面试准备08-Web与系统架构
Java面试准备之Web框架
web
Servlet
此部分内容见笔记 Java-Servlet
HTTPS/SSL/TLS
见笔记 面试准备12-计算机基础 中的 HTTPS/SSL/TLS
浏览器输入地址到页面显示经过的过程?
WEB请求处理三:Servlet容器请求处理
https://www.jianshu.com/p/571c474279af
RASP
OpenRASP(Runtime Application Self-Protection) 抛弃了传统防火墙依赖请求特征检测攻击的模式,创造性的使用RASP技术(应用运行时自我保护),直接注入到被保护应用的服务中提供函数级别的实时防护,可以在不更新策略以及不升级被保护应用代码的情况下检测/防护未知漏洞,尤其适合大量使用开源组件的互联网应用以及使用第三方集成商开发的金融类应用。
RASP 是一种新型应用安全防护技术。这种技术直接将防护引擎嵌入到应用内部,能够感知应用上下文。传统的防护设备,WAF、IDS等等,均是对HTTP请求进行分析和处理,并结合请求特征库进行匹配,能做的事情比较有限。
举个例子,当发生SQL注入攻击时,WAF和IDS只能看到HTTP请求。而RASP技术不但能看到完整的SQL语句,还可以和当前的HTTP请求进行关联,并结合语义引擎、用户输入识别等能力,实现对SQL注入的检测。
百度开源 OpenRASP
https://rasp.baidu.com/doc/
OpenRASP 最佳实践
https://rasp.baidu.com/download/OpenRASP%20Internals.pdf
WAF
WAF(Web Application Firewall),专为了对 WEB 网站和基于 WEB 的服务器提供全方位防护而设计的,以反向代理的方式部署在边界处。可检测和防御 Web/HTTP/XML 应用攻击、SQL注射、劫持会话、跨站脚本(XSS)、篡改表格字段、已知BUG、“零日”漏洞利用、缓冲器溢出、cookie布毒、拒绝服务、恶意机器人、参数篡改、强制登陆、恶意编码、目录游走等。
spring和shiro对url路径中分号的处理差异
用户拥有 /a/b 权限,无 /a/b/c 权限。
用户输入 /a/b;/c
spring 中路径变为 /a/b
shiro 验证通过
shiro 中路径变为 /a/b/c
实际访问了 /a/b/c
JSONP JSON Hijacking
JSONP 全称是 JSON with Padding ,是基于 JSON 格式的为解决跨域请求资源而产生的解决方案。他实现的基本原理是利用了 HTML 里 <script></script> 元素标签,远程调用 JSON 文件来实现数据传递。
XSS 跨站脚本攻击
xss 跨站脚本攻击(Cross Site Scripting)
XSS 就是利用网页的漏洞,让网页执行自己的js脚本,来达到一些目的。
例1,页面代码如下,之前嵌入用户输入的内容
<body>
$userInput
</body>
用户输入 <script>alert('hack')</script> 发生 xss 攻击
例2,如果下面的 api 直接跳转到 query 参数 url,用户可能构造一个 js 脚本传入,比如 javascript:console.log(document.cookie),导致 xss 攻击。
http://xxx.apis.com/v1/xx?url=http://another.api.com
前端安全系列(一):如何防止XSS攻击?
https://tech.meituan.com/2018/09/27/fe-security.html
CSRF 跨站请求伪造
CSRF(Cross-site request forgery)跨站请求伪造:攻击者诱导受害者进入第三方网站,在第三方网站中,向被攻击网站发送跨站请求。利用受害者在被攻击网站已经获取的注册凭证,绕过后台的用户验证,达到冒充用户对被攻击的网站执行某项操作的目的。
一个典型的 CSRF 攻击有着如下的流程:
1、受害者登录a.com,并保留了登录凭证(Cookie/jwt-token)。
2、攻击者引诱受害者访问了b.com。
3、b.com 向 a.com 发送了一个请求:a.com/act=xx。浏览器会默认携带a.com的Cookie等认证信息。
4、a.com接收到请求后,对请求进行验证,并确认是受害者的凭证,误以为是受害者自己发送的请求。
5、a.com以受害者的名义执行了act=xx。
攻击完成,攻击者在受害者不知情的情况下,冒充受害者,让a.com执行了自己定义的操作。
前端安全系列(二):如何防止CSRF攻击?
https://tech.meituan.com/2018/10/11/fe-security-csrf.html
移花接木:针对OAuth2的CSRF攻击
https://www.jianshu.com/p/c7c8f51713b6
SSRF 服务端请求伪造
SSRF(Server-Side Request Forgery) 服务端请求伪造,指的是攻击者在未能取得服务器所有权限时,利用服务器漏洞以服务器的身份发送一条构造好的请求给服务器所在内网。
SSRF攻击通常针对外部网络无法直接访问的内部系统
服务器端请求伪造(Server-Side Request Forgery,SSRF) 是一种由攻击者构造形成由服务端发起请求的一个安全漏洞。一般情况下,SSRF 攻击的目标是从外网无法访问的内部系统。SSRF 形成的原因大都是由于服务端提供了从其他服务器应用获取数据的功能且没有对目标地址做过滤与限制,比如从指定URL地址获取网页文本内容、加载指定地址的图片、下载等。
例1,如果下面接口功能资源抓取,用户可能传入一个外网无法访问的内网ip,从而获取内网资源,造成 SSRF 攻击
http://xxx.apis.com/v1/xx?url=http://another.api.com
例2,我曾经写过一个 /linkTest?url=xxx 测试 url 连通性的接口,被扫描出 SSRF 漏洞,因为参数 url 可能传入一个外部无法访问的内网 url,只要服务端向这个 url 发起了请求,无论是否返回请求结果给外部用户,都是 SSRF 漏洞
处理
1、对 url 参数的 host 做验证,判断是否内网 ip,阻断内网 ip 访问,或者白名单过滤后阻断内网访问。
2、检查 url 的协议,只允许 HTTP 和 HTTPS 协议,避免 file://、gopher://、ftp:// 等协议引发的高危风险
3、有条件的可自己封装 SafeURL sdk 做验证。
正向代理和反向代理的区别?
正向代理代理的对象是客户端,它隐藏了真实的请求客户端,服务端不知道真实的客户端是谁,客户端请求的服务都被代理服务器代替来请求,某些科学上网工具扮演的就是典型的正向代理角色。
反向代理代理的对象是服务端,它隐藏了真实的服务端,客户端不知道真实的服务器是哪个,也不需要知道,你只需要知道反向代理服务器是谁就好了,反向代理经常用来做负载均衡转发器。
正向代理就是你本来就知道会从哪台服务器上获得内容,反向代理与之相反。
正向代理和反向代理的区别
虽然正向代理服务器和反向代理服务器所处的位置都是客户端和真实服务器之间,所做的事情也都是把客户端的请求转发给服务器,再把服务器的响应转发给客户端,但是二者之间还是有一定的差异的。
1、正向代理其实是客户端的代理,帮助客户端访问其无法访问的服务器资源。反向代理则是服务器的代理,帮助服务器做负载均衡,安全防护等。
2、正向代理一般是客户端架设的,比如在自己的机器上安装一个代理软件。而反向代理一般是服务器架设的,比如在自己的机器集群中部署一个反向代理服务器。
3、正向代理中,服务器不知道真正的客户端到底是谁,以为访问自己的就是真实的客户端。而在反向代理中,客户端不知道真正的服务器是谁,以为自己访问的就是真实的服务器。
4、正向代理和反向代理的作用和目的不同。正向代理主要是用来解决访问限制问题。而反向代理则是提供负载均衡、安全防护等作用。二者均能提高访问速度。
漫话:如何给女朋友解释什么是反向代理?
https://mp.weixin.qq.com/s/T7vd5heXXUjnbV-1wHg8xg
get和post的区别
表象区别
HTTP 中 GET 与 POST 的区别
GET 参数通过 URL 传递,POST 放在 Request body 中。
GET 请求在 URL 中传送的参数是有长度限制的,而 POST 没有限制。
GET 在浏览器回退时是无害的,而 POST 会再次提交请求。
GET 产生的 URL 地址可以被 Bookmark,而 POST 不可以。
GET 请求会被浏览器主动 cache,而 POST 不会,除非手动设置。
GET 请求只能进行 URL 编码,而 POST 支持多种编码方式。
GET 请求参数会被完整保留在浏览器历史记录里,而 POST 中的参数不会被保留。
对参数的数据类型,GET 只接受 ASCII 字符,而 POST 没有限制。
GET 比 POST 更不安全,因为参数直接暴露在 URL 上,所以不能用来传递敏感信息。
(1)get一般用于从服务器上获取数据,post一般用于向服务器传送数据
(2)请求的时候参数的位置有区别,get的参数是拼接在url后面,用户在浏览器地址栏可以看到。post是放在http包的包体中。
比如说用户注册,你不能把用户提交的注册信息用get的方式吧,那不是说把用户的注册信息都显示在Url上了吗,是不安全的。
(3)能提交的数据有区别,get方式能提交的数据只能是文本,且大小不超过1024个字节,而post不仅可以提交文本还有二进制文件。
所以说想上传文件的话,那我们就需要使用post请求方式
(4)servlet在处理请求的时候分别对应使用doGet和doPost方式进行处理请求
GET是通过URL提交数据,因此GET可提交的数据量就跟URL所能达到的最大长度有直接关系。
HTTP协议没有对POST进行任何限制,一般是受服务器配置限制或者内存大小。
POST相对『安全』
这里是说相对『安全』,url中会附带GET请求的一些参数,而POST的在url中则看不到。
注:抓包都能看见,都是明文传输
GET是通过URL方式请求,可以直接看到,明文传输。
POST是通过请求header请求,可以开发者工具或者抓包可以看到,同样也是明文的。
GET是幂等的,POST非幂等
一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。
这里就是就是说每次GET得到的数据是不变的。
Servlet面试题归纳
https://www.cnblogs.com/xiaohouzai/p/7740171.html
GET和POST的区别
https://www.cnblogs.com/wswang/p/6054619.html
无本质区别
GET 和 POST 本质上没有区别
GET 和 POST 都是 HTTP 协议中的发送请求的方法, HTTP 协议基于 TCP/IP 协议,所以 GET 和 POST 本质上都是 TCP 连接上的 TCP 数据包。GET/POST/PUT/DELETE 等各种 HTTP 的方法都是封装在一个 TCP 包中(过长会拆包),并无差别,GET 和 POST 能做的事情是一样一样的。你要给 GET 加上 request body,给 POST 带上 url 参数,技术上是完全行的通的。
GET 用于查询和 POST 用于写入只是语义上的约束,完全可以不按约束来做。
99%的人都理解错了HTTP中GET与POST的区别
http://www.techweb.com.cn/network/system/2016-10-11/2407736.shtml
cookie与session
参见笔记 HTTP
HTTP 状态码
参见笔记 HTTP
Apache和Nginx对比
Apache创建于1995年,并从 1999 年开始在 Apache 软件基金会旗下进行开发。Apache灵活、高效,拥有丰富的扩展模块,以及活跃的社区支持,成为目前世界上最为主流的开源免费的Web服务器软件。
Nginx是由俄罗斯软件工程师Igor Sysoev编写的免费开源Web服务器。自从2004年上市以来,nginx专注于高性能,高并发性和低内存使用。并且其在负载均衡,缓存,访问和带宽控制以及与各种应用程序高效集成等方面的特性,都使得它逐步深受广大用户青睐。
Apache有三种工作模块,分别为prefork、worker、event。
prefork:多进程,每个请求用一个进程响应,这个过程会用到select机制来通知。
worker:多线程,一个进程可以生成多个线程,每个线程响应一个请求,但通知机制还是select不过可以接受更多的请求。
event:基于异步I/O模型,一个进程或线程,每个进程或线程响应多个用户请求,它是基于事件驱动(也就是epoll机制)实现的。
Nginx会按需同时运行多个进程:一个主进程(master)和几个工作进程(worker),配置了缓存时还会有缓存加载器进程(cache loader)和缓存管理器进程(cache manager)等。所有进程均是仅含有一个线程,并主要通过“共享内存”的机制实现进程间通信。主进程以root用户身份运行,而worker、 cache loader和cache manager均应以非特权用户身份运行。
相同点:
虽然Apache和Nginx各自的背景不同,但他们的作用目的是一致的,简单说就是接收用户请求,然后处理请求,最后将处理结果返回给用户。
区别:
1、进程模型。
apache是同步多进程模型,一个连接对应一个进程;nginx是异步的,多个连接(万级别)可以对应一个进程。
2、IO模型。
两者性能差别的主要原因在于网络IO模型选择不同,apache使用了select,而nginx使用了epoll模型!
3、静态与动态内容的处理。
nginx的优势是处理静态请求,apache适合处理动态请求,所以现在一般前端用nginx作为反向代理抗住压力,apache作为后端处理动态请求。
4、Nginx轻量级,配置简洁,支持热配,占用资源少,性能高,支持高并发。
Apache 配置复杂,组件丰富,bug少,更稳定。
5、php支持
Apache 对 PHP 支持比较简单,Nginx 需要配合其他后端来使用。
Nginx为什么比Apache Httpd高效:原理篇
http://www.mamicode.com/info-detail-1156329.html
Nginx 和 Apache 各有什么优缺点?
https://www.zhihu.com/question/19571087
select和epoll的区别(为什么Nginx性能高)
Kubernetes/k8s
见笔记 Kubernetes
k8s中如何做服务发现?
k8s的健康检查?
k8s的负载均衡?
系统设计
设计图
如何画好系统架构图
一种比较流行的是4+1视图,分别为场景视图、逻辑视图、物理视图、处理流程视图和开发视图。
场景视图
场景视图用于描述系统的参与者与功能用例间的关系,反映系统的最终需求和交互设计,通常由用例图表示。
如何画好架构图 - 程序猿DD
https://blog.csdn.net/j3T9Z7H/article/details/88265899
用于软件架构的 C4 模型
https://www.infoq.cn/article/C4-architecture-model/
时序图
时序图(Sequence Diagram),又名序列图、循序图,是一种UML交互图。它通过描述对象之间发送消息的时间顺序显示多个对象之间的动态协作。
有时候业务的流程会比较复杂,涉及到多种角色,这时就可以使用时序图来梳理这个业务逻辑。这样会使业务看起来非常清晰,代码写起来也是水到渠成的事情了。
时序图时会涉及下面7种元素:
1、角色(Actor)
系统角色,可以是人或者其他系统和子系统。以一个小人图标表示。
2、对象(Object)
对象位于时序图的顶部,以一个矩形表示。每个对象表示系统的一个子模块。
3、生命线(LifeLine)
时序图中每个对象和底部中心都有一条垂直的虚线,这就是对象的生命线(对象的时间线)。以一条垂直的虚线表。
4、控制焦点/激活(Activation)
控制焦点代表时序图中在对象时间线上某段时期执行的操作。以一个很窄的矩形表示。
5、消息(Message)
表示对象之间发送的信息。消息分为三种类型。
(1)同步消息(Synchronous Message)
消息的发送者把控制传递给消息的接收者,然后停止活动,等待消息的接收者放弃或者返回控制。用来表示同步的意义。以一条实线和实心箭头表示。
(2)异步消息(Asynchronous Message)
消息发送者通过消息把信号传递给消息的接收者,然后继续自己的活动,不等待接受者返回消息或者控制。异步消息的接收者和发送者是并发工作的。以一条实线和大于号表示。
(3)返回消息(Return Message)
返回消息表示从过程调用返回。以小于号和虚线表示。
6、自关联消息
表示方法的自身调用或者一个对象内的一个方法调用另外一个方法。以一个半闭合的长方形+下方实心剪头表示。
组合片段。
https://www.woshipm.com/ucd/607593.html
https://www.zhihu.com/question/418850957
如何设计实现资源池
资源池化的好处
资源池化需要考虑的因素?
commons-pool实现原理
资源池化相关内容参考笔记 Apache-Commons-Pool
红包系统设计
优惠券系统设计
标签系统设计
设计一个标签系统需要考虑什么?(火花思维二面)
1、标签分组,层级
2、系统间数据共享和隔离
共享数据:不同系统给同一个用户打的标签可互相看到
隔离:不同系统给同一用户打的标签互相看不到,同一标签可以是不同数据
3、并发控制
(1)建标签的并发控制,同一系统不能创建相同的标签
(2)打标签的并发控制,同一系统给同一用户的同一标签的值要唯一
角色权限管理系统设计(RBAC)
实体:
role 角色实体
privilege 权限实体
user 用户实体
user_group 用户组实体
user -> role 用户和其对应角色的关系
role -> privilege 角色和权限之前的关系
权限是分给角色的,然后再给用户分配角色
一个 user 可能对应多个 role
一个 role 可以对应多个 privilege
假如用户很多,挨个给每个用户分配角色也很麻烦,可以引入用户组的概念,一个部门的是一个用户组,给用户组指定role,用户组下的所有人都具有了这个role
RBAC(Role-Based Access Control)意思是基于角色的权限控制
如何区分功能权限和数据权限
组织 - 决定数据权限
角色 - 决定功能权限
用户 - 通过组织+角色给用户赋权,一个可属于多个角色,但只归属唯一的组织
灵活性:也可以单独给用户授权额外权限
一文带你入门权限管理系统设计
https://zhuanlan.zhihu.com/p/66340816
好友粉丝关注系统设计
主要包含 3 个字段的关系表
user1_id, user2_id, relation
relation
0 无关系
1 关注
2 被关注
3 好友
关系采用双向存储,假如 user1 关注 user2 ,则在表中插入 2 条数据
(user1, user2, 1) 表示 user1 和 user2 的关系是 1 关注
(user2, user1, 1) 表示 user2 和 user1 的关系是 2 被关注
假如之后 user2 又关注了 user1,则修改这两行数据,改为
(user1, user2, 3) 表示 user1 和 user2 的关系是 3 好友
(user2, user1, 3) 表示 user2 和 user1 的关系是 3 好友
关系的数据量可能是用户数量级的平方,以后如果要做分库分表,如何做?
按 user1_id 做分表字段
1、假如查 user1 的关系列表,直接可定位的具体的分表上
2、假如查 user1 和 user2 之间的关系,可以直接在 user1 关系所在的分表上查(当然也可以在user2的分表上查)
3、这样分表的问题是,每次写入一条数据,假如 user1 和 user2 在不同分表上,需要同时插入 (user1, user2, relation1), (user2, user1, relation2) 这两行数据位于不同的分表上,需要让两个分表上的写入在同一个事务中。
微信聊天系统设计
朋友圈系统设计
我理解朋友圈主要是一个观察者模式,包括观察者向被观察者注册、发布后的通知。
存储上需要的表结构
1、内容表,一条记录表示一条朋友圈,uid指明用户id,utf8mb4格式可以存储emoji表情
-- 内容表
CREATE TABLE `t_friend_circle_message` (
`id` bigint(15) NOT NULL AUTO_INCREMENT COMMENT '主键',
`uid` bigint(15) DEFAULT NULL COMMENT '用户id',
`content` varchar(500) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`picture` varchar(200) CHARACTER SET utf8 COLLATE utf8_unicode_ci DEFAULT '' COMMENT '图片',
`location` varbinary(100) DEFAULT '' COMMENT '位置',
-- `like_count` int(10) DEFAULT '0' COMMENT '点赞数', -- 放到redis中
`create_time` datetime DEFAULT NULL COMMENT '创建日期',
PRIMARY KEY (`id`)
);
2、时间线表,是个关系表,把用户 uid 和 内容 fcmid 关联起来。其实没有这个表也可以,只不过需要每次查询时二次筛选。
-- 时间轴表
CREATE TABLE `t_friend_circle_timeline` (
`id` bigint(15) NOT NULL AUTO_INCREMENT,
`uid` bigint(15) DEFAULT NULL COMMENT '用户id',
`fcmid` bigint(15) DEFAULT NULL COMMENT '朋友圈信息id',
`is_own` int(1) DEFAULT '0' COMMENT '是否是自己的',
`create_time` datetime DEFAULT NULL COMMENT '创建日期',
PRIMARY KEY (`id`)
);
3、评论表,uid表示哪个用户发的评论,fcmid表示在哪条朋友圈下发的
-- 评论表
CREATE TABLE `t_friend_circle_comment` (
`id` bigint(15) NOT NULL AUTO_INCREMENT,
`fcmid` bigint(15) DEFAULT NULL COMMENT '朋友圈信息id',
`uid` bigint(15) DEFAULT NULL COMMENT '用户id',
`content` varchar(500) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`create_time` datetime DEFAULT NULL COMMENT '创建日期',
PRIMARY KEY (`id`)
)
4、发朋友圈的处理逻辑:
- 用户A在朋友圈中发布一条消息,消息表 t_friend_circle_message 写入一条数据。
- 时间轴表 t_friend_circle_timeline 中增加一条数据,uid设置A,is_own设置为1,表示在A的时间轴中增加一条自己发布的消息。
- 遍历监听了用户 A 朋友圈的所有 uid 列表(涉及到朋友圈权限检查),依次处理,假设当前用户为 B
时间轴表 t_friend_circle_timeline 中增加一条数据,uid设置B,is_own设置为0,表示在B的时间轴中增加一条好友发布的消息。
5、添加好友的处理逻辑:
当用户 A,添加用户 C 为好友之后,需要触发同步好友时间轴的操作:
如果 C 允许 A 看他的朋友圈,且 A 选择看 C 的朋友圈,则从消息表 t_friend_circle_message 中查询好友 C 发布的 在允许世界范围内(3天、一星期、3个月)的消息插入到用户 A 的时间轴中。
同样逻辑同步 A 的朋友圈插入到 C 的时间轴中。
redis实现点赞功能
需要用一个 list 存储点赞的用户id,注意到点赞列表是有序的,能区分出谁第一个点赞,可以用 redis 的列表 list 来存储, list 的长度就是点赞数
1、点赞rpush likes_朋友圈id 点赞用户id
例如
uid 是 1 的用户给 id 为 123 的朋友圈点赞rpush likes_123 1
2、查询 id 为 123 的朋友圈的点赞个数llen likes_123
3、查询 id 为 123 的朋友圈的点赞列表lrange likes_123 0 -1
-1 表示最后一个元素
返回的 list 是按点赞先后顺序排列的
4、取消点赞lrem likes_朋友圈id 0 点赞用户id
例如
uid 是 1 的用户取消给 id 为 123 的朋友圈点赞lrem likes_123 0 1
第三个0表示删除list中的所有1
高并发/高可用/分布式系统
SLI/SLO/SLA
SLI(service level indicator):服务等级对象
指的是对象,例如:qps,响应时间,准确性等
SLO(service level objective):服务等级目标
指的是目标,例如:qps 99.99% ,响应时间10ms等
SLA (service level agreement):服务等级协议
指的是整个协议,包含SLI和SLO,并重点描述如果达不成目标,要如何赔偿
99.999% 服务可用性达到 5 个 9
1年 = 365天 = 8760小时
99.9 = 8760 * 0.1% = 8760 * 0.001 = 8.76小时
99.99 = 8760 * 0.0001 = 0.876小时 = 0.876 * 60 = 52.6分钟
99.999 = 8760 * 0.00001 = 0.0876小时 = 0.0876 * 60 = 5.26分钟
全年停机不超过 5.26 分钟才能做到 99.999%, 即 5 个 9
缓存/限流/降级
在开发高并发系统时有三把利器用来保护系统:缓存、降级和限流。
缓存的目的是提升系统访问速度和增大系统能处理的容量,可谓是抗高并发流量的银弹;
而降级是当服务出问题或者影响到核心流程的性能则需要暂时屏蔽掉,待高峰或者问题解决后再打开
如何设计一个高性能、高可用的服务架构?
翻墙看
https://www.hiredintech.com/classrooms/system-design/lesson/60
水平扩展和垂直扩展
服务器性能不足?集群:水平、垂直扩展
水平扩展:加服务器多server负载均衡,有相同的全部内容
垂直扩展:按业务、服务分离,不同服务器上有不同服务
jboss集群配置
jboss session复制配置
如果jboss cluster是使用mod_cluster实现的话,直接在app的web.xml中加一行 <distributable /> 即可
否则需要:
1、配置jboss-service.xml,指定协议比如tcp,填入其他jboss节点的ip和端口
2、在app的web.xml中加一行 <distributable />
3、在jboss-web.xml中增加以下内容:
<jboss-web>
<replication-config>
<replication-trigger>SET_AND_NON_PRIMITIVE_GET</replication-trigger>
<replication-granularity>SESSION</replication-granularity>
<replication-field-batch-mode>
Jboss集群的session复制
https://blog.csdn.net/liuyifeng_510/article/details/7032330
jboss eap 6.3 集群(cluster)-Session 复制(Replication)
https://www.cnblogs.com/yjmyzz/p/3979113.html
负载均衡
负载均衡分为硬件负载均衡及软件负载均衡。
硬件负载均衡,顾名思义,在服务器节点之间安装专门的硬件进行负载均衡的工作,F5便为其中的佼佼者。
软件负载均衡则是通过在服务器上安装的特定的负载均衡软件或是自带负载均衡模块完成对请求的分配派发。
硬件负载均衡:F5负载均衡器,昂贵
DNS级做负载均衡,多个请求到达DNS,返回不同的数据中心load balancer的ip,一般一个用户会固定一个ip一段时间,一旦此ip所在数据中心down,会在几分钟内重新dns解析到另外的ip
httpd负载均衡
web应用负载均衡策略
http://blog.csdn.net/flyhawk_xjtu/article/details/50780208
常用负载均衡策略?
分布式系统之常见的负载均衡策略
https://baijiahao.baidu.com/s?id=1576397515627443922&wfr=spider&for=pc
几种软负载均衡策略分析
http://blog.csdn.net/erlib/article/details/50994209
随机
采用随机算法进行负载均衡,通常在对等集群组网中,随机路由算法消息分发还是比较均匀的,但是存在两个主要缺点:
在一个截面上碰撞的概率较高
非对等集群组网,或者硬件配置差异较大,会导致各节点负载不均匀
按请求次数轮询(加权轮询)
轮询,按公约后的权重设置轮询比率,到达边界之后,继续绕接。他的主要缺点是存在慢的提供者累积请求问题。比如第二台机器很慢,但是没挂,当请求调到第二台时就卡在那,久而久之,所以请求都卡在调到第二台上。
轮询策略的实现非常简单,他的原理就是按照权重,顺序循环遍历服务提供者列表,到达上限后重新归零,继续顺序循环。
其缺点也非常明显,该策略将节点视为等同,与实际中复杂的环境不符。加权轮询为轮询的一个改进策略,每个节点会有权重属性,但是因为权重的设置难以做到随实际情况变化,仍有一定的不足。
最小响应时间
消费者缓存所有服务提供者的服务调用时延,周期性的计算服务调用平均时延,然后计算每个服务提供者服务调用时延与平均时延的差值,根据差值的大小动态调整权重,保证服务时延大的服务提供者接收更少的消息,防止消息堆积。
该策略的特点就是要保证处理能力强的服务提供者接收到更多的消息,通过动态自动调整权重消除服务调用时延的震荡范围,使所有服务提供者服务调用时延接近平均值,实现负载均衡。
该策略能较好地反应服务器的状态,但是由于是平均响应时间的关系,时间上有些滞后,无法满足快速响应的要求。因此在此基础之上,会有一些改进版本的策略,如只计算最近若干次的平均时间的策略等。
按流量均衡
lbmethod=bytraffic 按照流量均衡
指定lbmethod为bytraffic按流量均衡,并且配置比例3:1,则A负载的请求和响应的字节数是B的3倍
负载均衡带来的回话保持问题(session同步)
负载均衡带来一个问题:来自相同客户端的请求,可能被转发给不同的后台服务器上处理。如果服务器之间没有会话信息的同步机制,会导致其他服务器无法识别用户身份,造成用户在和应用系统发生交互时出现异常。比如,客户端输入了正确的用户名和口令,但却反复跳到登录页面。客户端放入购物篮的物品丢失。
sticky粘着session(在负载均衡器上配)
方式一、粘着session(sticky session)
使用粘着session后,来自同一IP的请求将被发送到同一个Jboss节点,从而保证session使用的连续性。
粘性session的好处在不会在不同的tomcat上来回跳动处理请求,但是坏处是如果处理该session的tomcat崩溃,那么之后的请求将由其他tomcat处理,原有session失效而重新新建一个新的session,这样如果继续从session取值,会抛出nullpointer的访问异常。
粘着session会影响负载均衡,导致后端负载不平均,而且一旦某个应用服务器挂掉,上面的session全部失效,所以较少使用。
有硬伤,所以基本可以不考虑这种方法。
session复制(在应用服务器上配)
方式二、session复制
如果不采用stickysession(粘性session),那么我们可以采用tomcat的session复制使所有节点tomcat的会话相同,tomcat使用组播技术,只要集群中一个tomcat节点的session发生改变,会广播通知所有tomcat节点发生改变。
Jboss的实现原理是使用拦截器(interceptor),根据用户的同步策略拦截request,做同步处理后再交给server产生响应。
好处是如果其中一个访问出错,则另外tomcat仍然具有有效的session内容,从而能正常接管其session。坏处是当tomcat实例很多,或者用户在session中有大量操作时,组播发送的信息量十分惊人。
session复制配置则是在发布的web应用程序中的web.xml中添加
第三方缓存session(memcached/redis)
方式三、通过第三方缓存来存放sessiono数据
为了解决大量session复制导致的性能瓶颈。于是人们想到了别外一种解决策略:通过第三方缓存来存放sessiono数据,如果某一结点失效,被委任接替失效结点的服务器可以从缓存中恢复session.基于这种思想,在google code上有一款开源产品:memcached-session-manager。
将session从系统中独立出来
目前主流做法是利用redis作为session管理的实现,因为redis访问极其快速。
负载均衡常见问题之会话保持-粘滞会话(Sticky Sessions),stickysessions
http://blog.csdn.net/tomcat_baby/article/details/52787679
mod_cluster负载均衡配置
mod_cluster是jboss的一个开源集群模块(基于httpd 2.2.x,也就是httpd2的一个模块),主要功能包括:自动发现集群主机并注册主机;为集群提供负载均衡能力
mod_cluster作为Apache的插件模块负责连接Apache和JBoss,根据负载均衡策略分发和请求给后台JBoss,所以我们可以将Apache httpd 加mod_cluster作为负载均衡器。
mod_cluster提供两种代理发现方法:
通过proxyList参数手动配置代理服务器列表
通过Advertise广播自动发现代理服务器
keepalived+LVS+Apache实现负载均衡器的高可用
整合apache+tomcat+keepalived实现高可用tomcat集群
https://www.cnblogs.com/Eivll0m/archive/2014/05/20/3734128.html
centos部署lvs+keepalived+apache/tomcat实现高性能高可用负载均衡
https://blog.csdn.net/nuli888/article/details/51912123
keepalived+LVS+apache双机搭建高可用负载均衡web服务
https://blog.csdn.net/softn/article/details/52141765
keepalived 的安装与apache停止或宕机配置
http://blog.51cto.com/2856499/1425838
CentOS 6.3下HAProxy+Keepalived+Apache配置笔记
https://www.linuxidc.com/Linux/2013-06/85598.htm
keepalived提供一个虚拟IP(Virtual IP),通过虚拟IP即可访问服务,不用管http服务器的真实ip
这里说的keepalived不是apache或者tomcat等某个组件上的属性字段,它也是一个组件,可以实现web服务器的高可用(HA high availably)。它可以检测web服务器的工作状态,如果该服务器出现故障被检测到,将其剔除服务器群中,直至正常工作后,keepalive会自动检测到并加入到服务器群里面。实现主备服务器发生故障时ip瞬时无缝交接。它是LVS集群节点健康检测的一个用户空间守护进程,也是LVS的引导故障转移模块(director failover)。Keepalived守护进程可以检查LVS池的状态。如果LVS服务器池当中的某一个服务器宕机了。keepalived会通过一 个setsockopt呼叫通知内核将这个节点从LVS拓扑图中移除。
Keepalived详解:https://my.oschina.net/piorcn/blog/404644
LVS(Linux Virtual Server)的简写,意即Linux虚拟服务器,这是一个由章文嵩博士发起的一个开源项目,它的官方网站是 http://www.linuxvirtualserver.org 现在 LVS 已经是 Linux 内核标准的一部分。使用 LVS 可以达到的技术目标是:通过 LVS 达到的负载均衡技术和 Linux 操作系统实现一个高性能高可用的 Linux 服务器集群,它具有良好的可靠性、可扩展性和可操作性。从而以低廉的成本实现最优的性能。LVS 是一个实现负载均衡集群的开源软件项目
对可用性要求越高,负载均衡的起点就要越接近用户. 我们在设置域名解析的时候,应该都注意过至少要设置两个dns服务器,这就是最基本的失效保障, 也就是说从此处开始,就已经可以做负载均衡了. 一个dns可以根据解析算法实现dns到ip(可以是应用服务器集群,也可以是负载均衡集群)的负载均衡. 每个阶段如何部署和规划, 都依赖于实际的要求了, 原则上应该选择成本最低收益最高的方案.
apache负载均衡问题
https://www.oschina.net/question/2318863_225980
主从热备+负载均衡(LVS + keepalived)
http://www.cnblogs.com/youzhibing/p/5021224.html
nginx实现请求的负载均衡 + keepalived实现nginx的高可用
http://www.cnblogs.com/youzhibing/p/7327342.html
硬件LB与软件LB
负载均衡实现方法有两种:硬件实现和软件实现
硬件比较常见的有:
F5 Big-IP
Citrix Netscaler
软件比较常见的有:
LVS(Linux Virtual Server)
HAProxy
Nginx
LVS 和 Keepalived 的原理介绍和配置实践
https://wsgzao.github.io/post/lvs-keepalived/
LB逐层演进
一、DNS
开始,只有一台web-server
加server后,配置DNS,轮询转发。
二、Nginx + DNS
DNS + Nginx 负载均衡,根据业务场景区分转发
DNS + Nginx keepalived 集群,保证Nginx高可用
三、LVS + Nginx + DNS
日活亿级用户的服务器架构要怎么搭?
https://mp.weixin.qq.com/s/3HKnF9dUw1URk8i2xcZHmg
基于nginx的preread实现七层负载均衡
常见的四层负载均衡策略是根据连接来源 IP 进行一致性 Hash,在节点数不变的情况下这样能保证每次都 Hash 到同一个 Broker 中,甚至在节点数稍微改变时也能大概率找到之前连接的节点。
之前我们也使用过来源 IP Hash 的策略,主要有两个缺点:
- 分布不够均匀,部分来源 IP 是大型局域网 NAT 出口,上面的连接数多,导致 Broker 上连接数不均衡
- 不能准确标识客户端,当移动客户端掉线切换网络就可能无法连接回刚才的 Broker 了
所以我们考虑七层的负载均衡,根据客户端的唯一标识来进行一致性 Hash,这样随机性更好,同时也能保证在网络切换后也能正确路由。常规的方法是需要完整解析通讯协议,然后按协议的包进行转发,这样实现的成本很高,而且增加了协议解析出错的风险。
最后我们选择利用 Nginx 的 preread 机制实现七层负载均衡,对后面长连接 Broker 的实现的侵入性小,而且接入层的资源开销也小。
Nginx 在接受连接时可以指定预读取连接的数据到 preread buffer 中,我们通过解析 preread buffer 中的客户端发送的第一个报文提取客户端标识,再使用这个客户端标识进行一致性 Hash 就拿到了固定的 Broker。
知乎千万级高性能长连接网关是如何搭建的
https://mp.weixin.qq.com/s/34nM-4d04yZZTQKiAGeEig
高可用HA
高可用集群(High Availability Cluster,简称HA Cluster),是指以减少服务中断时间为目的的服务器集群技术。
高可用集群主要实现自动侦测(Auto-Detect)故障、自动切换/故障转移(FailOver)和自动恢复(FailBack)。
简单来说就是,用高可用集群软件实现故障检查和故障转移(故障/备份主机切换)的自动化,当然像负载均衡、DNS分发也可提供高可性。
服务降级
什么是服务降级?
当服务器压力剧增的情况下,根据实际业务情况及流量,对一些服务和页面有策略的不处理或换种简单的方式处理,从而释放服务器资源以保证核心交易正常运作或高效运作。
使用场景
服务降级主要用于什么场景呢?当整个微服务架构整体的负载超出了预设的上限阈值或即将到来的流量预计将会超过预设的阈值时,为了保证重要或基本的服务能正常运行,我们可以将一些 不重要 或 不紧急 的服务或任务进行服务的 延迟使用 或 暂停使用。
什么时候降级?
手动配置
我们可以设置一个分布式开关,用于实现服务的降级,然后集中式管理开关配置信息即可。
自动降级(超时/失败/限流)
超时降级 —— 主要配置好超时时间和超时重试次数和机制,并使用异步机制探测恢复情况
失败次数降级 —— 主要是一些不稳定的API,当失败调用次数达到一定阀值自动降级,同样要使用异步机制探测回复情况
故障降级 —— 如要调用的远程服务挂掉了(网络故障、DNS故障、HTTP服务返回错误的状态码和RPC服务抛出异常),则可以直接降级
限流降级 —— 当触发了限流超额时,可以使用暂时屏蔽的方式来进行短暂的屏蔽
当我们去秒杀或者抢购一些限购商品时,此时可能会因为访问量太大而导致系统崩溃,此时开发者会使用限流来进行限制访问量,当达到限流阀值,后续请求会被降级;降级后的处理方案可以是:排队页面(将用户导流到排队页面等一会重试)、无货(直接告知用户没货了)、错误页(如活动太火爆了,稍后重试)。
对哪些服务降级?
如果等线上服务即将发生故障时,才去逐个选择哪些服务该降级、哪些服务不能降级,然而线上有成百上千个服务,则肯定是来不及降级就会被拖垮。同时,在大促或秒杀等活动前才去梳理,也是会有不少的工作量,因此建议在开发期就需要架构师或核心开发人员来提前梳理好,是否能降级的初始评估值,即是否能降级的默认值。
为了便于批量操作微服务架构中服务的降级,我们可以从全局的角度来建立服务重要程度的评估模型,如果有条件的话,建议可以使用 层次分析法(The analytic hierarchy process,简称AHP) 的数学建模模型(或其它模型)来进行定性和定量的评估
建议根据二八原则可以将服务划分为:80%的非核心服务+20%的核心服务
具体大促或秒杀活动时,建议以具体主题为中心进行建立(不同主题的活动,因其依赖的服务不同,而使用不同的进行降级更为合理)
降级权值
可以为每一个服务分配一个降级权值,从而便于更加智能化的实现服务治理。
处理策略
当触发服务降级后,新的交易再次到达时,我们该如何来处理这些请求呢?从微服务架构全局的视角来看,我们通常有以下是几种常用的降级处理方案:
页面降级 —— 可视化界面禁用点击按钮、调整静态页面
延迟服务 —— 如定时任务延迟处理、消息入MQ后延迟处理
写降级 —— 直接禁止相关写操作的服务请求
读降级 —— 直接禁止相关度的服务请求
缓存降级 —— 使用缓存方式来降级部分读频繁的服务接口
针对后端代码层面的降级处理策略,则我们通常使用以下几种处理措施进行降级处理:
抛异常
返回NULL
调用Mock数据
调用Fallback处理逻辑
微服务架构—服务降级
http://baijiahao.baidu.com/s?id=1597340463620584006
Hystrix
hystrix对应的中文名字是“豪猪”,豪猪周身长满了刺,能保护自己不受天敌的伤害,代表了一种防御机制,这与hystrix本身的功能不谋而合,因此Netflix团队将该框架命名为Hystrix,并使用了对应的卡通形象做作为logo。
hystrix基本介绍和使用(1)
https://www.cnblogs.com/cowboys/p/7655829.html
高可用集群三种工作方式
- 1、主从方式 (非对称方式),Active/Passive:主备模型
工作原理:主机工作,备机处于监控准备状况;当主机宕机时,备机接管主机的一切工作,待主机恢复正常后,按使用者的设定以自动或手动方式将服务切换到主机上运行,数据的一致性通过共享存储系统解决。 - 2、双机双工方式(互备互援),Active/Active:双主模型
工作原理:两台主机同时运行各自的服务工作且相互监测情况,当任一台主机宕机时,另一台主机立即接管它的一切工作,保证工作实时,应用服务系统的关键数据存放在共享存储系统中。 - 3、集群工作方式(多服务器互备方式)
工作原理:多台主机一起工作,各自运行一个或几个服务,各为服务定义一个或多个备用主机,当某个主机故障时,运行在其上的服务就可以被其它主机接管。
HA原则:任何节点都不能有单点,都要双机热备
终极HA:异地灾备
服务器高可用
服务器高可用?
http服务器负载均衡,如果http服务器宕机怎么办?双机热备
负载均衡服务器的高可用性
为了屏蔽负载均衡服务器的失效,需要建立一个备份机。主服务器和备份机上都运行High Availability监控程序,通过传送诸如“I am alive”这样的信息来监控对方的运行状况。当备份机不能在一定的时间内收到这样的信息时,它就接管主服务器的服务IP并继续提供服务;当备份管理器又从主管理器收到“I am alive”这样的信息是,它就释放服务IP地址,这样的主管理器就开开始再次进行集群管理的工作了。为在主服务器失效的情况下系统能正常工作,我们在主、备份机之间实现负载集群系统配置信息的同步与备份,保持二者系统的基本一致。
数据库高可用
数据库高可用?
数据库主从集群,如果只有一个master,master宕机怎么办?双master热备
浅谈web应用的负载均衡、集群、高可用(HA)解决方案
http://aokunsang.iteye.com/blog/2053719
高可用集群
http://blog.csdn.net/tjiyu/article/details/52643096
集群(cluster)和高可用性(HA)的概念
http://blog.csdn.net/zhu1289303556/article/details/50486999
分布式系统CAP理论
一个分布式系统最多只能同时满足一致性(Consistency), 可用性(Availability) 和分区容错性(Partition tolerance) 这三项中的两项。
Consistency 一致性
Consistency means that all clients see the same data at the same time, no matter which node they connect to.
一致性指更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致,一致性指的是数据的 强一致性
客户端向分布式系统的读请求,要么读到最新的数据,要么失败
三种一致性策略
对于关系型数据库,要求更新过的数据能被后续的访问都能看到,这是 强一致性(Strong Consistency)。
如果能容忍后续的部分或者全部访问不到,则是弱一致性。
如果经过一段时间后要求能访问到更新后的数据,则是 **最终一致性(Eventual Consitency)**。
CAP 中说,不可能同时满足的这个一致性指的是强一致性。
Availability 可用性
Availability means that that any client making a request for data gets a response, even if one or more nodes are down.
可用性指服务一直可用,而且是正常响应时间。
对于一个可用性的分布式系统,每一个非故障的节点必须对每一个请求作出响应。所以,一般我们在衡量一个系统的可用性的时候,都是通过停机时间来计算的。
对分布式系统的请求 一定会得到非错误的响应,但不保证响应一定包含最新写入的数据
也就是说从客户端的角度看,不会出现向分布式系统发出请求但得不到任何有意义的响应的情况,即系统提供的服务对客户端而言不能宕机,一直都是可用的。
Partition Tolerance 分区容错性
Partition tolerance means that the cluster must continue to work despite any number of communication breakdowns between nodes in the system.
网络分区(network partition)指的是网络中有节点挂掉时,原网络分解为两个或多个子网络的过程。
分区容错性指分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。也就是说,即使系统的一部分(一个或多个节点)无法与其他部分通信,系统仍然能够正常运行。
在实际的分布式系统设计中,由于网络故障是无法避免的,因此 分区容错性通常是一定要满足的,在满足分区容错性的前提下,系统设计者需要在一致性和可用性之间做出权衡
CAP选择
为什么满足 P 的前提下,C 和 A 只能选一个?
分区指的是网络分区,比如一个是A区域,一个是B区域,分布式服务的节点分布在这两个区域中,现在假设这两个地区的网络不通了。
- 如果保证可用性。向A区域发送修改请求,此时由于A和B网络不通,此时只有A中的服务修改成功,B无法修改成功,此时数据AB区域数据就不一致性,也就没有保证数据一致性
- 如果保证一致性,向A区域发送修改请求,此时由于A和B网络不通,所以此时A也不能修改成功,必须修改失败,否则就会导致AB数据不一致,也就没有了可用性
所以,在有分区容错性的前提下,可用性和一致性是无法同时保证的。
分布式系统总是由多个节点组成,网络问题几乎必定会出现。所以分区容错性 P 必须要保证,CAP 三者中,只能在CA两者之间做权衡,并且要想尽办法提升P。
对于多数大型互联网应用的场景,主机众多、部署分散,而且现在的集群规模越来越大,所以节点故障、网络故障是常态,而且要保证服务可用性达到N个9,即保证P和A,舍弃C(退而求其次保证最终一致性)。
对于涉及到钱财这样不能有一丝让步的场景,C必须保证。网络发生故障宁可停止服务,这是保证CA,舍弃P。
https://mp.weixin.qq.com/s/GOsM5KMsLzJ37KLGXhVZXQ
CP without A:如果不要求A(可用),相当于每个请求都需要在服务器之间保持强一致,而P(分区)会导致同步时间无限延长(也就是等待数据同步完才能正常访问服务),一旦发生网络故障或者消息丢失等情况,就要牺牲用户的体验,等待所有数据全部一致了之后再让用户访问系统。设计成CP的系统其实不少,最典型的就是分布式数据库,如Redis、HBase等。对于这些分布式数据库来说,数据的一致性是最基本的要求,因为如果连这个标准都达不到,那么直接采用关系型数据库就好,没必要再浪费资源来部署分布式数据库。
AP wihtout C:要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。典型的应用就如某米的抢购手机场景,可能前几秒你浏览商品的时候页面提示是有库存的,当你选择完商品准备下单的时候,系统提示你下单失败,商品已售完。这其实就是先在 A(可用性)方面保证系统可以正常的服务,然后在数据的一致性方面做了些牺牲,虽然多少会影响一些用户体验,但也不至于造成用户购物流程的严重阻塞。
ZooKeeper(CP)
Zookeeper保证的是CP,即任何时刻对Zookeeper的访问请求能得到一致的数据结果,同时系统对网络分割具备容错性,但是它不能保证每次服务请求的可用性。
从实际情况来分析,在使用Zookeeper获取服务列表时,如果zookeeper正在选主,或者Zookeeper集群中半数以上机器不可用,那么将就无法获得数据了。所以说,Zookeeper不能保证服务可用性。
Consul(CP)
Consul是一个服务发现和配置的工具,它在CAP理论中属于CP(一致性和分区容错性)。
Consul通过Raft协议来保证数据的一致性,即在多个节点之间复制和同步数据,确保每个节点的数据都是一致的。同时,Consul也能够在网络分区或节点故障的情况下,继续提供服务,满足分区容错性的要求。
虽然Consul在设计上强调了一致性和分区容错性,但在实际使用中,通过适当的配置和优化,也可以在一定程度上提高其可用性。
Eureka(AP)
Eureka是Netflix开源的一款服务发现框架,它在CAP理论中属于AP(可用性和分区容错性)。
Eureka的设计目标是在网络分区或故障发生时,能够保证服务的可用性。即使在部分节点失效或无法通信的情况下,Eureka仍然能够正常提供服务注册和发现的功能。
在Eureka中,每个节点都是平等的,没有所谓的主节点或从节点。所有节点都会定期向其他节点发送心跳,以此来检测节点的状态。即使在网络分区的情况下,Eureka也能够通过副本来提供服务,从而保证了分区容错性。
然而,由于Eureka强调的是可用性,因此在某些情况下,它可能无法保证数据的强一致性。例如,当网络分区恢复后,各个节点的数据可能会出现不一致的情况。
Oracle/MySQL(CA)
CA without P:如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。但放弃P的同时也就意味着放弃了系统的扩展性,也就是分布式节点受限,没办法部署子节点,这是违背分布式系统设计的初衷的。
传统的关系型数据库RDBMS:Oracle、MySQL就是CA。
CA 显然是为传统的(单点)关系型数据库和其他类似架构的非分布式数据库准备的,它们不存在网络分区的问题。
分布式服务发现应保证哪两个特性?
对于大多数分布式环境,尤其是涉及到数据存储的场景,数据一致性应该是首先被保证的,这也是zookeeper设计成CP的原因。
但是对于服务发现场景来说,情况就不太一样了:针对同一个服务,即使注册中心的不同节点保存的服务提供者信息不尽相同,也并不会造成灾难性的后果。因为对于服务消费者来说,能消费才是最重要的——拿到可能不正确的服务实例信息后尝试消费一下,也好过因为无法获取实例信息而不去消费。所以,对于服务发现而言,可用性比数据一致性更加重要——AP胜过CP。
分布式系统的CAP理论
http://www.hollischuang.com/archives/666
脑裂(split brain)
split brain 脑裂,指采用主从(master-slave)架构的分布式系统中,出现了多个活动的主节点的情况。但正常情况下,集群中应该只有一个活动主节点。
造成脑裂的原因主要是网络分区。由于网络故障或者集群节点之间的通信链路有问题,导致原本的一个集群被物理分割成为两个甚至多个小的、独立运作的集群,这些小集群各自会选举出自己的主节点,并同时对外提供服务。网络分区恢复后,这些小集群再度合并为一个集群,就出现了多个活动的主节点。
另外,主节点假死也有可能造成脑裂。由于当前主节点暂时无响应(如负载过高、频繁GC等)导致其向其他节点发送心跳信号不及时,其他节点认为它已经宕机,就触发主节点的重新选举。新的主节点选举出来后,假死的主节点又复活,就出现了两个主节点。
一般有以下三种思路来避免脑裂:
法定人数/多数机制(Quorum)
隔离机制(Fencing)
冗余通信机制(Redundant communication)
一、法定人数/多数机制(Quorum)
Quorum 一词的含义是“法定人数”,在 ZooKeeper 的环境中,指的是 ZK 集群能够正常对外提供服务所需要的最少有效节点数。也就是说,如果 n 个节点的 ZK 集群有少于 m 个节点是 up 的,那么整个集群就 down 了。m 就是所谓 Quorum size, 并且:m = n / 2 + 1
ZK的Quorum机制其实就是要求集群中过半的节点是正常的,所以ZK集群包含奇数个节点比偶数个节点要更好。显然,如果集群有6个节点的话,Quorum size是4,即能够容忍2个节点失败,而5个节点的集群同样能容忍2个节点失败,所以可靠性是相同的。偶数节点还需要额外多管理一个节点,不划算。
如果是 Leader 假死造成的脑裂,可通过纪元(epoch) 来解决。
集群每次选举出一个Leader时,都会自增纪元值(epoch),也就是Leader的代数。所以,就算原来的Leader复活,它的纪元值已经小于新选举出来的现任Leader的纪元值,Follower就会拒绝所有旧Leader发来的请求,所以不会产生脑裂。
除ZK外,Kafka集群的Controller也是靠纪元值防止脑裂的。
浅谈分布式系统脑裂现象与ZK、HDFS的避免方案
https://blog.csdn.net/nazeniwaresakini/article/details/106744043
分布式系统BASE理论
eBay的架构师Dan Pritchett源于对大规模分布式系统的实践总结,在ACM上发表文章提出BASE理论,BASE理论是对CAP理论的延伸,核心思想是 即使无法做到强一致性(Strong Consistency,CAP的一致性就是强一致性),但应用可以采用适合的方式(结合自身业务特点)达到最终一致性(Eventual Consitency)。
BASE是指基本可用(Basically Available)、软状态(Soft State)、最终一致性(Eventual Consistency)
基本可用(Basically Available)
基本可用是指分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用。
电商大促时,为了应对访问量激增,部分用户可能会被引导到降级页面,服务层也可能只提供降级服务。这就是损失部分可用性的体现。
什么是基本可用呢?假设系统,出现了不可预知的故障,但还是能用,相比较正常的系统而言:
响应时间上的损失:正常情况下的搜索引擎0.5秒即返回给用户结果,而基本可用的搜索引擎可以在2秒作用返回结果。
功能上的损失:在一个电商网站上,正常情况下,用户可以顺利完成每一笔订单。但是到了大促期间,为了保护购物系统的稳定性,部分消费者可能会被引导到一个降级页面。
软状态(Soft State)
软状态是指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。
分布式存储中一般一份数据至少会有三个副本,允许不同节点间副本同步的延时就是软状态的体现。mysql replication的异步复制也是一种体现。
最终一致性(Eventual Consistency)
最终一致性是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况。
分布式系统的leader选举
分布式系统或组件一般都包含Leader选举的过程,比如ZooKeeper的Leader节点选举,Redis Sentinel的领头节点选举,Redis Cluster中主节点的选举等。
所有节点具有3种状态:Leader, Follower, Candidate
Leader选举根据是否按照节点状态/数据选举,分成等价选举和择优选举
- 等价选举:Candidate完全等价,没有优劣之分。比如Redis Sentinel
- 择优选举:Candidate根据不同的状态,存在不同优先级。比如ZooKeeper
Leader选举的通用模式
https://www.jianshu.com/p/0dcfca1e5c68
Raft算法
见笔记 Raft分布式一致性算法
大数据处理
- 1、文件过大?拆分为n个小文件,怎么拆?依次取出每个数据e,hash(e)%n,散列到n个小文件中。
- 2、在每个小文件中,用hashmap处理,key是元素内容,value是出现次数。
- 3、在每个小文件中,用最小堆求出现次数前k大的。
- 4、在所有小文件的出现次数前k大元素中求出现次数前k大的。
从头到尾彻底解析Hash表算法:
http://blog.csdn.net/v_JULY_v/article/details/6256463
十道海量数据处理面试题与十个方法大总结:
http://blog.csdn.net/v_JULY_v/article/details/6279498
java海量大文件数据处理方式
https://blog.csdn.net/zhanjianshinian/article/details/78300505
找最大的K个数
编程之美–寻找最大的K个数:
http://blog.csdn.net/rein07/article/details/6742933
用最小堆:
建立一个长度为K的最小堆,用数组的前K个元素初始化,然后从第K+1个元素开始扫描数组,如果大于堆顶,则互换元素,并从上到下调整堆;如果小于堆顶,则继续读入下一个,这样最后最小堆里剩的就是最大的K个元素.时间复杂度O(N*logK)
最大堆:根结点的键值是所有堆结点键值中最大者。
最小堆:根结点的键值是所有堆结点键值中最小者。
热门搜索词TOP10的实现
搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。
假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。
这个题目与上个题目类似,我们选择使用HashMap,key为查询值,val为计数,内存使用为 3 * 256 M == 768M < 1G,然后我们不断的put就可以了,伪代码
HashMap<String, Integer> map = new HashMap<String,Integer>();
//如果内存再多点的话,我们就可以把初始化容量凑个1024的整数,减少扩容损失。
while(fileLog.hasNext()){
String queue = fileLog.next();
map.put(queue, map.get(queue) + 1);
}
接着使用堆排序遍历即可,堆的大小为10,复杂度为10xO(LogN)。
布隆过滤器
bitmap
对于海量的、取值分布很均匀的集合进行去重,Bitmap极大地压缩了所需要的内存空间。于此同时,还额外地完成了对原始数组的排序工作。缺点是,Bitmap对于每个元素只能记录1bit信息,如果还想完成额外的功能,恐怕只能靠牺牲更多的空间、时间来完成了。
高并发
秒杀系统设计
设计思路:
将请求拦截在系统上游,降低下游压力:秒杀系统特点是并发量极大,但实际秒杀成功的请求数量却很少,所以如果不在前端拦截很可能造成数据库读写锁冲突,甚至导致死锁,最终请求超时。
充分利用缓存:利用缓存可极大提高系统读写速度。
消息队列:消息队列可以削峰,将拦截大量并发请求,这也是一个异步处理过程,后台业务根据自己的处理能力,从消息队列中主动的拉取请求消息进行业务处理。
浏览器端(js):
页面静态化:将活动页面上的所有可以静态的元素全部静态化,并尽量减少动态元素。通过CDN来抗峰值。
禁止重复提交:用户提交之后按钮置灰,禁止重复提交
用户限流:在某一时间段内只允许用户提交一次请求,比如可以采取IP限流
站点层请求拦截与页面缓存
浏览器层的请求拦截,只能拦住小白用户(不过这是99%的用户哟),高端的程序员根本不吃这一套,写个for循环,直接调用你后端的http请求,怎么整?
a)同一个uid,限制访问频度,做页面缓存,x秒内到达站点层的请求,均返回同一页面
b)同一个item的查询,例如手机车次,做页面缓存,x秒内到达站点层的请求,均返回同一页面
如此限流,又有99%的流量会被拦截在站点层
服务层
上面只拦截了一部分访问请求,当秒杀的用户量很大时,即使每个用户只有一个请求,到服务层的请求数量还是很大。比如我们有100W用户同时抢100台手机,服务层并发请求压力至少为100W。
1、采用消息队列缓存请求:既然服务层知道库存只有100台手机,那完全没有必要把100W个请求都传递到数据库啊,那么可以先把这些请求都写到消息队列缓存一下,数据库层订阅消息减库存,减库存成功的请求返回秒杀成功,失败的返回秒杀结束。
2、利用缓存应对读请求:对类似于12306等购票业务,是典型的读多写少业务,大部分请求是查询请求,所以可以利用缓存分担数据库压力。
3、利用缓存应对写请求:缓存也是可以应对写请求的,比如我们就可以把数据库中的库存数据转移到Redis缓存中,所有减库存操作都在Redis中进行,然后再通过后台进程把Redis中的用户秒杀请求同步到数据库中。
数据库层
数据库层是最脆弱的一层,一般在应用设计时在上游就需要把请求拦截掉,数据库层只承担“能力范围内”的访问请求。所以,上面通过在服务层引入队列和缓存,让最底层的数据库高枕无忧。
如何设计一个秒杀系统
https://blog.csdn.net/suifeng3051/article/details/52607544
秒杀系统设计?
https://www.zhihu.com/question/54895548
限流
限流的目的是通过对并发访问/请求进行限速或者一个时间窗口内的的请求进行限速来保护系统,一旦达到限制速率则可以拒绝服务(定向到错误页或告知资源没有了)、排队或等待(比如秒杀、评论、下单)、降级(返回兜底数据或默认数据,如商品详情页库存默认有货)。
限流类型
一般开发高并发系统常见的限流有:
- 限制总并发数(比如数据库连接池、线程池)
- 限制瞬时并发数(如nginx的limit_conn模块,用来限制瞬时并发连接数)
- 限制时间窗口内的平均速率(如Guava的RateLimiter、nginx的limit_req模块,限制每秒的平均速率)
- 其他还有如限制远程接口调用速率、限制MQ的消费速率。
- 另外还可以根据网络连接数、网络流量、CPU或内存负载等来限流。
常用限流算法
计数器算法
计数器算法是限流算法里最简单也是最容易实现的一种算法。
比如我们规定,对于A接口来说,我们1分钟的访问次数不能超过100个。那么我们可以这么做:在一开 始的时候,我们可以设置一个计数器counter,每当一个请求过来的时候,counter就加1,如果counter的值大于100并且该请求与第一个 请求的间隔时间还在1分钟之内,那么说明请求数过多;如果该请求与第一个请求的间隔时间大于1分钟,且counter的值还在限流范围内,那么就重置 counter,具体算法的示意图如下:
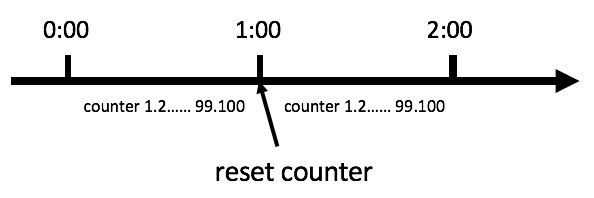
计数器限流法
问题:
固定窗口计数器是最为简单的算法,但这个算法有时会让通过请求量允许为限制的两倍。
考虑如下情况:
假设有个用户, 在 0:00 发送了第一个请求, 将计数器初始化为1
然后在 0:59 时,瞬间发送了 99 个请求,
并且 1:00 又瞬间发送了100个请求,注意在 1:00 的时候计数器会被重置为0,所以此时的 100 个请求是被允许的
那么其实这个用户在 1:00 前后的2秒里面的 199 个请求都是可以被允许的,通过此漏洞突破了计数器限流算法。
根本问题是,这个窗口不顺滑,精度太低。
滑动窗口法
滑动窗口计数器算法概念如下:
将时间划分为多个区间;
在每个区间内每有一次请求就将计数器加一维持一个时间窗口,占据多个区间;
每经过一个区间的时间,则抛弃最老的一个区间,并纳入最新的一个区间;
如果当前窗口内区间的请求计数总和超过了限制数量,则本窗口内所有的请求都被丢弃。
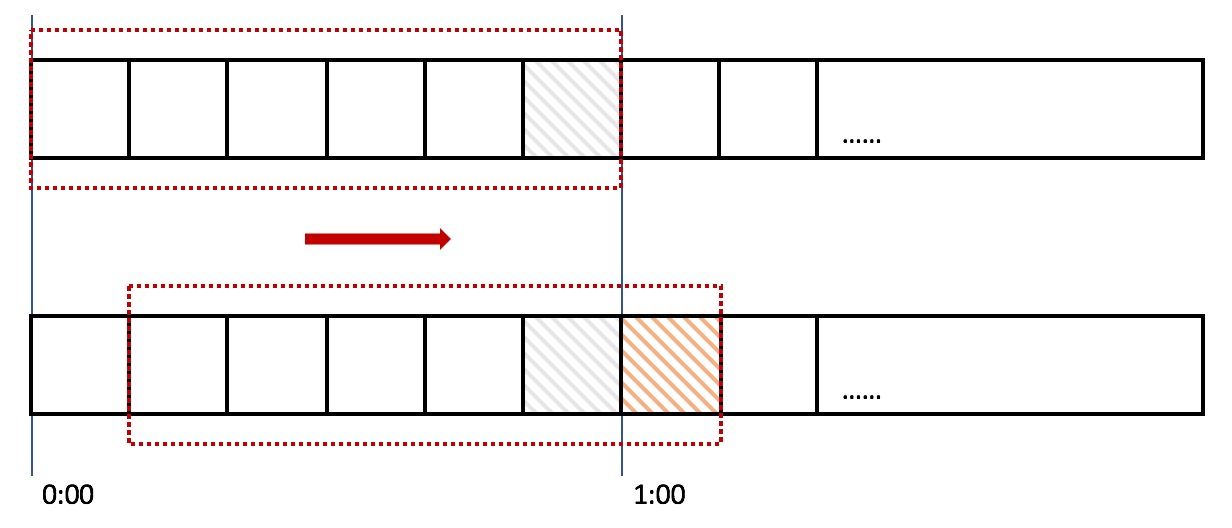
滑动窗口限流法
在上图中,整个红色的矩形框表示一个时间窗口,将时间窗口进行划分,比如图中,我们就将滑动窗口划成了6格,所以每格代表的是10秒钟。
每过10秒钟,我们的时间窗口就会往右滑动一格。每一个格子都有自己独立的计数器counter,比如当一个请求在 0:35 秒的时候到达,那么0:30~0:39对应的counter就会加1。
当滑动窗口的格子划分的越多,那么滑动窗口的滚动就越平滑,限流的统计就会越精确。
漏桶算法
漏桶算法这个名字就很形象,算法内部有一个容器,类似生活用到的漏斗,当请求进来时,相当于水倒入漏斗,然后从下端小口慢慢匀速的流出。不管上面流量多大,下面流出的速度始终保持不变。
不管服务调用方多么不稳定,通过漏桶算法进行限流,每10毫秒处理一次请求。因为处理的速度是固定的,请求进来的速度是未知的,可能突然进来很多请求,没来得及处理的请求就先放在桶里,既然是个桶,肯定是有容量上限,如果桶满了,那么新进来的请求就丢弃。
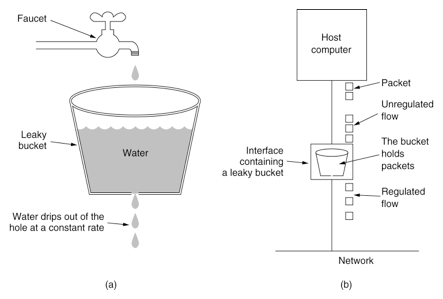
漏铜算法
在算法实现方面,可以准备一个队列,用来保存请求,另外通过一个定时线程池 ScheduledExecutorService 来定期从队列中获取请求并执行,可以一次性获取多个并发执行。
问题:
无法应对短时间的突发流量,永远只能以恒定的速率处理请求。
令牌桶算法(最优)
令牌桶算法是对漏桶算法的一种改进, 能够在限制调用的平均速率的同时还 允许一定程度的突发调用。
在令牌桶算法中,存在一个桶,用来存放固定数量的令牌。算法中存在一种机制,以一定的速率往桶中放令牌。每次请求调用需要先获取令牌,只有拿到令牌,才有机会继续执行,否则选择选择等待可用的令牌、或者直接拒绝。
放令牌这个动作是持续不断的进行,如果桶中令牌数达到上限,就丢弃令牌
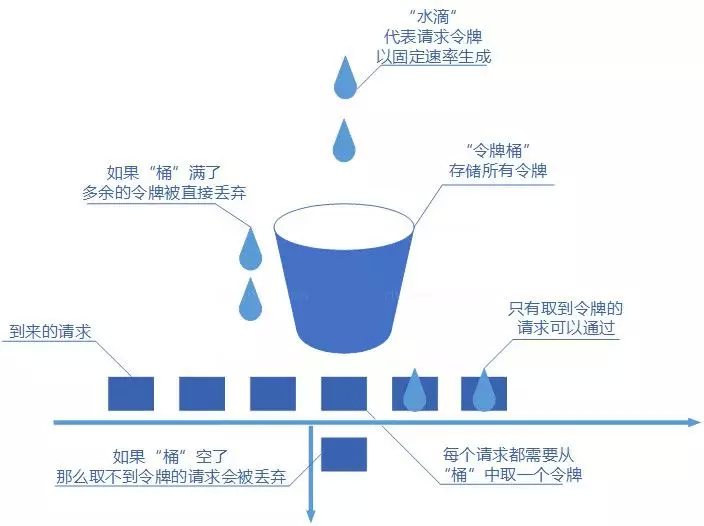
令牌桶算法
令牌更新方式
根据令牌桶算法,桶中的令牌是持续生成存放的,谁来持续生成令牌存放呢?
1、 开启一个定时任务,由定时任务持续生成令牌。这样的问题在于会极大的消耗系统资源,如,某接口需要分别对每个用户做访问频率限制,假设系统中存在6W用户,则至多需要开启6W个定时任务来维持每个桶中的令牌数,这样的开销是巨大的。
2、 惰性计算,或 延迟计算,记住上次请求的时间,在每次请求进来的时候先去计算上次请求和本次请求之间应该生成多少个令牌,将生成的令牌加入令牌桶中。
实现
Guava RateLimiter(单机限流)
参见笔记 Google-Guava 使用笔记
Lua脚本+Redis(分布式限流)
令牌桶算法需要在 Redis 中存储桶的大小、当前令牌数量,并且实现每隔一段时间添加新的令牌。
最简单的办法当然是每隔一段时间请求一次 Redis,将存储的令牌数量递增。
但实际上我们可以通过对限流两次请求之间的时间和令牌添加速度来计算得出上次请求之后到本次请求时,令牌桶应添加的令牌数量。因此我们在 Redis 中只需要存储上次请求的时间和令牌桶中的令牌数量,而桶的大小和令牌的添加速度可以通过参数传入实现动态修改。
使用 redis 的哈希结构, key 是限流接口 ID,或者限流 IP,存储两个域, last_time 是上次请求时间, current_token 是令牌桶中的令牌数量。
每次请求到来时,根据 IP 或 ID 获取 hmget 获取 redis 值, 计算 last_time 到当前时间的时间间隔内令牌应该增加的个数 delta_token ,重置 current_token = current_token + delta_token, 然后比较 current_token 和 允许的最大令牌数 max_token ,
如果 current_token < max_token,允许通过,重新 hmset 更新 redis 值,
如果 current_token > max_token,禁止通过, 重设 redis 值。
可以放在 nginx 网关上用 lua 脚本限流,也可以在服务内用lua脚本限流,都是分布式的。
分布式限流如何保证高可用?
假如 lua + redis 实现的分布式限流算法部署在 nginx 网关上,则网关上的所有流量都要先经过这个限流器,那么这个限流器的可用性就变得非常关键,那么如何保证高可用呢?
这里的高可用主要是说 redis 服务的高可用,可以有2个思路:
1、连接多个 redis 实例(集群),当其中一个挂掉的时候自动切换另一个
2、lua 脚本中做好降级策略,当 redis 连不上时降级为全部通过,或者降级为固定值限流。
分布式服务限流实战,已经为你排好坑了
https://www.infoq.cn/article/Qg2tX8fyw5Vt-f3HH673
nginx网关限流
对于Nginx接入层限流可以使用Nginx自带了两个模块:
连接数限流模块 ngx_http_limit_conn_module
漏桶算法实现的请求限流模块 ngx_http_limit_req_module
还可以使用OpenResty提供的Lua限流模块 lua-resty-limit-traffic 进行更复杂的限流场景。
limit_conn 总(并发)连接数限流
limit_conn用来对某个KEY对应的总的网络连接数进行限流,可以按照如IP、域名维度进行限流。
limit_conn是对某个KEY对应的总的网络连接数进行限流。可以按照IP来限制IP维度的总连接数,或者按照服务域名来限制某个域名的总连接数。但是记住不是每一个请求连接都会被计数器统计,只有那些被Nginx处理的且已经读取了整个请求头的请求连接才会被计数器统计。
配置示例:
http {
limit_conn_zone $binary_remote_addr zone=addr:10m;
limit_conn_log_level error;
limit_conn_status 503;
...
server {
...
location /limit {
limit_conn addr 1;
}
}
}
limit_conn:要配置存放KEY和计数器的共享内存区域和指定KEY的最大连接数;此处指定的最大连接数是1,表示Nginx最多同时并发处理1个连接;
limit_conn_zone:用来配置限流KEY、及存放KEY对应信息的共享内存区域大小;此处的KEY是“$binary_remote_addr”其表示IP地址,也可以使用如$server_name作为KEY来限制域名级别的最大连接数;
limit_conn_status:配置被限流后返回的状态码,默认返回503;
limit_conn_log_level:配置记录被限流后的日志级别,默认error级别。
limit_conn的主要执行过程如下所示:
1、请求进入后首先判断当前limit_conn_zone中相应KEY的连接数是否超出了配置的最大连接数;
如果超过了配置的最大大小,则被限流,返回limit_conn_status定义的错误状态码;
否则相应KEY的连接数加1,并注册请求处理完成的回调函数;
2、进行请求处理;
3、在结束请求阶段会调用注册的回调函数对相应KEY的连接数减1。
limt_conn可以限流某个KEY的总并发/请求数,KEY可以根据需要变化。
limit_req 平均速率限流
limit_req用来对某个KEY对应的请求的平均速率进行限流,并有两种用法:平滑模式(delay)和允许突发模式(nodelay)。
limit_req是漏桶算法实现,用于对指定KEY对应的请求进行限流,比如按照IP维度限制请求速率。
配置示例
http {
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;
limit_conn_log_level error;
limit_conn_status 503;
...
server {
...
location /limit {
limit_req zone=one burst=5 nodelay;
}
}
}
limit_req:配置限流区域、桶容量(突发容量,默认0)、是否延迟模式(默认延迟);
limit_req_zone:配置限流KEY、及存放KEY对应信息的共享内存区域大小、固定请求速率;此处指定的KEY是“$binary_remote_addr”表示IP地址;固定请求速率使用rate参数配置,支持10r/s和60r/m,即每秒10个请求和每分钟60个请求,不过最终都会转换为每秒的固定请求速率(10r/s为每100毫秒处理一个请求;60r/m,即每1000毫秒处理一个请求)。
limit_conn_status:配置被限流后返回的状态码,默认返回503;
limit_conn_log_level:配置记录被限流后的日志级别,默认error级别。
limit_req的主要执行过程如下所示:
1、请求进入后首先判断最后一次请求时间相对于当前时间(第一次是0)是否需要限流,如果需要限流则执行步骤2,否则执行步骤3;
2.1、如果没有配置桶容量(burst),则桶容量为0;按照固定速率处理请求;如果请求被限流,则直接返回相应的错误码(默认503);
2.2、如果配置了桶容量(burst>0)且延迟模式(没有配置nodelay);如果桶满了,则新进入的请求被限流;如果没有满则请求会以固定平均速率被处理(按照固定速率并根据需要延迟处理请求,延迟使用休眠实现);
2.3、如果配置了桶容量(burst>0)且非延迟模式(配置了nodelay);不会按照固定速率处理请求,而是允许突发处理请求;如果桶满了,则请求被限流,直接返回相应的错误码;
3、如果没有被限流,则正常处理请求;
4、Nginx会在相应时机进行选择一些(3个节点)限流KEY进行过期处理,进行内存回收。
聊聊高并发系统之限流特技
https://www.iteye.com/blog/jinnianshilongnian-2305117
分布式ID生成算法
java.util.UUID 单机UUID生成器
java 中的 UUID 类是利用 SecureRandom 强伪随机数类来生成的,SecureRandom 使用 鼠标点击,键盘点击 等随机事件作为种子,具有不可预测性。
private static class Holder {
static final SecureRandom numberGenerator = new SecureRandom();
}
public static UUID randomUUID() {
SecureRandom ng = Holder.numberGenerator;
byte[] randomBytes = new byte[16];
ng.nextBytes(randomBytes);
randomBytes[6] &= 0x0f; /* clear version */
randomBytes[6] |= 0x40; /* set to version 4 */
randomBytes[8] &= 0x3f; /* clear variant */
randomBytes[8] |= 0x80; /* set to IETF variant */
return new UUID(randomBytes);
}
例如:
@Test
public void testUUID() {
for (int i = 0; i < 5; i++) {
System.out.println(UUID.randomUUID());
}
}
结果:
10df95ab-a5ab-4011-9b36-971f39ce4412
fa28fd6f-f10d-461b-bfa3-79881c6f676d
b224bd88-9e42-4db3-a324-75e80e42ad2e
3ad77ff1-4fdf-4182-91be-332218a20f6a
615b90c7-725d-40a8-85b5-0eb0dff7722d
Redis incr命令全局id
Redis中有两个命令Incr,IncrBy, 因为Redis是单线程的所以能保证原子性。
缺点:
由于redis是内存的KV数据库,即使有AOF和RDB,但是依然会存在数据丢失,有可能会造成ID重复。
依赖于redis,redis要是不稳定,会影响ID生成。
适用:由于其性能比数据库好,但是有可能会出现ID重复和不稳定,这一块如果可以接受那么就可以使用。也适用于到了某个时间,比如每天都刷新ID,那么这个ID就需要重置,通过(Incr Today),每天都会从0开始加。
Snowflake雪花算法
如何处理时钟回拨?
Leaf美团分布式id算法
为什么叫leaf?
因为天底下没有两片完全一样的树叶
leaf 是基于 springboot、以HTTP协议的方式提供获取分布式唯一ID的服务。
总计有两种模式:Snowflake和Segment。
SnowFlake 模式依赖 zookeeper
segment 模式依赖 数据库
Segment有“段”的意思,leaf这种模式意味着并不是每次获取唯一ID都需要操作数据库。
所以,Segment模式就是在前面提到的数据库方案基础之上进行了优化:既然每次操作数据库性能有问题,那么我就每过 N 次才操作一次数据库。在这 N 次以内的访问,都只需要通过操作本地缓存获取。如此一来,性能就很高了。这个 N 值表示的范围就是 Segment 的意思。
不过还是有点瑕疵,因为每过 N 次都要操作一次数据库。如果恰好在这个时候并发较高,那么数据库操作就会阻塞,甚至出现超时,从而形成性能毛刺甚至降低SLA。怎么办?
leaf的做法是将这个步骤提前并异步化
当发号器已经分发到当前 segment 的 10% 的时候,就会触发一个异步操作去初始化下一个号段;
如何避免重启后分配重复的ID呢?
我们假设已经分配到1122,这个1122又没有持久化到任何一个地方,数据库中只保存了(max_id=2001, step=1000),如果这时候leaf宕机。leaf的做法是在第一次获取唯一ID的时候,会首先更新数据库跳到下一个号段(max_id=3001, step=1000),那么这时候获取的唯一ID就是2001,至于1123~2000之前的ID全部被抛弃,不会被分配了。
Segment模式有时钟回拨问题吗?
很明显没有,因为通过这种模式获取的ID没有任何时间属性,所以不存在时钟回拨问题。
Leaf——美团点评分布式ID生成系统
https://tech.meituan.com/2017/04/21/mt-leaf.html
Leaf:美团的分布式唯一ID方案深入剖析
https://www.jianshu.com/p/bd6b00e5f5ac
分布式锁
针对分布式锁的实现,目前比较常用的有以下几种方案:
基于数据库实现分布式锁
基于缓存(redis,memcached,tair)实现分布式锁
基于Zookeeper实现分布式锁
分布式锁的几种实现方式
http://blog.csdn.net/zdy0_2004/article/details/53070209
Java分布式锁三种实现方案
https://www.jianshu.com/p/535efcab356d
基于数据库表实现
要实现分布式锁,最简单的方式可能就是直接创建一张锁表,然后通过操作该表中的数据来实现了。
当我们要锁住某个方法或资源时,我们就在该表中增加一条记录,想要释放锁的时候就删除这条记录。
基于缓存实现分布式锁
相比较于基于数据库实现分布式锁的方案来说,基于缓存来实现在性能方面会表现的更好一点。而且很多缓存是可以集群部署的,可以解决单点问题。
目前有很多成熟的缓存产品,包括 Redis,memcached
可以使用缓存来代替数据库来实现分布式锁,这个可以提供更好的性能,同时,很多缓存服务都是集群部署的,可以避免单点问题。并且很多缓存服务都提供了可以用来实现分布式锁的方法,比如Tair的put方法,redis的setnx方法等。并且,这些缓存服务也都提供了对数据的过期自动删除的支持,可以直接设置超时时间来控制锁的释放。
基于redis实现分布式锁
set key value px milliseconds nx
原子性操作,当且仅当 key 不存在,将 key 的值设为 value ,设置有效期,并返回1;若给定的 key 已经存在,则 SETNX 不做任何动作,返回空。
这种实现方式有3大要点(也是面试概率非常高的地方):
1、set 命令要用 set key value px milliseconds nx 保证原子性
2、value 要具有唯一性,可以取 host+threadId
3、释放锁时要验证value值,不能误解锁;(需要先 get 锁内容,比较后再 del key,如何保证原子性?使用lua脚本)
注意:
1、为了防止加锁结点宕机后锁无法释放,需要给key设置一个过期时间,过期后锁自动释放
2、可能出现结点A把结点B的锁释放掉的问题
A结点加锁,设置过期时间,然后A结点由于某种原因阻塞了,过期时间到后锁自动释放,然后B结点也加了这个锁,B结点解锁之前A恢复了,A执行完事务后把B加的锁释放掉,然后B再释放锁时出现问题。
解决方法是锁中设置标志位,标识是哪个结点加的锁,只有加锁的结点才能释放锁。
如何解决任务超过锁的有效期?
1、一种方式就是不做处理,任务结束时比较锁key的value是不是自己的,如果是别人的锁就直接忽略,但是这样做的问题是,肯能同时有多个任务执行,如果job本身是幂等的话就不需处理,如果job不支持幂等,需要第二种方案
Redisson 是一个企业级的开源 Redis Client,也提供了分布式锁的支持。
Redisson 中有一个 Watchdog 的概念,翻译过来就是看门狗,它会在你获取锁之后,每隔 10s 帮你把 Key 的超时时间设为 30s。
这样的话,就算一直持有锁也不会出现 Key 过期了,其他线程获取到锁的问题了。
如何解决redis集群部署问题?
Redis 有 3 种部署方式:
单机模式
Master-Slave+Sentinel 选举模式
Redis Cluster 模式
使用 Redis 做分布式锁的缺点在于:如果采用单机部署模式,会存在单点问题,只要 Redis 故障了。加锁就不行了。
采用 Master-Slave 模式,加锁的时候只对一个节点加锁,即便通过 Sentinel 做了高可用,但是如果 Master 节点故障了,发生主从切换,此时就会有可能出现锁丢失的问题。
基于以上的考虑,Redis 的作者也考虑到这个问题,他提出了一个 RedLock 的算法。
分布式锁用Redis还是Zookeeper?
https://zhuanlan.zhihu.com/p/73807097
基于Zookeeper实现分布式锁
基于 zookeeper 临时有序节点可以实现的分布式锁。
大致思想即为:每个客户端对某个方法加锁时,在 zookeeper 上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。
判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。
当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。
redis/zk分布式锁区别?
redis分布式锁如果是自己手动简单 set key value nx px 实现的话,是非公平锁,当人可以用 redisson 实现的公平锁。
ZK获取锁会按照加锁的顺序,所以其是公平锁。
分布式定时任务
quartz
elastic-job-lite
SOFA分布式框架
SOFA 是蚂蚁金服自主研发的金融级分布式中间件,包含了构建金融级云原生架构所需的各个组件,包括微服务研发框架,RPC 框架,服务注册中心,分布式定时任务,限流/熔断框架,动态配置推送,分布式链路追踪,Metrics监控度量,分布式高可用消息队列,分布式事务框架,分布式数据库代理层等组件,是一套分布式架构的完整的解决方案,也是在金融场景里锤炼出来的最佳实践。
SOFA是蚂蚁金服长期发展沉淀下来的一条技术方案,在SpringCloud出现之前,SOFA已经能够在金融云环境下稳定运行了
权限控制模型
ACL 访问控制列表
ACL(access control list)访问控制列表。ACL是一种面向资源的访问控制模型。
ACL实体模型的核心在于用户可以直接和权限挂钩,权限模型包括:资源标识、用户标识、授权状态。
ACL的原理为:每一项资源,都配有一个列表,这个列表记录的就是哪些用户可以对这项资源执行增加(Create)、检索(Retrieve)、更新(Update)和删除(Delete)等操作。当用户试图访问这项资源时,会首先检查这个列表中是否有关于当前用户的访问权限,从而确定当前用户是否可执行相应的操作。总体来说,ACL是一种面向资源的访问控制模型,它的机制是围绕“资源”展开的。
优点:
ACL权限模型原理简单,直接将权限赋给用户,便于理解和操作。
可以满足个性化的需求,即为系统中的用户单独分配权限。
缺点:
由于需要维护每个用户的访问权限列表,管理者工作量大,所以需要解决复用性问题。
RBAC 基于角色(Role Based)
RBAC(Role-Based Access Control )基于角色的访问控制。RBAC认为权限的过程可以抽象概括为:判断【Who对What是否可进行How的访问操作】:
- Who:权限的拥用者或主体(如Principal、User、Group、Role、Actor等等)。
- What:权限针对的对象或资源(Resource、Class)。
- How:具体的权限(Privilege,正向授权与负向授权)。
RBAC的核心思想就是将访问权限与角色相关联,通过给用户分配适合的角色,让用户与访问权限相联系。角色是根据组织内为完成各种不同的任务需要而设置的,根据用户在组织中的职权和责任来设定他们的角色,用户可以在角色间进行转换,系统可以添加、删除角色,还可以对角色的权限进行添加、删除。这样通过应用RBAC可将安全性放在一个接近组织结构的自然层面上进行管理。权限被赋予角色,而不是用户,当一个角色被指定给一个用户时,此用户就拥有了该角色所包含的权限。一个用户拥有若干角色,一个角色拥有若干权限,这就构成“用户-角色-权限”的授权模型。
RBAC引入了角色的概念,目的是为了隔离用户与权限。角色(Role)作为一个用户(User)与权限(Privilege)的代理层,解耦了权限和用户的关系,所有的授权应该给予角色而不是直接给用户。
基于角色的访问控制方法(RBAC)的显著的两大特征是:
1.由于角色/权限之间的变化比角色/用户关系之间的变化相对要慢得多,减小了授权管理的复杂性,降低管理成本。
2.灵活地支持企业的安全策略,并对企业的变化有很大的伸缩性。
缺点:
- 由于权限是以角色为载体分配的,因此无法对某一角色下的个别用户需要进行特别的权限定制,只能再重新创建角色。即不可对角色组下的单个成员进行个性化权限设置。
- RBAC模型只给角色赋予了权限,没有提供这些权限的操作顺序控制机制。这一缺陷使得RBAC模型很难应用关于那些要求有严格操作顺序的实体系统。例如,在购物控制系统中要求系统对购买步骤的控制,在客户未付款之前不应让他把商品拿走。RBAC模型要求把这种控制机制放到权限模型中预设好。
ABAC 基于属性(Attribute Based)
ABAC是基于属性的访问控制权限模型。定义:规定哪些属性的主体可以对哪些属性的资源在哪些属性的环境下进行哪些操作属性。
ABAC其中的属性就是与主体、资源、环境相关的所有信息:
- 主体的属性:指的是与主体相关的所有信息,包括主体的年龄、性别、职位等。
- 资源的属性:指的是与资源相关的所有信息,包括资源的创建时间、创建位置、密级等。
- 环境的属性:指的是客观情况的属性,比如当前的时间、当前的位置、当前的场景(普通状态、紧急状态)。
- 操作属性:指的是可进行的全部操作,如增删改查等。
当企业中参与权限管理的用户数量很多、或者角色数量很多时,传统的RBAC模型会显露出一些缺点,比如容易遗漏需要参与到权限管理的部分用户,并且容易受到“角色数量爆炸”的影响。RBAC虽然是目前最普遍的权限控制模型。
此时需要新的权限管理方法来控制对企业的访问,允许特定用户在特定场景下拥有特定权限。通常考虑的第一种解决方案是基于属性的访问控制(ABAC),会在系统中设置好基于用户属性、资源属性、环境属性和操作权限的预定义规则,当某个用户进入到系统中时,会获取用户和当前场景的属性,基于这些属性,自动为该用户分配权限。所以说,ABAC中可以完全自动化——可根据所获取到的属性进行自动判定和授权,而不需要使用管理员手动设置授权。
传统的 RBAC 与 ACL 等访问控制机制,可以认为是 ABAC 的子集。
优点:
可适用于用户数量和角色数量很多的权限管理场景,在设置好预定义规则之后,系统可对用户进行自动授权,不需要使用管理员手动设置授权。
缺点:
当采用ABAC模型时,随着属性数量的不断增加,定义与单个用户相关联的每个属性的复杂性也随之增加,从而增加了管理整个企业的访问管理的难度。需要IT团队部署和维护。
实现成本高:ABAC非常的灵活,但是实现比较困难。这其中涉及到逻辑的动态执行,数据动态过滤等,更加具体就是动态拼接SQL语句。
TBAC 基于任务(Task Based)
TBAC是基于任务的访问控制模型。它从工作流中的任务角度建模,可以依据任务和任务状态的不同,对权限进行动态管理。适用于工作流、分布式处理和事务管理系统中的决策制定与权限管理。
基于任务的访问控制(TBAC)是一种动态的访问控制策略,它根据执行任务的上下文环境来控制对象的访问权限。在TBAC中,对象的访问权限不是静止不变的,而是随着任务的执行而发生变化。这种策略的优点是能够根据任务的需求动态调整访问权限,提高了系统的灵活性和适应性。同时,由于任务与权限紧密相关联,可以更好地支持协同工作场景,提高工作效率。但缺点是需要对任务进行详细分析和定义,并建立相应的访问控制模型,增加了实施的难度和成本。
ETL(提取/转换/加载)
ETL(Extract Transform Load)(提取、转换、加载)指数据驱动型组织从多个来源收集数据,然后将数据集中起来以满足数据发现、报告、分析和决策需求的过程。
在 ETL 流程中,各种数据源的类型、格式、规模和可靠性可能大不相同,因此数据要经过处理才能供组织和用户使用。同时,面对不同的目标和技术实施条件,组织可能使用数据库、数据仓库或数据湖来存储目标数据。
ETL 的三个步骤
1、提取
在提取阶段,ETL 将识别数据并从数据源复制数据,以便将数据传输到目标数据存储。其中,数据源包括结构化数据源和非结构化数据源,例如文档、电子邮件、业务应用、数据库、设备、传感器、第三方等等。
2、转换
ETL 对上一步骤提取的原始格式的原始数据进行映射和转换,为最终数据存储做好准备。在转换过程中,ETL 将按照适当方式校验和验证数据,进行数据去重和/或聚合,确保数据可靠、可查询。
3、加载
ETL 将转换后的数据移动到目标数据存储。加载操作可分为两种,一种是初始加载所有源数据,另一种是加载源数据的增量变更。另外,您既可以实时加载数据,也可以按计划分批加载。
上一篇 面试准备09-微服务与dubbo
下一篇 面试准备07-Redis和缓存
页面信息
location:protocol: host: hostname: origin: pathname: href: document:referrer: navigator:platform: userAgent: