Kubernetes/K8S-基础
Kubernetes/K8S 使用笔记
Kubernetes 官方文档
https://kubernetes.io/docs/home/
https://kubernetes.io/zh/docs/home/
学习 Kubernetes 最权威的文档。Kubernetes 官网源码和文档本身就是在 GitHub 开源的,中文版文档由国内的大神在维护,翻译的还不错。默认查看的是最新版文档,一些老版本文档可能没有中文版。
《Docker — 从入门到实践》 – docker 中文白皮书
https://yeasy.gitbooks.io/docker_practice/content/
https://github.com/yeasy/docker_practice
Kubernetes Handbook——Kubernetes中文指南/云原生应用架构实践手册 - Jimmy Song(宋净超)云原生布道师
https://jimmysong.io/kubernetes-handbook/
从Docker到Kubernetes进阶 - 阳明的博客
https://www.qikqiak.com/k8s-book/
kubernetes | 中文社区
https://www.kubernetes.org.cn/
k8s 快速尝试:
https://www.katacoda.com/courses/kubernetes
概述
Kubernetes 是 Google 开源容器集群管理系统,提供应用部署、维护、 扩展机制等功能,利用 Kubernetes 能方便地管理跨机器运行容器化的应用,其主要功能如下:
- 使用 Docker 对应用程序包装 (package)、实例化 (instantiate)、运行 (run)。
- 以集群的方式运行、管理跨机器的容器。
- 解决 Docker 跨机器容器之间的通讯问题。
- Kubernetes 的自我修复机制使得容器集群总是运行在用户期望的状态。包括容器的自动启动、自动重调度以及自动备份。
Kubernetes 是为生产环境而设计的容器调度管理系统,对于负载均衡、服务发现、高可用、滚动升级、自动伸缩等容器云平台的功能要求有原生支持。
一个 K8S 集群是由分布式存储(etcd)、 Node 节点和 Master 节点构成的。所有的集群状态都保存在etcd中,Master节点上则运行集群的管理控制模块。
Node 节点是真正运行应用容器的主机节点,在每个 Node 节点上都会运行一个 Kubelet 代理,控制该节点上的容器、镜像和存储卷等。
基础组件功能
etcd
一个高可用的K/V键值对存储和服务发现系统
保存了整个集群的状态;
flannel
实现夸主机的容器网络的通信
apiserver
提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制;
controller manager
负责维护集群的状态,比如故障检测、自动扩展、滚动更新等;
scheduler
负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上;
kubelet
负责维护容器的生命周期,同时也负责Volume(CSI)和网络(CNI)的管理;
kubelet 是工作节点执行操作的 agent,负责具体的容器生命周期管理,根据从数据库中获取的信息来管理容器,并上报 pod 运行状态等;
container runtime
负责镜像管理以及Pod和容器的真正运行(CRI);
kube-proxy
负责为 Service 提供 cluster 内部的服务发现和负载均衡;
kube-proxy 是一个简单的网络访问代理,同时也是一个 Load Balancer。它负责将访问到某个服务的请求具体分配给工作节点上的 Pod(同一类标签)。
K8S中一些基本概念
Namespaces 名字空间
通过将系统内部的对象分配到不同的 Namespace 中,这些 namespace 之间可以完全隔离,也可以通过某种方式,让一个 namespace 中的 service 可以访问到其他的 namespace 中的服务。
Kubernetes 会创建四个初始名字空间:default 没有指明使用其它名字空间的对象所使用的默认名字空间kube-system Kubernetes 系统创建对象所使用的名字空间kube-public 这个名字空间是自动创建的,所有用户(包括未经过身份验证的用户)都可以读取它。 这个名字空间主要用于集群使用,以防某些资源在整个集群中应该是可见和可读的。 这个名字空间的公共方面只是一种约定,而不是要求。kube-node-lease 此名字空间用于与各个节点相关的租期(Lease)对象; 此对象的设计使得集群规模很大时节点心跳检测性能得到提升。
DaemonSet
确保全部(或者一些)Node 上运行一个 Pod 的副本。当有 Node 加入集群时,也会为他们新增一个 Pod 。当有 Node 从集群移除时,这些 Pod 也会被回收。删除DaemonSet 将会删除它创建的所有 Pod。
service和pod
service:服务,是一个虚拟概念,逻辑上代理后端pod。
pod生命周期短,状态不稳定,pod异常后新生成的pod ip会发生变化,之前pod的访问方式均不可达。通过service对pod做代理,service有固定的ip和port,ip:port组合自动关联后端pod,即使pod发生改变,kubernetes内部更新这组关联关系,使得service能够匹配到新的pod。
这样,通过service提供的固定ip,用户再也不用关心需要访问哪个pod,以及pod是否发生改变,大大提高了服务质量。
如果pod使用rc创建了多个副本,那么service就能代理多个相同的pod,通过kube-proxy,实现负载均衡
K8S三种IP及端口
Node IP: 节点设备的IP,如物理机,虚拟机等容器宿主的实际IP。
Node Port:服务对外(gateway)暴露的端口。
Pod IP: Pod 的IP地址,是根据网络组件的IP段进行分配的。
Pod Port:应用程序启动时监听的端口,即Tomcat或undertow容器监听端口,例如8080。
Service IP: Service的IP,是一个虚拟IP,仅作用于service对象,由k8s 管理和分配,需要结合service port才能使用,单独的IP没有通信功能,集群外访问需要一些修改。
Service Port:服务内部(K8S内部)使用的端口。
在K8S集群内部,node ip 、pod ip、 service ip的通信机制是由k8s制定的路由规则,不是IP路由,即K8S的Pod ip、 Service ip与外界网络不通。
使用K8S的好处
降低成本:利用docker的隔离机制,一个node上可以部署多个pod
方便接入:新项目接入不用单独申请ec2资源,由SE根据集群资源使用情况扩缩容;使用docker镜像,不用安装依赖
自动化运维:k8s自动检测pod的heath状态,检测不通后自动从service上摘除节点;pod崩溃后自动重启;node宕机后pod自动漂移;pod部署为滚动部署,理论上无宕机时间
list watch 机制
List-watch 是 K8S 统一的异步消息处理机制,保证了消息的实时性,可靠性,顺序性,性能等等,是其声明式 API 的实现基础。
Etcd 存储集群的数据信息,apiserver 作为统一入口,任何对数据的操作都必须经过 apiserver。
客户端(kubelet/scheduler/controller-manager) 通过 list-watch 监听 apiserver 中资源(pod/rs/rc等等)的 create,update和delete事件,并针对事件类型调用相应的事件处理函数。
list 就是列出资源列表,采用 http 短连接。
watch 就是监听资源的变化,采用 http 长连接。
watch 长连接基于 HTTP/1.1 的 分块传输编码(Chunked transfer encoding)实现。
当客户端调用 watch API 时,apiserver 在 response 的 HTTP Header 中设置 Transfer-Encoding 的值为 chunked 表示采用分块传输编码,客户端收到该信息后,便和服务端该链接,并等待下一个数据块,即资源的事件信息。
K8S的informer模块封装list-watch API,用户只需要指定资源,编写事件处理函数,AddFunc,UpdateFunc和DeleteFunc等。
Kubernetes 对象
Understanding Kubernetes Objects 理解 Kubernetes 对象
https://kubernetes.io/docs/concepts/overview/working-with-objects/kubernetes-objects/
https://kubernetes.io/zh/docs/concepts/overview/working-with-objects/kubernetes-objects/
Kubernetes 对象是 “目标性记录” ———— 旦创建对象,Kubernetes 系统将持续工作以确保对象存在。 通过创建对象,本质上是在告知 Kubernetes 系统,所需要的集群工作负载看起来是什么样子的, 这就是 Kubernetes 集群的 期望状态(Desired State)。
也就是说 Kubernetes 对象描述的是一种要达到的目标状态。
操作 Kubernetes 对象 —— 无论是创建、修改,或者删除 —— 需要使用 Kubernetes API。 比如,当使用 kubectl 命令行接口时,CLI 会执行必要的 Kubernetes API 调用, 也可以在程序中使用 客户端库直接调用 Kubernetes API。
对象规约(spec)与对象状态(status)
对象规约 spec 描述了希望对象达到的状态,即期望状态(Desired State)
对象状态 status 描述了对象的 当前状态(Current State),它是由 Kubernetes 系统和组件 设置并更新的。在任何时刻,Kubernetes 控制平面(control plane) 都一直积极地管理着对象的实际状态,以使之与期望状态相匹配。
使用yaml描述对象
创建 Kubernetes 对象时,必须提供对象的规约,用来描述该对象的期望状态, 以及关于对象的一些基本信息(例如名称)。 当使用 Kubernetes API 创建对象时(或者直接创建,或者基于kubectl), API 请求必须在请求体中包含 JSON 格式的信息。 大多数情况下,需要在 .yaml 文件中为 kubectl 提供这些信息。 kubectl 在发起 API 请求时,将这些信息转换成 JSON 格式。
比如下面的 yaml 配置描述了一个类型为 Deployment 的对象
apiVersion: apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2 # tells deployment to run 2 pods matching the template
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
使用类似于上面的 .yaml 文件来创建 Deployment 的一种方式是使用 kubectl 命令行接口(CLI)中的 kubectl apply 命令, 将 .yaml 文件作为参数。
例如kubectl apply -f https://k8s.io/examples/application/deployment.yaml --record
输出类似如下这样:
deployment.apps/nginx-deployment created
必须字段
在想要创建的 Kubernetes 对象对应的 .yaml 文件中,需要配置如下的字段:
apiVersion创建该对象所使用的 Kubernetes API 的版本kind想要创建的对象的类别metadata帮助唯一标识对象的一些数据,包括一个 name 字符串、UID 和可选的 namespace
你也需要提供对象的 spec 字段。 对象 spec 的精确格式对每个 Kubernetes 对象来说是不同的,包含了特定于该对象的嵌套字段。
Kubernetes API 参考 能够帮助我们找到任何我们想创建的对象的 spec 格式。
例如
pod spec 参数
https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.19/#podspec-v1-core
deployment spec 参数
https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.19/#deploymentspec-v1-apps
Kubernetes API
Kubernetes API 总览
https://kubernetes.io/zh/docs/reference/using-api/api-overview/
Kubernetes API v1.19 参考手册
https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.19/
声明式API
“声明式” 是和 “命令式” 相对的。
所谓“声明式”,指的就是我只需要提交一个定义好的 API 对象来 “声明” 所期望达到的最终状态是什么样子就可以了,系统会通过各种方式达到这种我们 “声明” 的状态。
而如果提交的是一个个命令,去指导怎么一步一步达到期望状态,这就是“命令式”了。
“命令式 API”接收的请求只能一个一个实现,否则会有产生冲突的可能;
“声明式API”一次能处理多个写操作,并且具备 Merge 能力。
举个例子,我们声明一个 Deployment 应该有 3 个副本,直接提交这个 Deployment 声明,让 k8s 自动给我们将此 Deployment 的 pod 个数维护成 3 个,可能原来有 0,1,2 个 pod 需要新建来达到 3 个,也可能原来有 4,5,6 等更多个需要删除 pod 来达到 3 个,但我们不用管当前是啥状态,我们只需告诉 k8s 我们需要他有 3 个 pod 即可。这就是“声明式”。
Container 容器
从零开始入门 K8s:理解 RuntimeClass 与使用多容器运行时
https://www.infoq.cn/article/Ov2o7E3L1UbkCbq1V7o5
Image 镜像
Images
https://kubernetes.io/docs/concepts/containers/images/
imagePullPolicy 何时拉取镜像?
如果没有显式设定的话,Pod 中所有容器的默认镜像 拉取策略是 IfNotPresent 这一策略会使得 kubelet 在镜像已经存在的情况下直接略过拉取镜像的操作。
典型的有两种场景需要关注这个配置项:
一、如果想强制总是拉取最新镜像,可以:
1、将 imagePullPolicy 属性设为 Always 强制总是拉取镜像
2、省略 imagePullPolicy 属性并使用 :latest 作为要使用的镜像的标签; Kubernetes 会将策略设置为 Always
3、省略 imagePullPolicy 和要使用的镜像标签。
4、启用 AlwaysPullImages 准入控制器(Admission Controller)。
二、如果想用不更新镜像,总是使用本地提前拉取好的固定镜像(典型场景就是离线环境网络不通,只能本地提前通过docker load准备镜像),可以:
提前导入镜像,将 imagePullPolicy 属性设为 IfNotPresent(默认也是这个)或 Never
设置为IfNotPresent还是每次拉取镜像?
环境:
无法连接公网的离线环境,3 节点的 k8s 集群,有 node1, node2, node3 三个节点,node1 是 master 节点,在 node1 上 docker load 导入了需要的镜像。
期望启动 k8s pod 时可以直接使用本地导入的镜像,不要通过网络去 pull 镜像。
现象:
在 node1 上 kubectl apply -f xx.yml 部署一个资源后,pod 无法启动,kubectl describe pod 显示 pull image 失败。
排查:
1、确认 xx.yml 中的镜像 tag 和 node1 上的本地镜像 tag 是一致的。
2、确认 imagePullPolicy 属性是 IfNotPresent, 会优先读取本地镜像。
3、可以使用本地镜像的前提 k8s 当前 node 节点的本地有这个 tag 的镜像,仔细观察失败 pod, 发现这个 pod 被调度到了 node2 上启动,node2 上是没有这个本地镜像的,所以会尝试 pull 镜像,由于是离线环境,pull image 总是失败。
解决:
在 node1, node2, node3 三个结点上都 docker load 提前导入需要的镜像。
RuntimeClass 容器运行时类
Runtime Class
https://kubernetes.io/docs/concepts/containers/runtime-class/
为了在 pod 上运行容器,k8s 需要 **容器运行时(Container runtimes)**,常用的容器运行时有
- docker 最流行的容器引擎。
- containerd containerd 是 docker 的一部分,后来单独从 docker 中分离出来开源了。
- CRI-O 一个实现了 OCI(Open Container Initiative) 开放容器标准 和 k8s CRI(Container Runtime Interface) 容器交互接口的容器运行时。可作为一个轻量级的容器运行时代替 docker 引擎。
k8s 使用 CRI(Container Runtime Interface) 即 容器运行时接口 和我们选择的容器运行时进行交互。
多容器运行时带来下列问题:
集群里有哪些可用的容器运行时?
如何为 Pod 选择合适的容器运行时?
如何让 Pod 调度到装有指定容器运行时的节点上?
为此,在 Kubernetes v1.12 中推出 RuntimeClass 容器运行时类,最初以 CRD 的形式引入。
v1.14 之后,它又作为一种内置集群资源对象 RuntimeClas 被引入进来。
v1.16 又在 v1.14 的基础上扩充了 Scheduling 和 Overhead 的能力。
RuntimeClass 是一个用于选择容器运行时配置的特性
RuntimeClass 资源定义示例如下:
apiVersion: node.k8s.io/v1 # RuntimeClass 定义于 node.k8s.io API 组
kind: RuntimeClass
metadata:
name: myclass # 用来引用 RuntimeClass 的名字
# RuntimeClass 是一个集群层面的资源
handler: myconfiguration # 对应的 CRI 配置的名称
RuntimeClass 资源当前只有两个重要的字段:RuntimeClass 名 (metadata.name) 和 handler (handler)
定义好 RuntimeClass 后,便可在定义 Pod 时指定所需的运行时类,例如
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
runtimeClassName: myclass
# ...
这一设置会告诉 kubelet 使用所指的 RuntimeClass 来运行该 pod. 如果所指的 RuntimeClass 不存在或者 CRI 无法运行相应的 handler, 那么 pod 将会进入 Failed 终止阶段。 你可以查看相应的事件, 获取执行过程中的错误信息。
如果未指定 runtimeClassName, 则将使用默认的 RuntimeHandler, 相当于禁用 RuntimeClass 功能特性。
Node 节点
Label 标签
Labels and Selectors 标签和选择算符
https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/
https://kubernetes.io/zh/docs/concepts/overview/working-with-objects/labels/
Label(标签)是 Kubernetes 系统中另外一个核心概念。一个Label是一个 key=value 的键值对,其中key与value由用户自己指定。Label可以被附加到各种资源对象上,例如Node、Pod、Service、RC等,一个资源对象可以定义任意数量的Label,同一个Label也可以被添加到任意数量的资源对象上。Label通常在资源对象定义时确定,也可以在对象创建后动态添加或者删除。
标签(Labels) 是附加到 Kubernetes 对象(比如 Pods)上的键值对。
一个对象可以有多个标签,一个标签也可以附加到多个对象上,但每个 key 对于给定对象必须是唯一的。
给某个资源定义一个标签,随后可以通过 label 进行查询和筛选 ,deployment 与 service 之间通过 label 来关联。
标签的语法和字符集
标签 是键值对。
有效的标签键有两个段:可选的前缀和名称,用斜杠(/)分隔。 名称段是必需的,必须小于等于 63 个字符,以字母数字字符([a-z0-9A-Z])开头和结尾, 带有破折号(-),下划线(_),点( .)和之间的字母数字。 前缀是可选的,如果指定,前缀必须是 DNS 子域:由点(.)分隔的一系列 DNS 标签,总共不超过 253 个字符, 后跟斜杠(/)。
如果省略前缀,则假定标签键对用户是私有的。 向最终用户对象添加标签的自动系统组件(例如 kube-scheduler、kube-controller-manager、 kube-apiserver、kubectl 或其他第三方自动化工具)必须指定前缀。
kubernetes.io/ 前缀是为 Kubernetes 核心组件保留的。
有效标签值必须为 63 个字符或更少,并且必须为空或以字母数字字符([a-z0-9A-Z])开头和结尾, 中间可以包含破折号(-)、下划线(_)、点(.)和字母或数字。
标签选择运算符
API 目前支持两种类型的选择算符:基于等值的 和 基于集合的。 标签选择算符可以由逗号分隔的多个 需求 组成。 在多个需求的情况下,必须满足所有要求,因此逗号分隔符充当逻辑 与 && 运算符。
等值运算符
基于等值 或 基于不等值 的需求允许按标签键和值进行过滤。 匹配对象必须满足所有指定的标签约束,尽管它们也可能具有其他标签。
可接受的运算符有 =, == 和 != 三种。 前两个表示 相等(并且只是同义词),而后者表示 不相等。
例如:environment = production 选择所有 environment 是 production 的资源。tier != frontend 选择所有 tier 不是 frontend 的资源。environment=production,tier!=frontend 选择 production 环境中 tier 不是 frontend 的资源。
等值选择经常用于给 Pod 指定运行的 node, 例如下面这个 pod 配置中用 nodeSelector 指定必须运行在 accelerator 是 nvidia-tesla-p100 的 node 上。
apiVersion: v1
kind: Pod
metadata:
name: cuda-test
spec:
containers:
- name: cuda-test
image: "k8s.gcr.io/cuda-vector-add:v0.1"
resources:
limits:
nvidia.com/gpu: 1
nodeSelector:
accelerator: nvidia-tesla-p100
集合运算符
基于集合 的标签需求允许你通过一组值来过滤键。 支持三种操作符:in, notin 和 exists (只可以用在 key 标识符上)。
例如:environment in (production, qa) 选择 environment 是 production 或 qa 的资源。tier notin (frontend, backend) 选择 tier 不是 frontend 或 backend 的资源,以及所有没有 tier 标签的资源。partition 选择所有带有 partition 标签的资源,不校验 partition 标签的值。!partition 选择所有不带 partition 标签的资源,不校验 partition 标签的值。partition, environment notin (qa) 选择带有 partition 标签,且 environment 不是 qa 的资源。
其实等值运算符都可以用集合运算符来代替,比如 environment=production 等于 environment in (production)
集合运算符和等值运算符可以一起使用,比如 partition in (customerA, customerB),environment!=qa
预定义系统标签
kubernetes.io/hostname
示例 kubernetes.io/hostname=ip-172-20-114-199.ec2.internal
用于:Node
Kubelet 用 hostname 值来填充该标签。注意:可以通过向 kubelet 传入 –hostname-override 参数对 “真正的” hostname 进行修改。
Pod 容器组
Pods 容器组
https://kubernetes.io/docs/concepts/workloads/pods/
https://kubernetes.io/zh/docs/concepts/workloads/pods/
Pod(中文官方叫法是“容器组”)是可以在 Kubernetes 中创建和管理的、最小的可部署的计算单元。
Pod 是 Kubernetes 创建及管理的最小的可部署的计算单元,一个 Pod 由一个或者多个容器组成,这些容器共享内存,网络以及运行容器的方式。
Pod 和 容器
在 kubernetes 里面,Pod 实际上正是 kubernetes 项目为你抽象出来的一个可以类比为进程组的概念。
一个 Pod 中可以有一个或多个容器
1、一个 Pod 中运行一个容器。“每个 Pod 中一个容器” 的模式是最常见的用法;在这种使用方式中,你可以把 Pod 想象成是单个容器的封装,kuberentes 管理的是 Pod 而不是直接管理容器。
2、在一个 Pod 中同时运行多个容器。一个 Pod 中也可以同时封装几个需要紧密耦合互相协作的容器,它们之间共享资源。这些在同一个 Pod 中的容器可以互相协作成为一个 service 单位 —— 一个容器共享文件,另一个 “sidecar” 容器来更新这些文件。Pod 将这些容器的存储资源作为一个实体来管理。
如何查看pod中有多少个容器?
kubectl get pod 输出结果中 READY 1/2 表示: 已就绪容器个数/pod中总容器个数
如何
使用Pod
通常不需要直接创建 Pod,甚至单实例 Pod。 相反,你会使用诸如 Deployment 或 Job 这类工作负载资源 来创建 Pod。如果 Pod 需要跟踪状态, 可以考虑 StatefulSet 资源。
Pod 生命周期
Pod Lifecycle
https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/
Pod Conditions
Pod Condition 是一组 pod 已经满足或还未满足的条件:
PodScheduledPod 已被调度到 node 上ContainersReadyPod 内的全部容器已经 ReadyInitialized所有 Init 容器已经完成ReadyPod 已准备好处理请求,应该被添加的对应 service 的 Endpoint 中。readinessProbe 就绪探针成功后变为 Ready=true 状态。
Pod 的几种状态
Pod 遵循一个预定义的生命周期,起始于 Pending 阶段,如果至少其中有一个主要容器正常启动,则进入 Running, 之后取决于 Pod 中是否有容器以失败状态结束而进入 Succeeded 或者 Failed 阶段。
pending
Pod 已被 Kubernetes 系统接受,但有一个或者多个容器尚未创建亦未运行。此阶段包括等待 Pod 被调度的时间和通过网络下载镜像的时间。
Pod 一直处于 Pending 状态如何排查?
如果 Pod 一直停留在 Pending 状态,意味着该 Pod 不能被调度到某一个节点上。通常,这是因为集群中缺乏足够的资源或者 “合适” 的资源。kubectl describe pod pod-name 查看 pod 详情,结果中的 Events 字段,会有对应的事件描述为什么 Pod 不能调度到节点上。
Debugging Pods
https://www.kuboard.cn/learning/k8s-advanced/ts/application.html#debugging-pods
running
Pod 已经绑定到了某个节点,Pod 中所有的容器都已被创建。至少有一个容器仍在运行,或者正处于启动或重启状态。
succeeded
Pod 中的所有容器都已成功终止,并且不会再重启。
failed
Pod 中的所有容器都已终止,并且至少有一个容器是因为失败终止。也就是说,容器以非 0 状态退出或者被系统终止。
unknown
因为某些原因无法取得 Pod 的状态。这种情况通常是因为与 Pod 所在主机通信失败。
CrashLoopBackOff
CrashloopBackOff 表示 pod 经历了 starting, crashing 然后再次 starting 并再次 crashing.
这个失败的容器会被 kubelet 不断重启,并且按照几何级数(exponentially)延迟(10s,20s,40s…)直到 5 分钟,最后一次是 10 分钟后重置。
可能造成 pod 出现 CrashLoopBackOff 状态的原因:
数据库无法连接应用启动失败导致CrashLoopBackOff
1、mysql 数据库连不上等原因导致 Springboot 应用起不来。
pid 1进程退出导致CrashLoopBackOff
2、容器中的主命令执行完立即退出,然后被不断重新拉起。
Docker 容器必须保持 PID 1 进程持续运行,否则容器就会退出(也就是主进程退出)。对于 Docker 而言 PID 1 进程退出就是容器停止,此时如果容器在 Kubernetes 中就会重启容器。
遇到这种情况是一个使用 tomcat war 包部署的老服务,pod 的主命令是一个 Python 启动脚本,Python 脚本执行完就退出了,无论他启动的 tomcat 是否还继续运行,后来给 Python 脚本最后加了死循环解决。
通过退出码Exit Code分析pod重启原因
Exit Codes in Containers and Kubernetes – The Complete Guide
https://komodor.com/learn/exit-codes-in-containers-and-kubernetes-the-complete-guide/
kubectl describe pods pod-name 看 pod 状态
13x Exit Code,是通过 128 + Linux SIG信号编码 得来的。
看 Last State 上一个状态的 Exit Code
- 退出代码 0:一般为容器正常退出,通常由于容器没有附加前台进程,不一定是错了,可能只是job类型的执行一次的容器。
- 退出代码 1:由于容器中 pid 为 1 的进程错误而失败
- 退出代码 134:容器收到 SIGABRT 信号退出,通常是内部遇到某种严重错误自己调用 abort() 结束了
- 退出代码 137:由于容器收到 SIGKILL(9) 信号而失败,可能是由于内存超限被 OOMkiller 杀掉,也可能是由于 Liveness probe 存活探针失败而被 k8s 重启。
- 退出代码 139:由于容器收到 SIGSEGV(11) 信号而失败,一般是代码有问题,访问了不属于自己的内存
- 退出代码 143:由于容器收到 SIGTERM(15) 信号而失败
根据经验,看这个 Exit Code 经常也看不出来之前容器的退出原因,还是得看 /var/log/messages 或 journalctl -k 系统日志
Exit Code 0 正常结束
Exit Code 0 Purposely stopped Used by developers to indicate that the container was automatically stopped
Last State: Terminated
Reason: Completed
Exit Code: 0
Started: Sat, 04 Dec 2021 02:55:23 +0800
Finished: Sun, 05 Dec 2021 14:56:58 +0800
Exit Code 134 SIGABRT
Exit Code 134 Abnormal termination (SIGABRT) The container aborted itself using the abort() function.
Last State: Terminated
Reason: Error
Exit Code: 134
Started: Tue, 28 Jun 2022 14:43:25 +0800
Finished: Tue, 28 Jun 2022 17:02:46 +0800
触发 SIGABRT 的原因:
- 进程本身调用了
libc库中的abort()函数 - 进程调用了调试用的
assert()断言宏并且结果为 false
Exit Code 137 SIGKILL
Exit Code 137 Immediate termination (SIGKILL) Container was immediately terminated by the operating system via SIGKILL signal
Last State: Terminated
Reason: Error
Exit Code: 137
Started: Tue, 11 Jan 2022 13:52:04 +0800
Finished: Tue, 11 Jan 2022 14:46:48 +0800
137 = 128 + 9(SIGKILL)
可能原因:
1、此状态码可能是因为 pod 中容器内存达到了它的资源限制(resources.limits),一般是内存溢出(OOM),CPU达到限制只需要不分时间片给程序就可以。因为限制资源是通过 linux 的 cgroup 实现的,所以 cgroup 会将此容器强制杀掉,类似于 kill -9
137 可能是由于内存不足导致,一般来说是由于容器内存占用超过了配置的 resources.limits.memory 导致被 OOMkiller 杀掉了,具体原因可以去系统日志查看,ubuntu 的系统日志在 /var/log/syslog,centos 的系统日志在 /var/log/messages,都可以用 journalctl -k 来查看系统日志
但是注意,137 并不一定都是资源不足被杀掉,如果是资源不足被杀掉,会有
Reason: OOMKilled
提示
https://stackoverflow.com/questions/59729917/kubernetes-pods-terminated-exit-code-137
2、也可能是由于 Liveness probe 存活探针失败而被 k8s 重启
曾经遇到过 137 Reason: Error,看最后的事件显示是由于存活探针失败导致 pod 被重启
Warning Unhealthy 3m26s (x16 over 8m11s) kubelet, node1 Liveness probe failed: dial tcp 11.16.39.88:8642: connect: connection refused
Normal Killing 3m26s (x2 over 6m26s) kubelet, node2 Container my-app failed liveness probe, will be restarted
Exit Code 139 SIGSEGV
Exit Code 139 Segmentation fault (SIGSEGV) Container attempted to access memory that was not assigned to it and was terminated
139 = 128 + 11(SIGSEGV)
表明容器收到了 SIGSEGV 信号,无效的内存引用,对应 kill -11
一般是代码有问题,或者 docker 的基础镜像有问题
Exit Code 143 SIGTERM
Exit Code 143 Graceful termination (SIGTERM) Container received warning that it was about to be terminated, then terminated
143 = 128 + 15(SIGTERM)
表明容器收到了 SIGTERM 信号,终端关闭,对应 kill -15
一般对应 docker stop 命令,有时 docker stop 也会导致 Exit Code 137。发生在与代码无法处理 SIGTERM 的情况下,docker 进程等待十秒钟然后发出 SIGKILL 强制退出。
容器探针
在 Kubernetes 上下文中存活探针和就绪探针被称作健康检查。这些容器探针是一些周期性运行的小进程,这些探针返回的结果(成功,失败或者未知)反映了容器在 Kubernetes 的状态。基于这些结果,Kubernetes 会判断如何处理每个容器,以保证弹性,高可用性和更长的正常运行时间。
Probe 探针相关参数:
initialDelaySeconds容器启动后要等待多少秒后才开始启动、存活和就绪探针。 如果定义了启动探针,则存活探针和就绪探针的延迟将在启动探针已成功之后才开始计算 如果 periodSeconds 的值大于 initialDelaySeconds,则 initialDelaySeconds 将被忽略。默认是 0 秒,最小值是 0。periodSeconds执行探测的时间间隔(单位是秒)。默认是 10 秒。最小值是 1。timeoutSeconds探测的超时后等待多少秒。默认值是 1 秒。最小值是 1。successThreshold探针在失败后,被视为成功的最小连续成功数。默认值是 1。 存活和启动探测的这个值必须是 1。最小值是 1。failureThreshold探针连续失败了 failureThreshold 次之后, Kubernetes 认为总体上检查已失败:容器状态未就绪、不健康、不活跃。 对于启动探针或存活探针而言,如果至少有 failureThreshold 个探针已失败, Kubernetes 会将容器视为不健康并为这个特定的容器触发重启操作。 kubelet 遵循该容器的 terminationGracePeriodSeconds 设置。 对于失败的就绪探针,kubelet 继续运行检查失败的容器,并继续运行更多探针; 因为检查失败,kubelet 将 Pod 的 Ready 状况设置为 false。terminationGracePeriodSeconds为 kubelet 配置从为失败的容器触发终止操作到强制容器运行时停止该容器之前等待的宽限时长。 默认值是继承 Pod 级别的 terminationGracePeriodSeconds 值(如果不设置则为 30 秒),最小值为 1。
针对运行中的容器,kubelet 可以选择是否执行以下三种探针,以及如何针对探测结果作出反应:
livenessProbe 存活探针(失败后kill)
livenessProbe 存活探针,指示容器是否正在运行。如果存活态探测失败,则 kubelet 会杀死容器,并且容器将根据其重启策略决定未来。如果容器不提供存活探针,则默认状态为 Success。
readinessProbe 就绪探针(失败后从svc摘除)
readinessProbe 就绪探针,指示容器是否准备好接受请求流量
如果就绪态探测失败,端点控制器(Endpoint Controller) 将从与 Pod 匹配的所有 服务(Service) 的 端点列表(Endpoints) 中删除该 Pod 的 IP 地址,Ready 状态被设为 false
初始延迟之前的就绪态的状态值默认为 Failure。
如果容器不提供就绪态探针,则默认状态为 Success。
就绪探针旨在让 Kubernetes 知道你的应用是否准备好为请求提供服务。Kubernetes 只有在就绪探针通过才会把流量转发到Pod。如果就绪探针检测失败,Kubernetes 将停止向该容器发送流量,直到它通过。
kubelet 使用就绪探针可以知道容器何时准备好接受请求流量,当一个 Pod 内的所有容器都就绪时,才能认为该 Pod 就绪。 这种信号的一个用途就是控制哪个 Pod 作为 Service 的后端。 若 Pod 尚未就绪,会被从 Service 的负载均衡器中剔除。
startupProbe 启动探针(失败后kill)
startupProbe 启动探针,指示容器中的应用是否已经启动。
如果提供了启动探针,则所有其他探针都会被禁用,直到此探针成功为止
如果启动探测失败,kubelet 将杀死容器,而容器依其 重启策略 进行重启。
如果容器没有提供启动探测,则默认状态为 Success。
startupProbe 在 1.16 版本引入
Kubernetes supports readiness and liveness probes for versions ≤ 1.15. Startup probes were added in 1.16 as an alpha feature and graduated to beta in 1.18
对于启动时间较长的pod,可以定义一个 failureThreshold * periodSeconds 周期较长的启动探针,加一个周期较短的存活探针,既可以兼容 pod 启动时间长,又不会因为将存活探针周期设置太长而导致不能及时发现 pod 无响应
例1
ports:
- name: liveness-port
containerPort: 8080
livenessProbe:
httpGet:
path: /healthz
port: liveness-port
failureThreshold: 1
periodSeconds: 10
startupProbe:
httpGet:
path: /healthz
port: liveness-port
failureThreshold: 30
periodSeconds: 10
pod 有最多 5 分钟(30 × 10 = 300s)的时间来完成其启动过程:
- 一旦启动探测成功一次,存活探测任务就会接管对容器的探测,对容器死锁作出快速响应(1 × 10秒钟)
- 如果启动探测一直没有成功,容器会在 300 秒后被杀死,并且根据 restartPolicy 来执行进一步处置
例2、三种探针配置实践
- 启动探针:初始延迟60秒,之后10秒探测一次 /ping,探测30次,总共给服务器启动预留360秒初始化时间,成功1次则认为启动成功,30次都失败则kill pod重启。
- 就绪探针:启动探针成功后,延迟5秒开始探测,5秒一次*3次,成功1次则加入svc的Endpoint。运行中会持续探测就绪状态,3次都失败将pod从svc的Endpoint摘除,继续探测。
- 存活探针:启动探针成功后,延迟5秒开始探测,5秒一次*8次,8次全失败则kill pod重启。
startupProbe:
httpGet:
path: /ping
port: 8080
initialDelaySeconds: 60
periodSeconds: 10
timeoutSeconds: 3
failureThreshold: 30
successThreshold: 1
readinessProbe:
httpGet:
path: /ping
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
timeoutSeconds: 15
failureThreshold: 3
successThreshold: 1
livenessProbe:
httpGet:
path: /ping
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
timeoutSeconds: 15
failureThreshold: 8
successThreshold: 1
Init 容器
Init Containers Init 容器
https://kubernetes.io/docs/concepts/workloads/pods/init-containers/
https://kubernetes.io/zh/docs/concepts/workloads/pods/init-containers/
Init 容器是一种特殊容器,在 Pod 内的应用容器启动之前运行,可以包括一些应用镜像中不存在的实用工具和安装脚本。
每个 Pod 中可以包含多个容器,应用运行在这些容器里面,同时 Pod 也可以有一个或多个先于应用容器启动的 Init 容器。
Init 容器与普通的容器非常像,除了如下两点:
- 它们总是运行到完成。
- 每个都必须在下一个启动之前成功完成。
所以:
- Init 容器不支持 lifecycle、livenessProbe、readinessProbe 和 startupProbe, 因为它们必须在 Pod 就绪之前运行完成。
- 如果为一个 Pod 指定了多个 Init 容器,这些容器会按顺序逐个运行。每个 Init 容器必须运行成功,下一个才能够运行。当所有的 Init 容器运行完成时, Kubernetes 才会为 Pod 初始化应用容器并像平常一样运行。
如果 Pod 的 Init 容器失败,Kubernetes 会不断地重启该 Pod,直到 Init 容器成功为止。 然而,如果 Pod 对应的 restartPolicy 值为 Never,Kubernetes 不会重新启动 Pod。
为 Pod 设置 Init 容器需要在 Pod 的 spec 中添加 initContainers 字段, 该字段以 Container 类型对象数组的形式组织,和应用的 containers 数组同级相邻。 Init 容器的状态在 status.initContainerStatuses 字段中以容器状态数组的格式返回 (类似 status.containerStatuses 字段)。
为什么需要init容器?
因为 Init 容器具有与应用容器分离的单独镜像,其启动相关代码具有如下优势:
- Init 容器可以包含一些安装过程中应用容器中不存在的实用工具或个性化代码。 例如,没有必要仅为了在安装过程中使用类似 sed、awk、python 或 dig 这样的工具而去 FROM 一个镜像来生成一个新的镜像。
- Init 容器可以安全地运行这些工具,避免这些工具导致应用镜像的安全性降低。
- 应用镜像的创建者和部署者可以各自独立工作,而没有必要联合构建一个单独的应用镜像。
- Init 容器能以不同于 Pod 内应用容器的文件系统视图运行。因此,Init 容器可以访问 应用容器不能访问的 Secret 的权限。
- 由于 Init 容器必须在应用容器启动之前运行完成,因此 Init 容器 提供了一种机制来阻塞或延迟应用容器的启动,直到满足了一组先决条件。 一旦前置条件满足,Pod 内的所有的应用容器会并行启动。
init 容器使用示例
1、等待一个 Service 完成创建,创建一个包含如下 shell 命令的 init 容器:
for i in {1..100}; do sleep 1; if dig myservice; then exit 0; fi; exit 1`
dig 目标 service 成功后 init 容器完成,再继续执行后续当前容器的启动。
2、注册这个 Pod 到远程服务器,通过在命令中调用 API,类似如下:
curl -X POST http://$MANAGEMENT_SERVICE_HOST:$MANAGEMENT_SERVICE_PORT/register \
-d 'instance=$(<POD_NAME>)&ip=$(<POD_IP>)'
3、在启动应用容器之前等一段时间,使用类似命令 sleep 60
4、克隆 Git 仓库到卷中。
5、将配置值放到配置文件中,运行模板工具为主应用容器动态地生成配置文件。 例如,在配置文件中存放 POD_IP 值,并使用 Jinja 生成主应用配置文件。
下面的例子定义了一个具有 2 个 Init 容器的简单 Pod。 第一个等待 myservice 启动, 第二个等待 mydb 启动。 一旦这两个 Init容器 都启动完成,Pod 将启动 spec 节中的应用容器。
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: busybox:1.28
command: ['sh', '-c', 'echo The app is running! && sleep 3600']
initContainers:
- name: init-myservice
image: busybox:1.28
command: ['sh', '-c', "until nslookup myservice.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for myservice; sleep 2; done"]
- name: init-mydb
image: busybox:1.28
command: ['sh', '-c', "until nslookup mydb.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for mydb; sleep 2; done"]
pause 容器
我们检查 node 节点的时候会发现每个 node 上都运行了很多的 pause 容器
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
55f9851b66d6 79dd6d6368e2 "/opt/bin/flanneld -…" 3 days ago Up 3 days k8s_kube-flannel_kube-flannel-ds-sfw7f_kube-system_466fe793-8578-4993-a3d3-d9215aeeb96c_287
cbb1745cd369 k8s.gcr.io/kube-proxy "/usr/local/bin/kube…" 5 days ago Up 5 days k8s_kube-proxy_kube-proxy-lpbnl_kube-system_fa15d31f-83d5-4bfa-93f3-fb4386116e79_0
a18a3f092784 k8s.gcr.io/pause:3.2 "/pause" 5 days ago Up 5 days k8s_POD_kube-proxy-lpbnl_kube-system_fa15d31f-83d5-4bfa-93f3-fb4386116e79_0
642b8c79bd6c k8s.gcr.io/pause:3.2 "/pause" 5 days ago Up 5 days k8s_POD_kube-flannel-ds-sfw7f_kube-system_466fe793-8578-4993-a3d3-d9215aeeb96c_0
kubernetes 中的 pause 容器主要为每个业务容器提供以下功能:
1、在 pod 中担任 Linux 命名空间共享的基础;
2、启用 pid 命名空间,开启 init 进程。
Pause容器
https://jimmysong.io/kubernetes-handbook/concepts/pause-container.html
配置
resources Pod和容器资源管理
Resource Management for Pods and Containers
https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/
GPU 这类不可超分资源必须指定 Limit
如果不指定 resources.limits,部署 deployment 报错:
The Deployment “xxx-deployment” is invalid: spec.template.spec.containers[0].resources.limits: Required value: Limit must be set for non overcommitable resources
spec:
containers:
- name: busybox
image: busybox
command: ['sh', '-c', 'tail -f /dev/null']
resources:
requests:
nvidia.com/gpu: 2
limits:
nvidia.com/gpu: 2
Kubernetes CPU 资源单位
在 Kubernetes 中,CPU 资源的表示方式如下:
- 带小数:例如 0.5 表示 0.5 核(即 500 毫核)。
- 不带单位:例如 1 表示 1 核(等价于 1000m)。
- 毫核(millicores):例如 1000m 表示 1 核,500m 表示 0.5 核。
Kubernetes 内存资源单位
Kubernetes 内存资源的表示支持多种单位格式,包括十进制(SI 标准)和二进制(IEC 标准)单位:
- 十进制 K, M, G,例如 500M, 64k, 5G, 1T,较少使用
- 二进制 Ki, Mi, Gi,例如 512Ki, 1Mi, 1Gi, 1Ti,推荐写法
- 无后缀 纯数字(字节),例如 134217728 不推荐(可读性差)
建议在 Kubernetes 中统一使用二进制单位(如 Mi、Gi),避免混淆
调度、抢占和驱逐
Scheduling, Preemption and Eviction 调度,抢占和驱逐
https://kubernetes.io/docs/concepts/scheduling-eviction/
将 Pod 分配到节点
将 Pod 分配到节点
https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/
可以限制 Pod 只在几个特定的 Node 上运行,要达到这个目的有好几种方式,推荐的是使用标签选择器。
nodeSelector
nodeSelector 是节点选择约束的最简单推荐形式。nodeSelector 是 PodSpec 的一个字段。 它包含键值对的映射。为了使 pod 可以在某个节点上运行,该节点的标签中必须包含这里的每个键值对(它也可以具有其他标签)。
nodeSelector 提供了一种非常简单的方法来将 pod 约束到具有特定标签的节点上。
例1、通过特定标签选择节点
第一步,给 node1 打上标签 disktype=ssd,执行 kubectl label nodes node1 disktype=ssd
之后可以通过 kubectl get nodes --show-labels 查看节点有哪些标签
第二步,pod spec 中增加 nodeSelector 选择指定标签的节点
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
nodeSelector:
disktype: ssd
例2、通过主机名选择固定的机器
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
nodeSelector:
node: my-centos
亲和与反亲和
亲和与反亲和比 nodeSelector 更加强大:
- 可以配置“软需求”/“偏好”,而不是硬性要求,因此,如果调度器无法满足该要求,仍然调度该 Pod
- 可以使用节点上(或其他拓扑域中)的 Pod 的标签来约束,而不是使用节点本身的标签,来允许哪些 pod 可以或者不可以被放置在一起。
节点亲和(代替nodeSelector)
节点亲和概念上类似于 nodeSelector,它使你可以根据节点上的标签来约束 pod 可以调度到哪些节点。
目前有两种类型的节点亲和:
requiredDuringSchedulingIgnoredDuringExecution硬亲和,指定了将 pod 调度到一个节点上必须满足的规则(就像 nodeSelector 但使用更具表现力的语法)preferredDuringSchedulingIgnoredDuringExecution软亲和,指定调度器将尝试执行但不能保证的偏好。
名称中的 IgnoredDuringExecution 部分意味着,类似于 nodeSelector 的工作原理,如果节点的标签在运行时发生变更,从而不再满足 pod 上的亲和规则,那么 pod 将仍然继续在该节点上运行。
节点亲和:指定node(代替nodeSelector)
如果想 pod 运行在固定的几台 node 上,推荐使用亲和性来指定,代替 nodeSelector
spec
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node1
- node2
节点亲和:必须运行在master节点上
affinity: |
#command
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: node-role.kubernetes.io/master
operator: Exists
Pod 间亲和与反亲和
Pod 间亲和性与反亲和性使你可以基于已经在节点上运行的 Pod 的标签来约束 Pod 可以调度到的节点,而不是基于节点上的标签。
与节点亲和性一样,当前有两种类型的 Pod 亲和性与反亲和性,即 requiredDuringSchedulingIgnoredDuringExecution 和 preferredDuringSchedulingIgnoredDuringExecution
Pod 间亲和性通过 PodSpec 中 affinity 字段下的 podAffinity 字段进行指定。 而 Pod 间反亲和性通过 PodSpec 中 affinity 字段下的 podAntiAffinity 字段进行指定。
指定节点亲和/反亲和时可以通过 topologyKey 来筛选 node。
原则上,topologyKey 可以是任何合法的标签键。出于性能和安全原因,topologyKey 有一些限制:
- 对于 Pod 亲和性而言,在 requiredDuringSchedulingIgnoredDuringExecution 和 preferredDuringSchedulingIgnoredDuringExecution 中,topologyKey 不允许为空。
- 对于 requiredDuringSchedulingIgnoredDuringExecution 要求的 Pod 反亲和性, 准入控制器 LimitPodHardAntiAffinityTopology 要求 topologyKey 只能是 kubernetes.io/hostname。如果你希望使用其他定制拓扑逻辑, 你可以更改准入控制器或者禁用之。
Pod 间反亲和:多个实例不要调度到同一个节点
下面是一个简单 redis Deployment 的 YAML 代码段,它有三个副本和选择器标签 app=store。 Deployment 配置了 PodAntiAffinity,用来确保调度器不会将副本调度到单个节点上。
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis-cache
spec:
selector:
matchLabels:
app: store
replicas: 3
template:
metadata:
labels:
app: store
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- store
topologyKey: "kubernetes.io/hostname"
containers:
- name: redis-server
image: redis:3.2-alpine
污点和容忍度
Taints and Tolerations 污点和容忍度
https://kubernetes.io/docs/concepts/scheduling-eviction/taint-and-toleration/
污点(Taints) 应用于 node, 使 node 可以排斥一类特定的 Pod。
容忍度(Tolerations) 应用于 pod, 允许(但并不要求)Pod 调度到带有与之匹配的污点的节点上。
污点和容忍度(Toleration)相互配合,可以用来避免 Pod 被分配到不合适的节点上。 每个节点上都可以应用一个或多个污点,这表示对于那些不能容忍这些污点的 Pod,是不会被该节点接受的。
使用kubectl taint给node加污点
一个污点(Taints) 包括 key, value 和 effect(效果),形式为 key=value:effect
注意:
1、effect 目前只能是 NoSchedule, PreferNoSchedule, NoExecute 三者之一,不能是别的值。
2、目前污点只能应用于 node
3、value 是可选的,没有 value 也可以。
例如kubectl taint nodes foo dedicated=special-user:NoSchedule 给节点 foo 增加一个污点,它的键名是 dedicated, 键值是 special-user, 效果是 NoSchedule。 这表示只有拥有和这个污点相匹配的容忍度的 Pod 才能够被分配到 foo 这个节点。
如果在节点 foo 上键是 dedicated, 效果是 NoSchedule 的污点已经存在,则其 value 被替换为 special-user
kubectl taint nodes foo dedicated:NoSchedule- 删除节点 foo 上键是 dedicated, 效果是 NoSchedule 的污点(如果有的话)。
kubectl taint nodes foo bar:NoSchedule 给节点 foo 加上一个键是 bar, 效果是 NoSchedule 的污点,此污点没有value。
在PodSpec中定义Pod的容忍度
容忍度是 Pod 的一种属性,可以在 Pod 的 spec 中定义 Pod 的容忍度。
例如,定义 operator 是 Equal 的容忍度
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "NoSchedule"
定义 operator 是 Exists 的容忍度
tolerations:
- key: "key"
operator: "Exists"
effect: "NoSchedule"
operator 的默认值是 Equal
例如带有容忍度的一个 Nginx Pod 描述
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
tolerations:
- key: "example-key"
operator: "Exists"
effect: "NoSchedule"
三种污点效果
1 NoSchedule 表示不会将 Pod 分配到该节点,但不会将已经在此节点上的 pod 驱逐。
2 PreferNoSchedule 这是“优化”或“软”版本的 NoSchedule —— 系统会 尽量 避免将 Pod 调度到存在其不能容忍污点的节点上, 但这不是强制的。
3 NoExecute 不会将 Pod 分配到该节点(如果 Pod 还未在节点上运行), 并且会将 Pod 从该节点驱逐(如果 Pod 已经在节点上运行)
通常情况下,如果给一个节点添加了一个 effect 值为 NoExecute 的污点, 则任何不能忍受这个污点的 Pod 都会马上被驱逐, 任何可以忍受这个污点的 Pod 都不会被驱逐。
此外,对于 NoExecute 的容忍度在配置时还可以指定额外的容忍时间参数 tolerationSeconds, 表示 这个 pod 只能容忍这个污点 tolerationSeconds 秒。
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
tolerationSeconds: 3600
这表示如果这个 Pod 正在运行,同时一个匹配的污点被添加到其所在的节点, 那么 Pod 还将继续在节点上运行 3600 秒,然后被驱逐。 如果在此之前上述污点被删除了,则 Pod 不会被驱逐。
污点与容忍匹配过程
一个容忍度和一个污点相“匹配”是指它们有一样的键名和效果,并且:
- 如果 operator 是
Exists(此时容忍度不能指定 value),或者 - 如果 operator 是
Equal, 则它们的 value 应该相等
存在两种特殊情况:
- 如果一个容忍度的 key 为空且 operator 为 Exists, 表示这个容忍度与任意的 key, value 和 effect 都匹配,即这个容忍度能容忍任意 taint。
- 如果 effect 为空,则可以与所有键名 key 的效果相匹配。
可以给一个节点添加多个污点,也可以给一个 Pod 添加多个容忍度设置。
Kubernetes 处理多个污点和容忍度的过程就像一个过滤器:从一个节点的所有污点开始遍历, 过滤掉那些 Pod 中存在与之相匹配的容忍度的污点。余下未被过滤的污点的 effect 值决定了 Pod 是否会被分配到该节点,特别是以下情况:
- 如果未被过滤的污点中存在至少一个 effect 值为
NoSchedule的污点, 则 Kubernetes 不会将 Pod 分配到该节点。 - 如果未被过滤的污点中不存在 effect 值为
NoSchedule的污点, 但是存在 effect 值为 PreferNoSchedule 的污点, 则 Kubernetes 会 尝试 将 Pod 分配到该节点。 - 如果未被过滤的污点中存在至少一个 effect 值为
NoExecute的污点, 则 Kubernetes 不会将 Pod 分配到该节点(如果 Pod 还未在节点上运行), 或者将 Pod 从该节点驱逐(如果 Pod 已经在节点上运行)。
基于NoExecute污点的驱逐
effect 值是 NoExecute 的污点会影响已经在节点上运行的 Pod:
- 如果 Pod 不能忍受 effect 值为 NoExecute 的污点,那么 Pod 将马上被驱逐
- 如果 Pod 能够忍受 effect 值为 NoExecute 的污点,但是在容忍度定义中没有指定 tolerationSeconds, 则 Pod 还会一直在这个节点上运行。
- 如果 Pod 能够忍受 effect 值为 NoExecute 的污点,而且指定了 tolerationSeconds, 则 Pod 还能在这个节点上继续运行这个指定的时间长度。
节点运行过程中,当某种条件为真时,节点控制器会自动给节点添加一个污点。当前内置的污点包括:node.kubernetes.io/not-ready 节点未准备好。这相当于节点状态 Ready 的值为 “False”。node.kubernetes.io/unreachable 节点控制器访问不到节点. 这相当于节点状态 Ready 的值为 “Unknown”。node.kubernetes.io/out-of-disk 节点磁盘耗尽。node.kubernetes.io/memory-pressure 节点存在内存压力。node.kubernetes.io/disk-pressure 节点存在磁盘压力。node.kubernetes.io/network-unavailable 节点网络不可用。node.kubernetes.io/unschedulable 节点不可调度。node.cloudprovider.kubernetes.io/uninitialized 如果 kubelet 启动时指定了一个 “外部” 云平台驱动, 它将给当前节点添加一个污点将其标志为不可用。在 cloud-controller-manager 的一个控制器初始化这个节点后,kubelet 将删除这个污点。
比如,一个使用了很多本地状态的应用程序在网络断开时,仍然希望停留在当前节点上运行一段较长的时间, 愿意等待网络恢复以避免被驱逐。在这种情况下,Pod 的容忍度可能是下面这样的:
tolerations:
- key: "node.kubernetes.io/unreachable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 6000
表示即使节点状态为 unknown, 这个 pod 也可以继续在此节点上运行 6000 秒。
最佳实践
通过污点和容忍度,可以灵活地让 Pod 避开 某些节点或者将 Pod 从某些节点驱逐。
1、专用节点:如果您想将某些节点专门分配给特定的一组用户使用,您可以给这些节点添加一个污点(即, kubectl taint nodes nodename dedicated=groupName:NoSchedule), 然后给这组用户的 Pod 添加一个相对应的 toleration。拥有上述容忍度的 Pod 就能够被分配到上述专用节点,同时也能够被分配到集群中的其它节点。
2、配备了特殊硬件的节点:在部分节点配备了特殊硬件(比如 GPU)的集群中, 我们希望不需要这类硬件的 Pod 不要被分配到这些特殊节点,以便为后继需要这类硬件的 Pod 保留资源。 要达到这个目的,可以先给配备了特殊硬件的节点添加 taint (例如 kubectl taint nodes nodename special=true:NoSchedule 或 kubectl taint nodes nodename special=true:PreferNoSchedule), 然后给使用了这类特殊硬件的 Pod 添加一个相匹配的 toleration。
给 pod 添加 tolerations 通常通过 准入控制器 来完成。
查看集群中全部节点的污点信息
kubectl get nodes | awk '{print $1}' | grep -v NAME |xargs kubectl describe node|egrep "Name:|Taints" |awk 'ORS=NR%2?FS:RS'
Name: node1 Taints: <none>
Name: node2 Taints: <none>
Name: node3 Taints: <none>
Pod 优先级和抢占
Pod Priority and Preemption
https://kubernetes.io/docs/concepts/scheduling-eviction/pod-priority-preemption/
Pod 可以有优先级。
优先级表示一个 Pod 相对于其他 Pod 的重要性。
如果一个 Pod 无法被调度,调度程序会尝试驱逐较低优先级的 Pod, 以使高优先级 Pod 可以被调度。
要使用优先级和抢占:
1、新增一个或多个 PriorityClass 优先级类
2、创建 Pod 并将其 priorityClassName 设置为新增的 PriorityClass。 当然你不需要直接创建 Pod;通常,你将会添加 priorityClassName 到集合对象(如 Deployment) 的 Pod 模板中。
Kubernetes 已经提供了 2 个 PriorityClass: system-cluster-critical 和 system-node-critical 用于确保始终优先调度关键组件。
PriorityClass 优先级类
PriorityClass 是一个无名称空间对象,它定义了从优先级类名称到优先级整数值的映射。 名称在 PriorityClass 对象元数据的 name 字段中指定。 值在必填的 value 字段中指定。值越大,优先级越高。 PriorityClass 对象的名称必须是有效的 DNS 子域名,并且它不能以 system- 为前缀。
PriorityClass 对象可以设置任何小于或等于 10 亿的 32 位整数值。 较大的数字是为通常不应被抢占或驱逐的关键的系统 Pod 所保留的。 集群管理员应该为这类映射分别创建独立的 PriorityClass 对象。
PriorityClass 还有两个可选字段:globalDefault 和 description。
globalDefault 字段表示这个 PriorityClass 的值应该用于没有 priorityClassName 的 Pod。 系统中只能存在一个 globalDefault 设置为 true 的 PriorityClass。 如果不存在设置了 globalDefault 的 PriorityClass, 则没有 priorityClassName 的 Pod 的优先级为零。
description 字段是一个任意字符串。 它用来告诉集群用户何时应该使用此 PriorityClass。
PriorityClass 与现有集群注意事项:
1、如果你升级一个已经存在的但尚未使用此特性的集群,该集群中已经存在的 Pod 的优先级等效于零。
2、添加一个将 globalDefault 设置为 true 的 PriorityClass 不会改变现有 Pod 的优先级。 此类 PriorityClass 的值仅用于添加 PriorityClass 后创建的 Pod。
3、如果你删除了某个 PriorityClass 对象,则使用被删除的 PriorityClass 名称的现有 Pod 保持不变, 但是你不能再创建使用已删除的 PriorityClass 名称的 Pod。
优先级类示例:
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "此优先级类应仅用于 XYZ 服务 Pod。"
节点压力驱逐
Node-pressure Eviction
https://kubernetes.io/docs/concepts/scheduling-eviction/node-pressure-eviction/
硬驱逐条件
硬驱逐条件没有宽限期。当达到硬驱逐条件时, kubelet 会立即杀死 pod,而不会正常终止以回收紧缺的资源。
可以使用 eviction-hard 标志来配置一组硬驱逐条件,例如 memory.available<1Gi
kubelet 具有以下默认硬驱逐条件:
memory.available<100Minodefs.available<10%imagefs.available<15%nodefs.inodesFree<5%(Linux 节点)
磁盘剩余1GB才驱逐
/var/lib/kubelet/config.yaml
如修改为如下,就是剩余 1GB 才开始驱逐
evictionHard:
nodefs.available: "1Gi"
imagefs.available: "2Gi"
evictionMinimumReclaim:
nodefs.available: "1Gi"
imagefs.available: "2Gi"
修改之后 systemctl restart kubelet
如果之前由于磁盘空间不足导致节点有 node.kubernetes.io/disk-pressure:NoSchedule 污点,重启后污点自动消失
镜像被删除
磁盘使用空间高于 85% 后,集群会在该节点打上污点 node.kubernetes.io/disk-pressure:NoSchedule,并触发k8s节点驱逐pod策略,pod被驱逐后,当前节点pod处于停止状态,同时image处于未使用状态,又引起未使用的镜像被删除。
Evicted Pod The node had condition: [DiskPressure]
现象:
发现某个服务存在大量处于 Evicted 状态的 pod
my-app-1 0/1 Evicted 0 5d1h <none> centos <none> <none>
kubectl describe pod my-app-1 看到如下信息
Status: Failed
Reason: Evicted
Message: Pod The node had condition: [DiskPressure].
原因:
触发了 k8s 节点由于磁盘压力过大而驱逐 pod 的机制, 默认阈值是 磁盘占用量超 85%
然后发现果然根目录磁盘使用率达到 85% 了
解决:释放磁盘空间。
The node was low on resource: ephemeral-storage
现象:
长时间压测某个服务,出现容器被驱逐,describe 信息:
Status: Failed
Reason: Evicted
Message: The node was low on resource: ephemeral-storage. Container mc was using 224344Ki, which exceeds its request of 0.
原因:
pod 本身的日志超出了 ephemeral storage 大小限制,默认 100m
{
"log-driver": "json-file",
"log-opts": {
"max-size": "100m",
"max-file": "5"
}
}
解决:
修改 /etc/docker/daemon.json
{
"log-driver": "json-file",
"log-opts": {
"max-size": "10m",
"max-file": "3",
"labels": "production_status",
"env": "os,customer"
}
}
Pods evicted with error “The node was low on resource: ephemeral-storage”
https://access.redhat.com/solutions/4367311
Configure logging drivers
https://docs.docker.com/config/containers/logging/configure/
Kubernetes jobs getting failed with ephemeral-storage issue
https://stackoverflow.com/questions/61053326/kubernetes-jobs-getting-failed-with-ephemeral-storage-issue
Deployment 部署
Deployments 部署
https://kubernetes.io/docs/concepts/workloads/controllers/deployment/
Deployment 是 Kubernetes 在 1.2 版本中引入的新概念,用于更好地解决 Pod 的编排问题,Deployment+ReplicaSet 用于替换之前的 ReplicationController(RC)
Deployment 是最常用的用于部署无状态服务的方式。Deployment 控制器使得您能够以声明的方式更新 Pod(容器组)和 ReplicaSet(副本集)。
Deployment 为 Pod 提供声明式更新。只需要在 Deployment 中描述您想要的目标状态是什么,Deployment controller 就会帮您将 Pod 和 ReplicaSet 的实际状态改变到您的目标状态。可以滚动升级和回滚应用,扩容和缩容。
以“声明”的方式管理 Pod 和 ReplicaSet,其本质是将一些特定场景的一系列运维步骤固化下来,以便快速准确无误的执行。
Deployment 特点:
- 适合无状态的应用
- pod之间没有顺序
- 所有pod共享存储
- pod名字包含随机数字
- service都有ClusterIP,可以负载均衡
更新策略
.spec.strategy 指定新 Pod 替换旧 Pod 时的更新策略.spec.strategy.type 可以是 Recreate 或 RollingUpdate,默认是 RollingUpdate
Recreate 重新创建
.spec.strategy.type==Recreate 在创建新 Pods 之前,所有现有的 Pods 会被 kill 掉。
RollingUpdate 滚动更新
.spec.strategy.type==RollingUpdate 采取滚动更新的方式更新 Pods。你可以指定 maxUnavailable 和 maxSurge 来控制滚动更新过程。
.spec.strategy.rollingUpdate.maxUnavailable 最大不可用 Pod 数/比例,可选字段,用来指定更新过程中不可用的 Pod 的个数上限。该值可以是绝对数字(例如 5),也可以是所需 Pods 的百分比(例如 10%)。百分比值会转换成绝对数并去除小数部分。 如果 maxSurge 为 0,则此值不能为 0。 默认值为 25%。
例如,当此值设置为 30% 时,滚动更新开始时会立即将旧 ReplicaSet 缩容到期望 Pod 个数的70%。 新 Pod 准备就绪后,可以继续缩容旧有的 ReplicaSet,然后对新的 ReplicaSet 扩容, 确保在更新期间可用的 Pods 总数在任何时候都至少为所需的 Pod 个数的 70%。
.spec.strategy.rollingUpdate.maxSurge 最大峰值,可选字段,用来指定可以创建的超出期望 Pod 个数的 Pod 数量。此值可以是绝对数(例如 5)或所需 Pods 的百分比(例如 10%)。 如果 MaxUnavailable 为 0,则此值不能为 0。百分比值会通过向上取整转换为绝对数。 此字段的默认值为 25%。
例如,当此值为 30% 时,启动滚动更新后,会立即对新的 ReplicaSet 扩容,同时保证新旧 Pod 的总数不超过所需 Pod 总数的 130%。一旦旧 Pods 被 kill,新的 ReplicaSet 可以进一步扩容, 同时确保更新期间的任何时候运行中的 Pods 总数最多为所需 Pods 总数的 130%。
DaemonSet 守护集
DaemonSet 保证集群的每个节点上运行一个Pod,且只有一个Pod,每当有新的节点被加入到集群时,Pod 就会在目标的节点上启动,如果节点被从集群中剔除,节点上的 Pod 也会被垃圾收集器清除
DaemonSet 的作用就像是计算机中的守护进程,它非常适合一些系统应用,比如集群存储、日志收集和监控等『守护进程』,一个比较好的例子就是 Kubernetes 的 kube-proxy
DaemonSet 没有 Deployment 或 StatefulSet 中的 replicas 参数,因为是每个节点固定一个,无需指定副本数。
DaemonSet 也可以指定 nodeSelector 节点亲和,只在满足条件的 node 上启副本。
StatefulSet 状态集
StatefulSets
https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/
StatefulSet 是用来管理有状态应用的工作负载 API 对象。
StatefulSet 用来管理某 Pod 集合的部署和扩缩,并为这些 Pod 提供持久存储和持久标识符。
和 Deployment 类似, StatefulSet 管理基于相同容器规约的一组 Pod。但和 Deployment 不同的是, StatefulSet 为它们的每个 Pod 维护了一个有粘性的 ID。这些 Pod 是基于相同的规约来创建的, 但是不能相互替换:无论怎么调度,每个 Pod 都有一个永久不变的 ID。
StatefulSet 状态集适用于部署有状态的服务,比如带存储的 MySQL, Redis 等。
Deployment 适用于部署无状态的可任意扩缩的服务,比如各种 SpringBoot 微服务。
StatefulSet 特点:
- Pod 部署、扩展、更新、删除都要有顺序
- 每个pod都有自己存储,所以都用volumeClaimTemplates,为每个pod都生成一个自己的存储,保存自己的状态
- pod名字始终是固定的,从数字 0 开始递增
- service 没有 ClusterIP,是 headlessservice,所以无法负载均衡,返回的都是 pod 名,所以 pod 名字都必须固定,StatefulSet 在 Headless Service 的基础上又为 StatefulSet 控制的每个 Pod 副本创建了一个 DNS 域名:
$(podname).(headless server name).namespace.svc.cluster.local
注意:
1、给定 Pod 的存储必须由 PersistentVolume 基于所请求的 storage class 来提供,或者由管理员预先提供。
2、删除或者收缩 StatefulSet 并不会删除它关联的存储卷。 这样做是为了保证数据安全,众所周知,数据安全比收缩容器节省的那点儿资源要有价值的多。
状态集定义示例:
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx # has to match .spec.template.metadata.labels
serviceName: "nginx"
replicas: 3 # by default is 1
template:
metadata:
labels:
app: nginx # has to match .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx
image: k8s.gcr.io/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "my-storage-class"
resources:
requests:
storage: 1Gi
1、创建了名为 web 的状态集,声明了 3 个副本。
2、创建了名为 nginx 的 Headless Service 用来控制网络域名。
volumeClaimTemplates 卷申领模板
volumeClaimTemplates 列出需要使用的持久化存储。
实际上 volumeClaimTemplates 下面就是一个 PVC 对象的模板,我们不单独创建成 PVC 对象,而用这种模板就可以动态的去创建了对象了,这种方式在 StatefulSet 类型的服务下面使用得非常多。
ReplicationController(RC) 副本控制器
ReplicationController 副本控制器
https://kubernetes.io/docs/concepts/workloads/controllers/replicationcontroller/
https://kubernetes.io/zh/docs/concepts/workloads/controllers/replicationcontroller/
注意:Kubernetes 1.2 之后,推荐使用配置 ReplicaSet 的 Deployment 来进行 Pod 编排。
ReplicationController 确保在任何时候都有特定数量的 Pod 副本处于运行状态。 换句话说,ReplicationController 确保一个 Pod 或一组同类的 Pod 总是可用的。
当 Pod 数量过多时,ReplicationController 会终止多余的 Pod。当 Pod 数量太少时,ReplicationController 将会启动新的 Pod。 与手动创建的 Pod 不同,由 ReplicationController 创建的 Pod 在失败、被删除或被终止时会被自动替换。 例如,在中断性维护(如内核升级)之后,你的 Pod 会在节点上重新创建。 因此,即使你的应用程序只需要一个 Pod,你也应该使用 ReplicationController 创建 Pod。 ReplicationController 类似于进程管理器,但是 ReplicationController 不是监控单个节点上的单个进程,而是监控跨多个节点的多个 Pod。
在讨论中,ReplicationController 通常缩写为 “rc”,并作为 kubectl 命令的快捷方式。
与所有其它 Kubernetes 对象配置一样,ReplicationController 需要 apiVersion、kind 和 metadata 字段。
此外,RC 定义必须包含以下几部分:.spec.replicas Pod 副本个数
Pod 期待的副本数量。如果你没有指定 .spec.replicas, 那么它默认是 1。
.spec.selector Pod 选择器
用于筛选目标 Pod 的 Label Selector。ReplicationController 将管理标签与选择算符匹配的所有 Pod。
它不区分是它自己创建的还是其他进程创建的 Pod。
如果指定了 .spec.template.metadata.labels, 它必须和 .spec.selector 相同,否则它将被 API 拒绝。
如果没有指定 .spec.selector, 它将默认为 .spec.template.metadata.labels
注意:最好不要出现创建了多个控制器并且其选择算符之间存在重叠的情况,否则结果可能无法预料。
.spec.template Pod 模板
当 Pod 的副本数量小于预期数量时,用于创建新 Pod 的模板。.spec.template 是 RC 的 spec 的唯一必需字段。.spec.template 是一个 Pod 模板。 它的模式与 Pod 完全相同,只是它是嵌套的,没有 apiVersion 或 kind 属性。
除了 Pod 所需的字段外,ReplicationController 中的 Pod 模板必须指定适当的标签和适当的重新启动策略。
ReplicaSet 副本集
ReplicaSet 副本集
https://kubernetes.io/docs/concepts/workloads/controllers/replicaset/
https://kubernetes.io/zh/docs/concepts/workloads/controllers/replicaset/
ReplicaSet 的目的是维护一组在任何时候都处于运行状态的 Pod 副本(实例)的稳定集合。 因此,它通常用来保证给定数量的、完全相同的 Pod 的可用性。
ReplicaSet 副本集的主要几个字段有:
- selector 确定哪些 Pod 属于该副本集
- replicas 副本集应该维护几个 Pod 副本(实例)
- template Pod 的定义
副本集将通过创建、删除 Pod 容器组来确保符合 selector 选择器的 Pod 数量等于 replicas 指定的数量。当符合 selector 选择器的 Pod 数量不够时,副本集通过使用 template 中的定义来创建 Pod。
在 Kubernetes 中,并不建议您直接使用 ReplicaSet,推荐使用 Deployment,由 Deployment 创建和管理 ReplicaSet。
ReplicaSet 确保任何时间都有指定数量的 Pod 副本在运行。 然而,Deployment 是一个更高级的概念,它管理 ReplicaSet,并向 Pod 提供声明式的更新以及许多其他有用的功能。 因此,我们建议使用 Deployment 而不是直接使用 ReplicaSet,除非您需要自定义更新业务流程或根本不需要更新。
这实际上意味着,您可能永远不需要操作 ReplicaSet 对象:而是使用 Deployment,并在 spec 部分定义您的应用。
Job 任务
Job 会创建一个或者多个 Pods, 并将继续重试 Pods 的执行,直到指定数量的 Pods 成功终止。 随着 Pods 成功结束,Job 跟踪记录成功完成的 Pods 个数。 当数量达到指定的成功个数阈值时,任务(即 Job)结束。 删除 Job 的操作会清除所创建的全部 Pods。 挂起 Job 的操作会删除 Job 的所有活跃 Pod,直到 Job 被再次恢复执行。
Job 示例
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4
Custom Resources 定制资源
Custom Resources
https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/custom-resources/
定制资源(Custom Resource) 是对 Kubernetes API 的扩展,不一定在默认的 Kubernetes 安装中就可用。定制资源所代表的是对特定 Kubernetes 安装的一种定制。 不过,很多 Kubernetes 核心功能现在都用定制资源来实现,这使得 Kubernetes 更加模块化。
定制资源可以通过动态注册的方式在运行中的集群内或出现或消失,集群管理员可以独立于集群 更新定制资源。一旦某定制资源被安装,用户可以使用 kubectl 来创建和访问其中的对象,就像他们为 pods 这种内置资源所做的一样。
就定制资源本身而言,它只能用来存取结构化的数据。 当你将定制资源与 定制控制器(Custom Controller) 相结合时,定制资源就能够 提供真正的 声明式 API(Declarative API)。
使用声明式 API,你可以 声明 或者设定你的资源的期望状态,并尝试让 Kubernetes 对象的当前状态 同步到其期望状态。控制器负责将结构化的数据解释为用户所期望状态的记录,并 持续地维护该状态。
CustomResourceDefinitions(CRD) 定制资源定义
CustomResourceDefinition API 资源允许你定义定制资源。
定义 CRD 对象的操作会使用你所设定的名字和模式定义(Schema)创建一个新的定制资源, Kubernetes API 负责为你的定制资源提供存储和访问服务。
CRD 对象的名称必须是合法的 DNS 子域名。
当创建新的 CustomResourceDefinition(CRD) 时,Kubernetes API 服务器会为你所 指定的每一个版本生成一个 RESTful 的 资源路径。
CRD 可以是名字空间作用域的,也可以 是集群作用域的,取决于 CRD 的 scope 字段设置。和其他现有的内置对象一样,删除 一个名字空间时,该名字空间下的所有定制对象也会被删除。CustomResourceDefinition 本身是不受名字空间限制的,对所有名字空间可用。
CRD 示例:
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
# 名字必需与下面的 spec 字段匹配,并且格式为 '<名称的复数形式>.<组名>'
name: crontabs.stable.example.com
spec:
# 组名称,用于 REST API: /apis/<组>/<版本>
group: stable.example.com
# 列举此 CustomResourceDefinition 所支持的版本
versions:
- name: v1
# 每个版本都可以通过 served 标志来独立启用或禁止
served: true
# 其中一个且只有一个版本必需被标记为存储版本
storage: true
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
cronSpec:
type: string
image:
type: string
replicas:
type: integer
# 可以是 Namespaced 或 Cluster
scope: Namespaced
names:
# 名称的复数形式,用于 URL:/apis/<组>/<版本>/<名称的复数形式>
plural: crontabs
# 名称的单数形式,作为命令行使用时和显示时的别名
singular: crontab
# kind 通常是单数形式的驼峰编码(CamelCased)形式。你的资源清单会使用这一形式。
kind: CronTab
# shortNames 允许你在命令行使用较短的字符串来匹配资源
shortNames:
- ct
将上面的 yaml 保存为 resourcedefinition.yaml, 执行 kubectl apply -f resourcedefinition.yaml 即可创建这个 CRD
之后会在 /apis/stable.example.com/v1/namespaces/*/crontabs/... 创建这个新的受名字空间约束的 RESTful API 端点
此端点 URL 自此可以用来创建和管理定制对象。对象的 kind 是自上面创建时 spec 中指定的 CronTab
使用CRD创建定制对象
Extend the Kubernetes API with CustomResourceDefinitions
https://kubernetes.io/docs/tasks/extend-kubernetes/custom-resources/custom-resource-definitions/
例如,创建一个 kind 是 CronTab 的定制对象:
apiVersion: "stable.example.com/v1"
kind: CronTab
metadata:
name: my-new-cron-object
spec:
cronSpec: "* * * * */5"
image: my-awesome-cron-image
Operator
Operator pattern
https://kubernetes.io/docs/concepts/extend-kubernetes/operator/
Kubernetes Operator 是一种封装、部署和管理 Kubernetes 应用的方法。
Operator 利用 Custom Resources(CR) 自定义资源管理应用及其组件,Operator 遵循 k8s 的控制循环(即比较目标状态和当前状态,如果还未达到目标状态就不断循环尝试)。
Operator 的本意是为了模仿运维人员(Operator) 部署服务时的流程,设定部署目标,然后就不断尝试的去达到这个目标。也是一种声明式模式。
Volume 卷
Volume
https://kubernetes.io/docs/concepts/storage/volumes/
卷是 k8s 存储中的基本概念。
卷的核心是一个目录,其中可能存有数据,Pod 中的容器可以访问该目录中的数据。所采用的特定的卷类型将决定该目录如何形成的、使用何种介质保存数据以及目录中存放的内容。
卷分为临时卷和持久卷。临时卷类型的生命周期与 Pod 相同,当 Pod 不再存在时,Kubernetes 也会销毁临时卷;持久卷可以比 Pod 的存活期长,Kubernetes 不会在 Pod 停止时销毁持久卷。对于给定 Pod 中任何类型的卷,在容器重启期间数据都不会丢失。
使用卷时, 在 .spec.volumes 字段中设置为 Pod 提供的卷,并在 .spec.containers[*].volumeMounts 字段中声明卷在容器中的挂载位置。
容器中的进程看到的是由它们的 Docker 镜像和卷组成的文件系统视图。 Docker 镜像位于文件系统层次结构的根部。各个卷则挂载在镜像内的指定路径上。 卷不能挂载到其他卷之上,也不能与其他卷有硬链接。 Pod 配置中的每个容器必须独立指定各个卷的挂载位置。
hostPath 宿主机路径卷
宿主机路径,将宿主机文件系统上的路径做为存储卷挂载至 Pod 容器中。Pod 删除后,此存储卷不会被删除,数据不会丢失。
注意:在跨节点调度时,必须保证每个节点主机上的相同路径有相同的数据。
支持的 type 值如下:
`` 空字符串(默认)用于向后兼容,这意味着在安装 hostPath 卷之前不会执行任何检查。DirectoryOrCreate 如果在给定路径上什么都不存在,那么将根据需要创建空目录,权限设置为 0755,具有与 kubelet 相同的组和属主信息。Directory 在给定路径上必须存在的目录。FileOrCreate 如果在给定路径上什么都不存在,那么将在那里根据需要创建空文件,权限设置为 0644,具有与 kubelet 相同的组和所有权。FileOrCreate 模式不会负责创建文件的父目录。 如果欲挂载的文件的父目录不存在,Pod 启动会失败。File 在给定路径上必须存在的文件。Socket 在给定路径上必须存在的 UNIX 套接字。CharDevice 在给定路径上必须存在的字符设备。BlockDevice 在给定路径上必须存在的块设备。
hostPath 卷示例:
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: k8s.gcr.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /test-pd
name: test-volume
volumes:
- name: test-volume
hostPath:
# 宿主上目录位置
path: /data
# 此字段为可选
type: Directory
persistentVolumeClaim PVC卷
persistentVolumeClaim 卷用来将持久卷(PersistentVolume) 挂载到 Pod 中。
持久卷申领(PersistentVolumeClaim)是用户在不知道特定云环境细节的情况下”申领”持久存储 (例如 GCE PersistentDisk 或者 iSCSI 卷)的一种方法。
emptyDir
https://kubernetes.io/docs/concepts/storage/volumes/#emptydir
PersistentVolume(PV) 持久卷
Persistent Volumes
https://kubernetes.io/docs/concepts/storage/persistent-volumes/
持久卷(PersistentVolume, PV)是集群中的一块存储,可以由管理员事先供应,或者使用 存储类(Storage Class) 来动态供应。 持久卷是集群资源,就像节点也是集群资源一样。PV 持久卷和普通的 Volume 一样,也是使用卷插件来实现的,只是它们拥有独立于任何使用 PV 的 Pod 的生命周期。 此 API 对象中记述了存储的实现细节,无论其背后是 NFS、iSCSI 还是特定于云平台的存储系统。
持久卷申领(PersistentVolumeClaim, PVC) 表达的是用户对存储的请求。概念上与 Pod 类似。 Pod 会耗用节点资源,而 PVC 申领会耗用 PV 资源。Pod 可以请求特定数量的资源(CPU 和内存);同样 PVC 申领也可以请求特定的大小和访问模式 (例如,可以要求 PV 卷能够以 ReadWriteOnce、ReadOnlyMany 或 ReadWriteMany 模式之一来挂载)的 PV 资源。
PV 卷是集群中的资源。PVC 申领是对这些资源的请求,也被用来执行对资源的申领检查
KUBERNETES存储之PERSISTENT VOLUMES简介
https://www.cnblogs.com/styshoo/p/6731425.html
PV和PVC的生命周期
持久卷的供应(Provisioning)
PV 卷的供应有两种方式:静态供应或动态供应。
静态供应
集群管理员创建若干 PV 卷。这些卷对象带有真实存储的细节信息,并且对集群 用户可用(可见)。PV 卷对象存在于 Kubernetes API 中,可供用户消费(使用)。
动态供应(StorageClass)
如果管理员所创建的所有静态 PV 卷都无法与用户的 PersistentVolumeClaim 匹配, 集群可以尝试为该 PVC 申领动态供应一个存储卷。动态供应操作是基于 StorageClass 来实现的:PVC 申领必须请求某个存储类,同时集群管理员必须已经创建并配置了该类,这样动态供应卷的动作才会发生。如果 PVC 申领指定存储类为 “”,则相当于为自身禁止使用动态供应的卷。
为了基于存储类完成动态的存储供应,集群管理员需要在 API 服务器上启用 DefaultStorageClass 准入控制器。 举例而言,可以通过保证 DefaultStorageClass 出现在 API 服务器组件的 --enable-admission-plugins 标志值中实现这点;该标志的值可以是逗号 分隔的有序列表。关于 API 服务器标志的更多信息,可以参考 kube-apiserver 文档。
绑定(Binding)
用户创建一个带有特定存储容量和特定访问模式需求的 PersistentVolumeClaim 对象; 在动态供应场景下,这个 PVC 对象可能已经创建完毕。 主控节点中的控制回路监测新的 PVC 对象,寻找与之匹配的 PV 卷(如果可能的话), 并将二者绑定到一起。 如果为了新的 PVC 申领动态供应了 PV 卷,则控制回路总是将该 PV 卷绑定到这一 PVC 申领。 用户总是能够获得他们所请求的资源,只是所获得的 PV 卷可能会超出所请求的配置。 一旦绑定关系建立,则 PersistentVolumeClaim 绑定就是排他性的,无论该 PVC 申领是 如何与 PV 卷建立的绑定关系。 PVC 申领与 PV 卷之间的绑定是一种一对一的映射,实现上使用 ClaimRef 来记述 PV 卷 与 PVC 申领间的双向绑定关系。
如果找不到匹配的 PV 卷,PVC 申领会无限期地处于未绑定(unbound)状态。 当与之匹配的 PV 卷可用时,PVC 申领会被绑定。 例如,即使某集群上供应了很多 50 Gi 大小的 PV 卷,也无法与请求 100 Gi 大小的存储的 PVC 匹配。当新的 100 Gi PV 卷被加入到集群时,该 PVC 才有可能被绑定。
使用PVC作为卷
Pod 将 PVC 申领当做存储卷来使用。集群会检视 PVC 申领,找到所绑定的卷,并为 Pod 挂载该卷。对于支持多种访问模式的卷,用户要在 Pod 中以卷的形式使用申领 时指定期望的访问模式。
一旦用户有了申领对象并且该申领已经被绑定,则所绑定的 PV 卷在用户仍然需要它期间一直属于该用户。用户通过在 Pod 的 volumes 块中包含 persistentVolumeClaim 节区来调度 Pod,访问所申领的 PV 卷。
Pod 将 PVC 持久卷申领作为卷来使用,并藉此访问存储资源。 申领必须位于使用它的 Pod 所在的同一名字空间内。 集群在 Pod 的名字空间中查找申领,并使用它来获得申领所使用的 PV 卷。 之后,卷会被挂载到宿主上并挂载到 Pod 中。
Pod 使用 PVC 作为卷示例:
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: myfrontend
image: nginx
volumeMounts:
- mountPath: "/var/www/html"
name: mypd
volumes:
- name: mypd
persistentVolumeClaim:
claimName: myclaim
保护使用中的存储对象
保护使用中的存储对象(Storage Object in Use Protection)这一功能特性的目的 是确保仍被 Pod 使用的 PersistentVolumeClaim(PVC) 对象及其所绑定的 PersistentVolume(PV) 对象在系统中不会被删除,因为这样做可能会引起数据丢失。
说明: 当使用某 PVC 的 Pod 对象仍然存在时,认为该 PVC 仍被此 Pod 使用。
如果用户删除被某 Pod 使用的 PVC 对象,该 PVC 申领不会被立即移除。 PVC 对象的移除会被推迟,直至其不再被任何 Pod 使用。 此外,如果管理员删除已绑定到某 PVC 申领的 PV 卷,该 PV 卷也不会被立即移除。 PV 对象的移除也要推迟到该 PV 不再绑定到 PVC。
你可以看到当 PVC 的状态为 Terminating 且其 Finalizers 列表中包含 kubernetes.io/pvc-protection 时,PVC 对象是处于被保护状态的。
回收(Reclaiming)
当用户不再使用其存储卷时,他们可以从 API 中将 PVC 对象删除,从而允许 该资源被回收再利用。PersistentVolume 对象的回收策略告诉集群,当其被 从申领中释放时如何处理该数据卷。 目前,数据卷的回收策略有:Retain(保留)、Recycle(回收)或 Delete(删除)。
保留(Retain)
回收策略 Retain 使得用户可以手动回收资源。当 PersistentVolumeClaim 对象 被删除时,PersistentVolume 卷仍然存在,对应的数据卷被视为”已释放(released)”。 由于卷上仍然存在着前一申领人的数据,该卷还不能用于其他申领。
管理员可以通过下面的步骤来手动回收该卷:
1、删除 PersistentVolume 对象。与之相关的、位于外部基础设施中的存储资产 (例如 AWS EBS、GCE PD、Azure Disk 或 Cinder 卷)在 PV 删除之后仍然存在。
2、根据情况,手动清除所关联的存储资产上的数据。
3、手动删除所关联的存储资产;如果你希望重用该存储资产,可以基于存储资产的 定义创建新的 PersistentVolume 卷对象。
删除(Delete)
对于支持 Delete 回收策略的卷插件,删除动作会将 PersistentVolume 对象从 Kubernetes 中移除,同时也会从外部基础设施(如 AWS EBS、GCE PD、Azure Disk 或 Cinder 卷)中移除所关联的存储资产。
动态供应的卷会继承其 StorageClass 中设置的回收策略,该策略默认 为 Delete。 管理员需要根据用户的期望来配置 StorageClass;否则 PV 卷被创建之后必须要被编辑或者修补。
回收(Recycle)
警告: 回收策略 Recycle 已被废弃。取而代之的建议方案是使用动态供应。
如果下层的卷插件支持,回收策略 Recycle 会在卷上执行一些基本的 擦除(rm -rf /thevolume/*)操作,之后允许该卷用于新的 PVC 申领。
PersistentVolume(PV) 持久卷对象
每个 PV 对象都包含 spec 部分和 status 部分,分别对应卷的规约和状态。 PersistentVolume 对象的名称必须是合法的 DNS 子域名.
PV 资源对象示例
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0003
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
storageClassName: slow
mountOptions:
- hard
- nfsvers=4.1
nfs:
path: /tmp
server: 172.17.0.2
容量(Capacity)
一般而言,每个 PV 卷都有确定的存储容量。 容量属性是使用 PV 对象的 capacity 属性来设置的。 参考 Kubernetes 资源模型(Resource Model) 设计提案,了解 capacity 字段可以接受的单位。
目前,存储大小是可以设置和请求的唯一资源。 未来可能会包含 IOPS、吞吐量等属性。
卷模式(Volume Mode)
针对 PV 持久卷,Kubernetes 支持两种卷模式(volumeModes):Filesystem(文件系统) 和 Block(块)。 volumeMode 是一个可选的 API 参数。 如果该参数被省略,默认的卷模式是 Filesystem。
volumeMode 属性设置为 Filesystem 的卷会被 Pod 挂载(Mount) 到某个目录。 如果卷的存储来自某块设备而该设备目前为空,Kuberneretes 会在第一次挂载卷之前 在设备上创建文件系统。
你可以将 volumeMode 设置为 Block,以便将卷作为原始块设备来使用。 这类卷以块设备的方式交给 Pod 使用,其上没有任何文件系统。 这种模式对于为 Pod 提供一种使用最快可能方式来访问卷而言很有帮助,Pod 和 卷之间不存在文件系统层。另外,Pod 中运行的应用必须知道如何处理原始块设备。 关于如何在 Pod 中使用 volumeMode: Block 的卷,可参阅 原始块卷支持。
访问模式(Access Modes)
PersistentVolume 卷可以用资源提供者所支持的任何方式挂载到宿主系统上。 由于提供者(驱动)支持的能力不同,每个类型的 PV 卷的访问模式可设置的值也不同。 例如,NFS 可以支持多个读写客户,但是某个特定的 NFS PV 卷可能在服务器 上以只读的方式导出。每个 PV 卷都会获得自身的访问模式集合,描述的是 特定 PV 卷的能力。
访问模式有:ReadWriteOnce – 卷可以被一个节点以读写方式挂载;ReadOnlyMany – 卷可以被多个节点以只读方式挂载;ReadWriteMany – 卷可以被多个节点以读写方式挂载。
在命令行接口(CLI)中,访问模式也使用以下缩写形式:
RWO - ReadWriteOnce
ROX - ReadOnlyMany
RWX - ReadWriteMany
注意:每个卷只能同一时刻只能以一种访问模式挂载,即使该卷能够支持多种访问模式。例如,一个 GCEPersistentDisk 卷可以被某节点以 ReadWriteOnce 模式挂载,或者被多个节点以 ReadOnlyMany 模式挂载,但不可以同时以两种模式 挂载。
宿主机目录 HostPath 类型的持久卷只支持 ReadWriteOnce 访问模式。
存储类名(storageClassName)
每个 PV 可以属于某个类(Class),通过将其 storageClassName 属性设置为某个 StorageClass 的名称来指定。 特定类的 PV 卷只能绑定到请求该类存储卷的 PVC 申领。 未设置 storageClassName 的 PV 卷没有类设定,只能绑定到那些没有指定特定 存储类的 PVC 申领。
早前,Kubernetes 使用注解 volume.beta.kubernetes.io/storage-class 而不是 storageClassName 属性。这一注解目前仍然起作用,不过在将来的 Kubernetes 发布版本中该注解会被彻底废弃。
回收策略(Reclaim Policy)
目前的回收策略有:Retain – 手动回收Recycle – 基本擦除 (rm -rf /thevolume/*)Delete – 诸如 AWS EBS、GCE PD、Azure Disk 或 OpenStack Cinder 卷这类关联存储资产也被删除
目前,仅 NFS 和 HostPath 支持回收(Recycle)。 AWS EBS、GCE PD、Azure Disk 和 Cinder 卷都支持删除(Delete)。
节点亲和性(Node Affinity)
每个 PV 卷可以通过设置 节点亲和性 来定义一些约束,进而限制从哪些节点上可以访问此卷。 使用这些卷的 Pod 只会被调度到节点亲和性规则所选择的节点上执行。
说明: 对大多数类型的卷而言,你不需要设置节点亲和性字段。 AWS EBS、 GCE PD 和 Azure Disk 卷类型都能 自动设置相关字段。 你需要为 local 卷显式地设置 此属性。
状态/阶段(Status/Phase)
每个卷会处于以下阶段(Phase)之一:
Available(可用)– 卷是一个空闲资源,尚未绑定到任何申领;
Bound(已绑定)– 该卷已经绑定到某申领;
Released(已释放)– 所绑定的申领已被删除,但是资源尚未被集群回收;
Failed(失败)– 卷的自动回收操作失败。
命令行接口能够显示绑定到某 PV 卷的 PVC 对象。
PersistentVolumeClaim(PVC) 持久卷申领对象
每个 PVC 对象都有 spec 和 status 部分,分别对应申领的规约和状态。 PersistentVolumeClaim 对象的名称必须是合法的 DNS 子域名.
PVC 资源示例:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: myclaim
spec:
accessModes:
- ReadWriteOnce
volumeMode: Filesystem
resources:
requests:
storage: 8Gi
storageClassName: slow
selector:
matchLabels:
release: "stable"
matchExpressions:
- {key: environment, operator: In, values: [dev]}
和 PV 一样,PVC 资源对象也具有 访问模式、卷模式属性,并使用和持久卷 PV 相同的属性值。
和 Pod 一样,也可以请求特定数量的资源。在这个上下文中,请求的资源是存储。 卷和申领都使用相同的 资源模型。
标签选择符(Label Selector)
申领可以设置 标签选择算符(label selector) 来进一步过滤卷集合。只有标签与选择算符相匹配的卷能够绑定到申领上。 选择算符包含两个字段:
matchLabels - 卷必须包含带有此值的标签
matchExpressions - 通过设定键(key)、值列表和操作符(operator) 来构造的需求。合法的操作符有 In、NotIn、Exists 和 DoesNotExist。
来自 matchLabels 和 matchExpressions 的所有需求都按逻辑与的方式组合在一起。 这些需求都必须被满足才被视为匹配。
存储类名(storageClassName)
申领可以通过为 storageClassName 属性设置 StorageClass 的名称来请求特定的存储类。 只有 storageClassName 属性相同的 PV 卷, 才能绑定到 PVC 申领。
PVC 申领不必一定要请求某个类。如果 PVC 的 storageClassName 属性值设置为 “”, 则被视为要请求的是没有设置存储类的 PV 卷,因此这一 PVC 申领只能绑定到未设置 存储类的 PV 卷(未设置注解或者注解值为 “” 的 PV)。 未设置 storageClassName 的 PVC 与此大不相同,也会被集群作不同处理。 具体筛查方式取决于 DefaultStorageClass 准入控制器插件 是否被启用:
- 如果 DefaultStorageClass 准入控制器插件被启用,则管理员可以设置一个默认的 StorageClass。 所有未设置 storageClassName 的 PVC 都只能绑定到隶属于默认存储类的 PV 卷。 设置默认 StorageClass 的工作是通过将对应 StorageClass 对象的注解
storageclass.kubernetes.io/is-default-class赋值为true来完成的。 如果管理员未设置默认存储类,集群对 PVC 创建的处理方式与未启用准入控制器插件 时相同。如果设定的默认存储类不止一个,准入控制插件会禁止所有创建 PVC 操作。 - 如果 DefaultStorageClass 准入控制器插件被关闭,则不存在默认 StorageClass 的说法。 所有未设置 storageClassName 的 PVC 都只能绑定到未设置存储类的 PV 卷。 在这种情况下,未设置 storageClassName 的 PVC 与 storageClassName 设置未 “” 的 PVC 的处理方式相同。
取决于安装方法,默认的 StorageClass 可能在集群安装期间由插件管理器(Addon Manager)部署到集群中。
当某 PVC 除了请求 StorageClass 之外还设置了 selector,则这两种需求会按 逻辑与关系处理:只有隶属于所请求类且带有所请求标签的 PV 才能绑定到 PVC。
说明: 目前,设置了非空 selector 的 PVC 对象无法让集群为其动态供应 PV 卷。
早前,Kubernetes 使用注解 volume.beta.kubernetes.io/storage-class 而不是 storageClassName 属性。这一注解目前仍然起作用,不过在将来的 Kubernetes 发布版本中该注解会被彻底废弃。
问题
pod has unbound immediate PersistentVolumeClaims
一、问题:
vitess 集群中的 etcd 启动后一直处于 pending 状态,describe 查看 pod 显示
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling <unknown> default-scheduler pod has unbound immediate PersistentVolumeClaims (repeated 3 times)
二、排查:
1、kubectl get pvc 查看 pvc, 发现需要的几个 pvc 也是处于 Pending 状态:
#kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
example-etcd-faf13de3-1 Pending 36m
example-etcd-faf13de3-2 Pending 36m
example-etcd-faf13de3-3 Pending 36m
2、kubectl describe pvc example-etcd-faf13de3-1 查看一个具体 pvc
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal FailedBinding 113s (x142 over 37m) persistentvolume-controller no persistent volumes available for this claim and no storage class is set
可以看到原因是没有配置可用的持久卷,也没有声明 StorageClass.
3、kubectl get storageclass 或 kubectl get sc 查看当前的存储类,发现是有存储类的,但是没有配置为默认存储类。
三、解决:
解决方法有两个:
1、配置默认存储类
可以通过命令 kubectl patch storageclass <your-class-name> -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}' 将一个已有的存储类设置为默认存储类。
2、显式指定状态集 StatefulSet 的 volumeClaimTemplates 的 storageClassName 为系统内已有的存储类名。
node(s) had volume node affinity conflict
mysql pod 无法启动,event 里显示 1 node(s) had volume node affinity conflict
原因:
pod 的 pvc 申领在不同的机器上。
解决:
删除 pvc,删除 mysql statefulset, 重启时重新去 storageclass 匹配本机 pvc
Kubernetes Pod Warning: 1 node(s) had volume node affinity conflict
https://stackoverflow.com/questions/51946393/kubernetes-pod-warning-1-nodes-had-volume-node-affinity-conflict
pvc 处于 Terminating 状态
k8s 的 pvc(PersistentVolumeClaim) 在被 Pod 挂载的状态下,如果对其执行删除动作,将会变为 Terminating 状态。
https://blog.51cto.com/u_14086194/2718317
StorageClass 存储类
Storage Classes
https://kubernetes.io/docs/concepts/storage/storage-classes/
集群管理员需要提供各种各样、不同大小、不同访问模式的 PV, 而不用向用户暴露这些 volume 如何实现的细节。因为这种需求,就催生出一种 StorageClass 资源。
StorageClass 提供了一种方式,使得管理员能够描述他提供的存储的等级。集群管理员可以将不同的等级映射到不同的服务等级、不同的后端策略。
每个 StorageClass 都包含 provisioner, parameters 和 reclaimPolicy 字段, 这些字段会在 StorageClass 需要动态分配 PersistentVolume 时会使用到。
StorageClass 对象的命名很重要,用户使用这个命名来请求生成一个特定的类。 当创建 StorageClass 对象时,管理员设置 StorageClass 对象的命名和其他参数,一旦创建了对象就不能再对其更新。
存储类示例
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: standard
provisioner: kubernetes.io/aws-ebs
parameters:
type: gp2
reclaimPolicy: Retain
allowVolumeExpansion: true
mountOptions:
- debug
volumeBindingMode: Immediate
Provisioner 制备器
每个 StorageClass 都有一个制备器(Provisioner),用来决定使用哪个卷插件制备 PV。 该字段必须指定。
k8s 内置了很多制备器,这些制备器前缀为 kubernetes.io 并打包在 Kubernetes 中,例如 kubernetes.io/no-provisioner。
你还可以运行和指定外部制备器,例如 rancher.io/local-path,这些独立的程序遵循由 Kubernetes 定义的规范。 外部供应商的作者完全可以自由决定他们的代码保存于何处、打包方式、运行方式、使用的插件(包括 Flex)等。
local-path-provisioner
rancher / local-path-provisioner
https://github.com/rancher/local-path-provisioner
Rancher 提供的一种存储类实现,可以将本地磁盘存储以存储类的方式使用,内部是创建了一个 hostPath 宿主机路径卷
reclaimPolicy 回收策略
由 StorageClass 动态创建的 PersistentVolume 会在类的 reclaimPolicy 字段中指定回收策略,可以是 Delete 或者 Retain。如果 StorageClass 对象被创建时没有指定 reclaimPolicy,它将默认为 Delete。
通过 StorageClass 手动创建并管理的 PersistentVolume 会使用它们被创建时指定的回收政策。
volumeBindingMode 卷绑定模式
volumeBindingMode 字段控制了卷绑定和动态制备 应该发生在什么时候。
默认值 Immediate 模式表示一旦创建了 PersistentVolumeClaim 也就完成了卷绑定和动态制备。 对于由于拓扑限制而非集群所有节点可达的存储后端,PersistentVolume 会在不知道 Pod 调度要求的情况下绑定或者制备。
集群管理员可以通过指定 WaitForFirstConsumer 模式来解决此问题。 该模式将延迟 PersistentVolume 的绑定和制备,直到使用该 PersistentVolumeClaim 的 Pod 被创建。 PersistentVolume 会根据 Pod 调度约束指定的拓扑来选择或制备。这些包括但不限于 资源需求、 节点筛选器、 pod 亲和性和互斥性、 以及污点和容忍度。
设置/修改默认存储类 DefaultStorageClass
1、kubectl get storageclass 或 kubectl get sc 查看当前的存储类。
只有一个存储类,但是 NAME 后没有括号 default, 所以也不是默认存储类。
# kubectl get sc
NAME PROVISIONER AGE
local-path rancher.io/local-path 5d1h
2、将当前默认 StorageClass 改为非默认的
默认存储类的 storageclass.kubernetes.io/is-default-class 属性为 true, 将其改为 false 即可。
假如当前默认的存储类是 standard, 将其改为非默认kubectl patch storageclass standard -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"false"}}}'
3、标记一个 StorageClass 为默认的:kubectl patch storageclass <your-class-name> -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
之后再查看 sc, 发现是默认的了。
# kubectl get sc
NAME PROVISIONER AGE
local-path (default) rancher.io/local-path 5d1h
或者可以 describe 一下这个 sc, 可以看到有 storageclass.kubernetes.io/is-default-class=true 属性了。
# kubectl describe sc local-path
Name: local-path
IsDefaultClass: Yes
Annotations: kubectl.kubernetes.io/last-applied-configuration={"apiVersion":"storage.k8s.io/v1","kind":"StorageClass","metadata":{"annotations":{},"name":"local-path"},"provisioner":"rancher.io/local-path","reclaimPolicy":"Delete","volumeBindingMode":"WaitForFirstConsumer"}
,storageclass.kubernetes.io/is-default-class=true
Provisioner: rancher.io/local-path
Parameters: <none>
AllowVolumeExpansion: <unset>
MountOptions: <none>
ReclaimPolicy: Delete
VolumeBindingMode: WaitForFirstConsumer
Events: <none>
管理容器资源
https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/
Metrics Server
从Kubernetes v1.8 开始,资源使用情况的监控可以通过 Metrics API的形式获取,例如容器CPU和内存使用率。这些度量可以由用户直接访问(例如,通过使用kubectl top命令),或者由集群中的控制器(例如,Horizontal Pod Autoscaler)使用来进行决策,具体的组件为Metrics Server,用来替换之前的heapster,heapster从1.11开始逐渐被废弃。
Metrics server 定时从Kubelet的Summary API采集指标信息,这些聚合过的数据将存储在内存中,且以metric-api的形式暴露出去。
用处:
- kubectl top node/pod 命令获取集群、pod资源信息
- 调度器 HPA 水平扩展
ConfigMap 配置映射
ConfigMaps
https://kubernetes.io/docs/concepts/configuration/configmap/
ConfigMap API 给我们提供了向容器中注入配置信息的机制,ConfigMap 可以被用来保存单个属性,也可以用来保存整个配置文件或者 JSON 二进制大对象。ConfigMap 可以更方便地处理不包含敏感信息的字符串。
Kubernetes对象之ConfigMap
https://www.jianshu.com/p/cf8705a93c6b
HPA
Horizontal Pod Autoscaling,顾名思义,使 Pod 水平自动缩放。
通过ConfigMap更新服务配置
1、在 k8s dashboard 找到对应的服务的configmap,点查看/编辑yaml进行修改,改完点击更新;然后重启pod(删除pod即可);
2、登陆k8s master 执行 kubectl edit cm configmap-xx 直接编辑 configmap,改完保存,然后重启pod(删除pod即可);
热更新
目前暂不支持热更新
但可实现configmap更新完后pod自动重启:使用sidecar监听configmap变化修改template即可,如修改deployment的annotations
Secret 秘钥
Secrets
https://kubernetes.io/docs/concepts/configuration/secret/
Secret 对象类型用来保存敏感信息,例如密码、OAuth 令牌和 SSH 密钥。 将这些信息放在 secret 中比放在 Pod 的定义或者 容器镜像 中来说更加安全和灵活。
Secret 是一种包含少量敏感信息例如密码、令牌或密钥的对象。 这样的信息可能会被放在 Pod 规约中或者镜像中。 用户可以创建 Secret,同时系统也创建了一些 Secret。
Kubernetes Secret 默认情况下存储为 base64-编码的、非加密的字符串。 默认情况下,能够访问 API 的任何人,或者能够访问 Kubernetes 下层数据存储(etcd) 的任何人都可以以明文形式读取这些数据。
Kubernetes 内置 Secret 类型:Opaque 用户定义的任意数据kubernetes.io/service-account-token 服务账号令牌kubernetes.io/dockercfg ~/.dockercfg 文件的序列化形式kubernetes.io/dockerconfigjson ~/.docker/config.json 文件的序列化形式kubernetes.io/basic-auth 用于基本身份认证的凭据kubernetes.io/ssh-auth 用于 SSH 身份认证的凭据kubernetes.io/tls 用于 TLS 客户端或者服务器端的数据bootstrap.kubernetes.io/token 启动引导令牌数据
通过为 Secret 对象的 type 字段设置一个非空的字符串值,你也可以定义并使用自己 Secret 类型。如果 type 值为空字符串,则被视为 Opaque 类型。 Kubernetes 并不对类型的名称作任何限制。不过,如果你要使用内置类型之一, 则你必须满足为该类型所定义的所有要求。
kubectl get secret 查看 namespace 下的全部密钥
# kubectl get secret
NAME TYPE DATA AGE
mysql-alone Opaque 2 4h35m
kubectl get secret mysql-alone -o yaml 查看某个具体 secret 的原始 yaml
# kubectl get secret mysql-alone -o yaml
apiVersion: v1
data:
mysql-password: xxxxxxxxxxxx
mysql-root-password: xxxxxxxxxxxx
kind: Secret
metadata:
creationTimestamp: "2021-06-30T23:49:17Z"
labels:
app: mysql-alone
chart: mysql-1.1.1
heritage: Helm
release: mysql-alone
name: mysql-alone
namespace: default
resourceVersion: "374990"
selfLink: /api/v1/namespaces/default/secrets/mysql-alone
uid: fc66f625-3fb6-4957-99ee-9786af38d6b0
type: Opaque
ServiceAccount 服务账户
Configure Service Accounts for Pods
https://kubernetes.io/docs/tasks/configure-pod-container/configure-service-account/
服务账户为 Pod 中运行的进程提供了一个标识。
当自然人访问集群时(例如,使用 kubectl),API 服务器将身份验证为 特定的用户帐户(当前这通常是 admin,除非集群管理员已经定制了集群配置)。
Pod 内的容器中的进程也可以与 api 服务器接触。 当它们进行身份验证时,它们被验证为特定的服务帐户(例如,default)。
当你创建 Pod 时,如果没有指定服务账户,Pod 会被指定给命名空间中的 default 服务账户。 如果通过 kubectl get pods/podname -o yaml 命令查看 Pod 的原始 YAML 定义,可以看到 spec.serviceAccountName 字段已经被自动设置为 default 了。
每个 namespace 都有一个名为 default 的服务账户资源。
ServiceAccount 对象的名字必须是一个有效的 DNS 子域名。
可以通过 kubectl get serviceAccounts 命令查看 namespace 中的 ServiceAccount
也可以 kubectl get serviceaccounts vitess-operator -o yaml 查看某个具体的 ServiceAccount 的原始 yaml
# kubectl get serviceaccounts vitess-operator -o yaml
apiVersion: v1
kind: ServiceAccount
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"v1","kind":"ServiceAccount","metadata":{"annotations":{},"name":"vitess-operator","namespace":"default"}}
creationTimestamp: "2021-06-30T18:50:26Z"
name: vitess-operator
namespace: default
resourceVersion: "332313"
selfLink: /api/v1/namespaces/default/serviceaccounts/vitess-operator
uid: 2868977f-cd8d-4a79-be2e-1cc77c248a23
secrets:
- name: vitess-operator-token-nn4m5
可以看到系统已经自动创建了一个令牌并且被服务账户所引用。
RBAC 鉴权
Using RBAC Authorization
https://kubernetes.io/docs/reference/access-authn-authz/rbac/
RBAC 鉴权机制使用 rbac.authorization.k8s.io API 组来驱动鉴权决定,允许你通过 Kubernetes API 动态配置策略。
要启用 RBAC, 在启动 API 服务器 时将 --authorization-mode 参数设置为一个逗号分隔的列表并确保其中包含 RBAC.
kube-apiserver --authorization-mode=Example,RBAC --<其他选项> --<其他选项>
RBAC API 声明了四种 Kubernetes 对象:Role, ClusterRole, RoleBinding 和 ClusterRoleBinding. 你可以像使用其他 Kubernetes 对象一样, 通过类似 kubectl 这类工具 描述对象, 或修补对象。
Role 和 ClusterRole
RBAC 的 Role 或 ClusterRole 中包含一组代表相关权限的规则。 这些权限是纯粹累加的(不存在拒绝某操作的规则)。
Role 总是用来在某个名字空间内设置访问权限;创建 Role 时必须指定该 Role 所属的名字空间。
与之相对,ClusterRole 则是一个集群作用域的资源。这两种资源的名字不同(Role 和 ClusterRole)是因为 Kubernetes 对象要么是名字空间作用域的,要么是集群作用域的, 不可两者兼具。
在 namespace 内定义角色,应该使用 Role, 在集群范围内定义角色,应该使用 ClusterRole.
Role 或 ClusterRole 对象的名称必须是合法的 路径区段名称。
Role 示例:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: default
name: pod-reader
rules:
- apiGroups: [""] # "" 标明 core API 组
resources: ["pods"]
verbs: ["get", "watch", "list"]
声明了一个位于 “default” 名字空间的 Role 角色,可用来授予对 pods 的读访问权限
RoleBinding 和 ClusterRoleBinding
角色绑定(Role Binding)是将角色中定义的权限赋予一个或者一组用户。 它包含若干主体(用户、组或服务账户 ServiceAccount)的列表和对这些主体所获得的角色的引用。 RoleBinding 在指定的名字空间中执行授权,而 ClusterRoleBinding 在集群范围执行授权。
一个 RoleBinding 可以引用同一的名字空间中的任何 Role。 或者,一个 RoleBinding 可以引用某 ClusterRole 并将该 ClusterRole 绑定到 RoleBinding 所在的名字空间。 如果你希望将某 ClusterRole 绑定到集群中所有名字空间,你要使用 ClusterRoleBinding。
RoleBinding 或 ClusterRoleBinding 对象的名称必须是合法的 路径区段名称。
下面的例子中的 RoleBinding 将 “pod-reader” Role 授予在 “default” 名字空间中的用户 “jane”。 这样,用户 “jane” 就具有了读取 “default” 名字空间中 pods 的权限。
apiVersion: rbac.authorization.k8s.io/v1
# 此角色绑定允许 "jane" 读取 "default" 名字空间中的 Pods
kind: RoleBinding
metadata:
name: read-pods
namespace: default
subjects:
# 你可以指定不止一个“subject(主体)”
- kind: User
name: jane # "name" 是不区分大小写的
apiGroup: rbac.authorization.k8s.io
roleRef:
# "roleRef" 指定与某 Role 或 ClusterRole 的绑定关系
kind: Role # 此字段必须是 Role 或 ClusterRole
name: pod-reader # 此字段必须与你要绑定的 Role 或 ClusterRole 的名称匹配
apiGroup: rbac.authorization.k8s.io
Service 服务
Service
https://kubernetes.io/docs/concepts/services-networking/service/
常规 k8s 服务部署流程:先编写一个 Deployment 的控制器,然后创建一个 Service 对象,通过 Pod 的 label 标签进行关联,最后通过 Ingress 或者 type=NodePort 类型的 Service 来暴露服务。
Kubernetes 中 Pod 是随时可以消亡的(节点故障、容器内应用程序错误等原因)。如果使用 Deployment 运行您的应用程序,Deployment 将会在 Pod 消亡后再创建一个新的 Pod 以维持所需要的副本数。每一个 Pod 有自己的 IP 地址,然而,对于 Deployment 而言,对应 Pod 集合是动态变化的。
一组 pod 可以组成一个 Service, 对外提供统一的访问地址(Service ip 或 dns),对内转发请求到不同的 pod
Service 相当于一堆 Pod 前的代理入口,Pod 是 Service 的后端实现。
在 K8s 集群中,客户端需要访问的服务就是 Service 对象。每个 Service 会对应一个集群内部有效的虚拟 IP, 该虚拟 IP 通过 IPVS 规则,自动轮询访问后端 Pod. 在 K8s 集群中微服务的负载均衡是由 Kube-proxy 实现的。
Service 类型
Publishing Services (ServiceTypes)
https://kubernetes.io/docs/concepts/services-networking/service/#publishing-services-service-types
k8s 支持以下几种 Service 类型:
ClusterIP(默认)
ClusterIP 在集群内部 IP 上将 Service 暴露出去,这种类型的 Service 只能在集群内部访问。这是默认的 Service 类型。
默认的 ClusterIP 类型 Service 示例:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
如果想从集群外访问 ClusterIP 类型的 Service 也有办法,可以利用 Kubernetes 的 proxy 来访问服务:
1、kubectl proxy --port=8080 启动一个代理,这样 Kubernetes API Server 会监听宿主机本地的 8080 端口
2、之后可以通过下面的 url 访问想要的服务
http://localhost:8080/api/v1/proxy/namespaces/<NAMESPACE>/services/<SERVICE-NAME>:<PORT-NAME>/
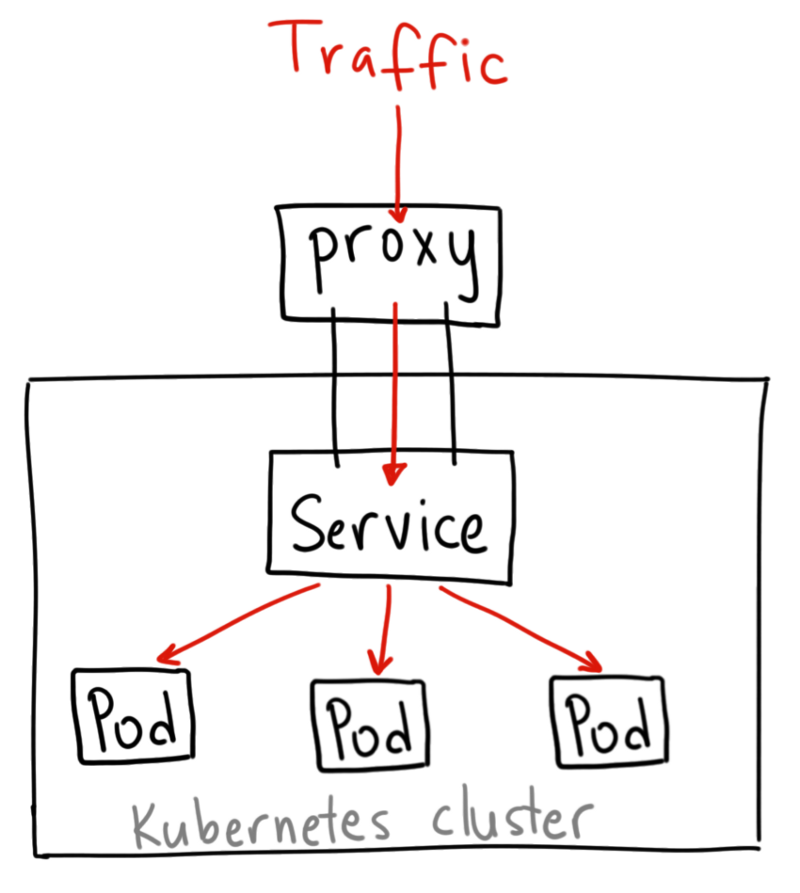
ClusterIP Service
我们的 k8s 集群中有的 Service 类型是默认的 ClusterIP 类型的,但是也能通过 NodeIP:targetPort 访问,怎么实现的呢?
因为我们的 k8s 和 容器 用的是 host 主机网络,容器内和宿主机间是完全互通的同一个网络,所以可以直接通过 宿主机IP:容器内服务的端口 访问。
NodePort
NodePort 在 Node IP 和 静态端口 NodePort 上将 Service 暴露出去。之后可在集群外通过 <NodeIP>:<NodePort> 访问 Service。
Service 类型为 NodePort 时,k8s 会从 service-node-port-range 配置(默认是 30000-32767)指定的端口范围内自动分配一个端口作为 nodePort。
也可以通过 nodePort 指定固定端口,但需要小心端口冲突
NodePort 服务是引导外部流量到 Service 的最原始方式。
NodePort 类型服务会在所有 Node 节点上监听 nodePort 端口(随机的或指定的),任何发送到该端口的流量都被转发到对应服务
NodePort 类型 Service 示例:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
type: NodePort
selector:
app: MyApp
ports:
# By default and for convenience, the `targetPort` is set to the same value as the `port` field.
- port: 80
targetPort: 80
# Optional field
# By default and for convenience, the Kubernetes control plane will allocate a port from a range (default: 30000-32767)
nodePort: 30007
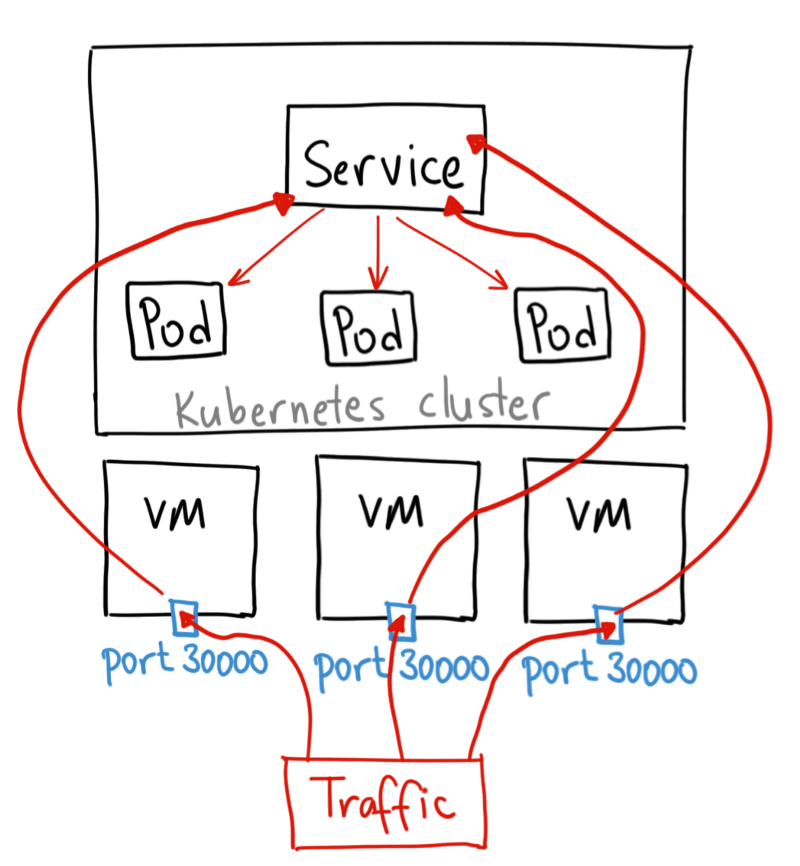
NodePort Service
LoadBalancer
LoadBalancer 通过云服务商提供的负载均衡器将 Service 暴露到外部,这种方式下会自动创建 ClusterIP 和 NodePort, 然后外部负载均衡器会路由到此 ClusterIP:NodePort
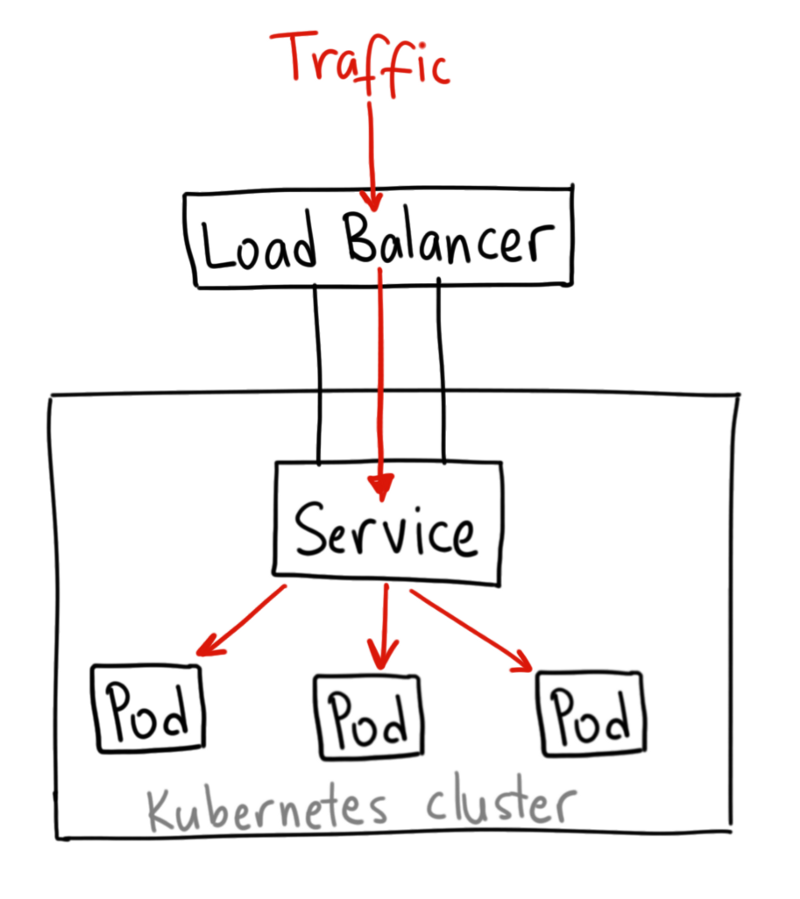
LoadBalancer Service
ExternalName
将 Service 映射到 CNAME 记录的 externalName 域。注意需要 kube-dns 1.7 版本及以上或 CoreDNS 0.0.8 版本及以上。
将k8s Service暴露到集群外部的几种方式
通过 host 主机网络
k8s 和 容器 都配置为 host 主机网络,容器内和宿主机间是完全互通的同一个网络,所以可以直接通过 宿主机IP:容器内服务的端口 访问。
通过 NodePort 类型 Service
通过 Service.Type=NodePort 类型的 Service, 此时集群中每一个节点(Node)都会监听指定端口, 我们通过任意节点的端口即可访问到指定服务. 但过多的服务会开启大量端口难以维护。
通过 kubectl port-forward 端口转发
通过 kubectl port-forward 转发, 操作方便,适合调试时使用, 不适用于生产环境。
通过云服务商的 LoadBalance
通过 LoadBalance 来暴露服务. LoadBalance(负载均衡 LB)需要由云服务商提供, 如果云环境中不提供 LB 服务, 我们通常直接使用Ingress, 或使用MetalLB来自行配置LB.
通过 Ingress Controller
通过 Ingress 公开多个服务。Ingress 公开了从群集外部到群集内 Services 的 HTTP 和 HTTPS 路由。通过 Ingress 可以将多个 Service 通过一个 IP 暴露出去,并且可以将路由规则合并到一个 Resource 中定义。流量路由由 Ingress 资源上定义的规则控制. 在云服务商不提供LB服务的情况下, 我们可以直接使用 Ingress 来暴露服务. (另外, 使用 LB + Ingress 的部署方案可以避免过多LB应用带来的花费).
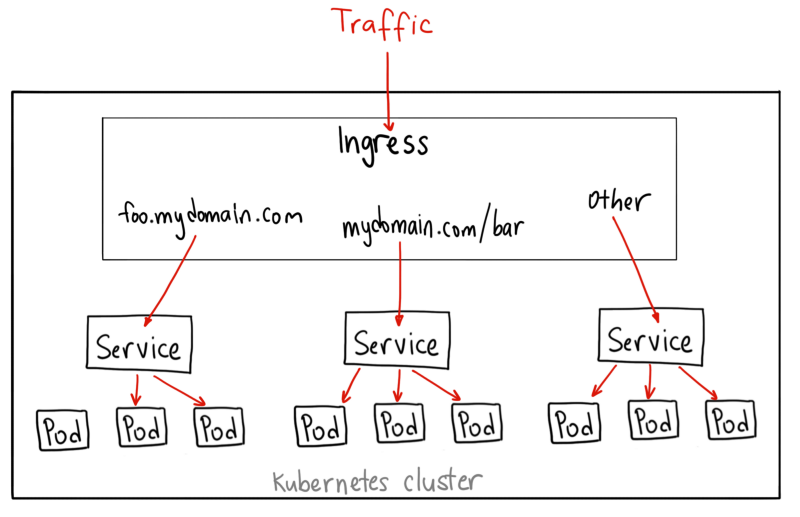
通过 Ingress 暴露服务
Port,TargetPort和NodePort
TargetPort 服务将向这个端口转发请求,必须和容器内应用监听的端口一致(例如Tomcat启动端口,SpringBoot端口)Port k8s 的服务地址,集群内的服务之间可以通过 service_name:port 端口互相访问。NodePort 通过 Node IP 和 NodePort 的形式将服务暴露出去
例如如下配置
apiVersion: v1
kind: Service
metadata:
name: hello-world
spec:
type: NodePort
selector:
app: hello-world
ports:
- protocol: TCP
port: 8080
targetPort: 80
nodePort: 30036
hello-world 服务在集群间通过 hello-world:8080 可互相访问
在外部,可以通过 NodeIp:30036 访问
以上两种方式,service都会将请求转发到应用的 80 端口
TargetPort 和 NodePort 相同时无法使用主机网络启动 Pod
TargetPort 和 NodePort 相同时无法使用主机网络启动 Pod,会报端口冲突错误
原因是开启 NodePort 后会在全部机器上监听相同的端口,然后导致 Pod 启动时端口冲突
比如
nodePort: 8888
targetPort: 8888
由于设置了 nodePort: 8888,会在全部 Node 上监听 8888 端口
然后启动 Pod 时,由于内部服务(比如 SpringBoot)也需要监听 8888 端口,且是主机网络,就会端口冲突报错 Web server failed to start. Port 8888 was already in use.
Headless Services 无头服务
有时不需要或不想要负载均衡,以及单独的 Service IP。 遇到这种情况,可以通过指定 Cluster IP(spec.clusterIP) 的值为 None 来创建 Headless Service。
对这无头 Service 并不会分配 Cluster IP,kube-proxy 不会处理它们,而且平台也不会为它们进行负载均衡和路由。
服务发现
Discovering services
https://kubernetes.io/docs/concepts/services-networking/service/#discovering-services
kubernetes 服务发现支持 Service 环境变量 和 DNS 两种方式
环境变量
同一个 namespace 里的 service 启动时,k8s 会把集群中所有当前可用的 service 的 ip 和 port 以环境变量的形式注入到pod里,在pod中的服务可以通过环境变量来知晓当前集群中的其他服务地址
环境变量名的格式为 {SVCNAME}_SERVICE_HOST 和 {SVCNAME}_SERVICE_PORT,这里 Service 的名称需大写,横线被转换成下划线。
例如,名称为 redis-master 的 Service 暴露了 TCP 端口 6379, 同时给它分配了 Cluster IP 地址 10.0.0.11,这个 Service 生成了如下环境变量:
REDIS_MASTER_SERVICE_HOST=10.0.0.11
REDIS_MASTER_SERVICE_PORT=6379
REDIS_MASTER_PORT=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP_PROTO=tcp
REDIS_MASTER_PORT_6379_TCP_PORT=6379
REDIS_MASTER_PORT_6379_TCP_ADDR=10.0.0.11
例如
$ env|grep -i service|sort
KUBERNETES_SERVICE_HOST=192.168.0.1
KUBERNETES_SERVICE_PORT=443
KUBERNETES_SERVICE_PORT_HTTPS=443
UDS_SNOWFLAKE_SERVER_DOCKER_SERVICE_HOST=192.168.154.29
UDS_SNOWFLAKE_SERVER_DOCKER_SERVICE_PORT=8080
UDS_SNOWFLAKE_SERVER_DOCKER_SERVICE_PORT_TCP_8080=8080
UDS_USER_DOCKER_SERVICE_HOST=192.168.73.10
UDS_USER_DOCKER_SERVICE_PORT=8001
UDS_USER_DOCKER_SERVICE_PORT_HTTP_8001=8001
注意:
- Pod 和 Service 的创建顺序是有要求的,Service 必须在 Pod 创建之前被创建,否则环境变量不会设置到 Pod 中,例如 PodA 中需要访问 ServiceB,如果 ServiceB 是在 PodA 之后创建的,则无法访问
- Pod 只能获取同 Namespace 中的 Service 环境变量
通过DNS解析服务名访问
K8s 集群会内置一个 DNS 服务器,service 创建成功后,会在 DNS 里导入一些记录。
依靠 DNS 解析,同一个 namespace 里 pod 可以直接通过 service 名去访问到刚才所声明的这个 service。
不同 namespace 间可通过 service-name.namespace 去访问
例如我们直接用 curl 去访问,就是 my-service:80 就可以访问到这个 service。
DNS 服务器需要通过 k8s 插件来安装。
访问其他 namespace下的 Service
比如连接 namespace2 下的 mysql-service, 直接在 Service 名后加 .namespace 即可:
jdbc:mysql://mysql-service.namespace2:3306/user
通过Service访问服务偶发超时问题
kubernetes集群中夺命的5秒DNS延迟
https://tencentcloudcontainerteam.github.io/2018/10/26/DNS-5-seconds-delay/
Racy conntrack and DNS lookup timeouts
https://www.weave.works/blog/racy-conntrack-and-dns-lookup-timeouts
Endpoints
k8s 中 Service 和 Pod 不是直接连接,而是通过 Endpoints 资源进行连通。
每个 Endpoint 对象都包含一个 Service 关联的 Pod 的 IP 地址和端口信息。
Service 关联一组 Endpoints,当客户端访问 Service 时,服务代理从 Endpoints 列表的ip和port对中选择一个,将请求重定向到此ip:port。
Endpoints 是 Kubernetes 服务发现机制的一部分。当一个 Service 配置了 Selector,Endpoint Controller 将自动根据 Service 关联 Pod 的 Ip 和 Port 创建相应的 Endpoint 对象。如果没有配置Selector,Endpoint Controller 则不会自动创建 Endpoint 对象。
Endpoint 的名称必须和服务的名称相同
Endpoints Controller 是 k8s 集群控制器的其中一个组件,负责监听 Service 和对应的 Pod 副本的变化:
- 如果监测到Service被删除,则删除该Service同名的Endpoints对象
- 如果监测到新的Service被创建或被修改,则根据Servic信息获取相关的Pod列表,然后创建或者更新Service对应的Endppints对象
- 如果监测到Pod事件,则更新它对应的Service的Endpoints对象(增加、删除或者修改对应的Endpoint条目)。
已知一个K8s NodePort,如何找对应的Pod?
有端口 8001,如何找到是哪个 pod 的?
1、查 service
kubectl get svc|grep 8001
得到 svc-8001
2、查 service 对应的 Endpoint
kubectl describe svc-8001
得到 service 对应的 ip:port 列表
3、查 pod
kubectl get pod -o wide|grep ip
k8s Service 代理外部服务
假如有个外部接口 127.0.0.1:8123/api/v1/path,想要通过 k8s 的 Service 代理这个接口
创建一个自定义的 Service 和 Endpoints,Endpoints 的 ip 和 port 是外部服务的
1、创建 external-service.yml
kind: Service
apiVersion: v1
metadata:
name: external-service
spec:
type: ClusterIP
ports:
- port: 8088
targetPort: 8123
---
kind: Endpoints
apiVersion: v1
metadata:
name: external-service
subsets:
- addresses:
- ip: 127.0.0.1
ports:
- port: 8123
2、执行 kubectl apply -f zhongke-rain-service.yml
之后容器内访问 external-service:8088 就是访问 127.0.0.1:8123,请求 external-service:8088/api/v1/path 就是请求原外部 api。
注意:
- Service 和对应 Endpoints 的 name 必须要一致
- 如果外部服务部署了多个实例,可以在 Endpoints 下配置多个相应的实例ip
https://beloved.family/wx/如何将外部服务纳入到k8s集群内
Service 与 Pod 的 DNS
https://kubernetes.io/zh-cn/docs/concepts/services-networking/dns-pod-service/
除了无头 Service 之外的 “普通” Service 会被赋予一个形如 my-svc.my-namespace.svc.cluster-domain.example 的 DNS A 和/或 AAAA 记录,取决于 Service 的 IP 协议族(可能有多个)设置。 该名称会解析成对应 Service 的集群 IP。
每个 Pod 也会被赋予 DNS 记录,格式为 pod-ipv4-address.my-namespace.pod.cluster-domain.example,例如,对于一个位于 default 名字空间,IP 地址为 172.17.0.3 的 Pod, 如果集群的域名为 cluster.local,则 Pod 会对应 DNS 名称: 172-17-0-3.default.pod.cluster.local
通过 Service 暴露出来的所有 Pod 都会有如下 DNS 解析名称可用: pod-ipv4-address.service-name.my-namespace.svc.cluster-domain.example
dnsPolicy Pod 的 DNS 策略
DNS 策略可以逐个 Pod 来设定。目前 Kubernetes 支持以下特定 Pod 的 DNS 策略。 这些策略可以在 Pod 规约中的 dnsPolicy 字段设置:
DefaultPod 从运行所在的节点继承名称解析配置。ClusterFirst与配置的集群域后缀不匹配的任何 DNS 查询(例如 “www.kubernetes.io") 都将转发到从节点继承的上游域名服务器。集群管理员可能配置了额外的存根域和上游 DNS 服务器。ClusterFirstWithHostNet**对于以 hostNetwork 方式运行的 Pod,应显式设置其 DNS 策略ClusterFirstWithHostNet**。否则,以 hostNetwork 方式和 “ClusterFirst” 策略运行的 Pod 将会做出回退至 “Default” 策略的行为。None此设置允许 Pod 忽略 Kubernetes 环境中的 DNS 设置。Pod 会使用其 dnsConfig 字段 所提供的 DNS 设置。
Default 不是默认的 DNS 策略。如果未明确指定 dnsPolicy 则使用 ClusterFirst
dnsConfig Pod 的 DNS 配置
dnsConfig 字段是可选的,它可以与任何 dnsPolicy 设置一起使用。 但是,当 Pod 的 dnsPolicy 设置为 “None” 时,必须指定 dnsConfig 字段。
dnsConfig 配置项(和 /etc/resolv.conf 配置文件类似)nameservers 将用作于 Pod 的 DNS 服务器的 IP 地址列表。 最多可以指定 3 个 IP 地址。当 Pod 的 dnsPolicy 设置为 “None” 时, 列表必须至少包含一个 IP 地址,否则此属性是可选的。 所列出的服务器将合并到从指定的 DNS 策略生成的基本名称服务器,并删除重复的地址。searches 用于在 Pod 中查找主机名的 DNS 搜索域的列表。此属性是可选的。 指定此属性时,所提供的列表将合并到根据所选 DNS 策略生成的基本搜索域名中。 重复的域名将被删除。Kubernetes 最多允许 32 个搜索域。options 可选的对象列表,其中每个对象可能具有 name 属性(必需)和 value 属性(可选)。 此属性中的内容将合并到从指定的 DNS 策略生成的选项。 重复的条目将被删除。
使用 HostAliases 向 Pod /etc/hosts 添加域名解析
https://kubernetes.io/zh-cn/docs/tasks/network/customize-hosts-file-for-pods/
使用 .spec.hostAliases 可以给 pod 中的 /etc/hosts 文件添加额外的域名解析
例如
apiVersion: v1
kind: Pod
metadata:
name: hostaliases-pod
spec:
restartPolicy: Never
hostAliases:
- ip: "127.0.0.1"
hostnames:
- "foo.local"
- "bar.local"
- ip: "10.1.2.3"
hostnames:
- "foo.remote"
- "bar.remote"
containers:
- name: cat-hosts
image: busybox:1.28
command:
- cat
args:
- "/etc/hosts"
启动后 pod 内的 /etc/hosts 文件内容为
# Kubernetes-managed hosts file.
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
fe00::0 ip6-mcastprefix
fe00::1 ip6-allnodes
fe00::2 ip6-allrouters
10.200.0.5 hostaliases-pod
# Entries added by HostAliases.
127.0.0.1 foo.local bar.local
10.1.2.3 foo.remote bar.remote
kube-proxy
kube-proxy 作为 Kubernetes 集群中的网络代理和负载均衡器,其作用是将发送到 Service 的请求转发到具体的后端。
当前 Kubernetes kube-proxy 的负载均衡支持以下三种代理模式:
userspace(1.2后淘汰)
userspace 模式下 kube-proxy 进程在用户空间监听一个本地端口,iptables 规则将流量转发到这个本地端口,然后 kube-proxy 在其内部应用层建立到具体后端的连接,即在其内部进行转发,这是在用户空间的转发,虽然比较稳定,但效率不高。
发往Service的请求会先进入内核空间的iptable,再回到用户空间由kube-proxy代理转发。内核空间和用户空间来回地切换成为了该模式的主要性能问题。
userspace 模式是 kube-proxy 早期(Kubernetes 1.0)的模式,在 Kubernetes v1.2 之后就被淘汰,不推荐使用
iptables(1.12之前默认)
iptables 模式从 Kubernetes 1.2 开始引入,在 Kubernetes 1.12 之前是 kube-proxy 的默认方式
在这种模式下kube-proxy监控Kubernetes对Service、Endpoint对象的增删改操作。监控到Service对象的增删改,将配置iptables规则,截获到Service的ClusterIp和端口的流量并将其重定向到服务的某个后端;监控到Endpoint对象的增删改,将更新具体到某个后端的iptables规则。
iptables模式基于netfilter,但因为流量的转发都是在内核空间,所以性能更高且更加可靠。
这种模式的缺点是,对于超大规模集群,当集群中服务数量达到一定量级时,iptables规则的添加将会出现很大延迟,因为规则的更新出现kernel local,所以此时将会出现性能问题
针对iptable的O(n)级别长链问题,Calico插件优化了iptable的规则,使用ipset保存IP,大大提高了IP的查找效率(ipset内查找的复杂度是O(1)),减少了iptable的规则数量。
ipvs(1.12起默认)
ipvs 模式从 Kubernetes 1.8 开始引入,在 Kubernetes 1.11 进入 GA, 并在 Kubernetes 1.12 成为 kube-proxy 的默认代理模式
ipvs 模式也是基于 netfilter, 对比 iptables 模式在大规模 Kubernetes 集群有更好的扩展性和性能,支持更加复杂的负载均衡算法(如:最小负载、最少连接、加权等),支持 Server 的健康检查和连接重试等功能。ipvs 依赖于 iptables, 使用 iptables 进行包过滤、SNAT、masquared。ipvs 将使用 ipset 需要被DROP或MASQUARED的源地址或目标地址,这样就能保证iptables规则数量的固定,我们不需要关心集群中有多少个Service了。
IPVS(IP Virtual Server) 是 LVS 项目的一部分,作为 Linux 内核的一部分,提供 4 层负载均衡器的功能,即传输层负载均衡。ipvs 运行在主机内核中,作为真实服务器集群前的负载均衡器,将到达服务的请求转发到真实的服务器上,并将多个 ip 的真实服务器集群的服务显示为单个 ip 的虚拟机服务。
Kubernetes 从1.10到1.11升级记录(续):Kubernetes kube-proxy开启IPVS模式
https://blog.frognew.com/2018/10/kubernetes-kube-proxy-enable-ipvs.html
k8s ipvs 长连接 Connection reset by peer问题
查看 tcp keepalive 的内核参数
$ sysctl net.ipv4.tcp_keepalive_time net.ipv4.tcp_keepalive_probes net.ipv4.tcp_keepalive_intvl
net.ipv4.tcp_keepalive_time = 7200
net.ipv4.tcp_keepalive_probes = 9
net.ipv4.tcp_keepalive_intvl = 75
net.ipv4.tcp_keepalive_time 是连接时长,当超过这个时间后,每隔 net.ipv4.tcp_keepalive_intvl 的时间间隔会发送keepalive数据包,net.ipv4.tcp_keepalive_probe 是发送keepalived数据包的频率。
使用 ipvsadm 命令查看k8s节点上 ipvs 的超时时间:
ipvsadm -l --timeout
Timeout (tcp tcpfin udp): 900 120 300
经过上面的分析可以看出,各个k8s节点上tcp keepalive超时是7200秒(即2小时),ipvs超时是900秒(15分钟),这就出现如果客户端或服务端在15分钟内没有应答时,ipvs会主动将tcp连接终止,而客户端服务还傻傻以为是2个小时呢。 很明显net.ipv4.tcp_keepalive_time不能超过ipvs的超时时间。
Kubernetes IPVS模式下服务间长连接通讯的优化,解决Connection reset by peer问题
https://blog.frognew.com/2018/12/kubernetes-ipvs-long-connection-optimize.html
Ingress
Ingress
https://kubernetes.io/docs/concepts/services-networking/ingress/
Ingress 是对集群中服务的外部访问进行管理的 API 对象,典型的访问方式是 HTTP.
Ingress 可以提供负载均衡、SSL终结和基于名字的虚拟主机等功能。
Ingress 将集群内部的 Service 暴露为集群外部可访问的 HTTP 或 HTTPS 端点,通过 Ingress 资源中定义的路由规则进行流量转发。
如下图所示:
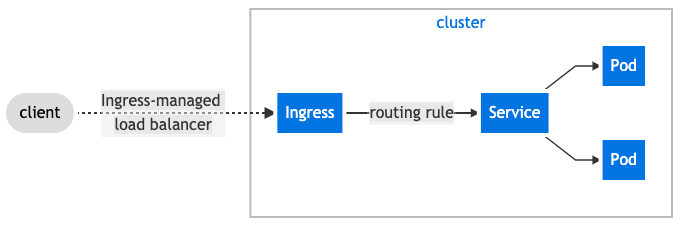
Ingress
通过配置 Ingress, 可以给集群内的 Service 提供外部可访问的 URLs, 流量负载均衡,SSL/TLS 终结,基于名字的虚拟主机等。
Ingress 不会公开任何端口或协议。 将 HTTP 和 HTTPS 以外的服务公开到 Internet 时,通常使用 Service.Type=NodePort 或 Service.Type=LoadBalancer 类型的服务。
Ingress Controller
必须部署一个 Ingress Controller 来实现 Ingress, 仅创建 Ingress 资源本身没有任何效果。Ingress 本身只是配置规则,需要 Ingress Controller 来将其实现。
Ingress Controller 是一个以 Pod 形式运行的反向代理程序,它解析 Ingress 的路由规则(yaml)来生成自己的转发规则(比如 nginx.conf),当 Ingress Controller 收到请求后就会根据这些规则将请求转发到对应的 Service.
Ingress Controller 会监听 Ingress 路由规则变化,如果 Ingress 有增删改的变动,所有的 Ingress Controller 都会及时更新自己的转发规则。
Kubernetes 本身并没有自带 Ingress Controller, 它只是一种标准,具体实现有多种,需要自己单独安装。
比如可以部署一个 ingress-nginx, 此外还有很多可选的 Ingress Controllers, 下面页面列出了可用的第三份 Ingress Controllers:
https://kubernetes.io/docs/concepts/services-networking/ingress-controllers/
Ingress Controller 应部署在边缘节点。所谓的 边缘节点 即集群内部用来向集群外暴露服务能力的节点,集群外部的服务通过该节点来调用集群内部的服务。
Ingress 资源
一个最小 Ingress 资源如下:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: minimal-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- http:
paths:
- path: /testpath
pathType: Prefix
backend:
service:
name: test
port:
number: 80
像其他 k8s 资源一样,需要 apiVersion, kind, metadata 几个字段。
Ingress 的名字必须是合法的 DNS Subdomain Names
Ingress 中经常使用 annotations 来配置一些选项,比如 rewrite-target annotation , 不同 Ingress Controller 支持不同的 annotations, 可以查看所选用的 Ingress Controller 的文档来了解支持哪些 annotations.
Ingress 规约(spec) 中包含配置负载均衡器或代理服务器所需要的所有信息,其中最重要的是用来处理请求的路由规则列表。
Ingress 只支持直接的 HTTP(S) 流量。
Ingress 规则
每个 HTTP 规则包含下列信息:
- 一个可选的
host. 上面例子中没有指明 host, 所以规则会应用到所有入站的 HTTP 请求。如果指明 host 的话,例如 foo.bar.com, 则规则只会应用到指明的 host. - 一个
paths列表,例如/testpath. 每个 path 都有一个关联的后端,后端通过service.name和service.port.name/service.port.number来定义。在负载均衡器将流量定向到引用的服务之前,host和path都必须匹配传入请求的内容。 backend是 Service 和 port 的组合。 到达 Ingress 的 HTTP(S) 请求匹配host和path后会被转发到对应的backend.
DefaultBackend 默认后端
Ingress Controller 中通常都会配置一个 defaultBackend 来处理不匹配任何 path 的请求。
没有配置任何规则的 Ingress 会将全部请求都转发到默认后端。defaultBackend 通常是 Ingress Controller 中的一个选项,并不在 Ingress 资源本身中配置。
如果 Ingress 规则中没有任何 host 和 path 匹配入站的 HTTP(S) 请求,则此请求会被转发给默认后端。
资源后端
除了将请求路由到 Service, Ingress 还可以将请求路由到某个 k8s 资源,这就是资源后端。
资源后端(Resource backend)是和 Ingress 对象在同一 namespace 下的 k8s 资源的对象引用。Resource 与 Service 配置是互斥的,在二者均被设置时会无法通过合法性检查。
资源后端常用于将入站请求转发给带有静态内容的对象存储后端。
比如一个静态图标的资源后端配置示例如下:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-resource-backend
spec:
defaultBackend:
resource:
apiGroup: k8s.example.com
kind: StorageBucket
name: static-assets
rules:
- http:
paths:
- path: /icons
pathType: ImplementationSpecific
backend:
resource:
apiGroup: k8s.example.com
kind: StorageBucket
name: icon-assets
通过 kubectl describe ingress ingress-resource-backend 查看此 Ingress 详情,能看到
Name: ingress-resource-backend
Namespace: default
Address:
Default backend: APIGroup: k8s.example.com, Kind: StorageBucket, Name: static-assets
Rules:
Host Path Backends
---- ---- --------
*
/icons APIGroup: k8s.example.com, Kind: StorageBucket, Name: icon-assets
Annotations: <none>
Events: <none>
Path 类型
Ingress 中的每个 path 都有对应的 path 类型,且每个 path 的类型都必须显式指定,不显式指定 path 类型无法通过验证。有三种 path 类型:ImplementationSpecific
ingress-nginx 和 nginx-ingress 的区别
注意:ingress-nginx 和 nginx-ingress 都是 ingress controller 实现,但两者不是同一个应用。
区别如下:
1、nginx-ingress 是 Nginx 维护的一个 ingress controller 实现,GitHub 上的项目叫 kubernetes-ingress
官网 https://www.nginx.com/products/nginx/kubernetes-ingress-controller/
GitHub https://github.com/nginxinc/kubernetes-ingress
2、ingress-nginx 是 kubernetes 维护的一个 ingress controller 实现。
官网 https://kubernetes.github.io/ingress-nginx/
GitHub https://github.com/kubernetes/ingress-nginx
3、star对比
ingress-nginx 的 GitHub star 是 kubernetes-ingress 的 3 倍左右(2020.9)
4、功能对比见下面这篇官方文档
Differences Between nginxinc/kubernetes-ingress and kubernetes/ingress-nginx Ingress Controllers
https://github.com/nginxinc/kubernetes-ingress/blob/master/docs/nginx-ingress-controllers.md
见异思迁:K8s 部署 Nginx Ingress Controller 之 kubernetes/ingress-nginx
https://www.cnblogs.com/dudu/p/12334613.html
Helm3部署ingress-nginx
注意:网上多数博客部署的都是 nginx-ingress, 我这里是 ingress-nginx
0、ingress-controller 应部署在边缘节点上,将 linode 作为边缘节点,给 linode node 打上 edge labelkubectl label node linode node-role.kubernetes.io/edge=
执行后查看 nodes
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
lightsail Ready <none> 7d23h v1.19.0
linode Ready edge,master 22d v1.19.0
1、添加 ingress-nginx 的 chart 仓库helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
添加后查看如下
$ helm repo list
NAME URL
ingress-nginx https://kubernetes.github.io/ingress-nginx
2、搜索 ingress-nginx 包
$ helm search repo ingress-nginx
NAME CHART VERSION APP VERSION DESCRIPTION
ingress-nginx/ingress-nginx 3.3.0 0.35.0 Ingress controller for Kubernetes using NGINX a...
3、拉取 chart 包并解压
$ cd ~/helm
$ helm pull ingress-nginx/ingress-nginx --untar
helm pull 最后的 --untar=true 表示下载 chart 包后自动解压,会在当前目录下创建 ingress-nginx 目录并解压到此目录中。或者拉取下来后 tar -zxvf 手动解压 tgz 包。
解压后如下
$ ll ingress-nginx/
总用量 48
-rw-r--r--. 1 linode linode 466 9月 29 20:21 Chart.yaml
drwxr-xr-x. 2 linode linode 4096 9月 29 20:21 ci
-rw-r--r--. 1 linode linode 61 9月 29 20:21 OWNERS
-rw-r--r--. 1 linode linode 9535 9月 29 20:21 README.md
drwxr-xr-x. 3 linode linode 4096 9月 29 20:21 templates
-rw-r--r--. 1 linode linode 20045 9月 29 20:21 values.yaml
3、安装helm install ingress-nginx ingress-nginx/ingress-nginxhelm install 后面第一个参数是安装后 release 的名字,自己任意指定,第二个参数是 chart 包的名字。
Installation Guide - NGINX Ingress Controller
https://kubernetes.github.io/ingress-nginx/deploy/#using-helm
dashboard
kubectl apply部署dashboard
可以参考官方文档直接使用 kubectl apply 部署
Web UI (Dashboard)
https://kubernetes.io/docs/tasks/access-application-cluster/web-ui-dashboard/
kubernetes / dashboard
https://github.com/kubernetes/dashboard
Helm3部署dashboard v2.7.1
这里使用 helm 部署,参考 Helm Hub 中 kubernetes-dashboard 页面的说明文档
https://hub.helm.sh/charts/k8s-dashboard/kubernetes-dashboard
1、添加repohelm repo add k8s-dashboard https://kubernetes.github.io/dashboard
搜索查看 kubernetes-dashboard 版本
$ helm search repo kubernetes-dashboard
NAME CHART VERSION APP VERSION DESCRIPTION
k8s-dashboard/kubernetes-dashboard 2.7.1 2.0.4 General-purpose web UI for Kubernetes clusters
2、拉取 chart 包并解压
$ mkdir helm && cd helm
$ helm pull k8s-dashboard/kubernetes-dashboard --untar=true
解压后如下
$ ll
总用量 44
drwxr-xr-x. 3 linode linode 4096 9月 22 15:44 charts
-rw-r--r--. 1 linode linode 447 9月 22 15:44 Chart.yaml
-rw-r--r--. 1 linode linode 15563 9月 22 15:44 README.md
-rw-r--r--. 1 linode linode 245 9月 22 15:44 requirements.lock
-rw-r--r--. 1 linode linode 163 9月 22 15:44 requirements.yaml
drwxr-xr-x. 2 linode linode 4096 9月 22 15:44 templates
-rw-r--r--. 1 linode linode 8191 9月 22 15:44 values.yaml
3、自定义配置文件 values.yaml
默认使用 values.yaml 这个配置文件,我们拷贝一份后修改,然后指定配置文件启动 chart. 拷贝一份命名为 values-my.yaml
kubernetes系列(十七) - 通过helm安装dashboard详细教程
https://www.cnblogs.com/baoshu/p/13326480.html
Helm 安装部署Kubernetes的dashboard
https://www.cnblogs.com/hongdada/p/11284534.html
第三方工具
Kuboard
eip-work / kuboard-press
https://github.com/eip-work/kuboard-press
Kuboard for K8S
https://kuboard.cn/
Kuboard 是基于 Kubernetes 的微服务管理界面。同时提供 Kubernetes 免费中文教程,入门教程,最新版本的 Kubernetes v1.18 安装手册
Kuboard 这个项目的官网上有最新版的 k8s 安装文档以及学习资料,很不错。
sealos
fanux / sealos
https://github.com/fanux/sealos
sealyun 专注于kubernetes安装
https://sealyun.com/
kubernetes高可用安装(kubernetes install)工具,一条命令,离线安装,包含所有依赖,内核负载不依赖haproxy keepalived,纯golang开发,99年证书,支持v1.16 v1.15 v1.17 v1.18 v1.19
kubesphere
kubesphere / kubesphere
https://github.com/kubesphere/kubesphere
KubeSphere 是在 Kubernetes 之上构建的面向云原生应用的 容器混合云,支持多云与多集群管理,提供全栈的 IT 自动化运维的能力,简化企业的 DevOps 工作流。KubeSphere 提供了运维友好的向导式操作界面,帮助企业快速构建一个强大和功能丰富的容器云平台。KubeSphere 愿景是打造一个基于 Kubernetes 的云原生分布式操作系统,它的架构可以很方便地与云原生生态进行即插即用(plug-and-play)的集成。
k8s发布
k8s滚动更新机制
为了应用升级部署时候 k8s 不停服达到用户无感知,Kubernetes支持称为滚动更新的功能。此功能允许您按顺序更新pod,一次更新一个(按照配置比例),而不是一次停止/更新整个pod。使发布版本更新和回滚而不会中断服务
问题
upstream connect error or disconnect/reset before headers. reset reason connection failure
k8s 的 Istio 网关报的这个错
Istio DestinationRule gives upstream connect error or disconnect/reset before headers
https://stackoverflow.com/questions/53103984/istio-destinationrule-gives-upstream-connect-error-or-disconnect-reset-before-he
error while creating mount source path ‘/etc/localtime’
Error: failed to start container “ess”: Error response from daemon: error while creating mount source path ‘/etc/localtime’: mkdir /etc/localtime: file exists
Back-off restarting failed container
原因:
宿主机的 /etc/localtime 错误的链接到了一个不存在的文件,导致 pod 挂载这个文件时找不到
/etc/localtime -> /usr/share/zoneinfor/Asia/Shanghai
zoneinfo 错写成 zoneinfor 了
上一篇 Pinpoint
下一篇 Prometheus监控
页面信息
location:protocol: host: hostname: origin: pathname: href: document:referrer: navigator:platform: userAgent: