Prometheus监控
Prometheus 是新一代的开源监控方案,它是监控、报警和时序数据库的组合,主要优势有:
- 简单易安装:安装单节点的 Prometheus-Server 即可搭建一套监控系统,不依赖分布式存储或第三方组件(时序数据库等)。
- 灵活的数据模型:Prometheus 定义的监控数据模型不受实体组织模型的约束,满足各种组织的监控需求;另外可对多维度的数据方便的进行汇聚计算与过滤。
- 强大的查询能力:PromQL 提供了强大的查询能力,其丰富的函数与低延迟的响应可满足报警与数据可视化的需求。
- 丰富的生态:丰富的语言SDK和 Exporter 可快速将监控纳入 Prometheus 监控中;与 K8S 的结合可快速实现对K8S集群中相关资源的监控;搭配 Grafana 可实现精美的数据可视化。
《prometheus-book》 中文文档(官方文档的完全翻译)
https://yunlzheng.gitbook.io/prometheus-book/
https://github.com/yunlzheng/prometheus-book
如何以优雅的姿势监控kubernetes 集群服务
https://www.kancloud.cn/huyipow/prometheus/527093
Prometheus 官网
https://prometheus.io/
https://github.com/prometheus/prometheus
Prometheus 官方文档
https://prometheus.io/docs/introduction/overview/
PromQL (Prometheus Query Language) 官方文档
https://prometheus.io/docs/prometheus/latest/querying/basics/
Prometheus官方最佳实践
https://prometheus.io/docs/practices/naming/
基本概念
时间序列
Prometheus会将所有采集到的样本数据以时间序列(time-series)的方式保存在内存数据库中,并且定时保存到硬盘上。
time-series是按照时间戳和值的序列顺序存放的,我们称之为向量(vector).
每条time-series通过指标名称(metrics name)和一组标签集(labelset)命名。
在time-series中的每一个点称为一个样本(sample),样本由以下三部分组成:
- 指标(metric):metric name和描述当前样本特征的labelsets;
- 时间戳(timestamp):一个精确到毫秒的时间戳;
- 样本值(value): 一个float64的浮点型数据表示当前样本的值。
指标(Metric)
所有的指标(Metric)都通过如下格式标示:
<metric name>{<label name>=<label value>, ...}
指标的名称(metric name)可以反映被监控样本的含义(比如, http_request_total - 表示当前系统接收到的HTTP请求总量)
标签(label)反映了当前样本的特征维度,通过这些维度Prometheus可以对样本数据进行过滤,聚合等。例如 api_http_requests_total{method=”POST”, handler=”/messages”}
Prometheus定义了4中不同的指标类型(metric type):
Counter(计数器)、Gauge(仪表盘)、Histogram(直方图)、Summary(摘要)
Counter 只增不减的计数器
Counter 类型的指标其工作方式和计数器一样,只增不减(除非系统发生重置)。
counter是一个累积量度,代表一个单调递增的计数器,其值只能增加或在重新启动时重置为零。
常见的监控指标,如http_requests_total,node_cpu都是Counter类型的监控指标。
一般在定义 Counter 类型指标的名称时推荐使用_total作为后缀。
Gauge 可增可减的仪表盘
与Counter不同,Gauge类型的指标侧重于反应系统的当前状态。因此这类指标的样本数据可增可减。
常见指标如:node_memory_MemFree(主机当前空闲的内容大小)、node_memory_MemAvailable(可用内存大小)都是Gauge类型的监控指标。
Summary 总和
Summary 类型指标会同时上报 _count 指标(总次数) 和 _sum 指标(总时间)
例如,指标 prometheus_tsdb_wal_fsync_duration_seconds 的指标类型为 Summary。 它记录了 Prometheus Server 中 wal_fsync 处理的处理时间,通过访问 Prometheus Server 的 /metrics 地址,可以获取到以下监控样本数据:
# HELP prometheus_tsdb_wal_fsync_duration_seconds Duration of WAL fsync.
# TYPE prometheus_tsdb_wal_fsync_duration_seconds summary
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.5"} 0.012352463
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.9"} 0.014458005
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.99"} 0.017316173
prometheus_tsdb_wal_fsync_duration_seconds_sum 2.888716127000002
prometheus_tsdb_wal_fsync_duration_seconds_count 216
从上面的样本中可以得知当前 Prometheus Server 进行 wal_fsync 操作的总次数为216次,耗时2.888716127000002s。
其中中位数(quantile=0.5)的耗时为0.012352463,9分位数(quantile=0.9)的耗时为0.014458005s。
Exporter 采集数据
所有可以向 Prometheus 提供监控样本数据的程序都可以被称为一个 Exporter
Exporter 的一个实例称为 target
Prometheus 通过轮询的方式定期从这些 target 中获取样本数据(术语叫做 刮取)
PromQL
PromQL 是 Prometheus 内置的数据查询语言,其提供对时间序列数据丰富的查询,聚合以及逻辑运算能力的支持。并且被广泛应用在 Prometheus 的日常应用当中,包括对数据查询、可视化、告警处理当中。
初识PromQL - 《prometheus-book》
https://yunlzheng.gitbook.io/prometheus-book/parti-prometheus-ji-chu/promql/prometheus-query-language
表达式数据类型
在 Prometheus 的表达式语言中,表达式或子表达式包括以下四种类型之一:
瞬时向量(Instant vector)
一组时间序列,每个时间序列包含单个样本,它们共享相同的时间戳。也就是说,表达式的返回值中只会包含该时间序列中的最新的一个样本值。而相应的这样的表达式称之为瞬时向量表达式。
直接通过类似于 PromQL 表达式 http_requests_total{} 查询时间序列时,返回值中只会包含该时间序列中的最新的一个样本值,这样的返回结果我们称之为瞬时向量。
例如 jvm 内存上报的指标如下
jvm_memory_bytes_used{Environment="Prod",Name="service-docker-pod1",Project="service_name",area="heap",instance="172.16.57.233:8001",job="kube-endpoints",kubernetes_namespace="prod"}
通过如下 ql 来查询 user-service 在 prod 环境的某台 instance 上的 heap 堆内存
jvm_memory_bytes_used{Project="user-service", kubernetes_namespace="prod", area="heap", instance="172.16.57.233:8001"}
区间向量(Range vector)
一组时间序列,每个时间序列包含一段时间范围内的样本数据。
而如果我们想过去一段时间范围内的样本数据时,我们则需要使用区间向量表达式。
区间向量表达式和瞬时向量表达式之间的差异在于在区间向量表达式中我们需要定义时间选择的范围,时间范围通过时间范围选择器 [] 进行定义。
PromQL 的时间范围选择器支持其它时间单位:
s - 秒
m - 分钟
h - 小时
d - 天
w - 周
y - 年
例如,通过以下表达式可以选择以当前时间为基准最近5分钟内的所有样本数据:http_request_total{}[5m]
该表达式将会返回查询到的时间序列中最近5分钟的所有样本数据:
http_requests_total{code="200",handler="alerts",instance="localhost:9090",job="prometheus",method="get"}=[
1@1518096812.326
1@1518096817.326
1@1518096822.326
1@1518096827.326
1@1518096832.326
1@1518096837.325
]
http_requests_total{code="200",handler="graph",instance="localhost:9090",job="prometheus",method="get"}=[
4@1518096812.326
4@1518096817.326
4@1518096822.326
4@1518096827.326
4@1518096832.326
4@1518096837.325
]
标量(Scalar)
一个浮点型的数据值
字符串(String)
一个简单的字符串值,当前未用到。
时间序列选择器
瞬时向量选择器
在最简单的形式中,仅指定指标(metric)名称。这将生成包含此指标名称的所有时间序列的元素的瞬时向量。
可以通过向花括号({})里附加一组标签来进一步过滤时间序列。
例如:选择指标名称为 prometheus_http_requests_total,job 标签值为 prometheus,handler标签值为/metrics的时间序列:
prometheus_http_requests_total{ job=”prometheus”, handler=”/metrics”}
PromQL 还支持用户根据时间序列的标签匹配模式来对时间序列进行过滤,目前主要支持两种匹配模式:完全匹配和正则匹配。总共有以下几种标签匹配运算符:
=选择与提供的字符串完全相同的标签。!=选择与提供的字符串不相同的标签。=~选择正则表达式与提供的字符串(或子字符串)相匹配的标签。!~选择正则表达式与提供的字符串(或子字符串)不匹配的标签。
区间向量过滤器
区间向量与瞬时向量的工作方式类似,唯一的差异在于在区间向量表达式中需要定义时间选择的范围,时间范围通过时间范围选择器 [] 进行定义,以指定应为每个返回的区间向量样本值中提取多长的时间范围。
时间范围通过数字来表示,单位可以使用以下其中之一的时间单位:
- s - 秒
- m - 分钟
- h - 小时
- d - 天
- w - 周
- y - 年
例如:选择在过去 5 分钟内指标名称为 prometheus_http_requests_total,job 标签值为 prometheus 的所有时间序列:
prometheus_http_requests_total{job=”prometheus”}[5m]
查询出来的值为区间向量,无法在 grafana 或者图表中展示。
offset 时间位移操作
在瞬时向量表达式或者区间向量表达式中,都是以当前时间为基准:
http_request_total{} # 瞬时向量表达式,选择当前最新的数据
http_request_total{}[5m] # 区间向量表达式,选择以当前时间为基准,5分钟内的数据
而如果我们想查询,5分钟前的瞬时样本数据,或昨天一天的区间内的样本数据呢? 这个时候我们就可以使用位移操作,位移操作的关键字为 offset。
例如,以下表达式返回相对于当前查询时间过去 5 分钟的 prometheus_http_requests_total 值:
prometheus_http_requests_total offset 5m
注意:offset 关键字需要紧跟在选择器 {} 后面。以下表达式是正确的:
sum(prometheus_http_requests_total{job=”prometheus”} offset 5m) // GOOD.
下面的表达式是不合法的:
sum(prometheus_http_requests_total{job=”prometheus”}) offset 5m // INVALID.
该操作同样适用于区间向量。以下表达式返回指标 prometheus_http_requests_total 一周前的 5 分钟之内的 HTTP 请求量的增长率:
rate(prometheus_http_requests_total[5m] offset 1w)
PromQL 聚合操作符
https://prometheus.io/docs/prometheus/latest/querying/operators/#aggregation-operators
https://yunlzheng.gitbook.io/prometheus-book/parti-prometheus-ji-chu/promql/prometheus-aggr-ops
语法<aggr-op>([parameter,] <vector expression>) [without|by (<label list>)]
without 用于从计算结果中移除列举的标签,而保留其它标签。
by 则正好相反,结果向量中只保留列出的标签,其余标签则移除。
通过 without 和 by 可以按照样本的问题对数据进行聚合。
sum 求和
sum 是 Prometheus 内置的聚合操作符,多个时序的数据会合并为单个时序的数据。不同时序的数据会相加在一起。sum 参数是 瞬时向量(single instant vector)
比如指标
http_server_requests_seconds_count{application="statistic",exception="None",method="POST",outcome="SUCCESS",status="200",uri="/statistic",} 512.0
例1,如果只需要计算总量,可以直接 sum{http_server_requests_seconds_count}
例2,按指定的标签聚合
method,outcome,status,uri 四个标签相同的合并为一个数据sum(http_server_requests_seconds_count) by (method,outcome,status,uri)
上面的写法和下面这种 sum by 在一起写法是一样的sum by(method,outcome,status,uri)(http_server_requests_seconds_count)
例3、上面的 sum by 等同于用 without 排除标签后按剩下的标签聚合sum(http_server_requests_seconds_count) without (application,exception)
<aggregation>_over_time() 时间范围内聚合
https://prometheus.io/docs/prometheus/latest/querying/functions/#aggregation_over_time
计算一个时间序列在给定查询时间范围内的聚合值
<aggregation>_over_time()
avg_over_time(range-vector)
min_over_time(range-vector)
max_over_time(range-vector)
sum_over_time(range-vector)
count_over_time(range-vector)
sum_over_time 是单个时序中的一个区间内的度量值相加,sum_over_time 使用的是 区间向量(range-vector)sum_over_time(cpu_usage_percent[20min]),cpu_usage_percent[20min] 获取了过去20分钟内CPU使用率的时间序列,然后 sum_over_time 函数计算了这段时间内的总和。
PromQL 内置函数
increase 区间增长量/差值
increase(v range-vector) 其中参数v是一个区间向量,increase 函数获取区间向量中的第一个和最后一个样本并返回其增长量。因此,可以通过以下表达式Counter类型指标的增长率:increase(node_cpu[2m]) / 120
这里通过 node_cpu[2m] 获取时间序列最近两分钟的所有样本,increase计算出最近两分钟的增长量,最后除以时间120秒得到node_cpu样本在最近两分钟的平均增长率。并且这个值也近似于主机节点最近两分钟内的平均CPU使用率。
rate 区间平均增长率
除了使用 increase 函数以外,PromQL 中还直接内置了 rate(v range-vector) 函数,rate 函数可以直接计算区间向量v在时间窗口内平均增长速率。因此,通过以下表达式可以得到与increase 函数相同的结果:rate(node_cpu[2m])
需要注意的是使用 rate 或者 increase 函数去计算样本的平均增长速率,容易陷入“长尾问题”当中,其无法反应在时间窗口内样本数据的突发变化。
例如,对于主机而言在2分钟的时间窗口内,可能在某一个由于访问量或者其它问题导致CPU占用100%的情况,但是通过计算在时间窗口内的平均增长率却无法反应出该问题。
irate 区间瞬时增长率
为了解决“长尾问题”问题,PromQL提供了另外一个灵敏度更高的函数 irate(v range-vector)。
irate同样用于计算区间向量的计算率,但是其反应出的是瞬时增长率。
irate函数是通过区间向量中最后两个两本数据来计算区间向量的增长速率。这种方式可以避免在时间窗口范围内的“长尾问题”,并且体现出更好的灵敏度,通过irate函数绘制的图标能够更好的反应样本数据的瞬时变化状态。irate(node_cpu[2m])
Prometheus 服务端安装配置
Docker 部署 Prometheus 服务端
INSTALLATION
https://prometheus.io/docs/prometheus/latest/installation/
docker 太方便了,准备好配置文件后直接启动就行,自动从 dockerhub 拉取最新官方镜像,我的启动命令如下:
docker run -d --rm \
--network host \
--name prometheus \
-v /home/centos/git/spring-boot-masikkk/devops/prometheus.yml:/etc/prometheus/prometheus.yml \
-v /data/prometheus:/prometheus \
prom/prometheus
解释下:-d 后台运行--rm 停止容器后删掉容器文件--network host 与宿主机完全共享网络,默认是bridge桥接,无法在nginx中通过localhost转发请求。默认是 9090 端口--name prometheus 指定启动的容器名,方便按名称stop等操作-v 映射配置文件,具体说是宿主机配置文件覆盖容器中的配置文件,我的配置文件在 git 仓库中,方便保存,也可以记录修改历史。-v /data/prometheus:/prometheus 映射数据目录,持久化容器数据,注意宿主机 /data/prometheus 目录要给容器内用户开写权限,否则启动失败
配置 Prometheus 刮取任务
CONFIGURATION
https://prometheus.io/docs/prometheus/latest/configuration/configuration/
我的 prometheus 配置文件如下,配了两个 job,分别从两个 spring boot 服务刮取监控指标
# 全局配置
global:
# 抓取指标的间隔,默认1m
scrape_interval: 60s
# # 评估规则间隔,默认1m
evaluation_interval: 60s
# 抓取指标的超时时间,默认10s
scrape_timeout: 10s
# 刮取 job 配置
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 1m
static_configs:
- targets: ['localhost:9090']
- job_name: 'node-exporter'
scrape_interval: 15s
static_configs:
- targets: ['localhost:9100']
# 每个微服务一个job
- job_name: 'blog'
# 多久采集一次数据,默认继承global值
scrape_interval: 15s
# 采集时的超时时间,默认继承global值
scrape_timeout: 10s
# 采集的url路径是啥
metrics_path: '/blog/actuator/prometheus'
# 采集服务的地址,设置为对应Spring Boot应用的服务器地址
static_configs:
- targets: ['localhost:8001']
- job_name: 'disqus'
# 多久采集一次数据
scrape_interval: 15s
# 采集时的超时时间
scrape_timeout: 10s
# 采集的路径是啥
metrics_path: '/comments/actuator/prometheus'
# 采集服务的地址,设置为对应Spring Boot应用的服务器地址。
static_configs:
- targets: ['localhost:8001']
PromQL 查询界面
安装完 prometheus 后,本地浏览器访问 http://localhost:9090 ,能看到 prometheus 界面说明安装没问题。
我在 vps 装了一个,又用 nginx 做了域名转发,可直接通过下面链接访问我的 prometheus 试用
http://prometheus.masikkk.com/
随意查一个 http://api.masikkk.com/statistic/actuator/prometheus 中上报的指标,如下图
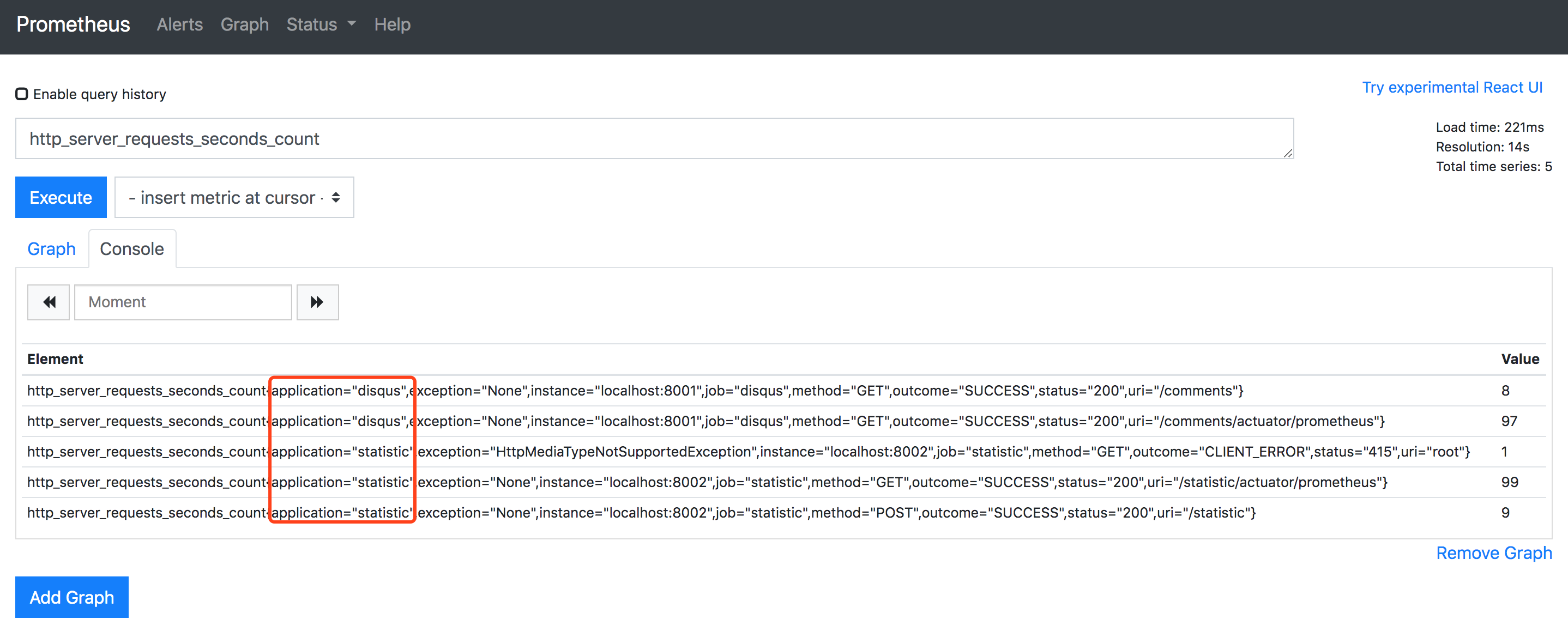
http_server_requests_seconds_count指标
Spring Boot 2.x监控数据可视化(Actuator + Prometheus + Grafana手把手)(docker安装)
http://www.itmuch.com/spring-boot/actuator-prometheus-grafana/
Prometheus 安装和基本配置 (二进制安装,非docker形式)
https://aeric.io/post/prometheus-addons-installation/
Error opening query log file permission denied
问题:
prometheus docker 容器启动报错:
ts=2023-09-10T08:44:45.953Z caller=query_logger.go:93 level=error component=activeQueryTracker msg="Error opening query log file" file=/prometheus/queries.active err="open /prometheus/queries.active: permission denied"
panic: Unable to create mmap-ed active query log
goroutine 1 [running]:
github.com/prometheus/prometheus/promql.NewActiveQueryTracker({0x7fff264c7f05, 0xb}, 0x14, {0x3df59e0, 0xc0007cc910})
/app/promql/query_logger.go:123 +0x411
main.main()
/app/cmd/prometheus/main.go:645 +0x7812
原因:
有数据目录映射 -v /data/prometheus:/prometheus
容器内用户无宿主机 /data/prometheus 目录的写权限
解决:
给 /data/prometheus 添加 777 权限
chmod -R 777 /data/prometheus
Exporter 指标导出服务
Exporter 服务的作用是采集监控数据,并按照 Prometheus 监控规范对外提供这些数据。
有的应用并没有内置支持 metrics 接口,比如 linux 系统、mysql、redis、kafka 等应用,这种情况下可以单独开发一个应用来提供对应的 metrics 指标接口,这就是 Exporter,比如 Node-Exporter 提供系统指标,Mysql-Exporter 提供 MySQL 指标。
Docker 安装 node-exporter
node-exporter 是 prometheus 官方提供的用于导出机器指标的服务
docker run -d --rm \
--network host \
--name node-exporter \
prom/node-exporter
默认是 9100 端口,启动后 curl localhost:9100/metrics 能看到指标数据即可
裸机直接部署 node-exporter
curl -OL https://github.com/prometheus/node_exporter/releases/download/v1.6.1/node_exporter-1.6.1.linux-amd64.tar.gz
tar -xzf node_exporter-1.6.1.linux-amd64
cd node_exporter-1.6.1.linux-amd64
./node_exporter
启动成功后,可以看到以下输出:
INFO[0000] Listening on :9100 source=”node_exporter.go:76”
指定端口启动
./node_exporter –web.listen-address=:9111
SpringBoot2 通过 Actuator 和 Micrometer 接入 Prometheus 监控
SpringBoot 中的 spring-boot-starter-actuator 依赖已经集成了对 Micrometer 的支持,其中的 metrics 端点的很多功能就是通过 Micrometer 实现的,prometheus 端点默认也是开启支持的。
实际上 actuator 依赖的 spring-boot-actuator-autoconfigure 中集成了对很多框架的开箱即用的API,其中 prometheus 包中集成了对 Prometheus 的支持,使得使用了 actuator 可以轻易地让项目暴露出 prometheus 端点,作为 Prometheus 收集数据的客户端,Prometheus(服务端软件)可以通过此端点收集应用中Micrometer的度量数据。
引入 actuator 和 micrometer-prometheus 依赖
<!-- Actuator 监控 -->
<!-- 在 spring-boot-starter-parent 中规定了版本 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!-- micrometer prometheus 监控, -->
<!-- micrometer prometheus 监控, 在 spring-boot-starter-parent / micrometer-bom 中规定了版本 -->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
暴露 /prometheus 端点
默认 actuator 已启用 /prometheus 端点,但并没有通过 http 暴露出来,配置 actuator 暴露端点
# spring boot actuator 监控配置
management:
endpoints.web:
# 暴露所有actuator监控端点,默认只暴露 /actuator/health 和 /actuator/info
exposure.include: "*"
# 不同微服务有各自的前缀
base-path: /statistic/actuator
# 映射健康检查端点的 path 到 status, 供 Prometheus 刮取
path-mapping.health: status
metrics.tags:
application: ${spring.application.name}
management.metrics.tags.application=prometheus-test 作用是为指标设置一个名为 application="服务名" 的Tag,假如有多个服务上报指标,可以用这个tag筛选来自哪个服务。
例如 process_cpu_usage 指标中就多出了这个 tag
# HELP process_cpu_usage The "recent cpu usage" for the Java Virtual Machine process
# TYPE process_cpu_usage gauge
process_cpu_usage{application="statistic",} 0.0
在 SpringBoot2 中,仅配置这两项,不做任何其他改动,已有如下 prometheus 指标可供收集
可查看我的几个服务的指标
http://api.masikkk.com/blog/actuator/prometheus
micrometer 对 prometheus 的支持:
Micrometer Prometheus
https://micrometer.io/docs/registry/prometheus
Micrometer 还给出了一个配置好的 Grafana JVM Dashboard 模板, 可以直接用
https://grafana.com/grafana/dashboards/4701
sprngboot 的支持:
https://docs.spring.io/spring-boot/docs/2.1.4.RELEASE/reference/htmlsingle/#production-ready-metrics-export-prometheus
spring message-converters:
https://docs.spring.io/spring/docs/5.2.0.RELEASE/spring-framework-reference/web.html#mvc-config-message-converters
JVM应用度量框架Micrometer实战
https://www.throwable.club/2018/11/17/jvm-micrometer-prometheus/
actuator 导出指标
req_time_seconds_count http请求总数
spring boot 2 之前的 actuator 导出的指标
请求总数,只要 Prometheus 服务端不重启就一直累加
例如指标如下
req_time_seconds_count{Environment="Stage",Name="uds-user-docker-b5c999855-h259t",Project="uds-user-docker",Tier="uds",exception="None",exported_Environment="stg",exported_Name="172.16.57.245",exported_Project="uds-user-service",exported_Tier="UDS",instance="172.16.57.245:8001",job="kube-endpoints",kubernetes_namespace="uds-stg",method="getUsers",module="BasicInfoApiV2Controller",uri="/uds/api/user/v2/users"} 12
req_time_seconds_count{Environment="Stage",Name="uds-user-docker-b5c999855-h259t",Project="uds-user-docker",Tier="uds",exception="None",exported_Environment="stg",exported_Name="172.16.57.245",exported_Project="uds-user-service",exported_Tier="UDS",instance="172.16.57.245:8001",job="kube-endpoints",kubernetes_namespace="uds-stg",method="getUsers",module="BasicInfoApiV2Controller",uri="/uds/in/user/v2/users"} 16492
req_time_seconds_count{Environment="Stage",Name="uds-user-docker-b5c999855-h259t",Project="uds-user-docker",Tier="uds",exception="None",exported_Environment="stg",exported_Name="172.16.57.245",exported_Project="uds-user-service",exported_Tier="UDS",instance="172.16.57.245:8001",job="kube-endpoints",kubernetes_namespace="uds-stg",method="getUsers",module="BasicInfoSsV2Controller",uri="/uds/ss/user/v2/users"} 6383
req_time_seconds_count{Environment="Stage",Name="uds-user-docker-b5c999855-xj8w4",Project="uds-user-docker",Tier="uds",exception="None",exported_Environment="stg",exported_Name="172.16.71.79",exported_Project="uds-user-service",exported_Tier="UDS",instance="172.16.71.79:8001",job="kube-endpoints",kubernetes_namespace="uds-stg",method="getUsers",module="BasicInfoApiV2Controller",uri="/uds/api/user/v2/users"} 12
req_time_seconds_count{Environment="Stage",Name="uds-user-docker-b5c999855-xj8w4",Project="uds-user-docker",Tier="uds",exception="None",exported_Environment="stg",exported_Name="172.16.71.79",exported_Project="uds-user-service",exported_Tier="UDS",instance="172.16.71.79:8001",job="kube-endpoints",kubernetes_namespace="uds-stg",method="getUsers",module="BasicInfoApiV2Controller",uri="/uds/in/user/v2/users"} 16577
req_time_seconds_count{Environment="Stage",Name="uds-user-docker-b5c999855-xj8w4",Project="uds-user-docker",Tier="uds",exception="None",exported_Environment="stg",exported_Name="172.16.71.79",exported_Project="uds-user-service",exported_Tier="UDS",instance="172.16.71.79:8001",job="kube-endpoints",kubernetes_namespace="uds-stg",method="getUsers",module="BasicInfoSsV2Controller",uri="/uds/ss/user/v2/users"} 6034
1、画出接口 getUsers 在每个实例的 qps 曲线图:
通过 method=”getUsers” 筛选出具体的接口,irate() 计算1分钟的变化率,由于同一个 method 可能对应多个 module 和 uri,通过 without 排除这两个标签
sum without(module,uri) (irate(req_time_seconds_count{Project="uds-user-docker",method="getUsers",exception="None"}[1m]))
2、画出接口 getUsers 在所有实例的汇总 qps 曲线图:
假如有n个实例,则上面画出的图就有n条曲线,sum() 汇总后就是所有实例的总和图:
sum(sum without(module,uri) (irate(req_time_seconds_count{Project="uds-user-docker",method="getUsers",exception="None"}[1m])))
3、画出每个 uri 在所有实例的 qps 折线图
通过 Project 筛选出当前项目的指标, irate() 求一分钟内的变化率,按 label uri 做 sum 即可
sum by(uri)(irate(req_time_seconds_count{Project="uds-user-docker"} [1m]))
画出的图每个 uri 是一条曲线
req_time_seconds_sum http请求总时间(s)
spring boot 2 之前的 actuator 导出的指标
请求总时间,单位秒,只要 Prometheus 服务端不重启就一直累加
例如指标如下
req_time_seconds_sum{Environment="Stage",Name="uds-user-docker-b5c999855-h259t",Project="uds-user-docker",Tier="uds",exception="None",exported_Environment="stg",exported_Name="172.16.57.245",exported_Project="uds-user-service",exported_Tier="UDS",instance="172.16.57.245:8001",job="kube-endpoints",kubernetes_namespace="uds-stg",method="getUsers",module="BasicInfoApiV2Controller",uri="/uds/api/user/v2/users"} 0.19373773
req_time_seconds_sum{Environment="Stage",Name="uds-user-docker-b5c999855-h259t",Project="uds-user-docker",Tier="uds",exception="None",exported_Environment="stg",exported_Name="172.16.57.245",exported_Project="uds-user-service",exported_Tier="UDS",instance="172.16.57.245:8001",job="kube-endpoints",kubernetes_namespace="uds-stg",method="getUsers",module="BasicInfoApiV2Controller",uri="/uds/in/user/v2/users"} 77.564125531
req_time_seconds_sum{Environment="Stage",Name="uds-user-docker-b5c999855-h259t",Project="uds-user-docker",Tier="uds",exception="None",exported_Environment="stg",exported_Name="172.16.57.245",exported_Project="uds-user-service",exported_Tier="UDS",instance="172.16.57.245:8001",job="kube-endpoints",kubernetes_namespace="uds-stg",method="getUsers",module="BasicInfoApiV2Controller",uri="/uds/in/user/v2/users/"} 0.034185448
req_time_seconds_sum{Environment="Stage",Name="uds-user-docker-b5c999855-h259t",Project="uds-user-docker",Tier="uds",exception="None",exported_Environment="stg",exported_Name="172.16.57.245",exported_Project="uds-user-service",exported_Tier="UDS",instance="172.16.57.245:8001",job="kube-endpoints",kubernetes_namespace="uds-stg",method="getUsers",module="BasicInfoSsV2Controller",uri="/uds/ss/user/v2/users"} 213.573544861
req_time_seconds_sum{Environment="Stage",Name="uds-user-docker-b5c999855-xj8w4",Project="uds-user-docker",Tier="uds",exception="None",exported_Environment="stg",exported_Name="172.16.71.79",exported_Project="uds-user-service",exported_Tier="UDS",instance="172.16.71.79:8001",job="kube-endpoints",kubernetes_namespace="uds-stg",method="getUsers",module="BasicInfoApiV2Controller",uri="/uds/api/user/v2/users"} 0.219216063
req_time_seconds_sum{Environment="Stage",Name="uds-user-docker-b5c999855-xj8w4",Project="uds-user-docker",Tier="uds",exception="None",exported_Environment="stg",exported_Name="172.16.71.79",exported_Project="uds-user-service",exported_Tier="UDS",instance="172.16.71.79:8001",job="kube-endpoints",kubernetes_namespace="uds-stg",method="getUsers",module="BasicInfoApiV2Controller",uri="/uds/in/user/v2/users"} 92.456734276
req_time_seconds_sum{Environment="Stage",Name="uds-user-docker-b5c999855-xj8w4",Project="uds-user-docker",Tier="uds",exception="None",exported_Environment="stg",exported_Name="172.16.71.79",exported_Project="uds-user-service",exported_Tier="UDS",instance="172.16.71.79:8001",job="kube-endpoints",kubernetes_namespace="uds-stg",method="getUsers",module="BasicInfoSsV2Controller",uri="/uds/ss/user/v2/users"} 215.207710859
1、画出接口 getUsers 在每个实例的响应时间折线图
通过 method=”getUsers” 筛选出具体的接口,irate() 计算1分钟的变化率,由于同一个 method 可能对应多个 module和uri,通过 without 排除这两个标签
sum without(module,uri) (irate(req_time_seconds_sum{Project="uds-user-docker",method="getUsers",exception="None"}[1m]))
假如有n个实例,则画出的图就有n条曲线
2、画出每个uri在所有实例的响应时间折线图
通过 Project 筛选出当前项目的指标, irate() 求一分钟内的变化率,按 label uri 做 sum 聚合即可
sum by(uri) (irate(req_time_seconds_sum{Project="uds-user-docker",method="getUsers",exception="None"}[1m]))
http_server_requests_seconds_count http请求总数
spring boot 2 之后的 actuator 导出的指标
请求总数,只要 Prometheus服务端不重启就一直累加
http_server_requests_seconds_count 是 Spring Boot 度量(metrics)系统中一个针对 HTTP 请求的计数器,用于记录每种请求方法(GET、POST、PUT、DELETE 等)在一个时间段内的请求数量。具体而言,http_server_requests_seconds_count 会根据请求的 URL、请求方法、状态码等维度进行计数,帮助开发人员了解系统在不同条件下的请求状况,从而更好地优化系统性能。
例如在 Prometheus 界面 http://prometheus.masikkk.com/
根据如下 promql 查询http_server_requests_seconds_count{application="statistic"}
表示查询服务 statistic 的所有 http 接口请求量,结果为
http_server_requests_seconds_count{application="statistic",exception="BindException",instance="localhost:8002",job="statistic",method="POST",outcome="CLIENT_ERROR",status="400",uri="/statistic"} 1
http_server_requests_seconds_count{application="statistic",exception="HttpMediaTypeNotAcceptableException",instance="localhost:8002",job="statistic",method="GET",outcome="CLIENT_ERROR",status="406",uri="root"} 1
http_server_requests_seconds_count{application="statistic",exception="HttpMediaTypeNotSupportedException",instance="localhost:8002",job="statistic",method="GET",outcome="CLIENT_ERROR",status="415",uri="root"} 56
http_server_requests_seconds_count{application="statistic",exception="None",instance="localhost:8002",job="statistic",method="GET",outcome="SUCCESS",status="200",uri="/statistic"} 5
http_server_requests_seconds_count{application="statistic",exception="None",instance="localhost:8002",job="statistic",method="GET",outcome="SUCCESS",status="200",uri="/statistic/actuator"} 2
http_server_requests_seconds_count{application="statistic",exception="None",instance="localhost:8002",job="statistic",method="GET",outcome="SUCCESS",status="200",uri="/statistic/actuator/prometheus"} 40148
http_server_requests_seconds_count{application="statistic",exception="None",instance="localhost:8002",job="statistic",method="GET",outcome="SUCCESS",status="200",uri="/statistic/ranks"} 241
http_server_requests_seconds_count{application="statistic",exception="None",instance="localhost:8002",job="statistic",method="POST",outcome="SUCCESS",status="200",uri="/statistic"} 3330
其中一些有错,一些是系统的,我们给 promql 加些参数筛选下http_server_requests_seconds_count{application="statistic",exception="None",method="POST",uri="/statistic"}
定位到唯一的一个接口的访问量统计
http_server_requests_seconds_count{application="statistic",exception="None",instance="localhost:8002",job="statistic",method="POST",outcome="SUCCESS",status="200",uri="/statistic"} 3338
画出 /statistic 接口的 qps 曲线图,用 irate() 计算1分钟的变化率即可:irate(http_server_requests_seconds_count{application="statistic",exception="None",method="POST",uri="/statistic"}[1m])
http_server_requests_seconds_sum http请求总时间(s)
spring boot 2 之后的 actuator 导出的指标
请求总时间,单位秒,只要 Prometheus 服务端不重启就一直累加
例如在 Prometheus 界面 http://prometheus.masikkk.com/
根据如下 promql 查询http_server_requests_seconds_sum{application="statistic",exception="None"}
http_server_requests_seconds_sum{application="statistic",exception="None",instance="localhost:8002",job="statistic",method="GET",outcome="SUCCESS",status="200",uri="/statistic"} 0.057566057
http_server_requests_seconds_sum{application="statistic",exception="None",instance="localhost:8002",job="statistic",method="GET",outcome="SUCCESS",status="200",uri="/statistic/actuator"} 0.055203038
http_server_requests_seconds_sum{application="statistic",exception="None",instance="localhost:8002",job="statistic",method="GET",outcome="SUCCESS",status="200",uri="/statistic/actuator/prometheus"} 69.266070275
http_server_requests_seconds_sum{application="statistic",exception="None",instance="localhost:8002",job="statistic",method="GET",outcome="SUCCESS",status="200",uri="/statistic/ranks"} 11.035615252
http_server_requests_seconds_sum{application="statistic",exception="None",instance="localhost:8002",job="statistic",method="POST",outcome="SUCCESS",status="200",uri="/statistic"} 86.756807211
增加筛选参数http_server_requests_seconds_sum{application="statistic",exception="None",method="POST",uri="/statistic"}
画出响应时间折线图,用 irate() 计算1分钟的变化率即可:irate(http_server_requests_seconds_sum{application="statistic",exception="None",method="POST",uri="/statistic"}[1m])
http_server_requests_seconds_max 最大时间(Gauge)
http_server_requests_seconds_max 用于记录 HTTP 请求的最长处理时间,以秒为单位。
SpringBoot 手动接入 Prometheus 监控
接入参考
在应用中内置Prometheus支持
https://yunlzheng.gitbook.io/prometheus-book/part-ii-prometheus-jin-jie/exporter/custom_exporter_with_java/custom_app_support_prometheus
Grafana+Prometheus系统监控之SpringBoot
https://www.cnblogs.com/smallSevens/p/7905596.html
自定义Metrics:让Prometheus监控你的应用程序(Spring版)
http://ylzheng.com/2018/01/24/use-prometheus-monitor-your-spring-boot-application/
基于Grafana和Prometheus的监视系统(3):java客户端使用
https://www.jianshu.com/p/60c6d6cb4c49
引入依赖
<!-- Exposition spring_boot -->
<dependency>
<groupId>io.prometheus</groupId>
<artifactId>simpleclient_spring_boot</artifactId>
<version>0.1.0</version>
</dependency>
<!-- Hotspot JVM metrics -->
<dependency>
<groupId>io.prometheus</groupId>
<artifactId>simpleclient_hotspot</artifactId>
<version>0.1.0</version>
</dependency>
<!-- Exposition servlet -->
<dependency>
<groupId>io.prometheus</groupId>
<artifactId>simpleclient_servlet</artifactId>
<version>0.1.0</version>
</dependency>
PrometheusConfig
Prometheus 配置,如果需要用到 Prometheus,则配置 @Import({PrometheusConfig.class}) 并且 prometheus.enable=true
package com.masikkk.common.config;
import com.masikkk.common.monitor.PrometheusMonitorClient;
import io.prometheus.client.exporter.MetricsServlet;
import io.prometheus.client.hotspot.DefaultExports;
import io.prometheus.client.spring.boot.EnablePrometheusEndpoint;
import io.prometheus.client.spring.boot.EnableSpringBootMetricsCollector;
import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Primary;
@EnablePrometheusEndpoint
@EnableSpringBootMetricsCollector
@ConditionalOnProperty(name = "prometheus.enable", havingValue = "true")
public class PrometheusConfig {
@Bean
public ServletRegistrationBean servletRegistrationBean() {
// DefaultExports.initialize(); 注意必须添加,否则不会有JVM指标
DefaultExports.initialize();
// 暴露数据刮取接口
return new ServletRegistrationBean(new MetricsServlet(), "/prometheus");
}
@Bean("prometheusMonitorClient")
@Primary
public PrometheusMonitorClient prometheusMonitorClient(){
return new PrometheusMonitorClient();
}
}
PrometheusClient
package com.masikkk.common.monitor;
import io.prometheus.client.Counter;
import io.prometheus.client.Gauge;
import io.prometheus.client.Summary;
// Prometheus监控客户端。 使用类中方法时,无需考虑并发调用导致监控数据异常的问题。因为方法内部已经使用cas与synchronized进行并发控制。
public class PrometheusMonitorClient {
// 通用计数器
private static final Counter counter = Counter.build()
.name("general_counter")
.labelNames("metric")
.help("通用计数器。可用于统计方法调用次数,包括controller方法,因此可用于统计接口调用次数和一般方法调用次数。也可用于错误次数统计,例如接口异常次数……")
.register();
// 通用的活跃值统计器
private static final Gauge gauge = Gauge.build()
.name("general_gauge")
.labelNames("metric")
.help("通用的活跃值统计器。可用于统计方法或接口的当前处理量。")
.register();
// 通用样本收集器
private static final Summary summary = Summary.build()
.name("general_summary")
.quantile(.9, .05) // 9分位数,抽样误差5%
.quantile(.99, .01)
.quantile(.999, .005)
.quantile(.9999, .001)
.maxAgeSeconds(30) // 样本数据为过去30秒内的数据,30秒之前的数据将被丢弃
.labelNames("metric")
.help("通用的样本收集器。")
.register();
public void count(String metric) {
counter.labels(metric).inc();
}
public void inc(String metric) {
gauge.labels(metric).inc();
}
public void dec(String metric) {
gauge.labels(metric).dec();
}
public void sum(String metric, double value) {
summary.labels(metric).observe(value);
}
}
Interceptor 中上报指标
package com.masikkk.common.interceptor;
import com.google.common.collect.Maps;
import com.masikkk.common.annotation.Metric;
import java.lang.reflect.Method;
import java.util.concurrent.ConcurrentMap;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.slf4j.MDC;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.core.NamedThreadLocal;
import org.springframework.stereotype.Component;
import org.springframework.web.method.HandlerMethod;
@slf4j
@Component
public class UdsBaseInterceptor extends HandlerInterceptorAdapter {
private NamedThreadLocal<Long> stopWatches = new NamedThreadLocal<>("StopWatch");
// api监控指标。key:api方法名,value:监控指标,默认为方法名下划线形式,可以通过@Metric注解自定义
private static ConcurrentMap<String, String> apiMetrics = Maps.newConcurrentMap();
@Autowired(required = false)
private PrometheusMonitorClient prometheusMonitorClient;
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) {
// 活跃值加1
if (prometheusMonitorClient != null) {
String metric = getMetric(handler);
prometheusMonitorClient.inc(metric);
}
// stop watch start
stopWatches.set(System.currentTimeMillis());
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) {
long handleTime = System.currentTimeMillis() - stopWatches.get();
if (prometheusMonitorClient != null) {
// 获得监控指标名称
String metric = getMetric(handler);
// 统计接口调用次数,统计接口响应状态
monitorClient.count(metric + "_" + response.getStatus());
// 活跃值减1
monitorClient.dec(metric);
// 统计接口调用时间
monitorClient.sum(metric, handleTime);
}
}
/**
* 获得监控指标名称
* @param handler
* @return
*/
private String getMetric(Object handler) {
Method method = ((HandlerMethod) handler).getMethod();
String methodName = method.getName();
String metric = apiMetrics.get(methodName);
if (StringUtils.isBlank(metric)) {
Metric annotation = method.getAnnotation(Metric.class);
if (annotation != null) {
// 如果方法有@Metric注解,则获得注解中的监控指标
metric = annotation.value();
} else {
// 默认将方法名的下划线形式作为监控指标
metric = StringUtils.toUnderline(methodName);
}
apiMetrics.put(methodName, metric);
}
return metric;
}
}
Prometheus 抓取配置
Prometheus 主要通过 Pull 的方式来抓取目标服务暴露出来的监控接口,因此需要配置对应的抓取任务来请求监控数据并写入到 Prometheus 提供的存储中
https://cloud.tencent.com/document/product/1416/55995
原始 Prometheus Job
/etc/prometheus/prometheus.yml 中直接配置抓取 job
K8S PodMonitor
在 K8S 生态下,基于 Prometheus Operator 来抓取 Pod 上对应的监控数据。
K8S ServiceMonitor
在 K8S 生态下,基于 Prometheus Operator 来抓取 Service 对应 Endpoints 上的监控数据。
ServiceMonitor 是 Prometheus Operator 中的一种资源类型,是一个 **自定义资源定义(CRD)**,它允许 Prometheus 自动发现和监控符合特定条件的服务,并收集和存储这些服务的指标数据。
通过 ServiceMonitor,Prometheus 可以自动发现 Kubernetes 集群中新创建的 Service 和 Endpoints 对象,并通过 ServiceMonitor CRD 来自动发现并管理它们。一旦ServiceMonitor 定义了要监测的服务,Prometheus 会自动收集这些服务的指标数据,并将其存储在 Prometheus 的时间序列数据库中。此外,ServiceMonitor 还允许在 Service 中定义标准的 Prometheus 标签,这些标签将应用于与该服务关联的所有 Endpoint,从而统一管理指标的标签,使得指标查询更加方便和一致。
下一篇 Lombok
页面信息
location:protocol: host: hostname: origin: pathname: href: document:referrer: navigator:platform: userAgent: