflect/DelegatingClassLoader@0x0000000703c50b58
0x000000070a9fc320 1 3056 0x0000000709035198 dead sun/reflect/DelegatingClassLoader@0x0000000703c50b58
0x000000070adcb4c8 1 3064 0x0000000709035198 dead sun/reflect/DelegatingClassLoader@0x0000000703c50b58
0x000000070a913760 1 1888 0x0000000709035198 dead sun/reflect/DelegatingClassLoader@0x0000000703c50b58
0x0000000709f3fd40 1 3032 null dead sun/reflect/DelegatingClassLoader@0x0000000703c50b58
0x000000070923ba78 1 3088 0x0000000709035260 dead sun/reflect/DelegatingClassLoader@0x0000000703c50b58
0x000000070a88fff8 1 3048 null dead sun/reflect/DelegatingClassLoader@0x0000000703c50b58
0x000000070adcbc58 1 1888 0x0000000709035198 dead sun/reflect/DelegatingClassLoader@0x0000000703c50b58
JVM调优命令-jmap - 钰火 - 博客园
https://www.cnblogs.com/myna/p/7573843.html
jmap查看内存使用情况与生成heapdump
http://www.cnblogs.com/yjd_hycf_space/p/7753847.html
docker中jmap无权限Operation not permitted
docker 镜像中使用 jdk 工具报错:
# ./jinfo 9
Attaching to process ID 9, please wait...
Error attaching to process: sun.jvm.hotspot.debugger.DebuggerException: Can't attach to the process: ptrace(PTRACE_ATTACH, ..) failed for 9: Function not implemented
sun.jvm.hotspot.debugger.DebuggerException: sun.jvm.hotspot.debugger.DebuggerException: Can't attach to the process: ptrace(PTRACE_ATTACH, ..) failed for 9: Function not implemented
at sun.jvm.hotspot.debugger.linux.LinuxDebuggerLocal$LinuxDebuggerLocalWorkerThread.execute(LinuxDebuggerLocal.java:163)
原因:
Docker 自 1.10 版本开始加入的安全特性。 jmap 这类 JDK 工具依赖于 Linux 的 PTRACE_ATTACH,而 Docker 自 1.10 版本开始,默认的 seccomp 配置文件中禁用了 ptrace
解决:
使用 –cap-add 明确添加指定功能:
docker run –cap-add=SYS_PTRACE …
Docker 中无法使用 JDK jmap之 Can’t attach to the process: ptrace(PTRACE_ATTACH问题
https://blog.csdn.net/russle/article/details/99708261
jhat
JVM Heap Analysis Tool 命令是与 jmap 搭配使用,用来分析jmap生成的dump,jhat内置了一个微型的HTTP/HTML服务器,生成dump的分析结果后,可以在浏览器中查看。在此要注意,一般不会直接在服务器上进行分析,因为jhat是一个耗时并且耗费硬件资源的过程,一般把服务器生成的dump文件复制到本地或其他机器上进行分析。
通常用法:jmap导出堆内存dump文件,然后使用jhat来分析。dump出来的文件还可以用MAT、VisualVM等工具查看。
命令格式:jhat [-stack <bool>] [-refs <bool>] [-port <port>] [-baseline <file>] [-debug <int>] [-version] [-h|-help] <file>
参数:
-J< flag >
因为 jhat 命令实际上会启动一个JVM来执行, 通过 -J 可以在启动JVM时传入一些启动参数. 例如, -J-Xmx512m 则指定运行 jhat 的Java虚拟机使用的最大堆内存为 512 MB. 如果需要使用多个JVM启动参数,则传入多个 -Jxxxxxx.-stack false|true
关闭对象分配调用栈跟踪(tracking object allocation call stack)。 如果分配位置信息在堆转储中不可用. 则必须将此标志设置为 false. 默认值为 true.-refs false|true
关闭对象引用跟踪(tracking of references to objects)。 默认值为 true. 默认情况下, 返回的指针是指向其他特定对象的对象,如反向链接或输入引用(referrers or incoming references), 会统计/计算堆中的所有对象。-port port-number
设置 jhat HTTP server 的端口号. 默认值 7000。-exclude exclude-file
指定对象查询时需要排除的数据成员列表文件(a file that lists data members that should be excluded from the reachable objects query)。 例如, 如果文件列列出了 java.lang.String.value , 那么当从某个特定对象 Object o 计算可达的对象列表时, 引用路径涉及 java.lang.String.value 的都会被排除。-baseline exclude-file
指定一个基准堆转储(baseline heap dump)。 在两个 heap dumps 中有相同 object ID 的对象会被标记为不是新的(marked as not being new). 其他对象被标记为新的(new). 在比较两个不同的堆转储时很有用。-debug int
设置 debug 级别. 0 表示不输出调试信息。 值越大则表示输出更详细的 debug 信息。-version
启动后只显示版本信息就退出。
jhat -port 7000 dump.hprof
用jmap把进程内存使用情况dump到文件中:
jmap -dump:live,format=b,file=tapi-server.hprof 105970
用jhat分析并启动一个http服务器:
[prouser@vm-vmw96712-app bin]$ ./jhat -port 7000 tapi-server.hprof
Reading from tapi-server.hprof...
Dump file created Mon Apr 09 14:24:00 CST 2018
Snapshot read, resolving...
Resolving 6003870 objects...
Chasing references, expect 1200 dots............................................................
Eliminating duplicate references..........................................................
Snapshot resolved.
Started HTTP server on port 7000
Server is ready.
在浏览器中查看 http://ip:7000/
JVM调优命令-jhat - 钰火 - 博客园
https://www.cnblogs.com/myna/p/7590620.html
jinfo
JVM Configuration info 这个命令作用是实时查看虚拟机运行参数。
命令语法:
jinfo [option] <pid> 连接到正在运行的java进程
jinfo [option] <executable> <core> 连接到core文件
jinfo [option] [server_id@]<remote server IP or hostname> 连接到远程主机
参数:
-flag:输出指定args参数的值
-flags:输出所有JVM参数的值
-sysprops:输出系统属性,等同于System.getProperties()
jinfo -flags pid 查看全部JVM参数值
# jinfo -flags 6
VM Flags:
-XX:+AlwaysPreTouch -XX:CICompilerCount=4 -XX:ConcGCThreads=2 -XX:ErrorFile=logs/hs_err_pid%p.log -XX:+ExitOnOutOfMemoryError -XX:G1ConcRefinementThreads=8 -XX:G1EagerReclaimRemSetThreshold=32 -XX:G1HeapRegionSize=4194304 -XX:G1ReservePercent=25 -XX:GCDrainStackTargetSize=64 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=data -XX:InitialHeapSize=8589934592 -XX:InitiatingHeapOccupancyPercent=30 -XX:MarkStackSize=4194304 -XX:MaxDirectMemorySize=4294967296 -XX:MaxHeapSize=8589934592 -XX:MaxNewSize=5150605312 -XX:MinHeapDeltaBytes=4194304 -XX:MinHeapSize=8589934592 -XX:NonNMethodCodeHeapSize=5839372 -XX:NonProfiledCodeHeapSize=122909434 -XX:-OmitStackTraceInFastThrow -XX:ProfiledCodeHeapSize=122909434 -XX:-RequireSharedSpaces -XX:ReservedCodeCacheSize=251658240 -XX:+SegmentedCodeCache -XX:+ShowCodeDetailsInExceptionMessages -XX:SoftMaxHeapSize=8589934592 -XX:ThreadStackSize=1024 -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseFastUnorderedTimeStamps -XX:+UseG1GC -XX:+UseSharedSpaces
如何查看Java进程的GC算法
1、jmap -heap pid 中有 gc 信息
2、jinfo -flags pid 中有 use 某种 gc 算法的标识,例如 -XX:+UseG1GC, -XX:+UseParallelGC
jinfo查看classpath
# jinfo 1|grep java.class.path
java.class.path=/root/apps/blog/blog-server.jar
java_class_path (initial): /root/apps/blog/blog-server.jar
jdb
Java调试工具(Java Debugger),主要用于对Java应用进行断点调试。
jcmd
https://docs.oracle.com/javase/8/docs/technotes/tools/unix/jcmd.html
从 jdk 1.7 开始,新增了一个命令行工具 jcmd,可以用它来导出堆、查看 Java 进程、导出线程信息、执行GC、还可以进行采样分析。
命令格式:
jcmd <pid | main class> <command ...|PerfCounter.print|-f file>
jcmd -l
jcmd -h
jcmd -l 查看jvm进程
等于 jps 命令
jcmd pid help 查看支持的命令
列出当前运行的 java 进程可以执行的操作
# jcmd 6 help
6:
The following commands are available:
JFR.stop
JFR.start
JFR.dump
JFR.check
VM.native_memory
VM.check_commercial_features
VM.unlock_commercial_features
ManagementAgent.stop
ManagementAgent.start_local
ManagementAgent.start
GC.rotate_log
Thread.print
GC.class_stats
GC.class_histogram
GC.heap_dump
GC.run_finalization
GC.run
VM.uptime
VM.flags
VM.system_properties
VM.command_line
VM.version
help
jcmd pid help CMD 查看某个命令的选项
例如查看 VM.native_memory 命令的的选项
# jcmd 6 help VM.native_memory
6:
VM.native_memory
Print native memory usage
Impact: Medium
Permission: java.lang.management.ManagementPermission(monitor)
Syntax : VM.native_memory [options]
Options: (options must be specified using the <key> or <key>=<value> syntax)
summary : [optional] request runtime to report current memory summary, which includes total reserved and committed memory, along with memory usage summary by each subsytem. (BOOLEAN, false)
detail : [optional] request runtime to report memory allocation >= 1K by each callsite. (BOOLEAN, false)
baseline : [optional] request runtime to baseline current memory usage, so it can be compared against in later time. (BOOLEAN, false)
summary.diff : [optional] request runtime to report memory summary comparison against previous baseline. (BOOLEAN, false)
detail.diff : [optional] request runtime to report memory detail comparison against previous baseline, which shows the memory allocation activities at different callsites. (BOOLEAN, false)
shutdown : [optional] request runtime to shutdown itself and free the memory used by runtime. (BOOLEAN, false)
statistics : [optional] print tracker statistics for tuning purpose. (BOOLEAN, false)
scale : [optional] Memory usage in which scale, KB, MB or GB (STRING, KB)
jcmd pid PerfCounter.print 查看性能统计
# jcmd 6 PerfCounter.print
6:
java.ci.totalTime=968635563589
java.cls.loadedClasses=31919
java.cls.sharedLoadedClasses=0
java.cls.sharedUnloadedClasses=0
java.cls.unloadedClasses=2332
...
jcmd pid GC.heap_dump
等于 jmap -dump:format=b,file=heapdump.phrof pid
# jcmd 6 GC.heap_dump d:\dump.hprof
6:
Heap dump file created
jcmd pid VM.native_memory 查看堆外内存
如果没开启 NMT,执行此命令提示如下:
# jcmd 6 VM.native_memory
6:
Native memory tracking is not enabled
开启 NMT 后结果如下:
Native Memory Tracking:
Total: reserved=6189655KB, committed=4035051KB
- Java Heap (reserved=4194304KB, committed=3274752KB)
(mmap: reserved=4194304KB, committed=3274752KB)
- Class (reserved=1179114KB, committed=146742KB)
(classes #23508)
(malloc=21994KB #32970)
(mmap: reserved=1157120KB, committed=124748KB)
- Thread (reserved=150248KB, committed=150248KB)
(thread #146)
(stack: reserved=149060KB, committed=149060KB)
(malloc=473KB #745)
(arena=714KB #291)
- Code (reserved=259568KB, committed=60476KB)
(malloc=9968KB #14269)
(mmap: reserved=249600KB, committed=50508KB)
- GC (reserved=175165KB, committed=171577KB)
(malloc=21921KB #390)
(mmap: reserved=153244KB, committed=149656KB)
- Compiler (reserved=257KB, committed=257KB)
(malloc=126KB #539)
(arena=131KB #3)
- Internal (reserved=193497KB, committed=193497KB)
(malloc=193465KB #31712)
(mmap: reserved=32KB, committed=32KB)
- Symbol (reserved=30721KB, committed=30721KB)
(malloc=27964KB #279733)
(arena=2757KB #1)
- Native Memory Tracking (reserved=5891KB, committed=5891KB)
(malloc=204KB #3166)
(tracking overhead=5687KB)
- Arena Chunk (reserved=891KB, committed=891KB)
(malloc=891KB)
JVM堆外内存跟踪(NMT)
Java Platform, Standard Edition Troubleshooting Guide
2.7 Native Memory Tracking
https://docs.oracle.com/javase/8/docs/technotes/guides/troubleshoot/tooldescr007.html
堆外内存跟踪 NativeMemoryTracking(NMT) 是 Hotspot VM 用来分析 VM 内部内存使用情况的一个功能。我们可以利用 jcmd(jdk自带)这个工具来访问 NMT 的数据。
NMT 必须先通过 VM 启动参数中打开,不过要注意的是,打开 NMT 会带来 5%-10% 的性能损耗-XX:NativeMemoryTracking=[off | summary | detail]off 默认关闭summary 只统计各个分类的内存使用情况.detail Collect memory usage by individual call sites.
上一篇 2018年运动记录
下一篇 面试准备03-Java线程和并发
页面信息
location:protocol: host: hostname: origin: pathname: href: document:referrer: navigator:platform: userAgent: